(译)内存沉思:多个名称相关的神秘的SQL Server内存消耗者。
对于多个不同名称的内存消费者
你曾经是否想知道内存授予是什么(Memory grants )?
什么是查询执行的保留(预定)内存(QE Reservations)?
以及查询执行内存(Query Execution Memory)?
工作空间内存(Workspace memory),以及内存保留(译者注:很多地方都将Reservations译作“保留”,个人认为译作“预定”一次更为容易理解,下文中预定同义与“保留”)
就好比生活中的许多事情一样,简而言之,一句话:所以的名字都指向SQL Server中的同一个内存消费者,
查询期间的为了排序或者哈希操作(包括bulk copy和索引创建等)的内存分配
请允许我引申出来更大的话题,在一个查询执行的过程中,这个查询可能会从不同的"buckets" 或者 clerks中申请内存,(从不同地方申请内的差异)依赖于申请的内存用来做什么。
例如,一个查询在最初的解析和编译时,他需要消费编译或者是优化内存。一旦查询语句编译完成之后,他所申请的内存就会释放,
同时其对应的查询执行计划会被缓存,为此,这个执行计划会消费过程缓存内存,并且这块内存一直被占用直到服务器重启或者内存发生压力,此时,查询准备好执行。
如果查询语句发生排序或者哈希操作(连接或者组合),那么它首选会使用实现预定的内存用来存储结果或者存储Hash桶(的结果)
这个部分内存发生在查询执行期间,具体会涉及到很多内存的名称。
术语和故障诊断工具
让我们回顾一下您可能会遇到的关于这个内存消耗者的不同类别。
同样,所有这些描述了与相同内存分配相关的概念:
查询执行内存 (QE Memory):
这一项是用来强调在查询执行过程中sort/hash内存使用这个事实,同时也是查询执行期间的最大的内存消费部分。
查询内存(QE)预定或者内存预定:
当一个查询需要sort/hash操作准备内存的时候,在执行期间,他将基于包含了sort或者hash运算的原始查询计划,执行一个内存保留请求(内存预定请求),
然后查询开始执行,他请求内存,同时sqlserver将会授予这个查询部分或者是全部的内存请求,主要是依赖于服务器可用内存
有一个叫做MEMORYCLERK_SQLQERESERVATIONS的内存clerk,这个内存计数器来保留这部分内存的分配的情况。
------------------------------译者注---------------------------------
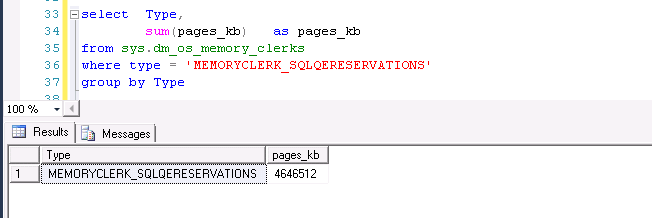
这部分内存可以从sys.dm_os_memory_clerks中查询出来,如下截图是一个存在负载的服务器的服务器上的MEMORYCLERK_SQLQERESERVATIONS分配情况
可见这部分内存还是不小的,这里是有超过4GB的MEMORYCLERK_SQLQERESERVATIONS(服务器内存32GB)
如果一个服务器没有负载的时候,这个内存的使用是很低的,甚至可以是0
--------------------------------------------------------------------------
内存授予(Memory Grants):
当SQL Server给一个请求授予请求内存的时候,称之为内存授予发生了,
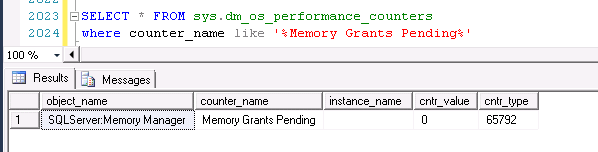
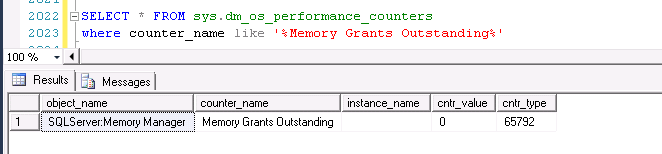
有一个性能计数器保留了已经有多少内存授予了请求内存:Memory Grants Outstanding
另外一个计数器表明有多少查询已经请求了sort/hash内存,但是出于等待状态,因为查询执行内存已经耗尽:Memory Grants Pending
这两个内存计数器显示了内存授予和内存授予的不足,也就是说,一个单独的查询可能消耗4GB的内存去执行一个排序,但这两种情况都不会被反映出来
------------------------------译者注---------------------------------
这部分内存可以理解为实时请求内存,SQL Server实时请求越多,这部分内存就越大,
比如一个Session需要20MB的运行内存,同时运行10个Session就需要200MB,同时运行100个Session就需要2000MB,当然每个Session需要的运行内存都不一样(memory grant),这里仅仅是举例
可以从sys.dm_os_memory_clerks中查询出来,如下截图是一个存在负载的服务器的服务器上的MEMORYCLERK_SQLQERESERVATIONS分配情况
可见这部分内存还是不小的,这里是有超过4GB的MEMORYCLERK_SQLQERESERVATIONS(服务器内存32GB)
如果一个服务器没有负载的时候,这个内存的使用是很低的,甚至可以是0
Memory Grants Outstanding某一个Session无法得到其申请的内存,处于等待内存状态,
SQL Server是一个自我调节(self tuning)引擎,这部分内存一般会预留的足够,正常情况下不会发生因为sql的执行缺少内存而等待的情况
凡事得分清楚轻重缓急,内存也一样分为急需的和非急需的,不能那边为了缓存数据而占据内存,而这边连实时的请求都无法响应吧。
举个不恰当的例子,再穷,可以不买房不买车,总的留够吃饭的钱吧。
其他地方的内存可以存在压力(比如数据缓存可能快速地被置换出内存),但是面对相应实时请求的内存,SQL Server留的还是比较充足的,个人很少见到因为Session等待内存而无法执行的情况。
但是话不能反过来说,不能说没有出现Memory Grants Pending,就说明内存没有压力。
----------------------------------------------------------------------------
为了观察单独的请求和他们已经申请的内存,你可以查询sys.dm_exec_query_memory_grants这个DMV
这个DMV显示的是当前运行的查询的内存授予情况,而非历史情况
另外,你可以捕获实际查询执行计划,查询其一个叫做Query plan的XML节点,他包含了内存授予的大小,
如下示例:
<QueryPlan DegreeOfParallelism="8" MemoryGrant="2009216"
另外一个DMV是 sys.dm_exec_requests,包含了一个叫做granted_query_memory的8kb为单位的列,
比如一个1000的值,意味着1000*8kb,或者说是8000kb的内存授予
工作空间内存(Workspace Memory):
这仍旧是另外一个描述同样内存的项目,
你经常会看到这个性能技术区授予Workspace Memory (KB),反映的是当前所有用来sort/hash操作的内存使用
最大工作空间内存(Maximum Workspace Memory (KB))数量是自SQL Server启动以来的最大的工作空间内存。
在我看来,工作空间内存项目是一个用来描述sqlserver7.0个sqlserver2000的内存分配的一个遗留问题,在SQLServer2005以后已经作废
资源信号量(Resource Semaphore):
为了给这个概念增加更多的复杂性,SQL Server使用一个称作信号量(semaphore)的线程同步对象来跟踪有多少已经被授予了的内存。
想法是这样的:如果sqlserver用光了workspace memory/QE memory, 那么使用out-of-memory错误来替代查询执行失败(不是直接反馈查询失败,而是等待内存)
它会促使查询等待可用内存,然后(得到可用内存之后)可以重新执行
在这个过程中,Memory Grants Pending 性能计数器开始变得有意义。
因此会在sys.dm_exec_query_memory_grants中生成wait_time_ms,granted_memory_kb = NULL, timeout_sec
顺便说一下,这个和编译内存是在SQL Server中仅有的在内存不足的情况下,会执行等待内存的两种内存。
在其他情况中,查询将会直接失败并报出701错误--内存不足。
在SQL Server中另外一种等待类型也昭示着一个查询是在等待内存授予--RESOURCE_SEMAPHORE
正如文档中所说的,这种情况发生,一个查询内存无法被立即授予归结于其他并发执行的查询。
频繁的等待和等待时间可能预示这个过多的并发查询,或者是过多的内存授予数量。
你可以在sys.dm_exec_requests这个DMW中观察Session级别的等待
为什么需要关注Memory Grants 或者 Workspace Memory 或者 Query Execution Memory或者不管你怎么称呼它。
过去几年对于性能问题的诊断过程中,我发现这是最常见的内存相关问题之一,应用程序经常执行一些看起来相当简单的查询,
却因为上执行大量的Sort或者hash操作而遭受到大量的性能破坏
那些查询不仅仅是在执行过程中消耗大量的内存,并且也会导致其他查询等待内存,这就是性能瓶颈。
使用上述我提供的工具(DWVs,性能计数器和实际执行计划),你可以查出来哪个查询是耗费了大量的内存,然后再考虑优化/重写的可能性
Sort/Hash操作产生的情景
提及查询重写,这里有一些可能会导致大量内存授予的情况
Sort操作产生的原因(包括但不限于以下几种情况)
ORDER BY (T-SQL)
GROUP BY (T-SQL)
DISTINCT (T-SQL)
Merge join操作是优化器选择的,其中合并联接的一个输入必须被排序
Hash Match操作产生的原因(包括但不限于以下几种情况)
JOIN (T-SQL) – 如果SQL选择执行一个Hash操作,典型的就是缺少合理的索引导致的一个昂贵的join操作--hash join,观察执行计划
DISTINCT (T-SQL) –Hash聚合可能会用来执行distinct操作,观察执行计划
SUM/AVG/MAX/MIN (T-SQL)– 任何聚合操作可能会导致Hash 聚合,观察执行计划
UNION – Hash聚合可能会用来做移除重复项
了解这些常见的原因可以帮助应用程序开发人员尽可能地消除对SQL Server的大量内存授予请求。
一如既往,基本的查询调优开始于检查查询是否有适当的索引,以帮助它们减少读取、尽可能减少或消除大型排序。
这里有个内存授予的博文供参考 http://blogs.msdn.com/b/sqlqueryprocessing/archive/2010/02/16/understanding-sql-server-memory-grant.aspx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号