
未来直播 “神器”,像素级视频分割是如何实现的 | CVPR 冠军技术解读
被誉为计算机视觉领域 “奥斯卡” 的 CVPR 刚刚落下帷幕,2021 年首届 “新内容 新交互” 全球视频云创新挑战赛正火热进行中,这两场大赛都不约而同地将关注点放在了视频目标分割领域,本文将详细分享来自阿里达摩院的团队在 CVPR DAVIS 视频目标分割比赛夺冠背后的技术经验,为本届大赛参赛选手提供 “他山之石”。
作者|负天
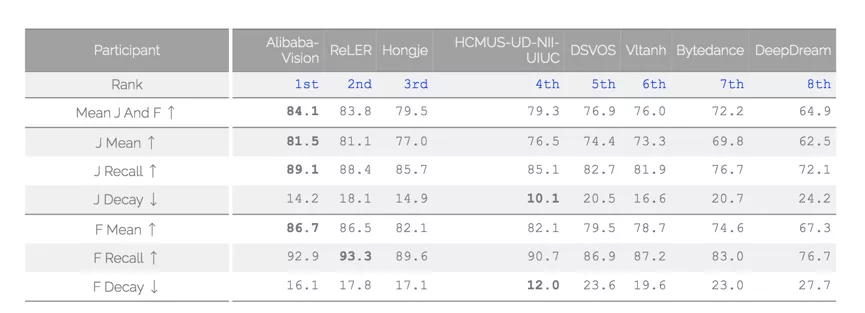
与图像识别不同,AI 分析理解视频的技术门槛较高。长期以来,业界在视频 AI 技术的研究上鲜有重大突破。以 CVPR 会议难度最高的比赛之一 DAVIS( Densely Annotated Video Segmentation)为例,该比赛需要参赛团队精准处理复杂视频中物体快速运动、外观变化、遮挡等信息,过去几年,全球顶级科技在该比赛中的成绩从未突破 80 分,而达摩院的模型最终在 test-challenge 上取得了 84.1 的成绩。

DAVIS 的数据集经过精心挑选和标注,视频分割中比较难的点都有体现,比如:快速运动、遮挡、消失与重现、形变等。DAVIS 的数据分为 train(60 个视频序列), val(30 个视频序列),test-dev(30 个视频序列),test-challenge(30 个视频序列)。其中 train 和 val 是可以下载的,且提供了每一帧的标注信息。对于半监督任务, test-dev 和 test-challenge,每一帧的 RGB 图片可以下载,且第一帧的标注信息也提供了。算法需要根据第一帧的标注 mask,来对后续帧进行分割。分割本身是 instance 级别的。
阿里达摩院:像素级视频分割
阿里达摩院提供了一种全新的空间约束方法,打破了传统 STM 方法缺乏时序性的瓶颈,可以让系统基于视频前一帧的画面预测目标物体下一帧的位置;此外,阿里还引入了语义分割中的精细化分割微调模块,大幅提高了分割的精细程度。最终,精准识别动态目标的轮廓边界,并且与背景进行分离,实现像素级目标分割。
基本框架
达摩院的算法基于 2019 年 CVPR 的 STM 做了进一步改进。STM 的主要思想在于,对于历史帧,每一帧都编码为 key-value 形式的 feature。预测当前帧的时候,以当前帧的 key 去和历史帧的 key 做匹配。匹配的方式是 non-local 的。这种 non-local 的匹配,可以看做将当前 key,每个坐标上的 C 维特征,和历史每一帧在这个坐标上的 C 维特征做匹配。匹配得到的结果,作为一个 soft 的 index,去读取历史 value 的信息。读取的特征和当前帧的 value 拼接起来,用于后续的预测。
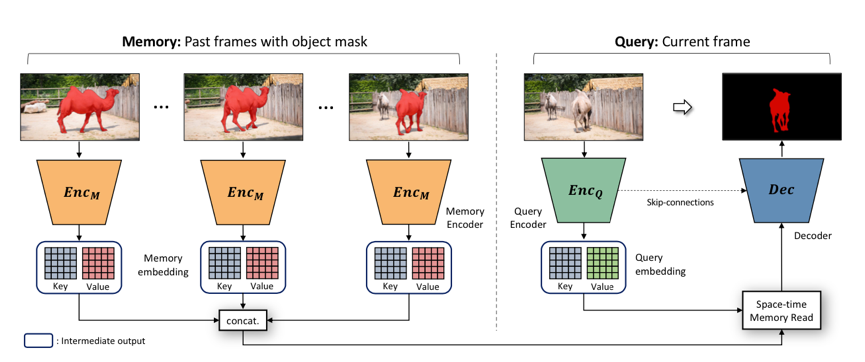
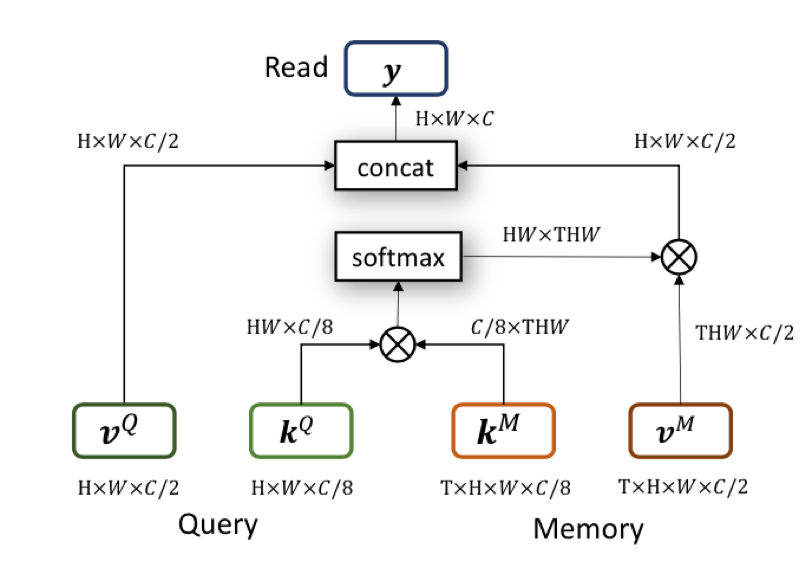
三大技术创新
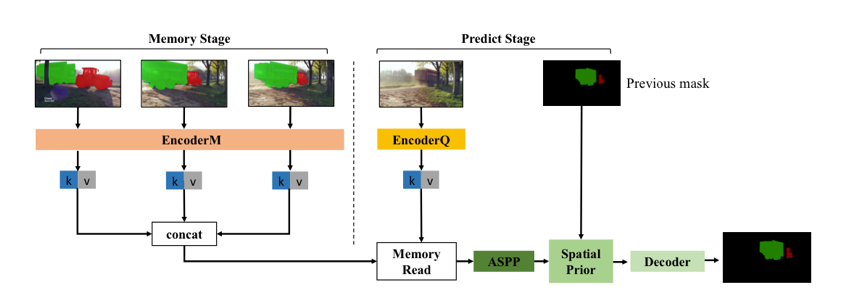
1. 空间约束
STM 的特征匹配方式,提供了一种空间上的长依赖, 类似于 Transformer 中,通过 self-attention 来做序列关联。这种机制,能够很好地处理物体运动、外观变化、遮挡等。但也有一个问题,就是缺乏时序性,缺少短时依赖。当某一帧突然出现和目标相似的物体时,容易产生误召回。在视频场景中,很多情况下,当前帧临近的几帧,对当前帧的影响要大于更早的帧。基于这一点,达摩院提出依靠前一帧结果,计算 attention 来约束当前帧目标预测的位置,相当于对短期依赖的建模。
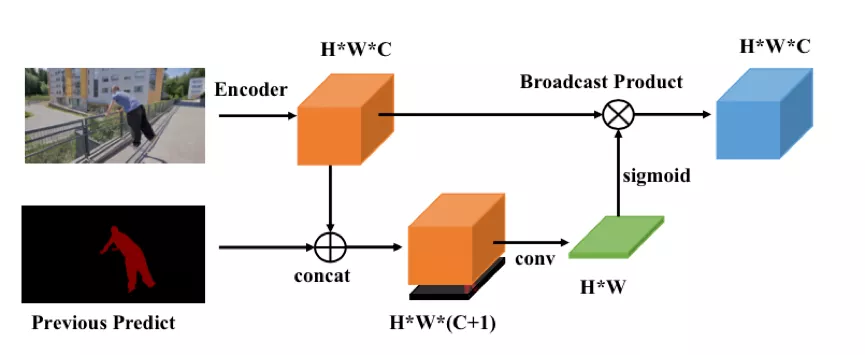
具体的方法如下图所示:
- 当前帧的特征和前一帧的预测 mask 在 channel 维度上做 concat,得到 HxWx (c+1) 的特征;
- 通过卷积将特征压缩为 HxW;
- 用 sigmoid 函数将 HxW 的特征,压缩范围,作为空间 attention;
- 把 attention 乘到原特征上,作为空间约束。
下图为空间 attention 的可视化结果,可以看到大致对应了前景的位置。

2. 增强 decoder
达摩院引入了语义分割中的感受野增强技术 ASPP 和精细化分割的微调(refinement)模块。ASPP 作用于 memory 读取后的特征,用于融合不同感受野的信息,提升对不同尺度物体的处理能力。
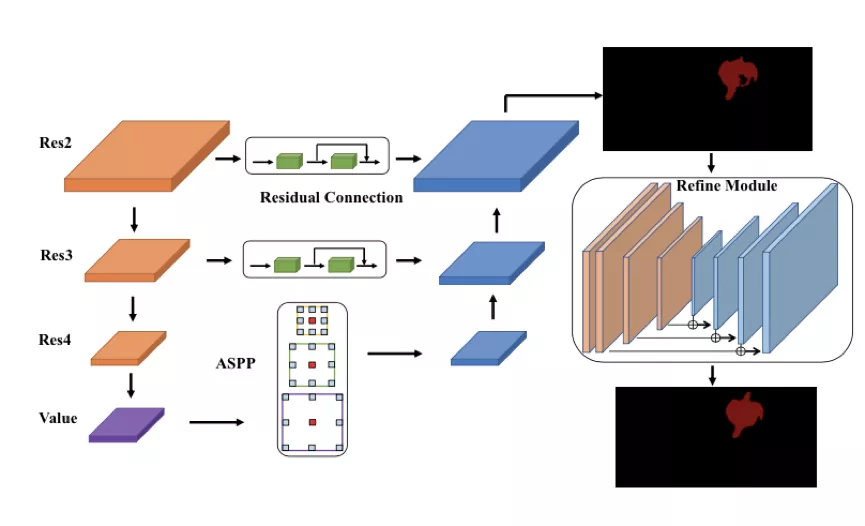
3. 训练策略
达摩院提出了一个简单但是有效的训练策略,减少了训练阶段和测试阶段存在的差异,提升了最终效果。
原始 STM 训练时,会随机从视频中采样 3 帧。这三帧之间的跳帧间隔,随着训练逐渐增大,目的是增强模型鲁棒性。但达摩院发现,这样会导致训练时和测试时不一致,因为测试时,是逐帧处理的。为此,在训练的最后阶段,达摩院将跳帧间隔重新减小,以保证和测试时一致。
其他
backbone: 达摩院使用了 ResNeST 这个比较新的 backbone,它可以无痛替换掉原 STM 的 resnet。在结果上有比较明显提升。
测试策略: 达摩院使用了多尺度测试和 model ensemble。不同尺度和不同 model 的结果,在最终预测的 map 上,做了简单的等权重平均。
显存优化: 达摩院做了一些显存优化方面的工作,使得 STM 在多目标模式下,可以支持大尺度的训练、测试,以及支持较大的 memory 容量。
数据: 训练数据上,达摩院使用了 DAVIS、Youtube-VOS,以及 STM 原文用到的静态图像数据库。没有其他数据。
结果
达摩院的模型,最终在 test-challenge 上取得了 84.1 的成绩。
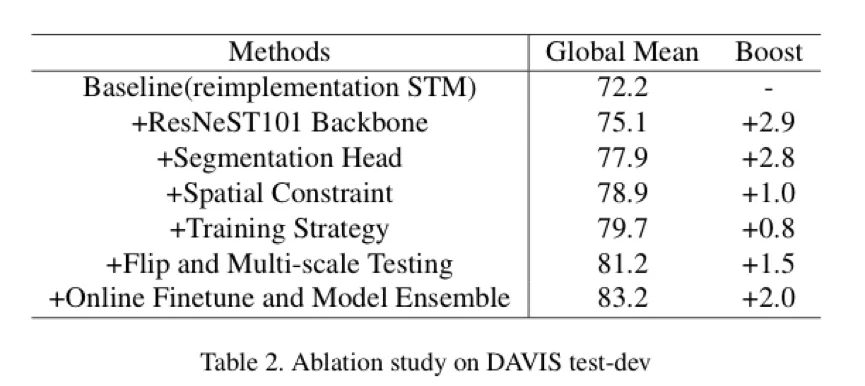
在 test-dev 上的消融实验。达摩院复现的 STM 达到了和原文一致的结果。在各种 trick 的加持下, 得到了 11 个点的提升。
随着互联网技术、5G 技术等的发展,短视频、视频会议、直播的场景越来越多,视频分割技术也将成为不可或缺的一环。比如,在视频会议中,视频分割可以精确区分前背景,从而对背景进行虚化或替换;在直播中,用户只需要站在绿幕前,算法就实时替换背景,实现一秒钟换新直播间;在视频编辑领域,可以辅助进行后期制作。
参考
- Oh SW, Lee JY, Xu N, Kim SJ. Video object segmentation using space-time memory networks. InProceedings of the IEEE International Conference on Computer Vision 2019
- Wang X, Girshick R, Gupta A, He K. Non-local neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition 2018
“新内容 新交互” 全球视频云创新挑战赛算法挑战赛道
本届全球视频云创新挑战赛是由阿里云联手英特尔主办,与优酷战略技术合作,面向企业以及个人开发者的音视频领域的挑战赛。算法挑战赛道聚焦视频人像分割领域,视频分割将传统图像分割问题延伸到视频领域,可服务于视频理解处理和编辑等任务。
算法赛道描述
本次大赛提供一个大规模高精度视频人像分割数据集,供参赛选手训练模型。不同于传统的二值分割目标(即人像区域标注为 1,其他区域标注为 0),本竞赛重点关注分割各个不同的人象实例,目标是从视频中精确、稳定分割出显著的(单个或多个)人体实例,以及其相应附属物、手持物。
本次比赛分为初赛数据集和复赛数据集。复赛数据集等初赛结束后公布,复赛中也可以使用初赛数据集。
初赛环节提供训练集供选手下载,训练数据集共 1650 段视频。训练集中每个样本由 RGB 图像序列和掩码图像序列组成,RGB 图像序列为原始视频图像序列,格式为 jpg 文件;掩码图像为人体分割的真值 (ground-truth),格式为 png 文件,掩码图像中不同的像素值表示不同的人体实例,0 为背景区域,非 0 为前景区域(例如 1 为人像 1,2 为人像 2)。RGB 和 png 文件是一一对应关系。数据集每个视频的长度为 80 帧~150 帧,每个视频的分辨率不完全相同。预赛的测试数据为 48 段视频。测试集只提供 RGB 图像序列。如出现多个人像实例,每个人像可以任意顺序标注,评测时将被独立计算。
本次比赛允许参数选手使用其他公开数据集和公开模型,但参赛选手的模型必须满足能在限定时间内复现的要求,复现精度小于规定误差。
评估标准
对于算法恢复的视频结果,本次比赛采用 Mean J And F 做为评价指标。J 为描述分割人体区域精度的 Jaccard Index,F 为描述分割人体的边界精确度。具体请参照参考文献 1。每个视频允许选手最多输出 8 个人物分割结果,选手分割结果与真值先进行 IOU 匹配,找到对应的人物后,根据该结果进行评分。多余的分割结果,没有惩罚。如果超过 8 个区域,整个视频结果无效。
奖项设置
冠军:1 支队伍,奖金 9 万人民币,颁发获奖证书
亚军:2 支队伍,奖金 3 万人民币,颁发获奖证书
季军:3 支队伍,奖金 1 万人民币,颁发获奖证书
Cooper Lake 最佳实践:3 支队伍,奖金 2 万人民币,颁发获奖证书
此外,复赛审核通过的排名前 12 队伍,可进入阿里云校招绿色通道。
视频云大赛正在火热报名中
扫码或点击下方链接,一起驱动下一代浪潮!
https://tianchi.aliyun.com/competition/entrance/531873/introduction


 浙公网安备 33010602011771号
浙公网安备 33010602011771号