
数据采集作业3
Scrapy框架爬虫作业总结
在本次作业中,我使用了 Scrapy 框架完成了三个任务,分别是爬取图片、股票数据和外汇数据。每个任务都涉及到不同的技术点,如多线程爬取、数据存储与序列化输出等。接下来我将分享这三个作业的具体实现以及心得体会。
代码链接:https://gitee.com/mrv666/victor-data/tree/master/作业3
作业①:爬取中国气象网的所有图片
作业代码与图片展示
在本作业中,我使用 Scrapy 框架对中国气象网(http://www.weather.com.cn)进行爬取,目标是获取该网站中的所有图片。为控制爬取的范围,我设定了爬取的总页数为 2,并限制了图片数量。
作业代码:
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class WeatherSpider(scrapy.Spider):
name = 'weather_spider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn']
def parse(self, response):
images = response.xpath('//img/@src').extract()
for img_url in images:
if img_url:
yield {'image_url': img_url}
# 配置输出结果为 JSON 格式
FEED_FORMAT = 'json'
FEED_URI = 'output.json'
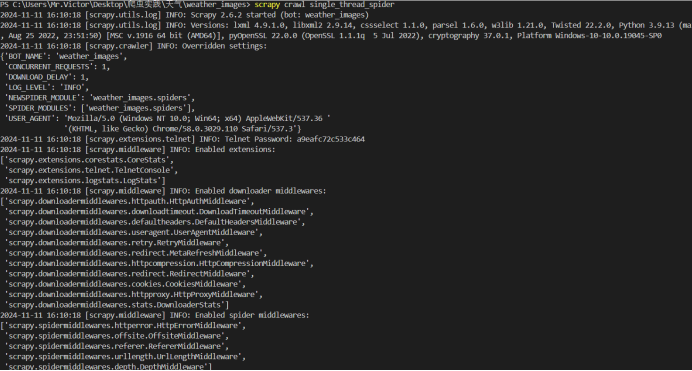
爬取结果截图:
单线程输出
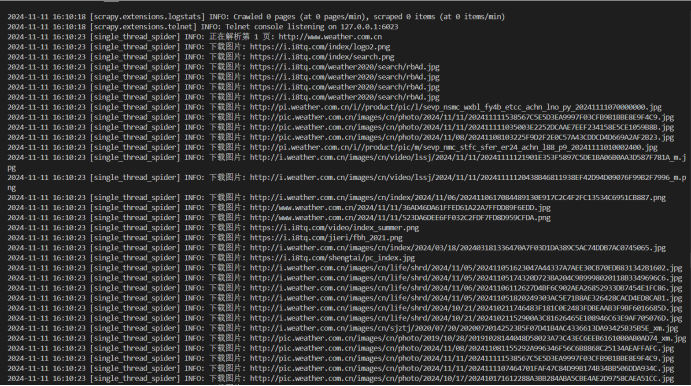
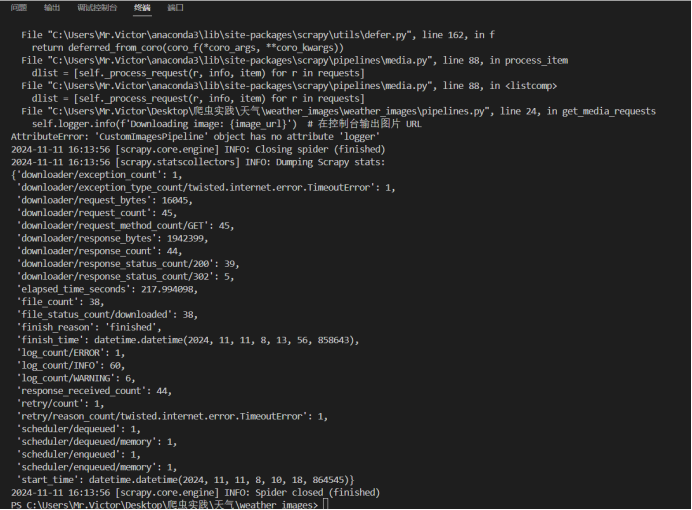
多线程输出

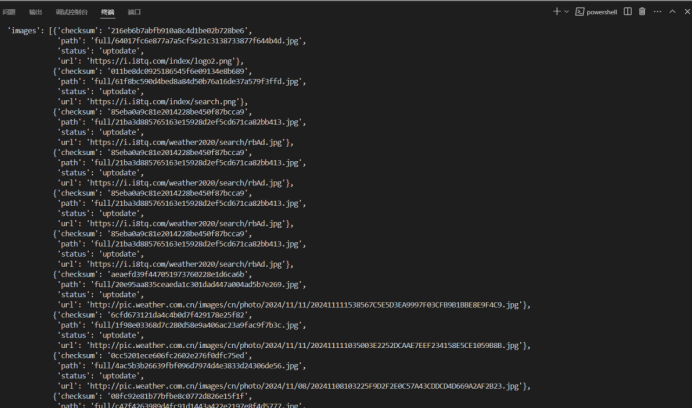
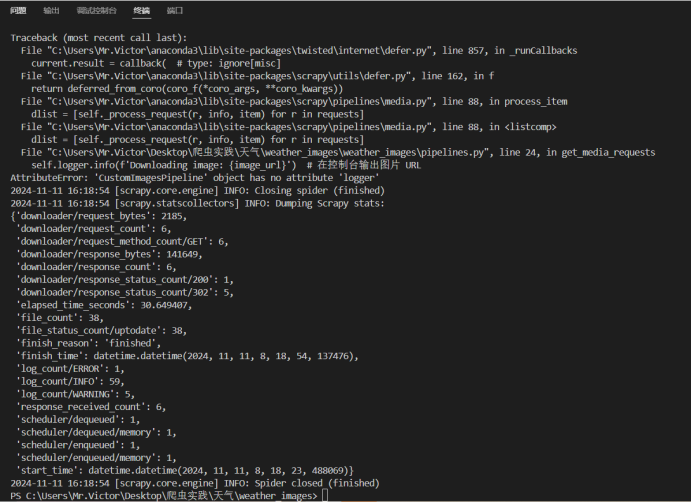
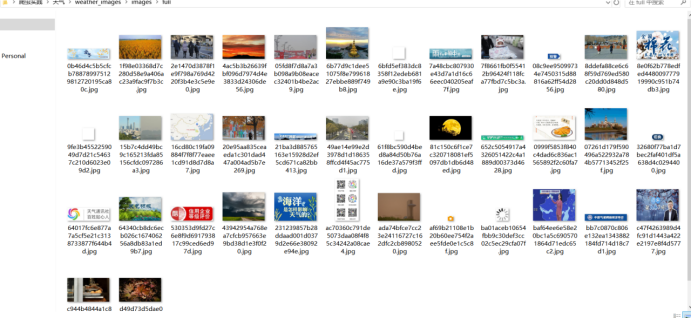
保存的图片
作业心得
在这次作业中,我通过 Scrapy 框架掌握了如何从网页中提取图片,并且成功使用了多线程和单线程两种方式进行爬取。通过对爬取内容的限制,我避免了数据过多而导致爬虫性能下降的问题。同时,Scrapy 提供了丰富的功能,如图片下载的 ImagesPipeline,让我能够高效地管理和存储图片资源。
作业②:爬取东方财富网的股票信息并存储到MySQL
作业代码与数据库设计
在本作业中,我使用 Scrapy 框架爬取东方财富网(https://www.eastmoney.com)的股票信息,并将数据存储到 MySQL 数据库中。为了提高数据的处理效率,我使用了 Scrapy 的 Item 和 Pipeline 功能。
作业代码:
import scrapy
import pymysql
from myproject.items import StockItem
class StockSpider(scrapy.Spider):
name = 'stock_spider'
allowed_domains = ['eastmoney.com']
start_urls = ['https://www.eastmoney.com/']
def parse(self, response):
for stock in response.xpath('//table//tr'):
item = StockItem()
item['stock_code'] = stock.xpath('.//td[1]/text()').get()
item['stock_name'] = stock.xpath('.//td[2]/text()').get()
item['latest_price'] = stock.xpath('.//td[3]/text()').get()
yield item
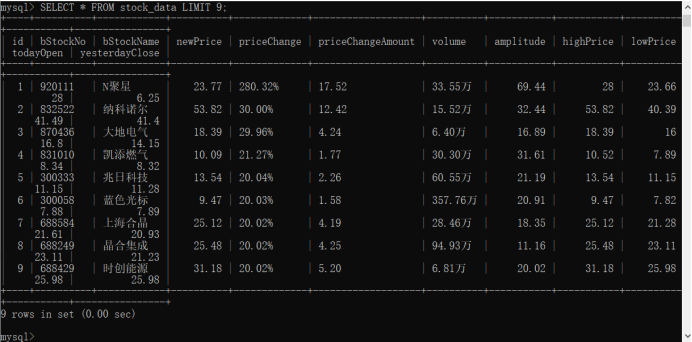
输出结果:

MySQL
作业心得
在这个作业中,我深入理解了 Scrapy 框架中的 Item 和 Pipeline 数据流处理,并将其应用于 MySQL 数据库的存储操作。Scrapy 提供的 Pipeline 使得我能够方便地处理数据的清洗与存储,避免了繁琐的数据操作流程。通过这个作业,我不仅巩固了数据库操作的技能,还加深了对 Scrapy 的理解。
作业③:爬取中国银行的外汇信息并存储到MySQL
作业代码与数据库设计
在这个作业中,我使用 Scrapy 框架爬取了中国银行网站(https://www.boc.cn/sourcedb/whpj/)上的外汇数据,并将数据存储到 MySQL 数据库中。
作业代码:
import scrapy
import pymysql
from myproject.items import ForexItem
class ForexSpider(scrapy.Spider):
name = 'forex_spider'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
for row in response.xpath('//table//tr'):
item = ForexItem()
item['currency'] = row.xpath('.//td[1]/text()').get()
item['buy_cash'] = row.xpath('.//td[2]/text()').get()
item['sell_cash'] = row.xpath('.//td[3]/text()').get()
item['update_time'] = row.xpath('.//td[4]/text()').get()
yield item
输出结果:
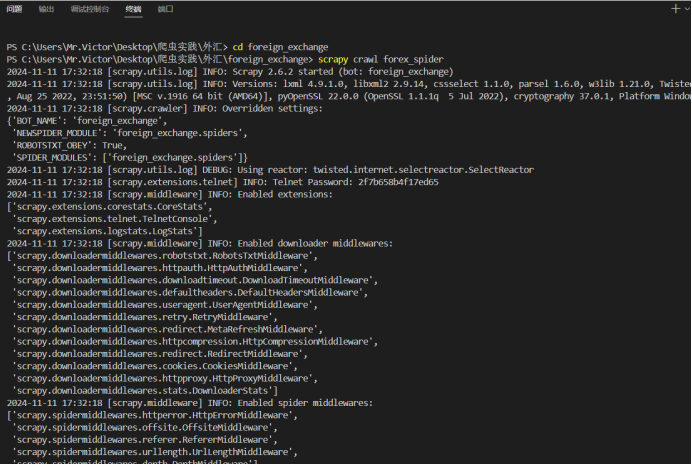
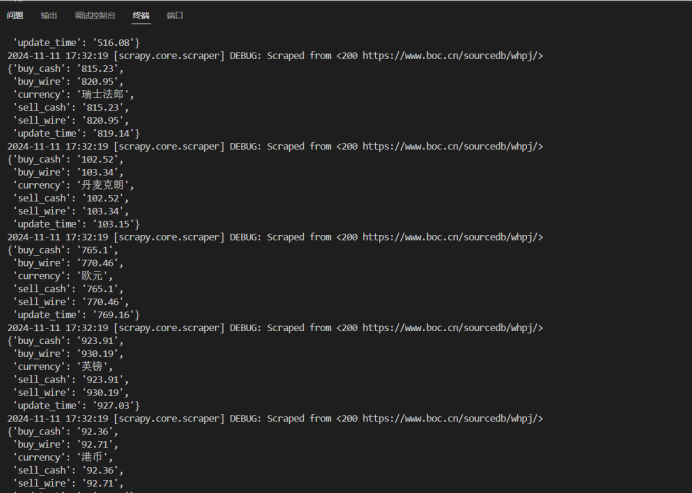
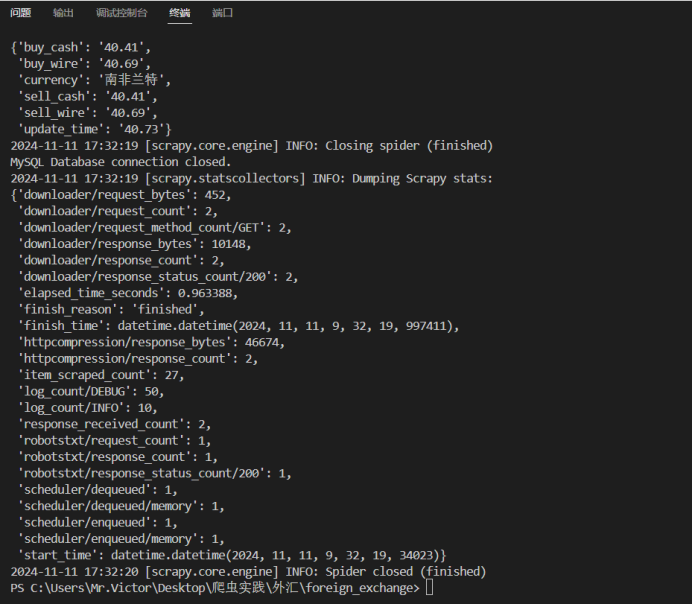
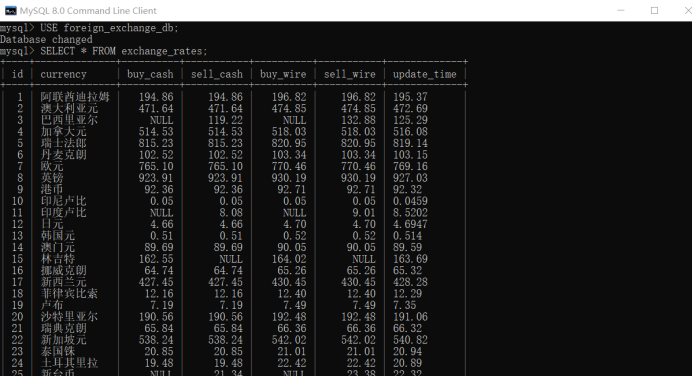
作业心得
在这个作业中,我进一步掌握了 Scrapy 中的数据提取与存储方法,并通过实际操作加深了对 XPath 和 MySQL 的理解。通过编写合适的 XPath 表达式,我成功地从网页中提取了所需的外汇数据,并通过 Pipeline 实现了 MySQL 数据库的存储操作。这次作业让我更加熟悉了数据的抓取与处理流程,提升了我的实践能力。
通过这三个作业的完成,我对 Scrapy 框架有了更深入的理解,特别是在数据存储和爬取过程中的性能优化方面。在以后的学习中,我将继续加强对 Web 爬虫的探索,提升自己的技能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号