MySQL DDL的成本高低
DDL(Data Definition Language)
众所周知,DDL定义了数据在数据库中的结构、关系以及权限等。比如CREATE,ALTER,DROP等等。
本期我们讨论MySQL 8.0 (使用InnoDB存储引擎)在修改表结构时,究竟会发生什么?
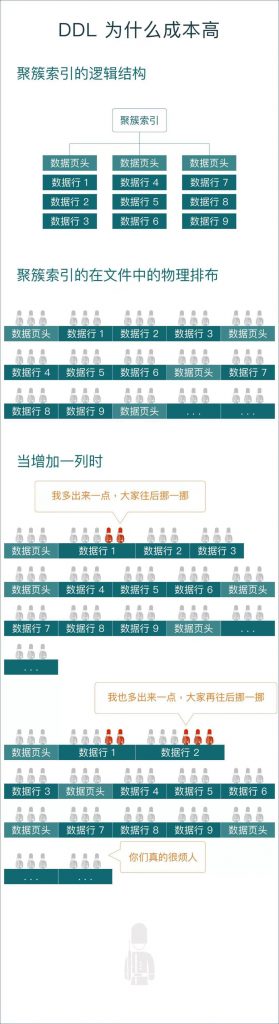
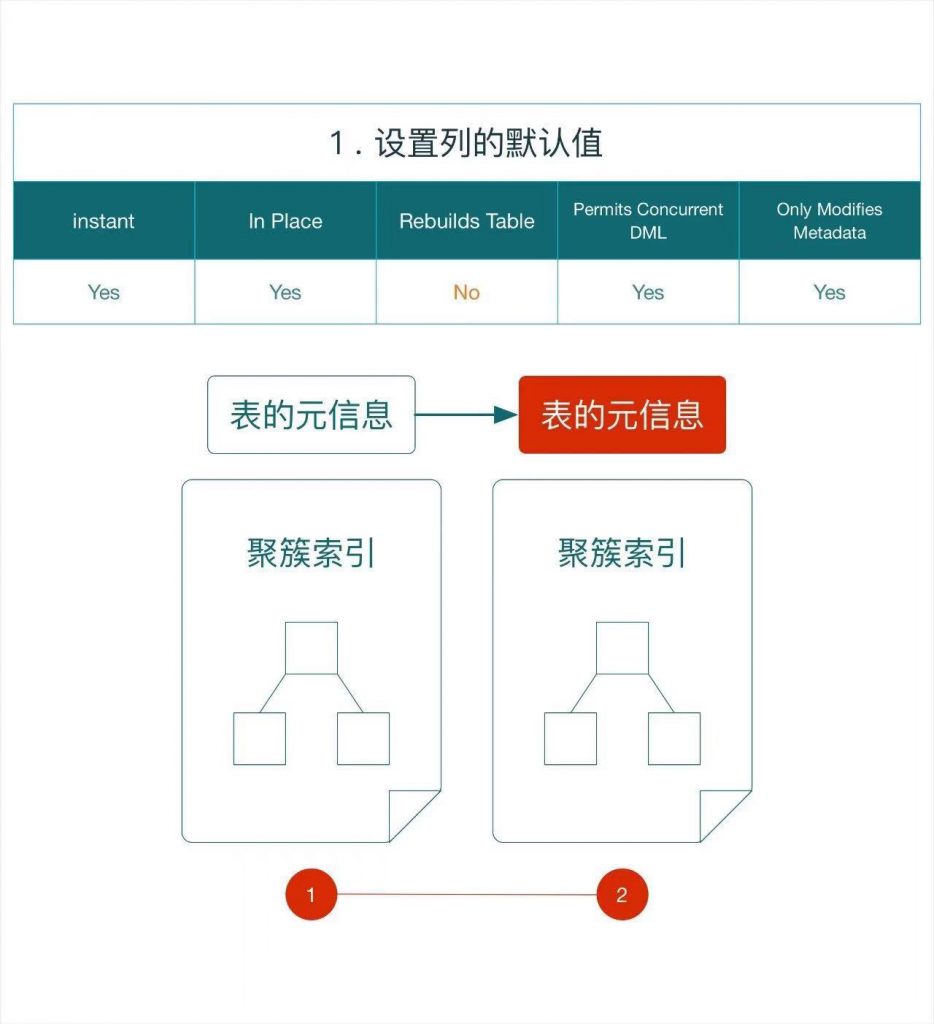
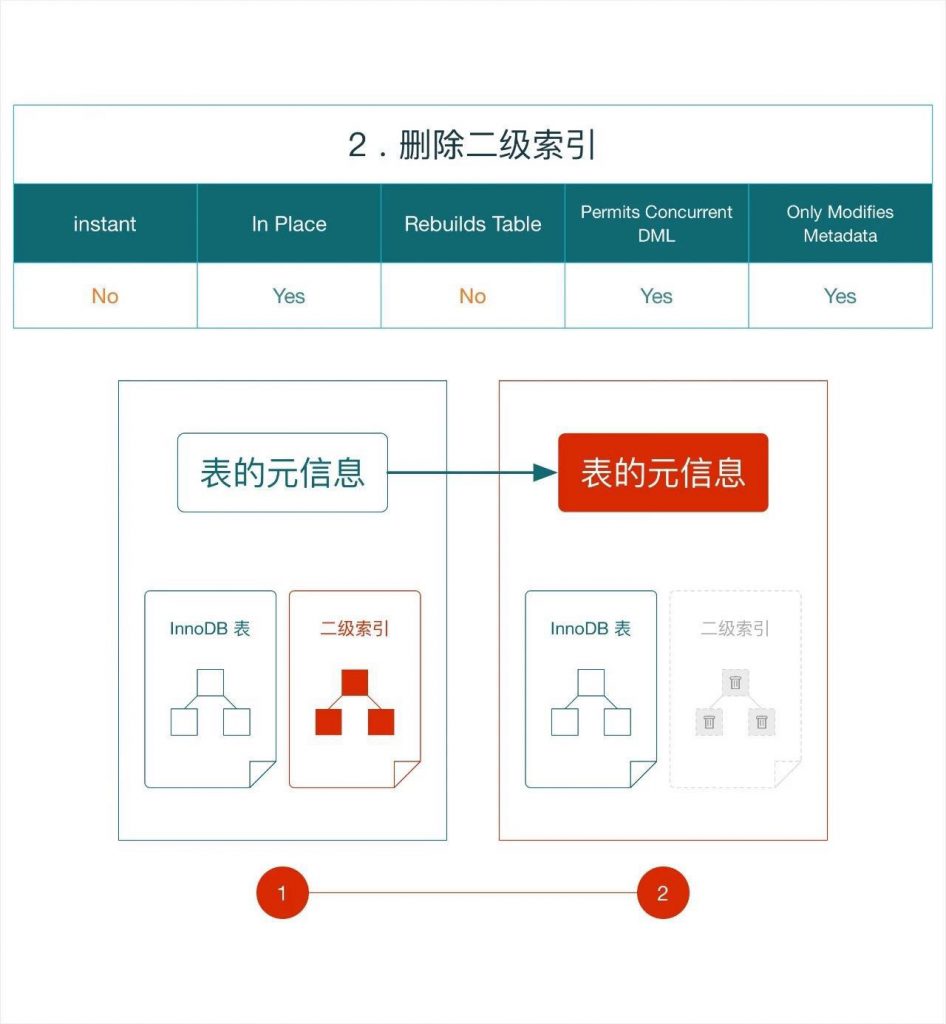
e.g. ALTER TABLE `t1` DROP INDEX `idx1`;
e.g. ALTER TABLE `t1` ADD INDEX `idx1` (`name`(10) ASC) ;
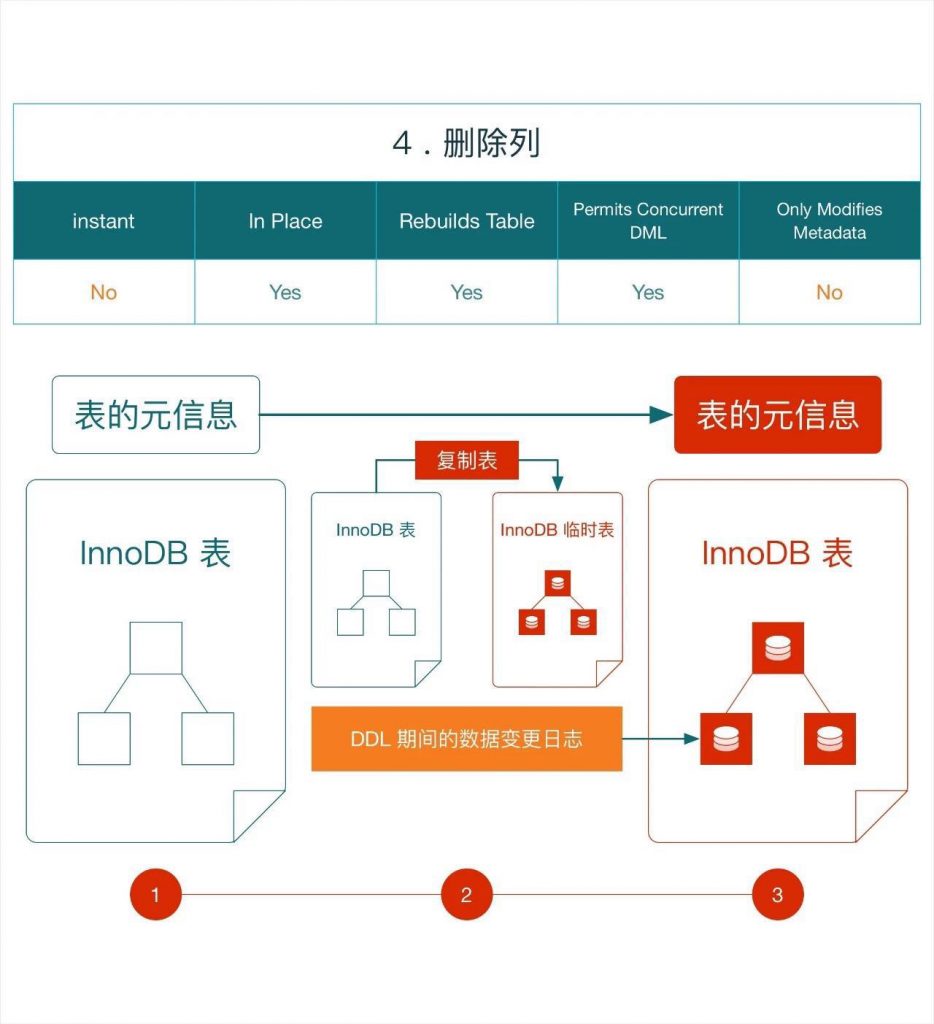
e.g. ALTER TABLE `t1` DROP COLUMN `c1`;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号