
NetAdapt:MobileNetV3用到的自动化网络简化方法 | ECCV 2018
NetAdapt的思想巧妙且有效,将优化目标分为多个小目标,并且将实际指标引入到优化过程中,能够自动化产生一系列平台相关的简化网络,不仅搜索速度快,而且得到简化网络在准确率和时延上都于较好的表现
来源:晓飞的算法工程笔记 公众号
论文: NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications

Introduction
轻量化网络主要有两种方法,分别为结构优化以及人工量化,但是以上两种方法都不能保证网络能够在不同的设备上都有较优的表现,而且目前的方法大都以非直接指标(计算量/参数量)作为指导,往往与实际结果有出入。
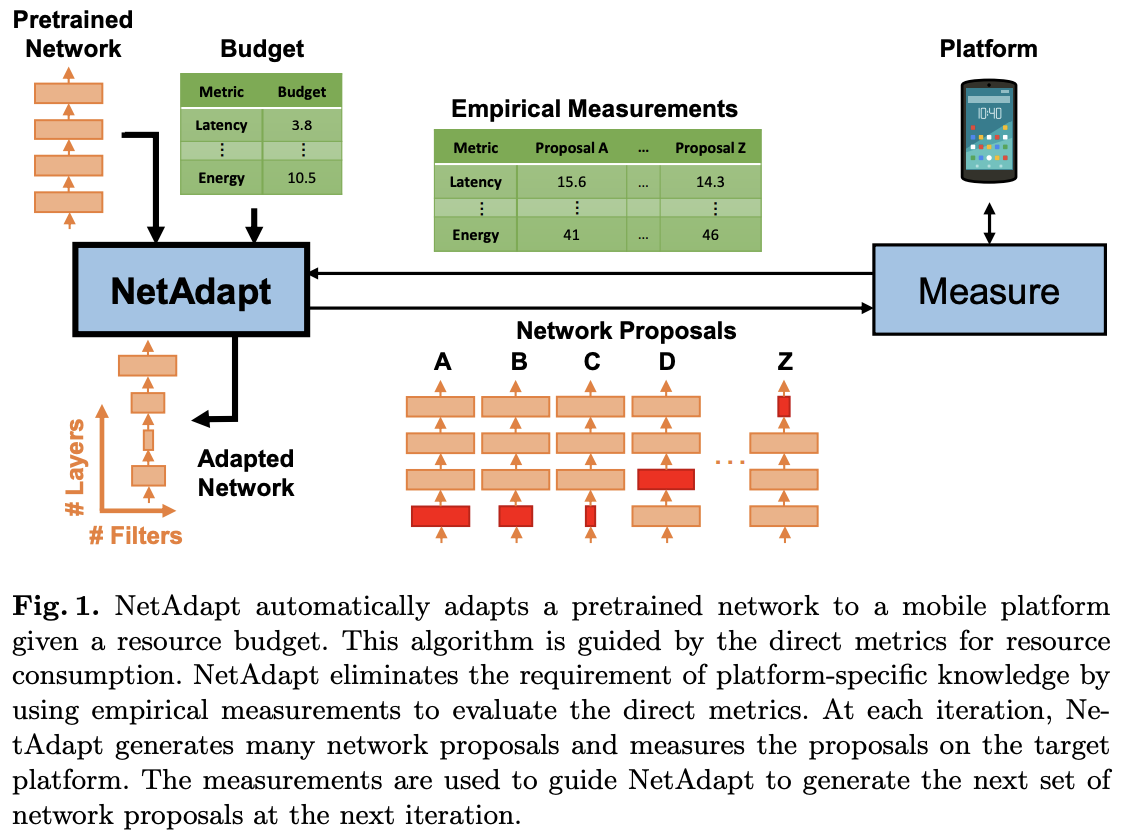
为此,论文提出平台相关的自动化网络简化方法NetAdapt,逻辑如图1所示,以迭代优化的方式慢慢获取满足预期资源消耗的网络。NetAdapt将资源直接指标引入优化过程,可同时支持多种资源约束,能够快速搜索平台相关的简化网络。
Methodology: NetAdapt
Problem Formulation
NetAdapt主要目标是解决以下非凸约束优化问题:
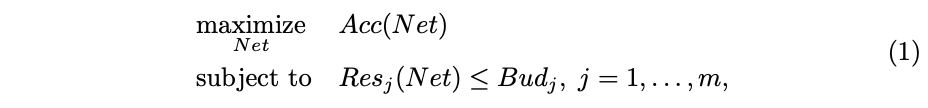
\(Net\)是从初始预训练网络简化得到的网络,\(Acc(\cdot)\)是准确率计算,\(Res_j (\cdot)\)是对资源\(j\)的消耗计算,\(Bud_j\)是资源\(j\)的总量,也是优化的约束条件,可以为时延、能耗、内存或其它。
NetAdapt将上述优化目标分成多个小目标进行迭代优化:
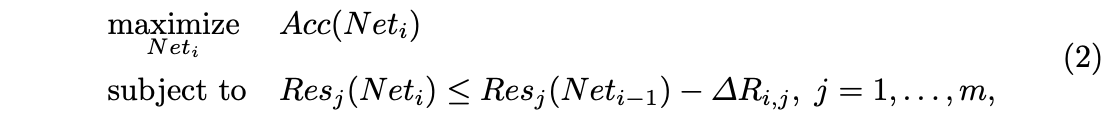
\(Net_i\)是第\(i\)次迭代产生的准确率最高的网络,\(Net_0\)是初始预训练模型。随着迭代次数的增加,网络的资源消耗会变得更少,\(\Delta R_{i,j}\)代表\(i\)次迭代中资源\(j\)的缩减量,整体的想法类似于学习率调度。当\(Res_j(Net_{i-1})-\Delta R_{i,j}=Bud_j\)满足所有资源时,算法终止,输出每一轮迭代优化中最优的网络,从中选择合适的网络。
Algorithm Overview

假设当前优化目标只有时延,可采用减少卷积层或全连接层的核数量进行资料消耗的优化,NetAdapt的算法逻辑如Algorithm 1所示。
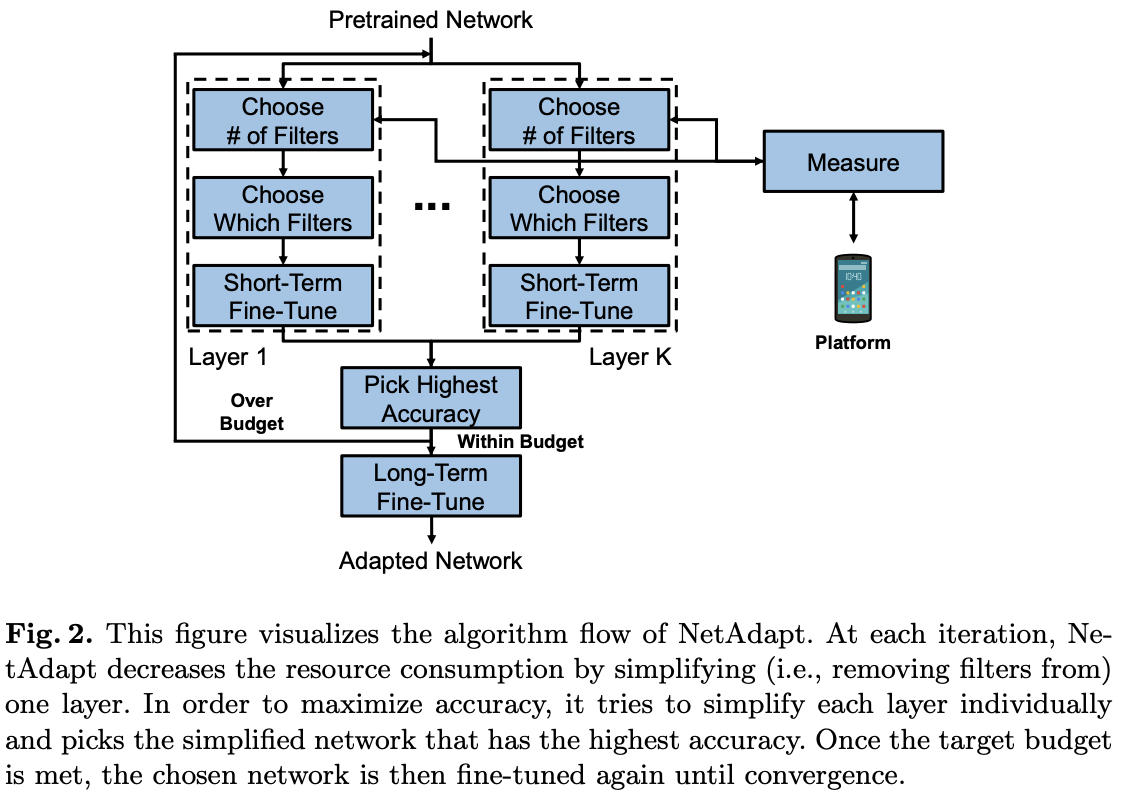
图2是每次迭代的细节,逐层(也可以网络unit为单位)选择保留的核数量(Choose # of Filters)以及保留的核(Choose Which Filters),核数量的选择基于经验估计(后面会讲到),注意这里选择去除整个核而不是其中的一些权值,比如\(512\times 3\times 3\)的卷积核缩减为\(256\times 3\times 3\)的卷积核,去除核后要去除对应的特征图。每层的优化都产生一个简化后的网络,简化后的网络随后进行短时间fine-tune(Short-Term Fine-Tune)来恢复准确率。
在上述操作完成后,NetAdapt单次迭代产生\(K\)个简化网络,选择其中准确率最高的网络作为下一轮迭代的初始网络(Pick Highest Accuracy)。若当前迭代的网络已满足资源要求时,退出优化并将每次迭代产生的最优网络fine-tune直到收敛(Long-Term Fine-Tune)。
Algorithm Details
-
Choose Number of Filters
当前层选择的核数量基于经验估计来决定,逐步减少核数量并计算每个简化网络的资源消耗,选择能满足当前资源消耗约束的最大核数量。当减少当前层的核数量时,后一层的相关维度要对应修改,这个也要考虑到资源消耗计算中。
-
Choose Which Filters
有很多方法来决定选择保留的核,论文采用简单magnitude-based方法,即选择\(N\)个L2-norm最大的核,\(N\)由上面的步骤决定。
-
Short-/Long-Term Fine-Tune
在NetAdapt的每次迭代中,都使用相对较小的次数(short-term)fine-tune搜索到的简化网络来恢复准确率,这一步对于小网络而言相当重要。由于大量减少资源量,如果不这样做,网络的准确率可能会降为零,导致算法选择了错误的网络。随着算法的进行,虽然网络会持续训练,但还没到收敛的地步,所以当得到最后的一系列自适应网络后,使用较多的次数(long-term)fine-tune直到收敛作为最后一步。
Fast Resource Consumption Estimation
在自适应的过程中,需要离线计算简化网络的资源消耗,这个计算可能会很慢并且由于设备有限难以并行,会成为算法的计算瓶颈。
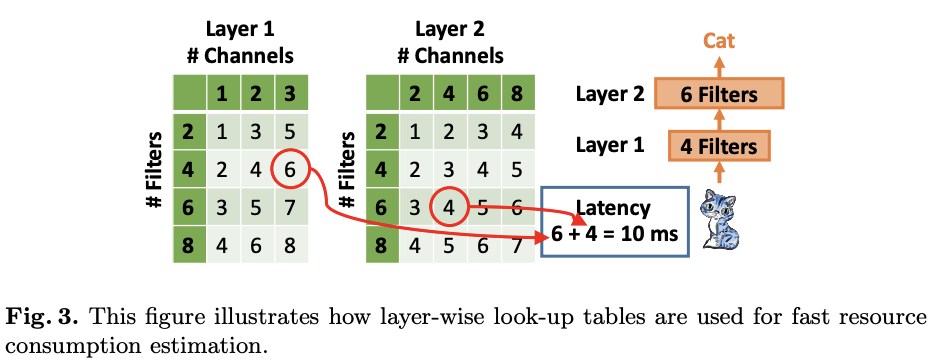
论文通过建立多个layer-wise look-up表格来解决上面提到的资源消耗计算问题,即前面提到的经验估计。每个表格预先计算对应层的在不同的输入维度和核数量下的资源消耗,注意相同输入大小和配置的层可以共用表格内容。在估算时,先找到对应的层的表格,通过累计layer-wise的资源消耗来估算network-wise资源消耗,逻辑如图3所示。
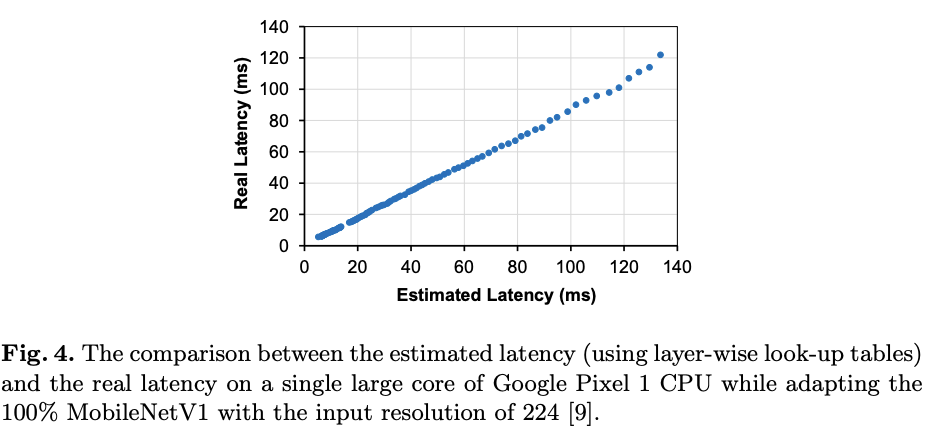
图4对比了对MobileNetV1进行优化过程中估算的时延与实际时延,可以看到两个值是高度相关的。
Experiment Results
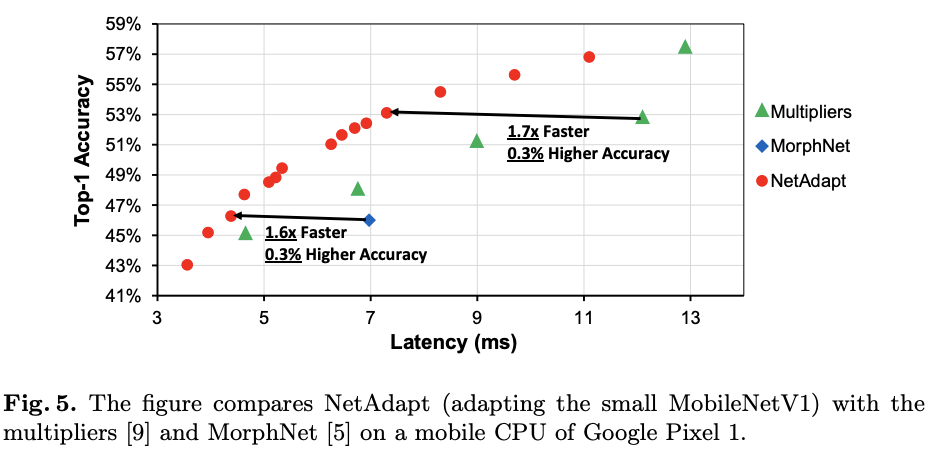
对比NetAdapt与其它网络简化方法在小型MobileNetV1(50%)上的简化效果。
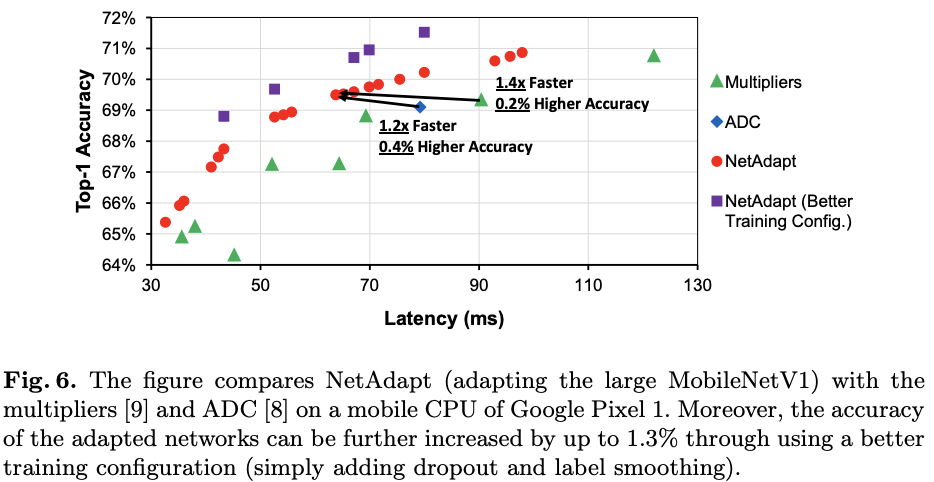
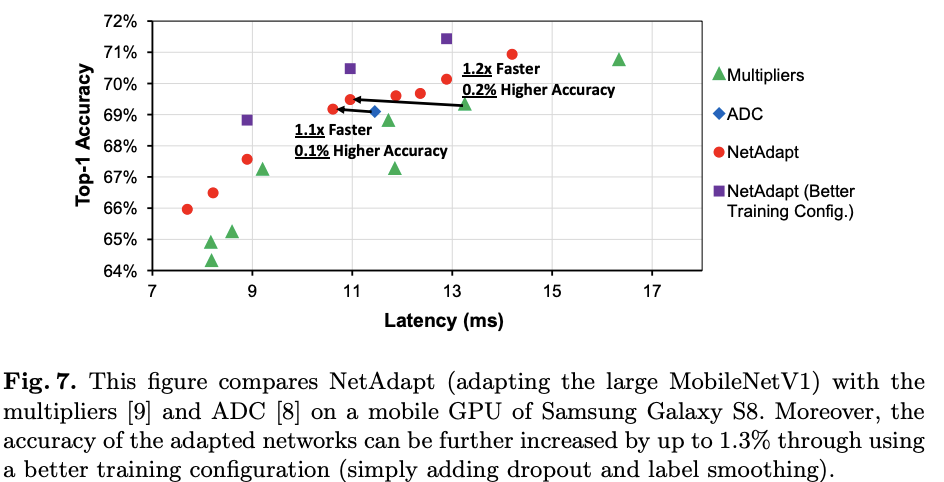
在不同的设备上对比NetAdapt与其它网络简化方法在小型MobileNetV1(100%)上的简化效果。
Conclustion
NetAdapt的思想巧妙且有效,将优化目标分为多个小目标,并且将实际指标引入到优化过程中,能够自动化产生一系列平台相关的简化网络,不仅搜索速度快,而且得到简化网络在准确率和时延上都于较好的表现。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号