项目报告:各模块数据流情况和资源消耗
简介:
对于写在秋招简历上的项目,本人在此进行一些讲解和分析;
其中讲解主要包括:
基于FPGA实现的多通道视频采集卡(2023年集创赛FPGA赛道题目)
多通道车载自动驾驶传感器数据采集系统(实验室项目)
UDP协议万兆以太网收发及FPGA验证(个人项目)
这三个项目之中的模块。
一些模块在多个项目中都存在,所以以模块为分栏讲解。
模块:
千兆以太网模块;
DVP相机解帧模块;
MIPI相机解帧模块;
GT高速收发器收发模块;
PCIe模块;
图像处理模块;
万兆网模块;
还在撰写中......
千兆以太网模块:
本模块存在于:
基于FPGA实现的多通道视频采集卡(2023年集创赛FPGA赛道题目)
多通道车载自动驾驶传感器数据采集系统(实验室项目)
本模块工作:
1.解包上位机发送的以太网数据帧;
2.将外部数据管理模块的数据通过以太网接口发送给上位机;
3.与上位机建立ARP连接。
资源消耗:
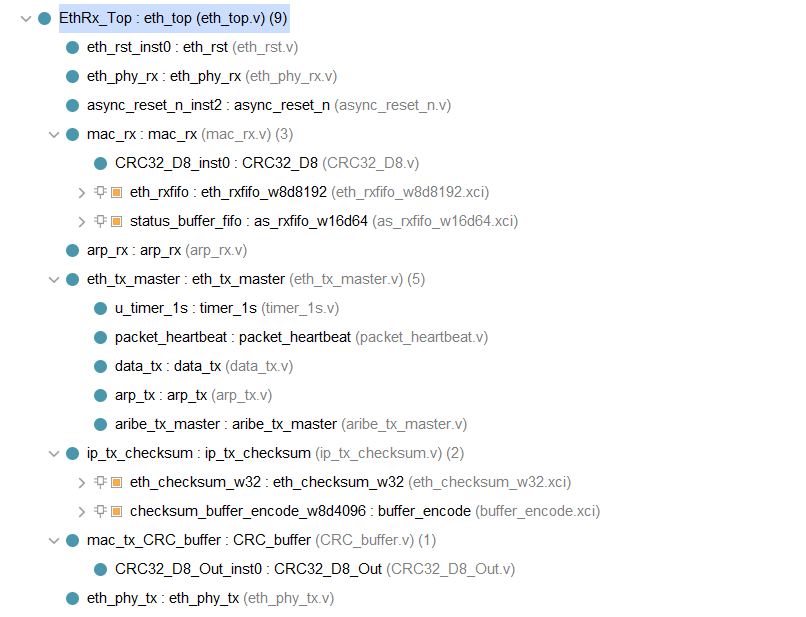

以太网模块由于编写时间较早,而且很多功能都是后续加入的,导致管理起来困难;
但细致分析的话不难发现,主要的LUT资源花费来自于对组帧和解帧的处理,这导致了需要用许多逻辑去管理;
至于BRAM在哪用掉了,在下文中见分晓。
对于接收端:
1.解析不同位置的字节数据需要花费一定的LUT资源;
2.由于需要校验CRC和CHECK SUM,需要保存一整帧数据,所以存储需要花费大量的BRAM,我这里使用了一个FIFO和一个BRAM,其中FIFO用于专门存储CRC等校验的结果,BRAM则需要存最大帧的数据;
所以,千兆网下的RX BRAM应该至少深度为4096,我实际给了8192;校验FIFO 建议给32,实际也给了32。因为1536/64是一个合适的比例,这意味着需要额外考虑的是:处理最大帧的过程中可以容纳多少个最短帧;
数据帧FIFO:8x8192
校验FIFO:32x32
接收端数据流: 1.外部数据通过RGMII管脚进入FPGA; 2.PHY通过IDDR完成处理; 3.从PHY数据流中解析出MAC数据,根据前导码完成帧头检验; 4.根据MAC层协议确定其中的具体以太网协议,完成其的流向; 4-1:ARP ACK协议数据,ARP协议不需要校验和,此处数据流的处理是判断其是ACK还是REQ,
如果此前发送过REQ,此时的状态机就已经准备好接收ARP ACK了,
接收完ARP ACK以后解析其中数据并处理MAC地址; 4-2:ARP REQ协议数据,上位机会定期发送ARP REQ数据,
接收到此数据,且状态机处于空闲状态的时候,下一个发送的以太网数据帧为ARP ACK; 4-3:UDP协议数据,解析其中数据字段是否为指定包头,我在此自定义了一些字段,
来判断当前写入的UDP报文是否来自于我的需求方,
检验其中的校验和、CRC、端口号、MAC、IP地址等,均通过检验则将数据写入DDR3中;
对于发送端:
1.需要考虑不同发送包的差异,把命令给到发送模块以进行不同的组帧;(比如ARP就不需要处理校验和这些东西),这就产生了LUT资源的花销;
2.BRAM消耗来自我做了一个位宽转换模块:eth_tx_data_master;这个模块用于将需要发送的数据8bit输出;
(当然这里需要考虑跨时钟域问题,用到了异步的FIFO,更标准的用法是再仲裁一路读取供以太网输出,这在时序和上位机的接收帧率上都要好一些,只是我个人认为不太有必要再挤压DDR3的带宽);
发送模块的FIFO: 缓存数据~位宽转换FIFO:8x4096 配置信息FIFO:(16 长度 + 16+16两个校验和)x(32)=48x32 帧数据FIFO:8x4096
发送模块的数据流:
1.外部数据输入以太网发送数据缓存模块,数据缓存模块在满足要求以后向仲裁模块发送请求;
2.得到允许,并发送完以太网包头,根据需要组帧完成头部字段以后,组帧模块从缓存模块FIFO从读出数据并送往校验和模块;
3.校验和模块根据TYPE决定是否添加校验和,如果需要添加则添加,不需要则不改变,此后送往CRC模块;
4.添加CRC后,将数据通过ODDR输出至RGMII管脚;
第一部分:当外部数据将期望发送的数据输入到以太网模块的时候,需要一个位宽转换FIFO来缓存,由于以太网的最大帧长为1536byte,所以缓存FIFO需要至少缓存两帧,所以此处FIFO的形制为8x2048或8x4096。
当缓存FIFO的数据达到约定好的发包数据负载长度请求的时候,数据发送模块向仲裁模块请求,得到相应后数据从缓存FIFO中读出,送完组帧模块。
第二部分:组帧模块,仲裁完成的同时,会向对应的组帧模块发送一个使能,这个使能会使组帧模块向校验和模块发送一些数据。(我在千兆网中组帧模块是分开写的,这是一种不够高明的写法,也是当时对以太网学习进行的一些摸索,每一种数据包都用不同的模块进行组帧),这里的组帧模块各自有各自的处理数据的方法,例如ARP组帧模块就没有FIFO,而是发送相对固定的数据,直到ARP ACK 或 ARP REQ的时候从上位机下发的包中解析需要的地址信息。缓存FIFO位于UDP组帧模块中。
第三部分:校验和模块。校验和模块有两个FIFO,一个是配置FIFO,一个是帧数据FIFO(其实用RAM也是一样的,我这里实际用的是RAM)。组帧模块会在发送帧数据的同时发送一些配置信息,这个配置信息包括TYPE和帧的长度,而当发送帧数据接收的时候,校验和模块会把配置信息和帧数据输入时计算的校验和一同写入配置FIFO。当配置FIFO不为空,就会自动启动一次读,从中读取出来的数据包括数据包的TYPE,长度等。模块会根据TYPE来选择是否需要校验和,如果需要,会在读取帧数据FIFO的同时将校验和塞到指定的位置,如果不需要,则不添加。


module eth_tx_data_master #( parameter TX_Sync_Frame = {8'hF0,8'h5A,8'hA5,8'h0F}, parameter TX_Pixel_H = 16'd640, parameter TX_Pixel_W = 16'd480 )( input wire sys_rst_n , //pre input wire pre_wr_clk , input wire pre_wr_vaild , input wire [15:0] pre_wr_data , input wire pre_wr_sync , //post input wire post_rd_clk , input wire post_rd_vaild , output wire [07:0] post_rd_data , output reg post_rd_req ); reg fifo_wr_en ; reg [15:0] fifo_wr_data ; reg fifo_rst ; wire fifo_rd_en ; wire [07:0] fifo_rd_data ; wire full ; wire empty ; wire [15:0] rd_data_count ; wire [15:0] wr_data_count ; reg wait_rst_cycle ; reg wr_cycle ; reg r_wr_cycle ; reg [07:0] wr_cnt ; reg [15:0] col_cnt ; reg [15:0] row_cnt ; reg video_en_ch0 ; assign fifo_rd_en = post_rd_vaild; assign post_rd_data = fifo_rd_data; always @(posedge pre_wr_clk) begin if(sys_rst_n == 1'b0) begin col_cnt <= 'd0; end else if(pre_wr_sync == 1'b1) begin col_cnt <= 'd0; end else if(pre_wr_vaild == 1'b1 && col_cnt == 'd1279) begin col_cnt <= 'd0; end else if(pre_wr_vaild == 1'b1) begin col_cnt <= col_cnt + 1'b1; end end always @(posedge pre_wr_clk) begin if(sys_rst_n == 1'b0) begin row_cnt <= 'd0; end else if(pre_wr_sync == 1'b1) begin row_cnt <= 'd0; end else if(pre_wr_vaild == 1'b1 && col_cnt == 'd1279) begin row_cnt <= row_cnt + 1'b1; end end always @(*) begin if((col_cnt <= 'd639)&&(row_cnt <= 'd479)&&(pre_wr_vaild == 1'b1)) begin video_en_ch0 <= 1'b1; end else begin video_en_ch0 <= 1'b0; end end always @(posedge pre_wr_clk) begin fifo_rst <= pre_wr_sync ; r_wr_cycle <= wr_cycle ; end always @(posedge pre_wr_clk) begin if(sys_rst_n == 1'b0) begin wait_rst_cycle <= 1'b0; end else if(wr_cycle == 1'b1) begin wait_rst_cycle <= 1'b0; end else if(fifo_rst == 1'b1 && pre_wr_sync == 1'b0) begin wait_rst_cycle <= 1'b1; end end always @(posedge pre_wr_clk) begin if(sys_rst_n == 1'b0) begin wr_cycle <= 1'b0; end else if(wr_cnt == 'd3 && wr_cycle == 1'b1) begin wr_cycle <= 1'b0; end else if(wait_rst_cycle == 1'b1 && full == 1'b0) begin wr_cycle <= 1'b1; end end always @(posedge pre_wr_clk) begin if(sys_rst_n == 1'b0) begin wr_cnt <= 'd0; end else if(wr_cnt == 'd3 && wr_cycle == 1'b1) begin wr_cnt <= 'd0; end else if(wr_cycle == 1'b1) begin wr_cnt <= wr_cnt + 1'b1; end end always @(posedge pre_wr_clk) begin if(sys_rst_n == 1'b0) begin fifo_wr_en <= 1'b0; end else if(wr_cycle == 1'b1) begin fifo_wr_en <= 1'b1; end else if(video_en_ch0 == 1'b1) begin fifo_wr_en <= 1'b1; end else begin fifo_wr_en <= 1'b0; end end always @(posedge pre_wr_clk) begin if(sys_rst_n == 1'b0) begin fifo_wr_data <= 8'hff; end else if(wr_cycle == 1'b1) begin if(wr_cnt == 0) begin fifo_wr_data <= TX_Sync_Frame[31-:16]; end else if(wr_cnt == 1) begin fifo_wr_data <= TX_Sync_Frame[15-:16]; end else if(wr_cnt == 2) begin fifo_wr_data <= TX_Pixel_H; end else if(wr_cnt == 3) begin fifo_wr_data <= TX_Pixel_W; end else begin fifo_wr_data <= 8'hff; end end else if(video_en_ch0 == 1'b1) begin fifo_wr_data <= pre_wr_data; end else begin fifo_wr_data <= 8'hff; end end always @(*) begin if(rd_data_count >= 'd1280) begin post_rd_req <= 1'b1; end else begin post_rd_req <= 1'b0; end end buff_eth_tx buff_eth_tx ( .rst ( fifo_rst ), // input wire rst .wr_clk ( pre_wr_clk ), // input wire wr_clk .rd_clk ( post_rd_clk ), // input wire rd_clk .din ( fifo_wr_data ), // input wire [15 : 0] din .wr_en ( fifo_wr_en ), // input wire wr_en .rd_en ( fifo_rd_en ), // input wire rd_en .dout ( fifo_rd_data ), // output wire [7 : 0] dout .full ( full ), // output wire full .empty ( empty ), // output wire empty .rd_data_count( rd_data_count ), // output wire [12 : 0] rd_data_count .wr_data_count( wr_data_count ), // output wire [11 : 0] wr_data_count .wr_rst_busy ( ), // output wire wr_rst_busy .rd_rst_busy ( ) // output wire rd_rst_busy ); endmodule
特殊资源:IO,时钟等;
以太网模块使用了IODELAY,IDDR,ODDR原语来约束时钟;
DVP相机解析模块:
解析对象:SONY IMX222相机
就是很普通的解帧,看手册,没有什么可以讨论的地方。
DVP相机:
仅有8bit数据输入端口;
通过SPI配置;(向指定寄存器写入规定的数值)
解帧:
其的数据流构成分为有效数据,无效数据等。
为了从第一行第一列像素开始做解帧,需要等待无效像素行的标志,
等待得到无效像素行以后,状态机跳转,开始等待有效像素行,
这时候等待的有效像素行即为第一行第一列数据;
当然,这里的实际有效像素行大小和配置信息的输出画幅大小有关;
通过在特定的计数场景下才存储数据可以调整实际的图像在画幅中的位置。

MIPI-CSI 解析模块:
标准资源:LUT BRAM

资源开销很均匀,每个模块都只有几时LUT的耗用,很普通的解串+对齐+解帧模块;
甚至没有太多需要花费BRAM的地方;
特殊资源:IO,时钟等;
使用了IBUFD 来差分转单端,使用了ISERDES 来转换串行数据;还有BUFIO来增强驱动并且输入BUFD(换成BUFG之类的也行);
GT高速收发器模块
64/66模式

这里实质是600+LUT,但我花费了大量的资源去生成ILA,这里没有及时删除;
当然,我这里也没有列出位宽转换的FIFO模块,因为这不是讨论的重点。



GT模块会花费GT CHANNEL和GT COMMON资源,还有BUFG。
这是因为USERCLK的生成需要MMCM的参与。
万兆以太网模块
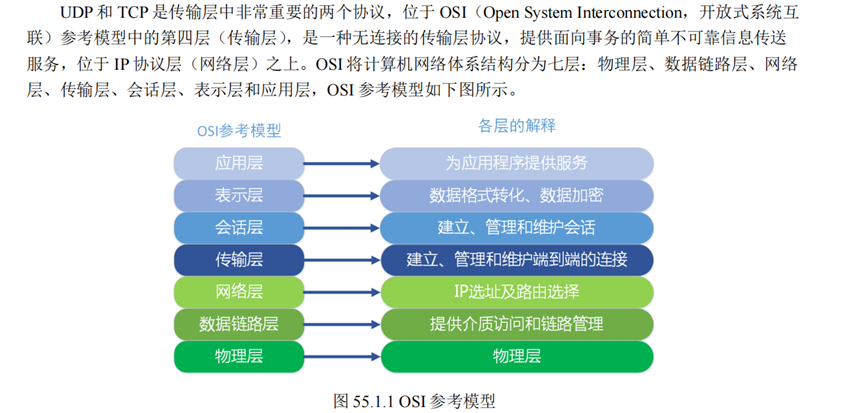
万兆以太网和千兆以太网的传输协议是一样的,但是使用的接口不同,承载其数据的介质不同,使得其需要额外处理。
本万兆以太网模块使用PCS&PMA IP完成了对物理层的处理,这个IP的作用可参考:https://blog.csdn.net/wjcqwe/article/details/129652602
XGMII的协议是(32+4+1)x2总共74根线组成的,这些高速信号如果直接作为接口输出会带来巨大的走线困扰,更不用说FPGA仅通过两根GT线(一对高速收发器)来完成了;
实质上XGMII会先连接到XAUI上,而XAUI再连接到内部的XGMII接口完成输出,这就降低了走线成本。
XAUI 接口 由于受电气特性的影响,XGMII接口的PCB走线最大传输距离仅有7cm,
并且XGMII接口的连线数量太多,给实际应用带来不便,
因此,在实际应用中,XGMII接口通常被XAUI接口代替,
XAUI即10 Gigabit attachment unit interface,10G附属单元接口,
XAUI在XGMII的基础上实现了XGMII接口的物理距离扩展,
将PCB走线的传输距离增加到50cm,使背板走线成为可能。 源端XGMII把收发32位宽度数据流分为4个独立的lane通道,
每个lane通道对应一个字节,
经XGXS(XGMII Extender Sublayer)完成8B/10B编码后,
将4个lane分别对应XAUI的4个独立通道,
XAUI端口速率为:2.5Gbps * 1.25 * 4=12.5Gbps。 在发送端的XGXS模块中,将TXD[31:0]/ RXD[31:0],TXC[3:0]/ RXC[3:0],
TXC/ RXC转换成串行数据从TX Lane[3:0]/ RX Lane[3:0]中发出去,
在接收端的XGXS模块中,串行数据被转换成并行,并且进行时钟恢复和补偿,
完成时钟去抖,经过5B/4B解码后,重新聚合成XGMII。 XAUI接口采用差分线,收发各四对,CML逻辑,AC耦合方式,耦合电容在10nF~100nF之间。 XAUI接口可以直接接光模块,如XENPAK/X2等。也可以转换成一路10G信号XFI,接XFP/SFP+等。
至于FPGA内部直接使用的接口,则是64bit的,用于连接到IP上;
当然这个IP实质上也是通过GT WIZARD封装得到的,类似于AURORA 8/10或者64/66。
只是省去了我们操作gearbox的计数器、滑窗对齐这些操作而已。
本项目中暂时没有做ICMP协议,但是会针对ICMP协议加入的情况做充足的分析。
实际仅使用了:ARP UDP。
所有添加+剥去字节数量不满足8字节的RCB的时候都需要做尾端对齐处理;
以满足AXIS协议的数据要求。
发送模块
https://www.cnblogs.com/VerweileDoch/p/18105593
1.UDP 模块:
数据帧FIFO:64x16
(如果需要计算UDP校验和则需要64x256)
2.仲裁模块1 ICMP和UDP FIFO:
数据帧FIFO:64x512
尾端对齐FIFO:8x32
配置信息FIFO:80x32
x2:UDP & ICMP

3.IP模块:
数据帧FIFO:64x16
IP层校验和仅仅是首部校验,节约了资源。

4.仲裁模块2 IP & ARP:
数据帧FIFO:64x512
尾端对齐FIFO:8x32
配置信息FIFO:80x32
x2:ARP & IP

5.MAC模块
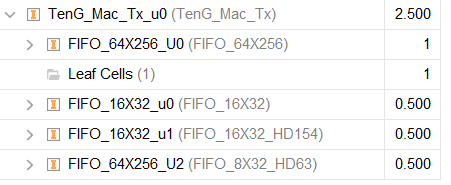
数据帧FIFO:64x256
配置信息FIFO:40x32
发送模块数据流: 1.UDP模块。
UDP模块需要添加UDP首部:8字节:2+2端口+2长度+2校验和
外部模块将数据输入万兆以太网数据缓存模块,这也是UDP模块,
这里的处理方法很灵活,我使用了axis接口。
类似于千兆以太网,如果只是希望输入多少数据就发送多少数据的话,
通过s_axis_user_last来完成对输入数据长度的统计,
把长度等重要信息存储发送到下一个模块即可。
但是这样操作实质上没有必要,也不是很符合业务需求。
我个人的操作是:外部模块通过axis输入需要发送数据的同时,
也一并将需要发送数据的长度、type、源mac地址等数据一并给出,供后续的模块支取。
(我个人认为任意长度的数据帧发送暂时是不需要的,因为以太网有最小数据帧需求,
似乎是64字节,如果考虑到这个还需要加额外的校验、补零处理,所以此处是我为了学习以太网而做了简化)。
这里我使用了一个FIFO来稍微延迟数据的下发,
即外部数据输入的过程中,该FIFO不为空的时候开始读取,
此处FIFO之目的是为了计算UDP校验和,如果需要此功能需要把FIFO的深度提升,
至少为512深度。
(如果需要封装更上层协议(传输层协议)则十分有必要,
这也是本人写完千兆网留下的一个想法,但此处实际上是从IP层才开始做总裁的)。
2.仲裁模块①:ICMP和ICMP的仲裁
此处也需要分别考虑,如果需要考虑ICMP,则需要UDP报文和ICMP报文仲裁;
UDP层将数据下发至仲裁模块,因为除了UDP报文以外,还可能发送ARP报文。
(在千兆以太网协议栈中,我的仲裁是:当此前报文传输结束后,进行仲裁,
如果之前来到过ARP REQ,则优先发送一次ARP ACK,再发送下一帧的UDP报文)
为了考虑多种报文,需要的FIFO数量就因此而增加了。
相较于千兆网中我使用状态机先仲裁再组帧,将数据写入数据帧FIFO,将发包类型写入配置信息FIFO,
万兆网为了提升组帧效率是有必要
【先分别组帧,分别写入不同FIFO,再仲裁判断从哪个FIFO读出指定数据以进行下一步操作】
其实这两种方法来说,万兆网中采用的方法也提升不了太多的速度,
但是在需要发送多种类型包的时候,这种方法是更方便管理的,也是我的一个尝试:
【在资源还算充裕的时候使用这种方法可以节约开发时间,
毕竟都写入一个FIFO只有UDP和ARP包的时候还好,包类型增加的话恐怕不容易去考虑周到】
在这个思想的指导下,我需要结合万兆网的一些特性完成对FIFO的设置,
首先以太网非巨型帧的最大数据帧长是1536byte,
在万兆网场景下是64x192而已,所以对于万兆网来说:
数据帧FIFO的设置是64x256为佳,
如果需要考虑【一个最大帧长加若干最小帧长】,
则是192+64/8 x (1536/64) = 384 深度;
所以最稳妥的是根据需要发送数据帧数的类型设置多个
【64x512】空间的RAM或FIFO;
尾端处理FIFO:同时还要考虑到我所使用的是axis接口,
需要将尾端keep传输到下一个模块,
这里需要用到【8x32】32 = 2 ^ (log2(1536/64) + 1 )
配置信息FIFO:为了考虑数据组帧信息里包括的长度,type等信息,
这里设置了80x32,是为了考虑将来可能需要做的分片2和巨型帧处理等,
主要还是type:2,length:2;
所以根据以上总总考虑,IP层模块需要使用的存储资源便是:
64x512
8x32
80x32。
仲裁部分:当任意一个配置信息FIFO不为空的时候启动仲裁.优先级ICMP > UDP;
3.IP层组帧模块:
IP层组帧模块需要添加20字节长度的IP层首部数据;
从0x45开始,对于千兆网协议栈来说这里需要用FIFO来解决问题,
因为20字节的延迟是非常麻烦的,而且至少得用8x32长度的FIFO;
万兆网位宽是64,所以理论上不用FIFO也没有什么问题,
但同样的为了管理数据流,这里用到一个64x16的数据帧FIFO。
4.仲裁模块2:IP & ARP
就像之前的ICMP和UDP,这里IP和ARP都处于网络层,
他们进入数据链路层的过程中也需要仲裁;
这里的仲裁模块和之前是一样的,ARP优先级>UDP。
5,MAC模块
仲裁模块之后的数据流进入到MAC模块,这是万兆网协议栈实现过程中最复杂的模块。
MAC模块需要负责添加22字节的数据,分别是8字节的前导码(在千兆网协议栈是8字节,此处实质上是7字节),
还有14字节的MAC首部:6+6:MAC地址。
MAC模块需要使用:
数据帧FIFO:64x256
配置信息FIFO 长度:16x32
配置信息FIFO type:16x32
配置信息FIFO KEEP:8X32
其最难的部分在于两个部分:
1.可以同时计算64位输入的CRC;
2.尾端对齐处理。
添加完MAC头,GT收发器的控制信号,即可输入PCS&PMA IP核。
资源开支:
PCIE模块:RIFFA
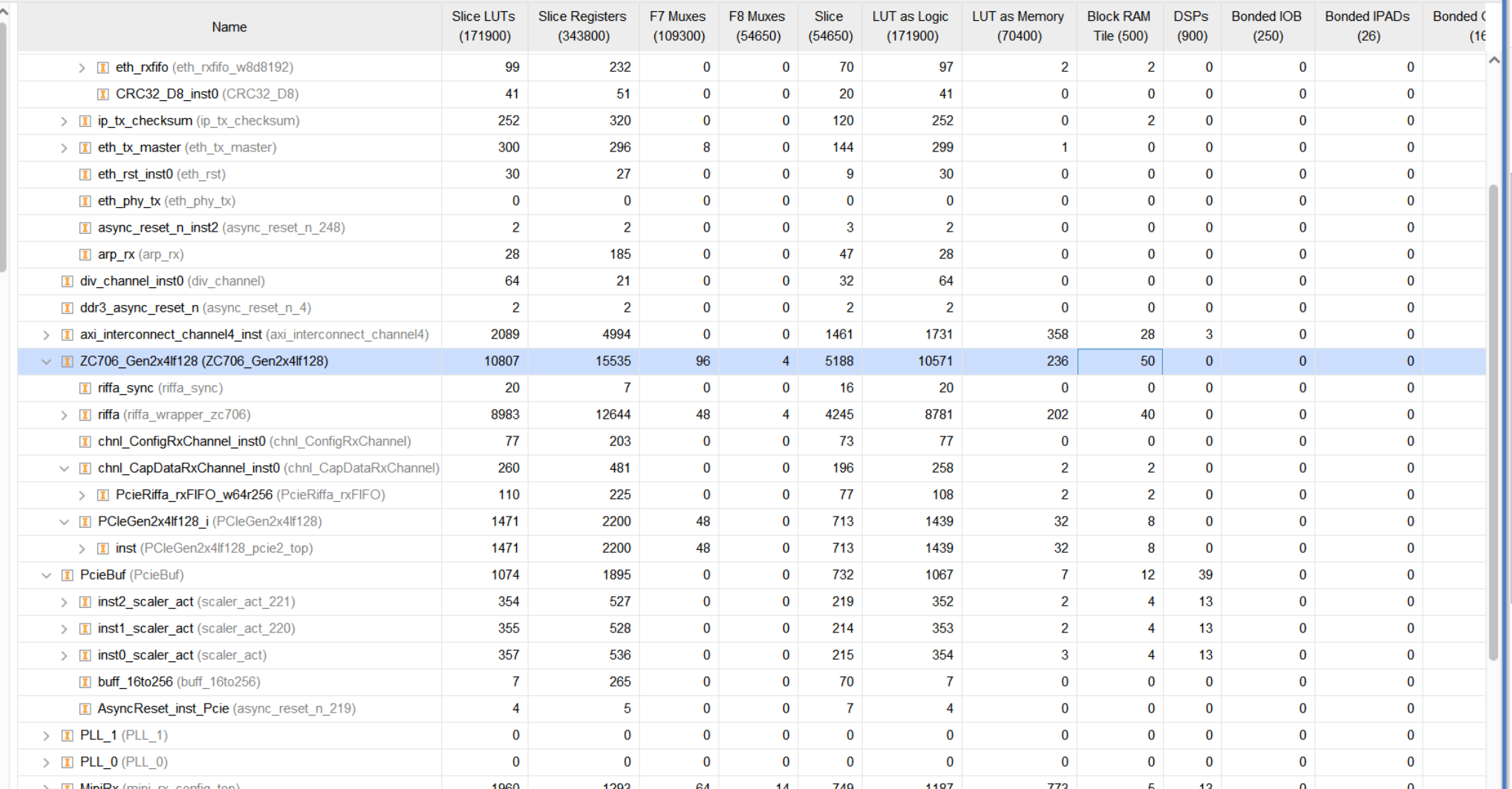
框架花销了极多资源,
第一个通道负责接收配置,获得数据流帧的格式和产生同步帧;
第二个通道使用AXIS接口获取解析完成的TLP包数据;
这里花费资源比较多的原因是因为我需要对PCIE的视频数据做缩放,这就需要转换成单个像素输入,于是我顺便调整了PCIE的写入速率,通过控制AXIS接口;
同时两个位宽转换模块使得BRAM的开销大大上涨了。
PCIE模块:XDMA
原计划使用XDMA框架替代项目一中的Riffa方案,但是实际上花费的资源要多太多,于是乎告罢。
而且中断非常不好用。

图像处理模块:
高斯和去拜尔仅仅开销了一些BRAM,就不加入讨论了。
白平衡:

为了完成低误差的图像处理,使用了一些DSP;
module White_Balance #( parameter I_w = 1920, parameter I_h = 1080, parameter Channel_Num = 3 )( input wire Pre_CLK , input wire Pre_Rst , input wire Pre_Vsync , input wire Pre_de , input wire [7:0] Pre_Pixel_R , input wire [7:0] Pre_Pixel_G , input wire [7:0] Pre_Pixel_B , output wire Post_Vsync , output wire Post_de , output wire [7:0] Post_Pixel_R , output wire [7:0] Post_Pixel_G , output wire [7:0] Post_Pixel_B , output wire [23:0] Post_Pixel_Total ); //========================================= Define Ports =========================================// localparam Shift_Num = 21; localparam Kaver_Divisor = I_w*I_h*Channel_Num; reg [2:0] Delay_Pre_de ; wire Pose_Pre_de ; wire Nege_Pre_de ; reg r_Pre_Vsync ; wire Pose_Pre_Vsync ; wire Nege_Pre_Vsync ; reg [31:0] Red_Sum ; reg [31:0] Green_Sum ; reg [31:0] Blue_Sum ; reg [32:0] K_Sum ; reg [10:0] Aver_R ; reg [10:0] Aver_G ; reg [10:0] Aver_B ; reg [32:0] Aver_K ; reg Calcu_Kaver ; wire [63 : 0] Kaver_Result ; wire Kaver_vaild ; //Pixel*Kaver wire [18 : 0] Multi_RxKaver ; wire [18 : 0] Multi_GxKaver ; wire [18 : 0] Multi_BxKaver ; //Pixel*Kaver/Pixel_aver wire [39 : 0] Div_RxKaver_D_Raver ; wire Div_RxKaver_vaild ; wire [39 : 0] Div_GxKaver_D_Gaver ; wire Div_GxKaver_vaild ; wire [39 : 0] Div_BxKaver_D_Baver ; wire Div_BxKaver_vaild ; wire [18:0] Quo_R_Pixel ; wire [18:0] Quo_G_Pixel ; wire [18:0] Quo_B_Pixel ; reg r_Post_de ; reg [7:0] r_Post_Pixel_R ; reg [7:0] r_Post_Pixel_G ; reg [7:0] r_Post_Pixel_B ; //========================================= Define Ports =========================================// always @(posedge Pre_CLK) begin Delay_Pre_de <= {Delay_Pre_de[1:0],Pre_de}; r_Pre_Vsync <= Pre_Vsync; end assign Pose_Pre_Vsync = (Pre_Vsync == 1'b1)&&(r_Pre_Vsync == 1'b0); assign Nege_Pre_Vsync = (Pre_Vsync == 1'b0)&&(r_Pre_Vsync == 1'b1); //Calcu_Kaver always @(posedge Pre_CLK) begin if(Pre_Rst == 1'b1) begin Calcu_Kaver <= 1'b0; end else if(Nege_Pre_Vsync == 1'b1) begin Calcu_Kaver <= 1'b1; end else begin Calcu_Kaver <= 1'b0; end end //Pixel Sum always @(posedge Pre_CLK) begin if(Pre_Rst == 1'b1) begin Red_Sum <= 'd0; Green_Sum <= 'd0; Blue_Sum <= 'd0; K_Sum <= 'd0; end else if(Calcu_Kaver == 1'b1) begin Red_Sum <= 'd0; Green_Sum <= 'd0; Blue_Sum <= 'd0; K_Sum <= 'd0; end else if(Pre_de == 1'b1) begin Red_Sum <= Red_Sum + Pre_Pixel_R; Green_Sum <= Green_Sum + Pre_Pixel_G; Blue_Sum <= Blue_Sum + Pre_Pixel_B; K_Sum <= K_Sum + Pre_Pixel_R + Pre_Pixel_G + Pre_Pixel_B; end else begin Red_Sum <= Red_Sum ; Green_Sum <= Green_Sum; Blue_Sum <= Blue_Sum ; K_Sum <= K_Sum ; end end //Div Pipeline = 16 Div_Kaver Kaver_Comput_33D23 ( .aclk ( Pre_CLK ), // input wire aclk .aresetn ( !Pre_Rst ), // input wire aresetn .s_axis_divisor_tvalid ( Calcu_Kaver ), // input wire s_axis_divisor_tvalid .s_axis_divisor_tdata ( Kaver_Divisor ), // input wire [23 : 0] s_axis_divisor_tdata .s_axis_dividend_tvalid( Calcu_Kaver ), // input wire s_axis_dividend_tvalid .s_axis_dividend_tdata ( K_Sum ), // input wire [39 : 0] s_axis_dividend_tdata .m_axis_dout_tvalid ( Kaver_vaild ), // output wire m_axis_dout_tvalid .m_axis_dout_tdata ( Kaver_Result ) // output wire [63 : 0] m_axis_dout_tdata [56:24] ); //aver always @(posedge Pre_CLK) begin if(Pre_Rst == 1'b1) begin Aver_R <= 'd0; Aver_G <= 'd0; Aver_B <= 'd0; end else if(Calcu_Kaver == 1'b1) begin Aver_R <= Red_Sum[21+:11] ; Aver_G <= Green_Sum[21+:11]; Aver_B <= Blue_Sum[21+:11] ; end else begin Aver_R <= Aver_R; Aver_G <= Aver_G; Aver_B <= Aver_B; end end always @(posedge Pre_CLK) begin if(Pre_Rst == 1'b1) begin Aver_K <= 'd0; end else if(Kaver_vaild == 1'b1) begin Aver_K <= Kaver_Result[56:24]; end else begin Aver_K <= Aver_K; end end //Multi Pipeline = 3 //Red Pixel_Multi_Kaver Pixel_Multi_Kaver_Red_8x11 ( .CLK ( Pre_CLK ), // input wire CLK .A ( Pre_Pixel_R ), // input wire [7 : 0] .B ( Aver_K[10:0] ), // input wire [10 : 0] .P ( Multi_RxKaver ) // output wire [18 : 0] ); //Div Pipeline = 16 Div_GenGain Div_GenGain_Red ( .aclk ( Pre_CLK ), // input wire aclk .aresetn ( !Pre_Rst ), // input wire aresetn .s_axis_divisor_tvalid ( Delay_Pre_de[2] ), // input wire s_axis_divisor_tvalid .s_axis_divisor_tdata ( Aver_R ), // input wire [15 : 0] s_axis_divisor_tdata .s_axis_dividend_tvalid ( Delay_Pre_de[2] ), // input wire s_axis_dividend_tvalid .s_axis_dividend_tdata ( Multi_RxKaver ), // input wire [23 : 0] s_axis_dividend_tdata .m_axis_dout_tvalid ( Div_RxKaver_vaild ), // output wire m_axis_dout_tvalid .m_axis_dout_tdata ( Div_RxKaver_D_Raver ) // output wire [39 : 0] m_axis_dout_tdata [34:16] ); //Gre Pixel_Multi_Kaver Pixel_Multi_Kaver_Gre_8x11 ( .CLK ( Pre_CLK ), // input wire CLK .A ( Pre_Pixel_G ), // input wire [7 : 0] .B ( Aver_K[10:0] ), // input wire [10 : 0] .P ( Multi_GxKaver ) // output wire [18 : 0] ); Div_GenGain Div_GenGain_Gre ( .aclk ( Pre_CLK ), // input wire aclk .aresetn ( !Pre_Rst ), // input wire aresetn .s_axis_divisor_tvalid ( Delay_Pre_de[2] ), // input wire s_axis_divisor_tvalid .s_axis_divisor_tdata ( Aver_G ), // input wire [15 : 0] s_axis_divisor_tdata .s_axis_dividend_tvalid ( Delay_Pre_de[2] ), // input wire s_axis_dividend_tvalid .s_axis_dividend_tdata ( Multi_GxKaver ), // input wire [23 : 0] s_axis_dividend_tdata .m_axis_dout_tvalid ( Div_GxKaver_vaild ), // output wire m_axis_dout_tvalid .m_axis_dout_tdata ( Div_GxKaver_D_Gaver ) // output wire [39 : 0] m_axis_dout_tdata ); //Blue Pixel_Multi_Kaver Pixel_Multi_Kaver_Blu_8x11 ( .CLK ( Pre_CLK ), // input wire CLK .A ( Pre_Pixel_B ), // input wire [7 : 0] .B ( Aver_K[10:0] ), // input wire [10 : 0] .P ( Multi_BxKaver ) // output wire [18 : 0] ); Div_GenGain Div_GenGain_Blu ( .aclk ( Pre_CLK ), // input wire aclk .aresetn ( !Pre_Rst ), // input wire aresetn .s_axis_divisor_tvalid ( Delay_Pre_de[2] ), // input wire s_axis_divisor_tvalid .s_axis_divisor_tdata ( Aver_B ), // input wire [15 : 0] s_axis_divisor_tdata .s_axis_dividend_tvalid ( Delay_Pre_de[2] ), // input wire s_axis_dividend_tvalid .s_axis_dividend_tdata ( Multi_BxKaver ), // input wire [23 : 0] s_axis_dividend_tdata .m_axis_dout_tvalid ( Div_BxKaver_vaild ), // output wire m_axis_dout_tvalid .m_axis_dout_tdata ( Div_BxKaver_D_Baver ) // output wire [39 : 0] m_axis_dout_tdata ); assign Quo_R_Pixel = Div_RxKaver_D_Raver[34:16]; assign Quo_G_Pixel = Div_GxKaver_D_Gaver[34:16]; assign Quo_B_Pixel = Div_BxKaver_D_Baver[34:16]; always @(posedge Pre_CLK) begin if(Pre_Rst == 1'b1) begin r_Post_Pixel_R <= 'd0; end else if(Div_RxKaver_vaild == 1'b1) begin if(Quo_R_Pixel > 8'd255) begin r_Post_Pixel_R <= 8'd255; end else begin r_Post_Pixel_R <= Quo_R_Pixel[7:0]; end end else begin r_Post_Pixel_R <= r_Post_Pixel_R; end end always @(posedge Pre_CLK) begin if(Pre_Rst == 1'b1) begin r_Post_Pixel_G <= 'd0; end else if(Div_GxKaver_vaild == 1'b1) begin if(Quo_G_Pixel > 8'd255) begin r_Post_Pixel_G <= 8'd255; end else begin r_Post_Pixel_G <= Quo_G_Pixel[7:0]; end end else begin r_Post_Pixel_G <= r_Post_Pixel_G; end end always @(posedge Pre_CLK) begin if(Pre_Rst == 1'b1) begin r_Post_Pixel_B <= 'd0; end else if(Div_BxKaver_vaild == 1'b1) begin if(Quo_B_Pixel > 8'd255) begin r_Post_Pixel_B <= 8'd255; end else begin r_Post_Pixel_B <= Quo_B_Pixel[7:0]; end end else begin r_Post_Pixel_B <= r_Post_Pixel_B; end end always @(posedge Pre_CLK) begin if(Pre_Rst == 1'b1) begin r_Post_de <= 1'b0; end else if(Div_BxKaver_vaild == 1'b1) begin r_Post_de <= 1'b1; end else begin r_Post_de <= 1'b0; end end assign Post_Vsync = r_Pre_Vsync ; assign Post_de = r_Post_de; assign Post_Pixel_R = r_Post_Pixel_R; assign Post_Pixel_G = r_Post_Pixel_G; assign Post_Pixel_B = r_Post_Pixel_B; assign Post_Pixel_Total = {r_Post_Pixel_R,r_Post_Pixel_G,r_Post_Pixel_B}; // ila_0 White_ILA ( // .clk(Pre_CLK), // .probe0( Pre_de ),//1 // .probe1( Pre_Vsync ),//1 // .probe2( Calcu_Kaver ),//1 // .probe3( Pre_Pixel_R ),//8 // .probe4( Pre_Pixel_G ),//8 // .probe5( Pre_Pixel_B ),//8 // .probe6( Kaver_vaild ),//1 // .probe7( Aver_R ),//11 // .probe8( Aver_G ),//11 // .probe9( Aver_B ),//11 // .probe10( K_Sum ),//33 // .probe11( Aver_K ),//33 // .probe12( Multi_RxKaver ),//19 // .probe13( Multi_GxKaver ),//19 // .probe14( Multi_BxKaver ),//19 // .probe15( Delay_Pre_de ),//3 // .probe16( Post_Pixel_R ),//8 // .probe17( Post_Pixel_G ),//8 // .probe18( Post_Pixel_B ),//8 // .probe19( Post_de ),//1 // .probe20( Div_BxKaver_vaild ) //1 // ); endmodule
双线性插值:

花费很多的BRAM,很多的LUT,还有很多的DSP:因为涉及大量有符号数的定点数相乘。
如果希望动态计算缩放比例,需要使用除法器。
我想更好的解决方案是使用localparam做很多个选择,然后根据实际情况选择不同的localparam;
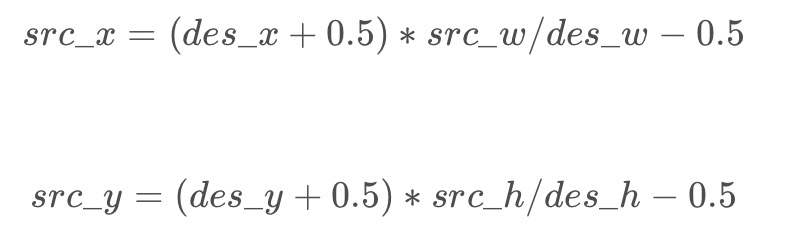


 浙公网安备 33010602011771号
浙公网安备 33010602011771号