ARTS_4
概述
ARTS 是耗子叔发起的编程挑战:
每周完成一个ARTS: 每周至少做一个 leetcode 的算法题、阅读并点评至少一篇英文技术文章、学习至少一个技术技巧、分享一篇有观点和思考的技术文章。(也就是 Algorithm、Review、Tip、Share 简称ARTS)
Algorithm
https://leetcode.cn/problems/all-oone-data-structure/
感觉退役那么久之后模拟水平确实下降了很多,题目其实看上去不是很难,而且思路也非常好想。
首先你需要一个添加跟删除耗时为\(O(1)\)的数据结构,那么我们有两个选项,一个是map另一个是list。
之后我们发现他是需要根据给出的string进行查找,所以这一步我们肯定需要选择map。不然的话,不能通过key去寻找对应的信息。
之后我们发现题目的要求里面还需要求出当前最大最小值,我们发现map完全实现不了这个操作,因为\(O(1)\)的map内部是无序的,那么我们只能考虑用list来维护了。
那么该如何维护呢,其实一旦想到用list就比较简单了。只需要让这个list是一个单调递增的list就行。因为每次都是+1或者-1,所以list的节点只可能往前移动或者往后移动或者不动。
但是如果每个key都给一个节点的话,会容易被卡——假设inc了1e4个不同的key,之后每次都是inc两次,之后dec两次一个key,这样话每次节点的移动都是1e4。所以考虑节点的信息,因为是次数cnt跟所有次数为cnt的key集合,也就是map[string]struct{},想明白这点之后就是疯狂的模拟,模拟的细节较多,都写注解里了。
package main
import (
"container/list"
)
type node struct {
cnt int //次数
mp map[string]struct{} //字符串集合
}
func NewNode(n int, key string) *node {
ret := &node{
cnt: n,
mp: make(map[string]struct{}),
}
ret.mp[key] = struct{}{}
return ret
}
type AllOne struct {
l *list.List
mp map[string]*list.Element
}
func Constructor() AllOne {
return AllOne{
l: list.New(),
mp: make(map[string]*list.Element),
}
}
func (this *AllOne) Inc(key string) {
// 发现是个新的key
if cur, ok := this.mp[key]; !ok {
// 链表里已经有东西了
if this.l.Len() != 0 {
// 看看链表最前面的元素的cnt是否为1
head := this.l.Front().Value.(*node)
// 不为1的话需要新开一个cnt为1的节点
if head.cnt > 1 {
// 插入到链表头部
this.l.PushFront(NewNode(1, key))
// 记录key对应的node地址
this.mp[key] = this.l.Front()
return
}
// 为1的话就在这个节点加入这个点的mp
head.mp[key] = struct{}{}
this.mp[key] = this.l.Front()
return
}
// 链表为空
// 插入到链表头部
this.l.PushFront(NewNode(1, key))
// 记录key对应的node地址
this.mp[key] = this.l.Front()
} else { // 发现是已经在维护链表中的key
cur_v := cur.Value.(*node)
nxt := cur.Next()
//如果当前的节点是单key节点
if len(cur_v.mp) == 1 {
// 当前节点是最后一个节点
if nxt == nil {
// 那就直接修改节点cnt即可
cur_v.cnt++
return
}
// 如果后面一个节点的cnt不是接着的前面的cnt
if nxt.Value.(*node).cnt != cur_v.cnt+1 {
// 那就直接修改节点cnt即可
cur_v.cnt++
return
}
// 如果后面一个节点的cnt是接着的前面的cnt
//就把当前key插入后面的节点
nxt.Value.(*node).mp[key] = struct{}{}
//同时更新key所在list位置
this.mp[key] = nxt
//并删除当前节点
this.l.Remove(cur)
}
//如果当前的节点是多key节点
//若当前节点已经是最后一个节点
if nxt == nil {
//直接就往最后插入
this.l.PushBack(NewNode(cur_v.cnt+1, key))
//同时更新这个key的相关节点信息
this.mp[key] = this.l.Back()
// 同时把之前节点关于key的信息删除
delete(cur_v.mp, key)
return
}
// 后面还有节点
nxt_v := nxt.Value.(*node)
// 如果后面一个节点的cnt不是接着的前面的cnt
if nxt_v.cnt != cur_v.cnt+1 {
// 新开一个节点,查到当前节点后面
this.l.InsertAfter(NewNode(cur_v.cnt+1, key), cur)
//同时更新这个key的相关节点信息
this.mp[key] = cur.Next()
// 同时把之前节点关于key的信息删除
delete(cur_v.mp, key)
return
}
// 如果是直接接着的
// 往下个节点插入key
nxt_v.mp[key] = struct{}{}
//更新key所在list位置
this.mp[key] = nxt
// 当前节点删除key
delete(cur_v.mp, key)
}
}
func (this *AllOne) Dec(key string) {
cur := this.mp[key]
cur_v := cur.Value.(*node)
prev := cur.Prev()
//如果当前的节点是单key节点
if len(cur_v.mp) == 1 {
// 当前节点是第一个节点
if prev == nil {
// 那就直接修改节点cnt即可
cur_v.cnt--
// 如果cnt变成0了就要删除
if cur_v.cnt == 0 {
delete(this.mp, key)
this.l.Remove(cur)
}
return
}
// 如果前面一个节点的cnt不是接着的后面的cnt
if prev.Value.(*node).cnt != cur_v.cnt-1 {
// 那就直接修改节点cnt即可
cur_v.cnt--
return
}
// 如果前面一个节点的cnt是接着的前面的cnt
//就把当前key插入后面的节点
prev.Value.(*node).mp[key] = struct{}{}
//同时更新key所在list位置
this.mp[key] = prev
//并删除当前节点
this.l.Remove(cur)
}
//如果当前的节点是多key节点
//若当前节点已经是第一个节点
if prev == nil {
// 看当前的cnt是否为1
if cur_v.cnt-1 == 0 {
// 删除这个key相关信息
delete(cur_v.mp, key)
delete(this.mp, key)
return
}
// 否则就往前面插入
this.l.PushFront(NewNode(cur_v.cnt-1, key))
//同时更新这个key的相关节点信息
this.mp[key] = this.l.Front()
// 同时把之前节点关于key的信息删除
delete(cur_v.mp, key)
return
}
// 后面还有节点
pre_v := prev.Value.(*node)
// 如果前面一个节点的cnt不是接着的前面的cnt
if pre_v.cnt != cur_v.cnt-1 {
// 新开一个节点,查到当前节点后面
this.l.InsertBefore(NewNode(cur_v.cnt-1, key), cur)
//同时更新这个key的相关节点信息
this.mp[key] = cur.Prev()
// 同时把之前节点关于key的信息删除
delete(cur_v.mp, key)
return
}
// 如果是直接接着的
// 往下个节点插入key
pre_v.mp[key] = struct{}{}
//更新key所在list位置
this.mp[key] = prev
// 当前节点删除key
delete(cur_v.mp, key)
}
func (this *AllOne) GetMaxKey() string {
if this.l.Back() != nil {
p := this.l.Back().Value.(*node)
for k := range p.mp {
return k
}
}
return ""
}
func (this *AllOne) GetMinKey() string {
if this.l.Front() != nil {
p := this.l.Front().Value.(*node)
for k := range p.mp {
return k
}
}
return ""
}
func main() {
allOne := Constructor()
allOne.Inc("hello")
allOne.Inc("goodbye")
allOne.Inc("hello")
allOne.Inc("hello")
println(allOne.GetMaxKey()) // 返回 "hello"
allOne.Inc("leet")
allOne.Inc("code")
allOne.Inc("leet")
allOne.Dec("hello")
allOne.Inc("leet")
allOne.Inc("code")
allOne.Inc("code")
println(allOne.GetMaxKey()) // 返回 "leet"
}
Tips
关于Prometheus的yml文件相关字段含义,以及应该如何设置
工作苦yml久矣,每次看mentor还有同期跟我讲yml里面要怎么设置都是一头雾水,现在也还是不会。今天就系统学一下,这里面各个字段到底是什么含义。
原始的配置文件内容:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
这上面官方的注释都写得差不多了其实。
global*:
全局配置(如果有内部单独设定,会覆盖这个参数)
# my global config
global:
scrape_interval: 15s # 默认15s 全局每次数据收集的间隔
evaluation_interval: 15s # 规则扫描时间间隔是15秒,默认不填写是 1分钟
scrape_timeout: 5s #超时时间
external_labels: # 用于外部系统标签的,不是用于metrics(度量)数据
alerting :
ps: 暂时工作中还没有用到。
告警插件定义。这里会设定alertmanager这个报警插件。
rule_files:
ps: 暂时工作中还没有用到。
告警规则。 按照设定参数进行扫描加载,用于自定义报警规则,其报警媒介和route路由由alertmanager插件实现。
scrape_configs:
采集配置。配置数据源,包含分组job_name以及具体target。又分为静态配置和服务发现
scrape_configs 默认规则:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
支持的配置:
job_name:
任务目标名,可以理解成分组,每个分组包含具体的target组员。
scrape_interval:
这里如果单独设定的话,会覆盖global设定的参数,拉取时间间隔为5s
targets:
监控目标访问地址
说明:上述为静态规则,没有设置自动发现。
这种情况下增加主机需要自行修改规则,通过supervisor reload 对应任务,也是缺点:每次静态规则添加都要重启prometheus服务,不利于运维自动化。
prometheus支持服务发现(也是运维最佳实践经常采用的):
基于文件的服务发现方式不需要依赖其他平台与第三方服务,用户只需将 要新的target信息以yaml或json文件格式添加到target文件中 ,prometheus会定期从指定文件中读取target信息并更新
好处:
(1)不需要一个一个的手工去添加到主配置文件,只需要提交到要加载目录里边的json或yaml文件就可以了;
(2)方便维护,且不需要每次都重启prometheus服务端。
scrape_configs:
#通过配置file 获取target
- job_name: 'cn-hz-21yunwei-other'
file_sd_configs:
- files:
- file_config/21yunwei/host.json
关于Grafana的Variable设置
variables变量的设置页面
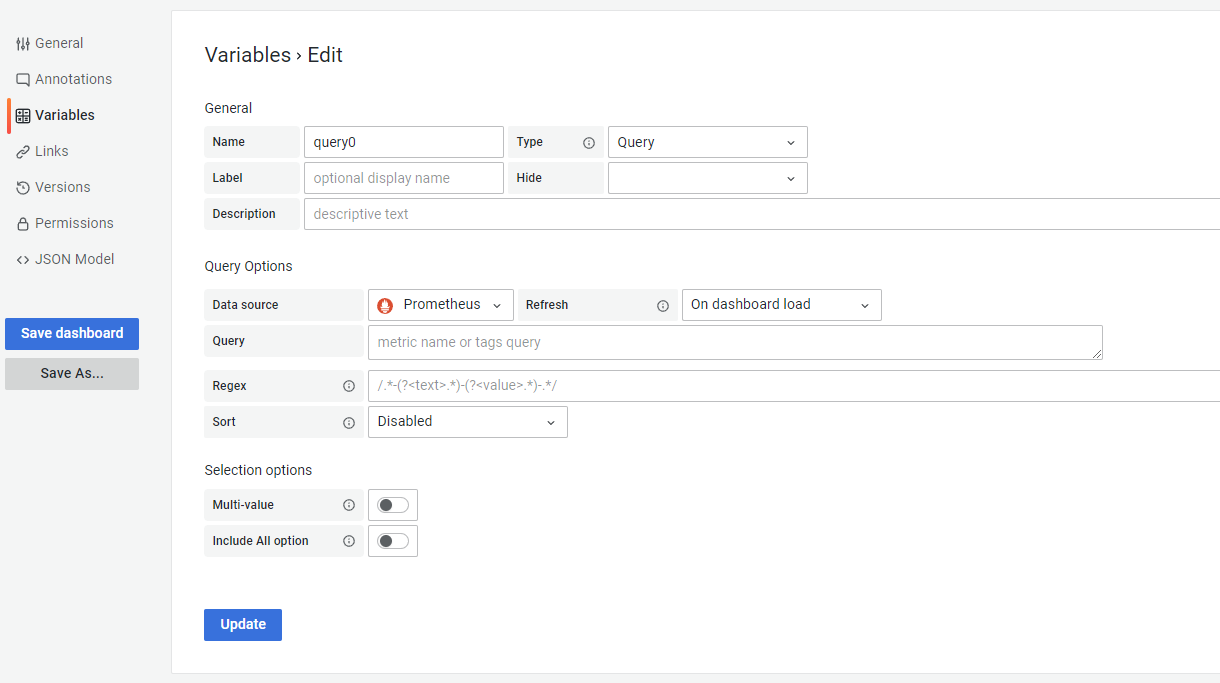
variables提供了参数功能,相当于一个宏变量,这个宏变量的值是和datasource级联的
参数作用
General
name: 变量名称,在其他地方调用这个变量时,使用$name。

type: 变量的类型,如下:
-
query 表示这个变量是一个查询语句:
-
datasource 就表示改变量代表一个数据源,如果是datasource 那就可以用改变量修改整个仪表盘的数据源
-
interval 表示查询的时间跨度,例如:
-
custom 自定义一些其他变量
-
constant 定义可以隐藏的常量,对于要共享的仪表盘中包括路径或者前缀很有用,在仪表盘导入过程中,常量变量将成为导入时的选项。
-
text box 用户提供一个可以自由输入的文本框
label:标签,在仪表盘上显示标签名字,不设置标签则显示变量名
hide:隐藏,用于隐藏标签,可以调用,但是在仪表盘不显示变量名
Query Options
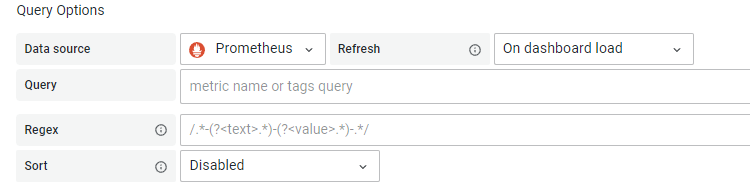
data source: 选择数据源
refresh: 刷新方式
-
never:从不刷新
-
on dashboard load:仪表盘加载时,常用选项
-
on time range changed:时间范围发生变化时
Query:
Query 类型的变量允许您向 Prometheus 查询指标、标签或标签值的列表。
query使用的函数:
-
label_names()返回标签名称列表,会将prometheus所有指标的标签名称全部显示出来,赋值给变量名
-
label_values(label)返回每个指标中标签的标签值列表,例如 查询标签名是instance的对应的标签值,把结果赋值给变量名
-
label_values(metric, label)返回指定指标中标签的标签值列表,例如 查询指标kube_node_info中的标签名是instance的 对应的标签值,把结果赋值给变量名
-
metrics(metric) 返回与指定指标正则表达式匹配的指标列表,例如 将包含这个“memory_Mem” 字段的指标名过滤出来,赋值给变量名
-
query_result(query)返回查询的 Prometheus 查询的结果列表
regex:使用正则表达式 对抓取到的返回值进行过滤,例如
sort:对获取的返回值 进行排序
-
Disanled禁用
-
Alphabetical(asc)按字母升序
-
Alphabetical(desc)按字母降序
-
Numerical(asc)按数字升序
-
Numerical(desc)按数字降序
-
Alphabetical(casc-insensitive,asc)按字母不区分大小写升序
-
Alphabetical(casc-insensitive,desc)按字母不区分大小写降序
Selection options
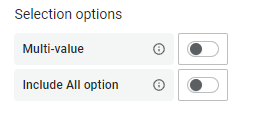
Multi-value:启用这个功能,变量的值就可以选择多个,具体表现在变量对应的下拉框中可以选多个值的组合。
Include All option:启用这个功能,变量下拉框中就多了一个all选项。
下面这段代码输出什么?
type person struct {
name string
}
func main() {
var m map[person]int
p := person{"mike"}
fmt.Println(m[p])
}
答案解析:
m 是一个 map,值是 nil。从 nil map 中取值不会报错,而是返回相应的零值,这里值是 int 类型,因此返回 0。
Review
https://medium.com/@mbinjamil/using-interfaces-in-go-the-right-way-99384bc69d39
分享的是一个关于Golang中interface的正确使用方法。
讲道理在medium上找一篇对我有所帮助的文章还挺难的,大多是比较简单的教程,或者是空谈与介绍。
Accept Interfaces, Return Structs
接口是一组对象的方法的抽象集合,所以我们在实现具体方法前,不应该先考虑如何去定义interface。我们应该在观察消费者行为的时候,抽象消费者所需要的方法,而不是在实现的时候考虑如何去抽象。
Go Code Review Comments里提到一点:
“Go interfaces generally belong in the package that uses values of the interface type, not the package that implements those values.”
也就是,一个接口应该出现在消费者的package里,而不是实现的package里。
Don’t Do this
package tcp
type Server interface {
Start()
}
type server struct { ... }
func (s *server) Start() { ... }
func NewServer() Server {
return &server{ ... }
}
package consumer
import “tcp” //耦合
func StartServer(s tcp.Server) {
s.Start()
}
这是非常不推荐的interface的用法,因为它不是为了抽象的目的而定义的,而且这种写法将消费者包耦合到了实施者包。
Do This Instead
package tcp
type Server struct { ... }
func (s *server) Start() { ... }
func NewServer() Server { return &Server{ ... } }
package consumer
type Server interface {
Start()
}
func StartServer(s Server) { s.Start() }
这样的话就把实现package跟消费package解耦了,消费者只需要关心,这个interface所拥有的方法,而不需要关心其他。
Go Standard Library
这部分主要是提及在golang standard中,上述原则的体现。
像在io包中
type Reader interface {
Read(p []byte) (n int, err error)
}
func Copy(dst Writer, src Reader) (written int64, err error)
还有HTTP包中
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
func ListenAndServe(addr string, handler Handler) error
Interface Segregation Principle
这部分是讲上述原则其实也是为了SOLID原则,即其中的 Interface Segregation Principle也就是接口隔离原则。
“Clients should not be forced to depend on interfaces that they do not use.”
同时,消费者应该只接收含有他们所关心方法的接口。
// os.File contains many unrelated methods
func Save(f *os.File, doc *Document) error
// io.ReadWriteCloser contains unrelated Read() and Close() methods
func Save(rwc io.ReadWriteCloser, doc *Document) error
// io.Writer contains only one method Write() that is required
func Save(w io.Writer, doc *Document) error
第一个方法,os.File包含了太多用户不需要的函数、
第二个方法,io.ReadWriteCloser包含了与定义不相关的Read()和CLose()
第三个方法,正好是我们所需要的。
当我们在使用它们之前定义接口时,即在生产者包中,它们通常是包含许多方法的大型接口。此外,这些接口将添加新方法,因为实现会随着时间而变化。这意味着使用相同接口的所有消费者更有可能拥有与其功能无关的方法。
因此,仅在需要使用接口时才定义接口意味着我们遵循接口隔离原则。并且通过遵循这个原则,我们可以防止为多个职责定义方法的臃肿接口,从而产生更易于维护的 Go 代码。
Share
关于这篇文章中提到的一些说法我觉得挺契合我的想法的:
- 技术终究还是用来解决问题的。不要单纯为了技术而技术,技术归根结底还是为应用场景和产业落地服务。
- 输出倒逼输入
- 珍惜当下,健康生活

 浙公网安备 33010602011771号
浙公网安备 33010602011771号