SQL Server 2019 新函数Approx_Count_Distinct
2019年11月4日微软发布了2019正式版,该版本有着比以往更多强大的新功能和性能上的优势,可参阅SQL Server 2019 新版本。
SQL Server 2019具有一组丰富的增强功能和新功能。特别是,数据库引擎中有许多新功能改进,以实现更好的性能和查询调整。
一些重要的增强功能包括:
- 行模式内存授予
- 行存储上的批处理模式
- APPROX_COUNT_DISTINCT
- 兼容性级别提示
- 列存储索引的增强,例如在线重建,压缩估计
- 配置管理器中的证书管理
- 数据库分类改进
在本文中,我们将讨论Approx_Count_Distinct函数。该功能以前在Azure SQL数据库中可用,但现在已随SQL Server 2019启动。
在日常环境中,当我们处理数据时,数据库中有许多表具有重复的值。例如,假设一个客户表保存了从商店购买产品的所有客户的记录。众所周知,客户可以多次购买产品,并且每次客户访问商店并购买商品时,都会在客户表中进行输入。
现在,假设我们想从表中了解唯一客户的信息,因此直到现在,对于SQL Server 2017,我们都使用Count different函数来获取唯一记录。计数不同功能的格式如下。
首先,让我们准备具有数百万行的示例数据库和表,然后为您介绍SQL Server 2019 Approx_count_distinct中的新函数。
在本文中,我们将需要为我将使用ApexSQL Generate的测试数据生成数百万行。
出于演示目的,让我们在数据库中创建两个表。
- 员工表:
CREATE Table Employees ( EMPId int identity primary key, EMP_name nvarchar(50) Null
)
- 插入200万行随机数据
- 我们将在表中插入任何Null值。
- EmployeesWithNull :。
CREATE Table EmployeesWithNull ( EMPId int identity primary key, EMP_name nvarchar(50) Null)
- 在此表中插入200万条记录。
- 我们将在此表中插入NULL值
Approx_Count_Distinct函数概述
SQL Server 2019引入了新函数Approx_Count_distinct以提供行的近似计数。Count(distinct())函数提供实际的行数。在实际情况下,如果我们得到近似值,则也可以使用不同的值。此新功能提供了大约的行数,对于大量的行很有用。
该函数APPROX_COUNT_DISTINCT应该使用较少的内存和CPU资源,以便可以获取数据结果而不会出现任何问题,例如溢出到磁盘或CPU峰值。这对于数十亿行的需求很有用。
根据Microsoft 文档,“函数实现可保证97%的概率内2%的错误率。”
Approx_Count_distinct的语法为APPROX_COUNT_DISTINCT(表达式)
让我们对两个计数(不同)进行一些比较。
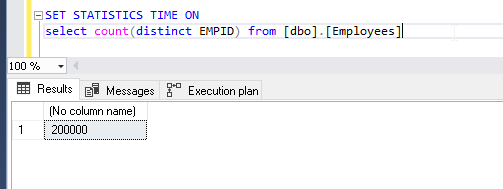
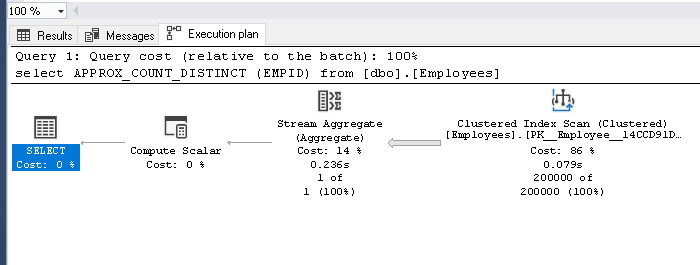
从“ dbo.employees”表中获取不同记录的数量,并查看实际的执行计划
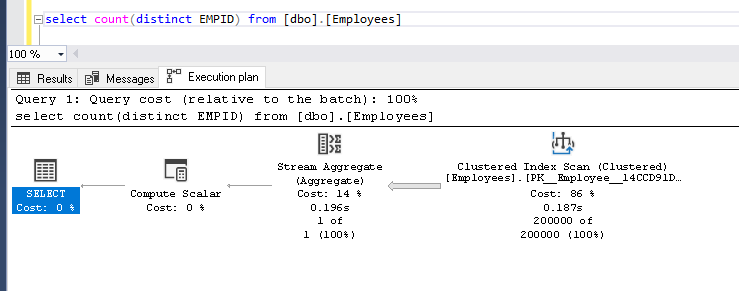
还可以从计数不同功能中查看统计信息。
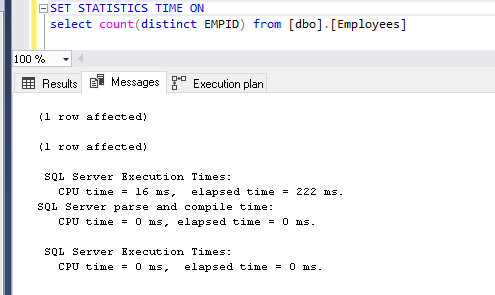
查看输出记录数。它在表中显示200万个不同的记录。
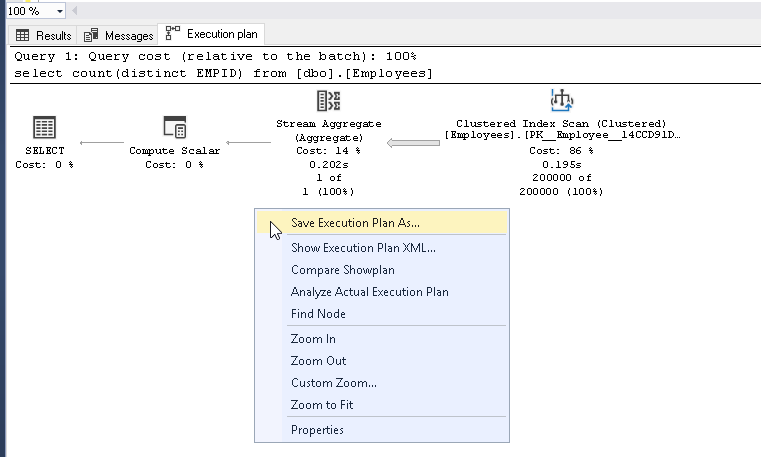
通过右键单击“将执行计划另存为”来保存执行计划,并提供保存位置。
现在使用SQL Server 2019函数APPROX_COUNT_Distinct运行以下查询。
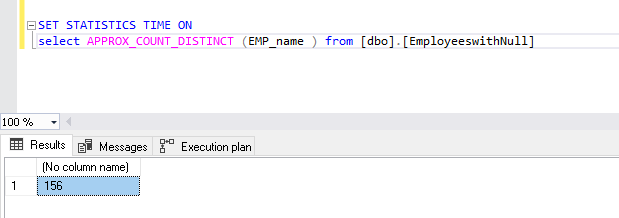
SET STATISTICS TIME ON select APPROX_COUNT_DISTINCT(EMPID) from [dbo].[Employees]
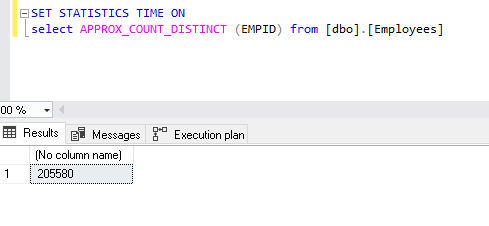
注意记录数。它表示205,580条记录,而我们的表仅包含200万行。它表明我们没有得到不同值的准确计数,而是近似值。
右键单击执行计划,然后单击“比较显示计划”
在“比较显示计划”中,提供先前保存的执行计划路径
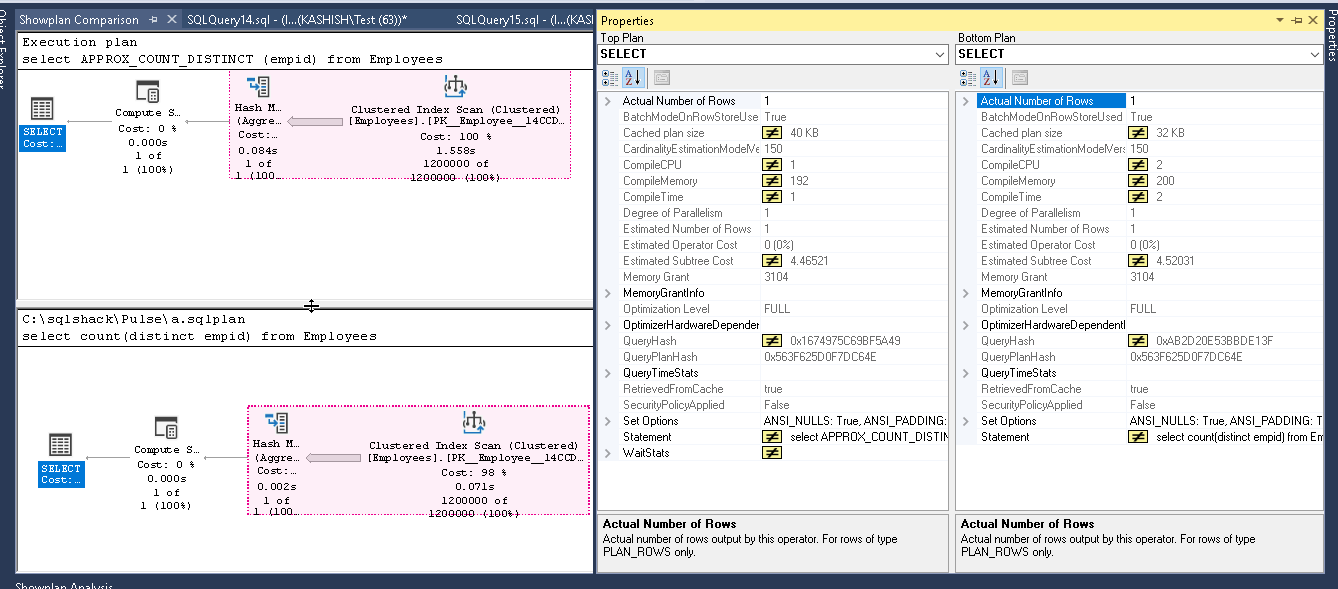
现在,我们可以看到Count(离散)和Approx_Count_distinct的比较。两种执行计划看起来都一样。在Approx_Count_distinct中,与使用count(distinct)的0.195秒相比,可以看到聚簇索引扫描时间为0.079秒的微小改进。
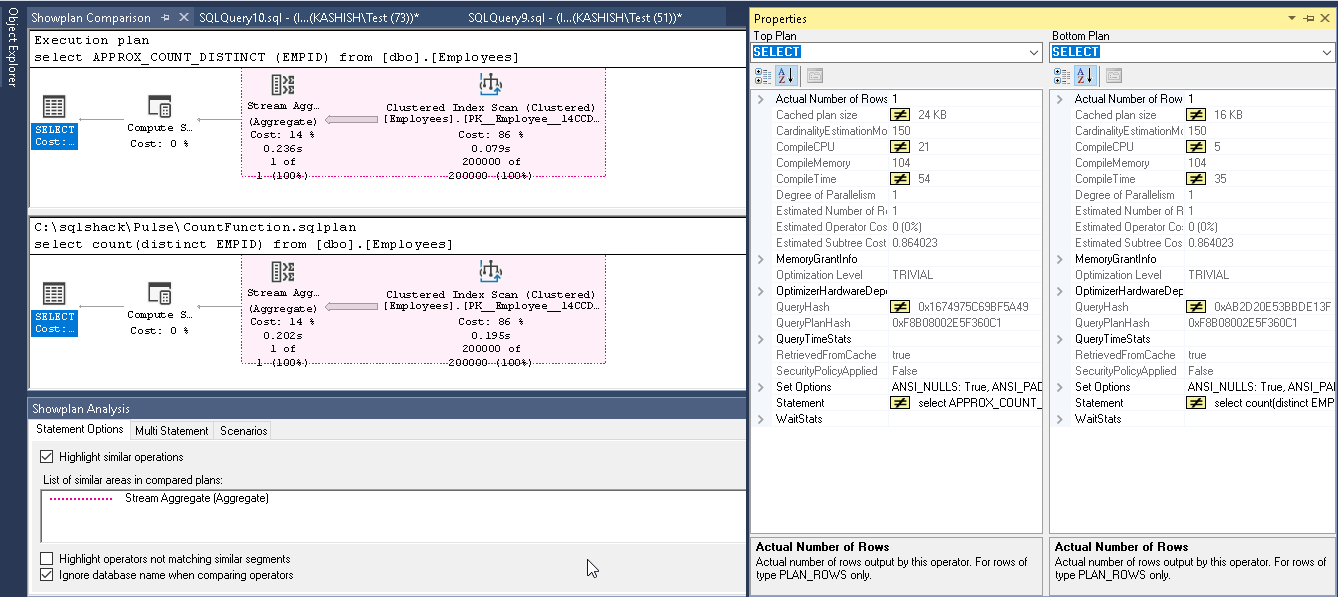
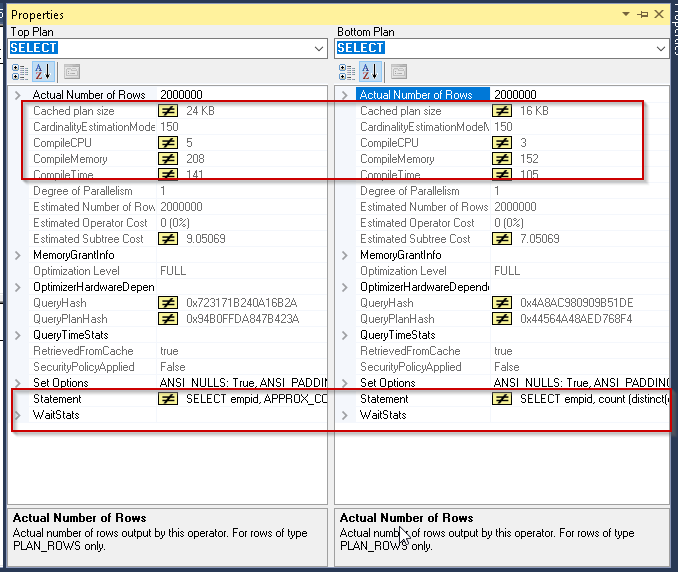
现在,如果我们比较两个执行计划中的select运算符,则在下面的结果集中,我们在Approx_count_distinct函数中看到的值有点高。例如,当我们使用新功能时,缓存计划大小,compileCPU,Compilememory,编译时间很高。
让我们在表上使用Null值执行相同的测试。

在执行计划比较报告中可以看到以下结果。
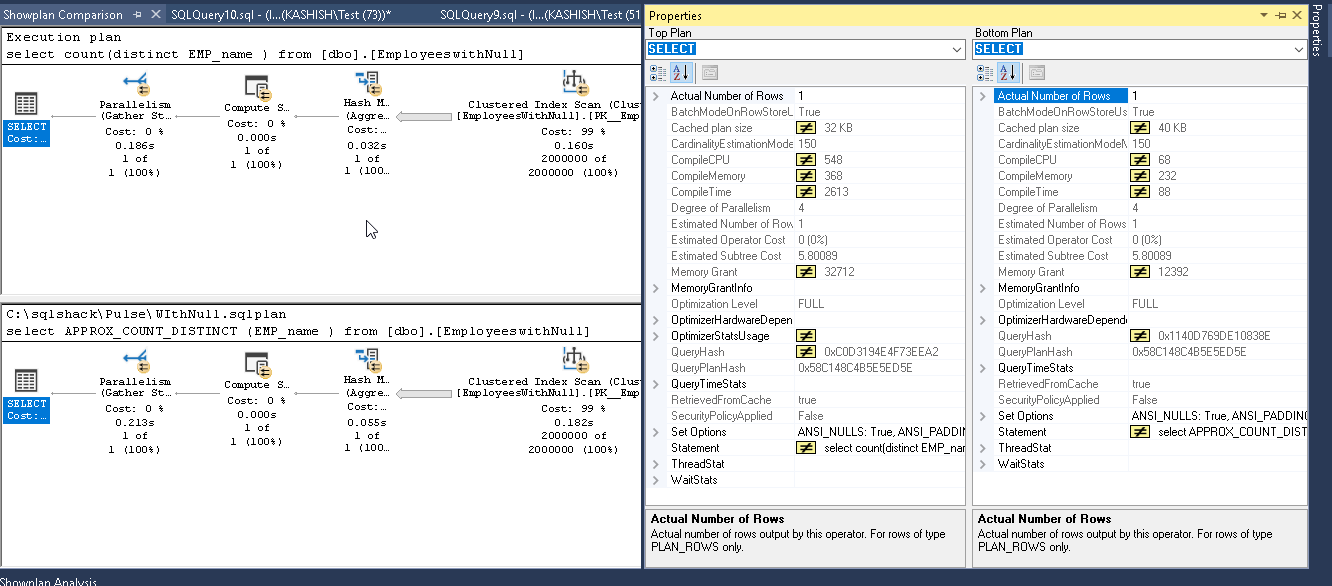
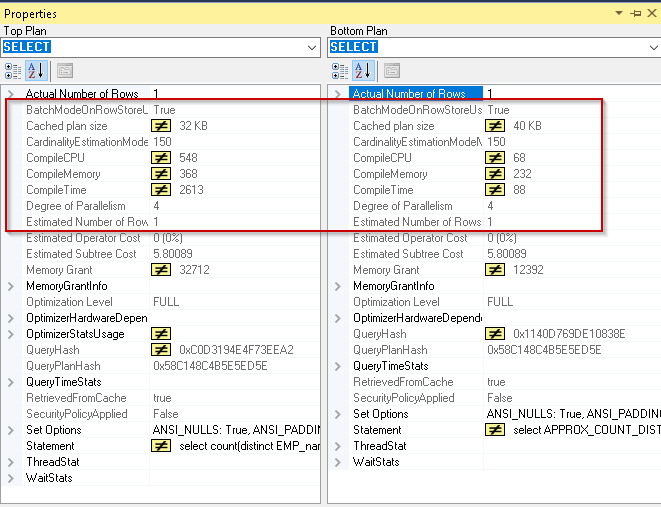
与计数不同功能相比,行计数再次高。

让我们在表中插入更多记录并刷新数据。
如果现在比较两个执行计划,则使用APPROX_COUNT_DISTINCT函数时,性能几乎不会提高。

让我们再对示例数据库WideWorldImporters进行测试。在比较报告中,我们发现使用Approx_Count_distinct时,CompileCPU,CompileMemory和CompileTime的值较少,而计数不同。
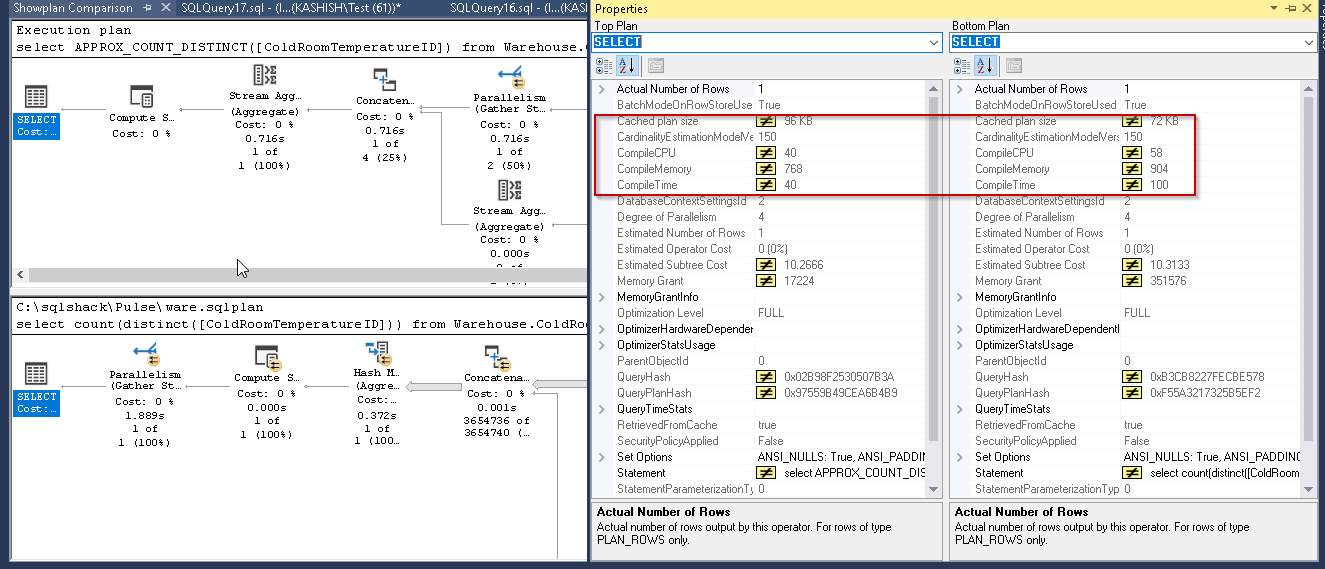
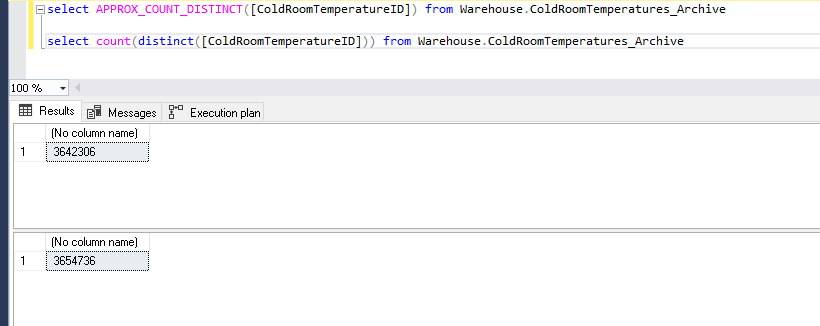
您可以在两种方法中看到行数的差异。在我的演示中,大多数时候我都看到带有新功能的高行数,但是在这里我们可以看到比实际值低的值,但比实际值低0.34%。
让我们在运行两个查询以捕获实时性能跟踪之前启动默认的扩展事件会话“标准”。从SQL Server Management Studio展开XEvent分析器,然后启动会话。
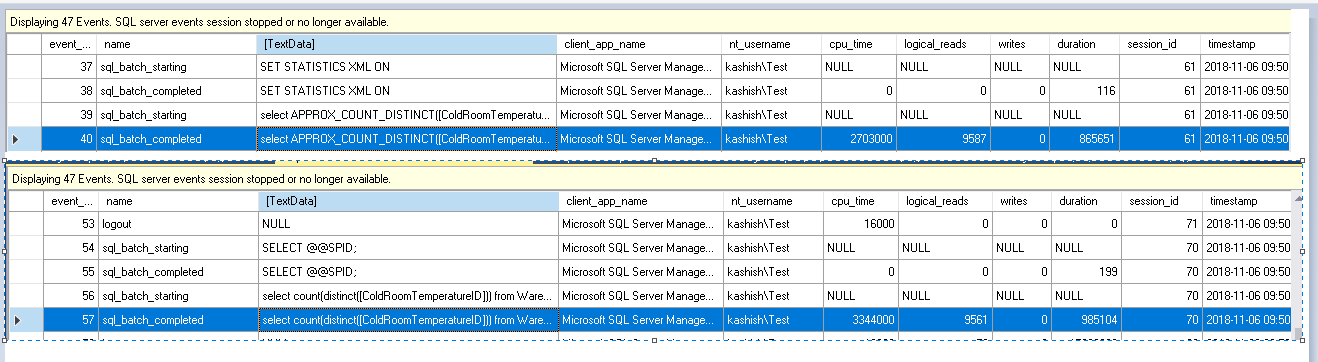
这将捕获逻辑读取,CPU时间,写入,持续时间。
我们可以注意到,在使用Approx_count_distinct时,其值与count count函数相比要低一些。
结论
我们探索了在SQL Server 2019中获得近似计数的不同非空值的新功能。在我的测试期间,我在性能方面得到了混合的结果,但是您可以尝试在更复杂的数据方案中运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号