SQL Server 锁升级(Lock Escalations)
在今天的文章里,我想谈下SQL Server里锁升级(Lock Escalations)。锁升级是SQL Server使用的优化技术,用来控制在SQL Server锁管理里把持锁的数量。我们首先用SQL Server里所谓的锁层级(Lock Hierarchy )开始,因为那是在像SQL Server的关系数据库里,为什么有锁升级概念存在的原因。
锁层级(Lock Hierarchy )
下图展示了SQL Server使用的锁层级:
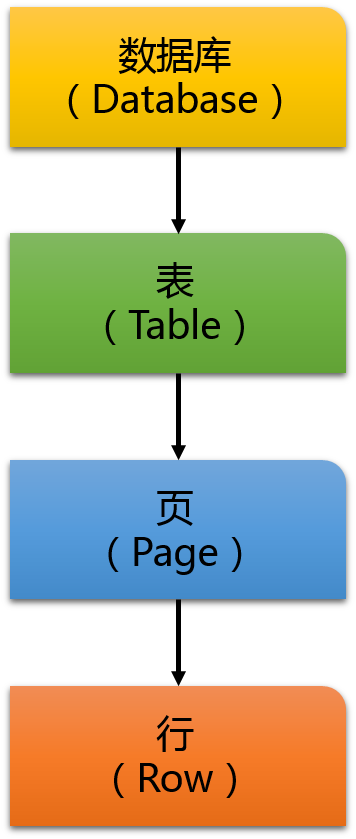
从图里可以看到,锁层级开始于数据库层级,向下至行层级。在数据库本身层级,你一直有一个共享锁(Shared Lock (S) )。当你的查询连接到一个数据库(例如USE MyDatabase),共享锁会阻止数据库删除,或者在那个数据库上还原备份。当你进行一个操作时,在数据库层级下,在表上,在页上,在记录上都会有锁。
当你执行一个SELECT语句,在表和页上会有一个意向共享锁(Intent Shared Lock (IS) ),在记录本身上有共享锁(Shared Lock (S) )。当你进行数据修改语句(INSERT,UPDATE,DELETE),在表和页上会有一个意向排它或更新锁( Intent Exclusive or Update Lock (IX or IU) ),在改变的记录上有排它或更新锁(Exclusive or Update Lock (X or U) )。当多个线程尝试在锁层级里并发获取锁时,SQL Server会一直获取从头到脚的锁来阻止所谓的竞争危害。当你对表进行20000条记录的删除操作时,现在想象下这个锁层级会是什么样的?我们来假定记录是400 bytes长,这就意味这在8kb的页里刚好有20条记录:
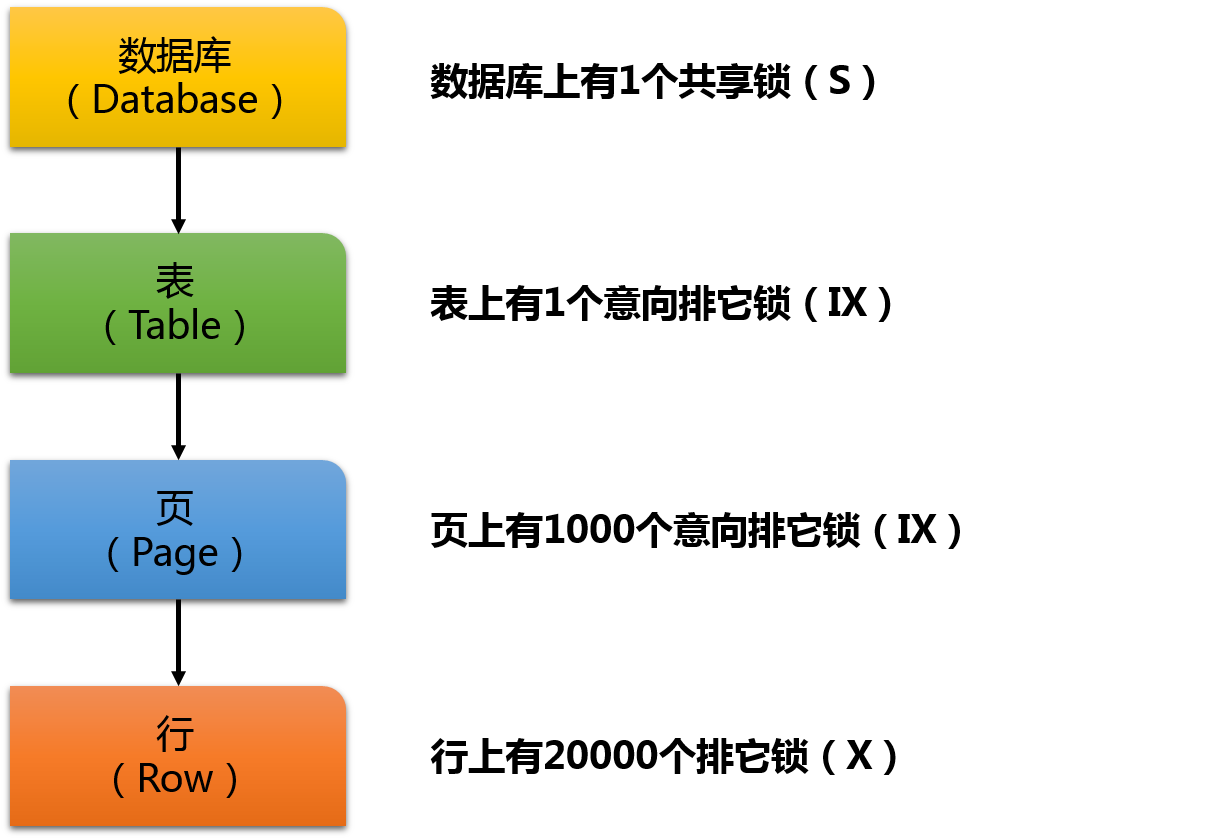
在数据库上你有1个共享锁(S),在表上有1个意向排它锁(IX),在页上有1000个意向排它锁(IX)(20000条记录散布在1000个页上),最后在记录本身你有20000个排它锁(X)。对于DELETE操作总计你获取了21002个锁。在SQL Server里每个锁需要96 bytes的内存,因此对这个简单的查询需要1.9MB的锁。当你并行执行多个查询时,这个不会无限扩展。因此,SQL Server现在用所谓的锁升级(Lock Escalation)实现。
锁升级(Lock Escalations)
在你的锁层级里一旦有超过5000个锁,SQL Server会升级这么多的精细粒度(fine-granularity)的锁为简单的粗粒度(coarse-granularity)的锁。默认情况下,SQL Server“总是”升级到表层级。这意味着你的锁层级从刚才例子的样子,在锁升级成功执行后,变成如下的样子:

如你所见,在表本身上你只有一个大锁。在DELETE操作的情况下,在表层级你有一个排它锁(X)。这会以负面伤及你数据库的并发。在表层级把持一个排它锁(X)意味者没有其他回话可以访问那个表——每个其它查询会阻塞。当你在可重读隔离级别(Repeatable Read Isolation Level)运行你的SELECT语句,你也在把持你的共享锁(S)直到事务结束,这也就是说只要你读超过5000条记录就会发生锁升级。这里的结果是一个共享锁(S)在表本身!你的表只是暂时只读,因为在表上每个其它数据修改都会阻塞!
这里还有个误解——SQL Server会锁升级从行层级到页层级,最后到表层级。错了!在SQL Server里没有这样的代码路径存在!默认情况下,SQL Server总是会直接升级到表层级。到页层级的升级策略不存在。如果你的表被分区了(只针对企业版本的SQL Server),那样的话,你可以配置升级到分区层级。但这里你必须非常仔细测试你的数据访问模式,因为锁升级到分区层级会引起死锁。因此这个选项默认是没启用的。
自SQL Server 2008开始,你可以控制SQL Server如何进行锁升级——通过ALTER TABLE语句和LOCK_ESCALTATION属性。有3个可用选项:
- TABLE
- AUTO
- DISABLE
-- Controllling Lock Escalation ALTER TABLE Person.Person SET ( LOCK_ESCALATION = AUTO -- or TABLE or DISABLE ) GO
默认选项是TABLE,意味着SQL Server总是执行锁升级到表层级——即使这个表已被分区。如果你的表已被分区,你想设置分区层级的锁升级(因为你已经测试了你的数据访问模式,用它你不会引起死锁),那么你可以修改选项为AUTO。AUTO意味着你的锁升级会执行到分区层级,如果表被分区的话,否则就到表层级。使用DISABLE选项你可以完全禁用那个表的锁升级。但是禁用锁升级并不是最好的选项,因为SQL Server的锁管理器会消耗大量的内存,如果你对你的查询和索引设计不深思熟虑的话。
减少锁升级
- 优先使用行版本控制跟踪标志1211。
DBCC TRACEON 1211, -1- 跟踪标志1224
- 加大阀值,减少锁升级的可能。In many cases, it is desirable to control the escalation threshold at the object level
sp_configure 'locks', 10000; GO RECONFIGURE; GO
在大多数情况下,数据库引擎使用默认的锁定和锁升级设置进行操作时提供的性能最佳。如果数据库引擎实例生成大量锁并且频繁进行锁升级,请考虑通过下列方法减少锁定:
- 对于读取操作,使用不会生成共享锁的隔离级别。
- 当 READ_COMMITTED_SNAPSHOT 数据库选项为 ON 时,使用 READ COMMITTED 隔离级别。
- 使用 SNAPSHOT 隔离级别。
- 使用 READ UNCOMMITTED 隔离级别。此隔离级别只能用于能对脏读进行操作的系统。
-
使用 PAGLOCK 或 TABLOCK 表提示,使数据库引擎使用页、堆或索引锁而不是行锁。但是,使用此选项增加了用户阻止其他用户尝试访问相同数据的问题,对于并发用户较多的系统,不应使用此选项。
还可以使用跟踪标志 1211 和 1224 来禁用所有或某些锁升级。
监控锁升级
可以使用 SQL Server Profiler Lock:Escalation 事件监视锁升级,请参阅。
锁升级的具体对象:
每个升级事件主要在单个 Transact-SQL 语句级别上操作。当事件启动时,只要活动语句满足升级阈值的要求,数据库引擎就会尝试升级当前事务在活动语句所引用的任何表中持有的所有锁。如果升级事件 在语句访问表之前启动,则不会尝试升级该表上的锁。如果锁升级成功,只要表被当前语句引用并且包括在升级事件中,上一个语句中事务获取的、在事件启动时仍 被持有的锁都将被升级。
例如,假定某个会话执行下列操作:
-
开始一个事务。
-
更新 TableA。这将在 TableA 中生成排他行锁,直到事务完成后才会释放该锁。
-
更新 TableB。这将在 TableB 中生成排他行锁,直到事务完成后才会释放该锁。
-
执行联接 TableA 和 TableC 的 SELECT 语句。查询执行计划要求先从 TableA 中检索行,然后才从 TableC 中检索的行。
-
SELECT 语句在从 TableA 中检索行时(此时还没有访问 TableC)触发锁升级。
如果锁升级成功,只有会话在 TableA 中持有的锁才会升级。这包括来自 SELECT 语句的共享锁和来自上一个 UPDATE 语句的排他锁。由于决定是否应进行锁升级时只考虑会话在 TableA 上为 SELECT 语句获取的锁,所以一旦升级成功,会话在 TableA 上持有的所有锁都将被升级到该表上的排他锁,而 TableA 上的所有其他较低粒度的锁(包括意向锁)都将被释放。
不会尝试升级 TableB 上的锁,因为 SELECT 语句中没有 TableB 的活动引用。同样,也不会尝试升级 TableC 上尚未升级的锁,因为发生升级时尚未访问该表。
小结
在SQL Server里锁升级基本是个噩梦。你如何才能从表里删除5000行记录而不产生锁升级?你可以临时禁用锁升级,但这里你要非常仔细。另外一个方法(我推荐的)是让你的DELETE/UPDATE语句在一个循环里,作为不同,独立的事务:DELETE/UPDATE少于5000行记录,这样的话你可以阻止锁升级。这样做的好处,你庞大的事务会分解为多个小事务,但也会让你的事务日志更多,带来自动增长问题。
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2014/02/25/lock-escalations/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号