笔记:从Aurora 8b/10b 到Aurora 64b/66b (一):Aurora 8b/10b
aurora ip核会自行完成:https://www.cnblogs.com/VerweileDoch/p/18331116
这个链接中的活动,包括:
1.TX端口的组帧:添加commoa,SOF,EOF,定期发送commoa,发送空闲码,数据对齐等;
2.RX端口的拆帧:解开帧,取出数据,完成对齐等;
这让我们可以不用通过GT收发器IP直接操作就能完成数据的收发工作,
其中8b/10b支持的是6.6Gbps以下,64b/66b则最高支持10.3125Gbps的数据收发;
资源耗用:
整体资源耗用上比我直接写的rtl代码多花200个lut,和数百个ff,只是这种程度的差异我想没必要特意使用,因为RTL我也没做多少优化;
但是BUFG使用的MMCM的格式是使得每个CHANNEL上要比AURORA IP核使用多1个,这是非常严重的浪费,虽然也是可以花一些精力就能优化掉的,
但是考虑时间成本,每个通道少用1个BUFG换取多用200个LUT我觉得还是很棒的,日后有时间重构再说,目前也只是学习。
其实不用这种MMCM的方法,直接使用BUFG也是可以的,需要在GT配置的时候把一些端口的勾选取消;
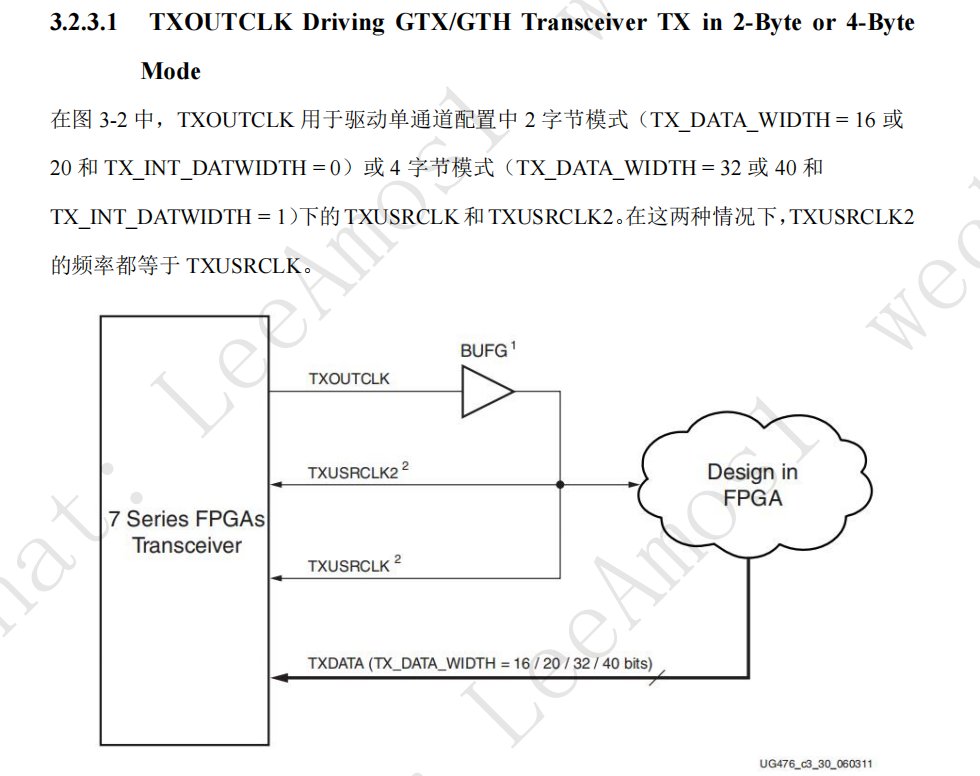
也就是第三页的TX OUTCLK的时钟源PLL参考,我相信也是可以正常工作的,毕竟用户时钟通过TX OUTCLK直接经由BUFG驱动用户模块本来就是476的结构之一;
但也需要注意,选用不同的结果主要考虑的还是TXUSRCLK2和TXUSRCLK的关系,他们之间可能存在倍数关系也可能相等,这点在476中有所提及,
为了使得BUFG相关资源耗用的减少,考虑合适的关系是很重要的,他们的关系主要和GT收发器内部的数据交互位宽和用户位宽有关,TXUSRCLK可能需要较高的频率来完成对TXUSRCLK2端口数据的搬运;


/////////////////////////////////////////////////////////////////////////////// // file: clk_wiz_v2_1.v // // (c) Copyright 2010-2012 Advanced Micro Devices, Inc. All rights reserved. // // This file contains confidential and proprietary information // of Advanced Micro Devices, Inc. and is protected under U.S. and // international copyright and other intellectual property // laws. // // DISCLAIMER // This disclaimer is not a license and does not grant any // rights to the materials distributed herewith. Except as // otherwise provided in a valid license issued to you by // AMD, and to the maximum extent permitted by applicable // law: (1) THESE MATERIALS ARE MADE AVAILABLE "AS IS" AND // WITH ALL FAULTS, AND AMD HEREBY DISCLAIMS ALL WARRANTIES // AND CONDITIONS, EXPRESS, IMPLIED, OR STATUTORY, INCLUDING // BUT NOT LIMITED TO WARRANTIES OF MERCHANTABILITY, NON- // INFRINGEMENT, OR FITNESS FOR ANY PARTICULAR PURPOSE; and // (2) AMD shall not be liable (whether in contract or tort, // including negligence, or under any other theory of // liability) for any loss or damage of any kind or nature // related to, arising under or in connection with these // materials, including for any direct, or any indirect, // special, incidental, or consequential loss or damage // (including loss of data, profits, goodwill, or any type of // loss or damage suffered as a result of any action brought // by a third party) even if such damage or loss was // reasonably foreseeable or AMD had been advised of the // possibility of the same. // // CRITICAL APPLICATIONS // AMD products are not designed or intended to be fail- // safe, or for use in any application requiring fail-safe // performance, such as life-support or safety devices or // systems, Class III medical devices, nuclear facilities, // applications related to the deployment of airbags, or any // other applications that could lead to death, personal // injury, or severe property or environmental damage // (individually and collectively, "Critical // Applications"). Customer assumes the sole risk and // liability of any use of AMD products in Critical // Applications, subject only to applicable laws and // regulations governing limitations on product liability. // // THIS COPYRIGHT NOTICE AND DISCLAIMER MUST BE RETAINED AS // PART OF THIS FILE AT ALL TIMES. // //---------------------------------------------------------------------------- // User entered comments //---------------------------------------------------------------------------- // None // //---------------------------------------------------------------------------- // Output Output Phase Duty Cycle Pk-to-Pk Phase // Clock Freq (MHz) (degrees) (%) Jitter (ps) Error (ps) //---------------------------------------------------------------------------- // CLK_OUT1 100.000 0.000 50.000 130.958 98.575 // //---------------------------------------------------------------------------- // Input Clock Input Freq (MHz) Input Jitter (UI) //---------------------------------------------------------------------------- // primary 100.000 0.010 `timescale 1ps/1ps (* X_CORE_INFO = "gtwizard_0,gtwizard_v3_6_15,{protocol_file=Start_from_scratch}" *) (* CORE_GENERATION_INFO = "clk_wiz_v2_1,clk_wiz_v2_1,{component_name=clk_wiz_v2_1,use_phase_alignment=true,use_min_o_jitter=false,use_max_i_jitter=false,use_dyn_phase_shift=false,use_inclk_switchover=false,use_dyn_reconfig=false,feedback_source=FDBK_AUTO,primtype_sel=MMCM_ADV,num_out_clk=1,clkin1_period=10.0,clkin2_period=10.0,use_power_down=false,use_reset=true,use_locked=true,use_inclk_stopped=false,use_status=false,use_freeze=false,use_clk_valid=false,feedback_type=SINGLE,clock_mgr_type=MANUAL,manual_override=false}" *) module gtwizard_0_CLOCK_MODULE # ( parameter MULT = 2, parameter DIVIDE = 2, parameter CLK_PERIOD = 6.4, parameter OUT0_DIVIDE = 2, parameter OUT1_DIVIDE = 2, parameter OUT2_DIVIDE = 2, parameter OUT3_DIVIDE = 2 ) (// Clock in ports input CLK_IN, // Clock out ports output CLK0_OUT, output CLK1_OUT, output CLK2_OUT, output CLK3_OUT, // Status and control signals input MMCM_RESET_IN, output MMCM_LOCKED_OUT ); wire clkin1; // Input buffering //------------------------------------ BUFG clkin1_buf (.O (clkin1), .I (CLK_IN)); // Clocking primitive //------------------------------------ // Instantiation of the MMCM primitive // * Unused inputs are tied off // * Unused outputs are labeled unused wire [15:0] do_unused; wire drdy_unused; wire psdone_unused; wire clkfbout; wire clkfbout_buf; wire clkfboutb_unused; wire clkout0b_unused; wire clkout0; wire clkout1; wire clkout1b_unused; wire clkout2; wire clkout2b_unused; wire clkout3; wire clkout3b_unused; wire clkout4_unused; wire clkout5_unused; wire clkout6_unused; wire clkfbstopped_unused; wire clkinstopped_unused; MMCME2_ADV #(.BANDWIDTH ("OPTIMIZED"), .CLKOUT4_CASCADE ("FALSE"), .COMPENSATION ("ZHOLD"), .STARTUP_WAIT ("FALSE"), .DIVCLK_DIVIDE (DIVIDE), .CLKFBOUT_MULT_F (MULT), .CLKFBOUT_PHASE (0.000), .CLKFBOUT_USE_FINE_PS ("FALSE"), .CLKOUT0_DIVIDE_F (OUT0_DIVIDE), .CLKOUT0_PHASE (0.000), .CLKOUT0_DUTY_CYCLE (0.500), .CLKOUT0_USE_FINE_PS ("FALSE"), .CLKIN1_PERIOD (CLK_PERIOD), .CLKOUT1_DIVIDE (OUT1_DIVIDE), .CLKOUT1_PHASE (0.000), .CLKOUT1_DUTY_CYCLE (0.500), .CLKOUT1_USE_FINE_PS ("FALSE"), .CLKOUT2_DIVIDE (OUT2_DIVIDE), .CLKOUT2_PHASE (0.000), .CLKOUT2_DUTY_CYCLE (0.500), .CLKOUT2_USE_FINE_PS ("FALSE"), .CLKOUT3_DIVIDE (OUT3_DIVIDE), .CLKOUT3_PHASE (0.000), .CLKOUT3_DUTY_CYCLE (0.500), .CLKOUT3_USE_FINE_PS ("FALSE"), .REF_JITTER1 (0.010)) mmcm_adv_inst // Output clocks (.CLKFBOUT (clkfbout), .CLKFBOUTB (clkfboutb_unused), .CLKOUT0 (clkout0), .CLKOUT0B (clkout0b_unused), .CLKOUT1 (clkout1), .CLKOUT1B (clkout1b_unused), .CLKOUT2 (clkout2), .CLKOUT2B (clkout2b_unused), .CLKOUT3 (clkout3), .CLKOUT3B (clkout3b_unused), .CLKOUT4 (clkout4_unused), .CLKOUT5 (clkout5_unused), .CLKOUT6 (clkout6_unused), // Input clock control .CLKFBIN (clkfbout), .CLKIN1 (clkin1), .CLKIN2 (1'b0), // Tied to always select the primary input clock .CLKINSEL (1'b1), // Ports for dynamic reconfiguration .DADDR (7'h0), .DCLK (1'b0), .DEN (1'b0), .DI (16'h0), .DO (do_unused), .DRDY (drdy_unused), .DWE (1'b0), // Ports for dynamic phase shift .PSCLK (1'b0), .PSEN (1'b0), .PSINCDEC (1'b0), .PSDONE (psdone_unused), // Other control and status signals .LOCKED (MMCM_LOCKED_OUT), .CLKINSTOPPED (clkinstopped_unused), .CLKFBSTOPPED (clkfbstopped_unused), .PWRDWN (1'b0), .RST (MMCM_RESET_IN)); // Output buffering //-----BUFG in feedback not necessary as a known phase relationship is not needed between the outclk and the usrclk------ //BUFG clkf_buf // (.O (clkfbout_buf), // .I (clkfbout)); BUFG clkout0_buf (.O (CLK0_OUT), .I (clkout0)); BUFG clkout1_buf (.O (CLK1_OUT), .I (clkout1)); //BUFG clkout2_buf // (.O (CLK2_OUT), // .I (clkout2)); //BUFG clkout3_buf // (.O (CLK3_OUT), // .I (clkout3)); assign CLK2_OUT = 1'b0; assign CLK3_OUT = 1'b0; endmodule
/////////////////////////////////////////////////////////////////////////////// // (c) Copyright 2023 Advanced Micro Devices, Inc. All rights reserved. // // This file contains confidential and proprietary information // of Advanced Micro Devices, Inc. and is protected under U.S. and // international copyright and other intellectual property // laws. // // DISCLAIMER // This disclaimer is not a license and does not grant any // rights to the materials distributed herewith. Except as // otherwise provided in a valid license issued to you by // AMD, and to the maximum extent permitted by applicable // law: (1) THESE MATERIALS ARE MADE AVAILABLE "AS IS" AND // WITH ALL FAULTS, AND AMD HEREBY DISCLAIMS ALL WARRANTIES // AND CONDITIONS, EXPRESS, IMPLIED, OR STATUTORY, INCLUDING // BUT NOT LIMITED TO WARRANTIES OF MERCHANTABILITY, NON- // INFRINGEMENT, OR FITNESS FOR ANY PARTICULAR PURPOSE; and // (2) AMD shall not be liable (whether in contract or tort, // including negligence, or under any other theory of // liability) for any loss or damage of any kind or nature // related to, arising under or in connection with these // materials, including for any direct, or any indirect, // special, incidental, or consequential loss or damage // (including loss of data, profits, goodwill, or any type of // loss or damage suffered as a result of any action brought // by a third party) even if such damage or loss was // reasonably foreseeable or AMD had been advised of the // possibility of the same. // // CRITICAL APPLICATIONS // AMD products are not designed or intended to be fail- // safe, or for use in any application requiring fail-safe // performance, such as life-support or safety devices or // systems, Class III medical devices, nuclear facilities, // applications related to the deployment of airbags, or any // other applications that could lead to death, personal // injury, or severe property or environmental damage // (individually and collectively, "Critical // Applications"). Customer assumes the sole risk and // liability of any use of AMD products in Critical // Applications, subject only to applicable laws and // regulations governing limitations on product liability. // // THIS COPYRIGHT NOTICE AND DISCLAIMER MUST BE RETAINED AS // PART OF THIS FILE AT ALL TIMES. // // /////////////////////////////////////////////////////////////////////////////// // // CLOCK_MODULE // // // Description: A module provided as a convenience for desingners using 2/4-byte // lane Aurora Modules. This module takes the GT reference clock as // input, and produces fabric clock on a global clock net suitable // for driving application logic connected to the Aurora User Interface. // `timescale 1 ns / 1 ps (* core_generation_info = "aurora_8b10b,aurora_8b10b_v11_1_19,{user_interface=AXI_4_Streaming,backchannel_mode=Sidebands,c_aurora_lanes=1,c_column_used=left,c_gt_clock_1=GTXQ2,c_gt_clock_2=None,c_gt_loc_1=X,c_gt_loc_10=X,c_gt_loc_11=X,c_gt_loc_12=X,c_gt_loc_13=X,c_gt_loc_14=X,c_gt_loc_15=X,c_gt_loc_16=X,c_gt_loc_17=X,c_gt_loc_18=X,c_gt_loc_19=X,c_gt_loc_2=X,c_gt_loc_20=X,c_gt_loc_21=X,c_gt_loc_22=X,c_gt_loc_23=X,c_gt_loc_24=X,c_gt_loc_25=X,c_gt_loc_26=X,c_gt_loc_27=X,c_gt_loc_28=X,c_gt_loc_29=X,c_gt_loc_3=X,c_gt_loc_30=X,c_gt_loc_31=X,c_gt_loc_32=X,c_gt_loc_33=X,c_gt_loc_34=X,c_gt_loc_35=X,c_gt_loc_36=X,c_gt_loc_37=X,c_gt_loc_38=X,c_gt_loc_39=X,c_gt_loc_4=X,c_gt_loc_40=X,c_gt_loc_41=X,c_gt_loc_42=X,c_gt_loc_43=X,c_gt_loc_44=X,c_gt_loc_45=X,c_gt_loc_46=X,c_gt_loc_47=X,c_gt_loc_48=X,c_gt_loc_5=X,c_gt_loc_6=X,c_gt_loc_7=X,c_gt_loc_8=X,c_gt_loc_9=1,c_lane_width=4,c_line_rate=62500,c_nfc=false,c_nfc_mode=IMM,c_refclk_frequency=156250,c_simplex=false,c_simplex_mode=TX,c_stream=false,c_ufc=true,flow_mode=UFC,interface_mode=Framing,dataflow_config=Duplex}" *) module aurora_8b10b_CLOCK_MODULE ( input GT_CLK , input GT_CLK_LOCKED , output USER_CLK , output SYNC_CLK , output PLL_NOT_LOCKED ); BUFG user_clk_buf_i ( .I ( GT_CLK ), .O ( USER_CLK ) ); assign SYNC_CLK = USER_CLK; assign PLL_NOT_LOCKED = !GT_CLK_LOCKED; endmodule
以下是搬运的笔记
参考:
https://www.xilinx.com/products/intellectual-property/aurora8b10b.html#documentation
https://docs.amd.com/r/en-US/pg046-aurora-8b10b
https://docs.amd.com/v/u/en-US/aurora_8b10b_ds797
https://mp.weixin.qq.com/s/gT4QUgvoFF6UI0PAhfEPvQ
补丁:
Aurora 系 IP内部都是不含COMMON(QPLL)的;
需要开发者自行例化然后接入,这是为了方便时钟共享;
Aurora 8b/10b仅支持小于6.6G的线速率;
64b/66b则支持10.3125G
简介
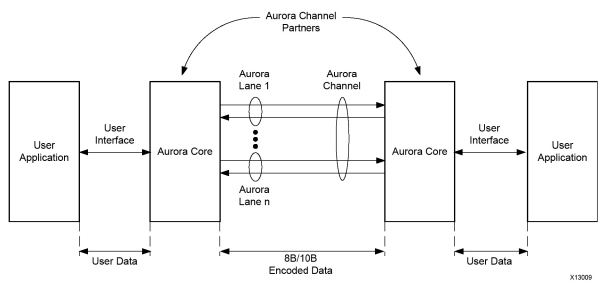
Aurora 8B/10B 内核(此图)是一种可扩展的轻量级链路层协议,用于高速串行通信。
该协议是开放的,可以使用 AMD FPGA 技术实现。
该协议通常用于需要简单、低成本、高速率数据通道的应用,并用于使用一个或多个收发器在设备之间传输数据。
Aurora 8B/10B 核心在连接到 Aurora 通道合作伙伴时会自动初始化通道,并以帧或数据流的形式在通道上自由传输数据。
Aurora 帧可以是任意大小,并且可以随时中断。
有效数据字节之间的间隙会自动填充空闲字节,以保持锁定并防止过度的电磁干扰。
流量控制可用于降低传入数据的速率或通过通道发送简短的高优先级消息。
流是单个、无休止的帧。在没有数据的情况下,将传输空闲字节以保持链接处于活动状态。
Aurora 8B/10B 核心使用 8B/10B 编码规则检测单位错误和大多数多位错误。过多的位错误、断开连接或设备故障会导致核心重置并尝试重新初始化新通道。
应用
Aurora 8B/10B 内核可用于各种应用,因为它们具有低资源成本、可扩展的吞吐量和灵活的数据接口。内核应用示例包括:
•芯片到芯片链接:用高速串行连接取代芯片之间的并行连接可以显著减少 PCB 上所需的走线和层数。内核提供使用 GTP、GTX 和 GTH 收发器所需的逻辑,同时将 FPGA 资源成本降至最低。
•板到板和背板链接:内核使用标准 8B/10B 编码,使其与许多现有的电缆和背板硬件标准兼容。Aurora 8B/10B 内核可以进行扩展,包括线路速率和通道宽度,从而允许在新的高性能系统中使用廉价的传统硬件。
•单工连接(单向):Aurora 协议提供了执行单向通道初始化的替代方法,使得在没有反向通道的情况下可以使用 GTP、GTX 和 GTH 收发器,并降低因未使用全双工资源而产生的成本。
用户数据和流控
https://mp.weixin.qq.com/s/gT4QUgvoFF6UI0PAhfEPvQ
其中用户与IP之间可以传输两种数据,一种是用户的发送或者接收的数据,称为用户PDU。另一种是用于控制发送数据速率的指令(简称流控),称为用户流量控制(User Flow Control Messages)。
Aurora 8B/10B协议发送数据的流程如下所示,需要经过Padding、组帧、8B/10B编码、串行化等几个过程。
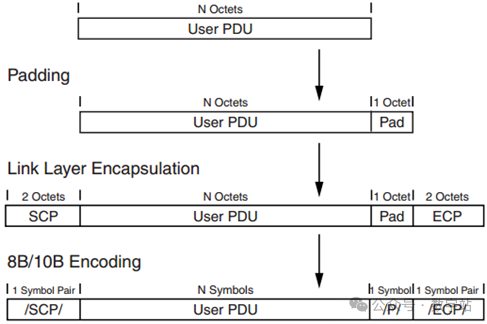
Padding:因为Aurora 8B/10B信道传输的最小信息单位是两个字节,因此首先需要检测用户待发送数据字节数为奇数还是偶数。
如果是奇数,则在用户待发送数据后面补充一个值为0x9C(K28.4)的K码Pad数据。
组帧:就是在开始发送数据前发送2字节的起始码SCP(值分别为K28.2、K27.7),在帧尾发送两字节停止位ECP(值分别为K29.7、K30.7)。
8B/10B编码:
在传输之前,通过高速收发器的PCS中的8B/10B进行编码,用于填充数据的Pad被编码为控制字符,其余被编码为数据字符。
编码后的数据被串行化,以差分不归零(NRZ)格式传输。
Aurora 8B/10B协议接收数据的流程如下所示,包含串并转换、8B/10B解码、去除帧头帧尾和空闲字符、去除Pad等几个阶段。
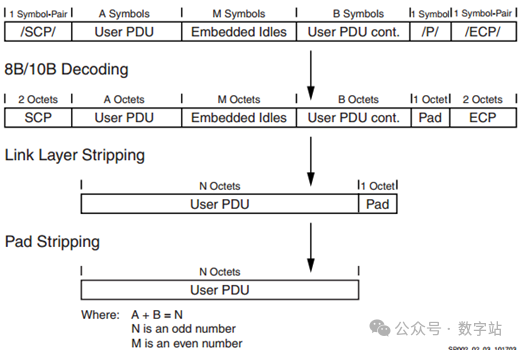
串并转换:串行数据流以差分NRZ格式接收,将该数据反序列化为10位数据和控制符号。
8B/10B解码:串并转换后,链路层有效负载被解码为八位字节流。
在解码过程中,必须把停止位ECP之前的填充字符Pad标记,便于后续去除。
去除链路层:把解码后用户数据流中的起始位SCP、停止位ECP、空闲字符去除。
空闲字符可能是通过流控操作发送端插入的,
但空闲序列必须在偶数字节用户数据之后开始插入,并且插入偶数个空闲字符。去
除Pad:最后去除填充的Pad字符0x9C(K28.4),之后把得到的数据传输给用户。
Aurora 8B/10B协议除了常规的用户数据收发,主要特点是支持可选的流量控制机制和多通道绑定机制。
可选的流量控制机制提供了低延迟流量控制,防止因为发送速率和接收速率不同导致的数据丢失。
Aurora 8B/10B协议支持User Flow Control(UFC)和Native Flow Control(NFC)两种流量控制机制,相关的流量控制方案如下图所示,下文将对这两种机制进行详细讲解。
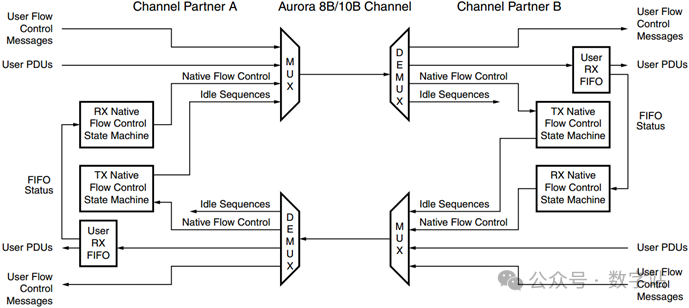
用户流量控制(UFC)
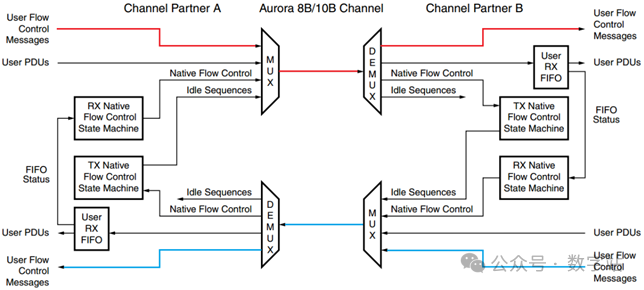
这个接口主要用于传输一些高优先级的数据,将UFC数据插入到用户待发送数据(UPDU)中,优先传输,一般用来传输比较重要的控制信息。下图是UFC数据的流向图,均是单向传输。
UFC开始传输后不能被时钟补偿序列、NFC或空闲序列中断。
因为UFC会中断用户数据的发送,因此Aurora 8B/10B协议实现可能需要将用户待发送数据暂存,防止数据丢失。
UFC的数据格式如下图所示,长度为4到18个字节,
第一个字节是用户流控制开始字符(SUF),是一个K码,值为K28.4。
第二个字节称为命令字节的数据字符,之后紧跟着发送用户需要传输的高优先级数据,数据长度为2到16个字节。
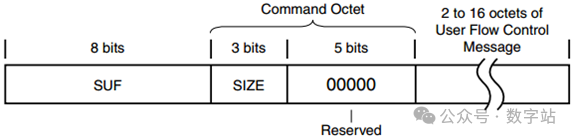
注意K28.4可以用于SUF和填充,区别在于填充字符后面只能跟一个控制字符,不能跟一个数据字符。
UFC消息的长度为SIZE取值乘2加2,即SIZE*2+2。因为SIZE长度只有三位,因此UFC消息大小可以是2到16之间的任意偶数字节。
本地流量控制(NFC)
本地流量控制(Native Flow Control,简称NFC)是一种链路层流量控制机制,由Aurora 8B/10B接口生成并解释,而UFC是上层实现的机制。
NFC的机制其实比较简单,如下图所示,高速收发器A通过蓝色走线向高速收发器B传输数据。
由于双方的速率可能并不一致,导致高速收发器B的用户接收FIFO快溢出了,此时高速收发器B会生成NFC消息,然后通过发送端口传输给高速收发器A的接收端。
高速收发器A解析NFC消息之后,可能会暂停发送用户数据(蓝线暂停),而是发送空闲数据(黄线发送),接收端接收空闲数据会直接丢弃,不会存入接收FIFO,通过上述机制来防止接收FIFO溢出。
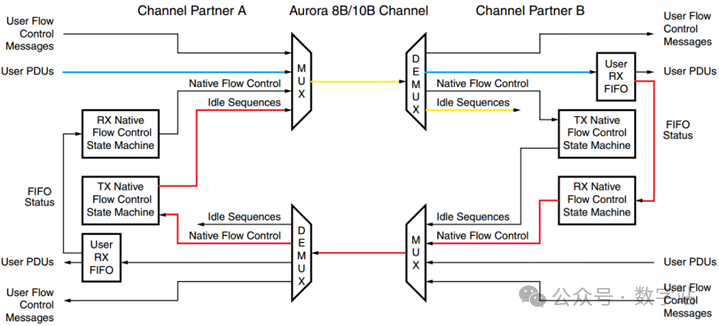
注意NFC的优先级低于UFC,这是因为发送的UFC消息也不会存入接收端的FIFO中,即UFC的传输对接收端的FIFO溢出没有影响。
高速收发器A的发送端通过在请求的时间间隔内暂停发送用户数据,来响应接收端的NFC控制。
这段时间除了可以发送空闲序列之外,暂停还可以传输UFC和NFC数据,因为这些都没有存储在接收端的FIFO中。
发送端暂停的时间与接收端通过NFC传输的数据有关,
NFC的数据格式如下图所示,长度为两字节。
第一个字节是本地流控制开始字符(SNF),第二个字节是数据字符,称为命令字节。

命令字节包含暂停字段,该字段指定发送空闲字符的时钟周期数,下表显示了暂停字段的编码。
NFC暂停字段编码
|
PAUSE |
暂停间隔(符号) |
|
0000 |
0(XON) |
|
0001 |
2 |
|
0010 |
4 |
|
0011 |
8 |
|
0100 |
16 |
|
0101 |
32 |
|
0110 |
64 |
|
0111 |
128 |
|
1000 |
256 |
|
1001~1110 |
保留 |
|
1111 |
无限(XOFF) |
当发送端口收到接收端的NFC数据时,如果Aurora 8B/10B接口正在发送用户数据,
发送端可以通过完成模式或立即模式两种方式之一响应NFC。
完成模式需要等待用户这一帧数据发送完成之后才执行暂停的时间,
而立即模式可以直接中断用户当前数据的发送,直接暂停规定时间,一般采用立即模式;(存疑)
通过上面分析可知,NFC与用户收发数据的关系不大,是在Aurora 8B/10B协议内部完成的。
可能有点影响的是暂停时间设置多大合适,要考虑接收端与发送端传输的延迟,不能发送端接收到NFC时,接收端的FIFO就已经溢出了。
端口
Aurora 8B/10B 核心的主要功能模块包括:
• 通道逻辑:每个 GTP、GTX 或 GTH 收发器(以下称为收发器)由通道逻辑模块的一个实例驱动,该模块初始化每个单独的收发器并处理控制字符的编码和解码以及错误检测。
• 全局逻辑:全局逻辑模块执行通道初始化的绑定和验证阶段。在操作期间,该模块生成 Aurora 协议所需的随机空闲字符并监控所有通道逻辑模块的错误。
• RX 用户界面:AXI4-Stream RX 用户界面将数据从通道移动到应用程序并执行流控制功能。
• TX 用户界面:AXI4-Stream TX 用户界面将数据从应用程序移动到通道并执行流控制 TX 功能。标准时钟补偿模块嵌入在核心内部。该模块控制时钟补偿 (CC) 字符的定期传输。
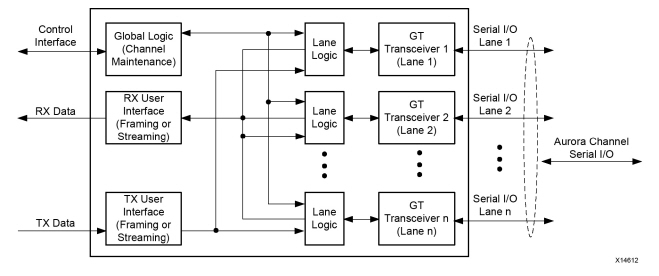

端口描述
用于生成每个 Aurora 8B/10B 核心的参数决定了该特定核心可用的接口。
接口在 IP 符号中可见,如图所示。
在 IP 符号中,如果左键单击接口旁边的 + 号,则可以看到分组在其中的端口。
在本节(即端口描述)中,通常,接口显示为单行条目,后跟分组在其中的端口。
例如,在表:用户 I/O 端口 (TX) (TX) 中,USER_DATA_S_AXIS_TX 是接口,s_axi_tx_* 端口分组到该接口中。核心有四到六个接口。
用户端口
Aurora 8B/10B 核心可采用帧或流式用户数据接口生成。此接口包括流式或帧式数据传输所需的所有端口。
帧式用户界面符合 AMBA® AXI4-Stream 协议规范 [参考文献 4],并包含传输和接收帧式用户数据所需的信号。
流式接口允许在没有帧分隔符的情况下发送数据,操作更简单,并且比帧式接口占用更少的资源。数据端口宽度取决于通道宽度和所选通道数。
顶层架构
Aurora 8B/10B顶层架构如下图所示,包括收发器以及控制逻辑和用户接口。
该IP提供给用户两种接口,即帧接口和流接口。
其中帧接口为axi4_Stream接口,而流接口只有数据和有效指示信号,没有掩码信号和最后字节指示信号。
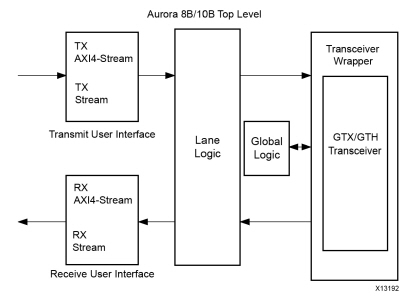
本节提供流式传输和帧传输接口的详细信息。用户界面逻辑的设计应符合此处所述的相应接口的时序要求。
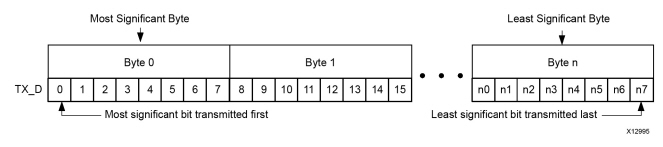
AXI4-Stream Bit Ordering
Aurora 8B/10B 核心采用升序排序。它们首先传输和接收最高有效字节的最高有效位。此图显示了 Aurora 8B/10B 核心的 AXI4-Stream 数据接口的 n 字节示例的组织。
大端发送;
帧接口(Framing Interface)
帧接口的相关信号流向如下图所示,与AXI4-Stream接口信号基本一致,该接口可以传输任意字节数据。
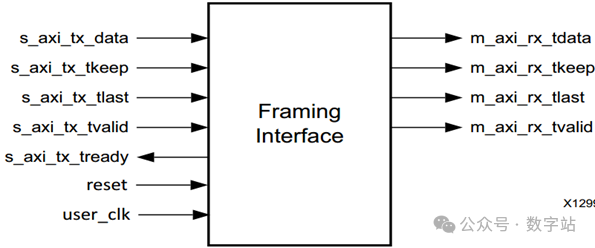
User Interface Ports
Table: User I/O Ports (TX) and Table: User I/O Ports (RX) list duplex and simplex core AXI4-Stream TX and RX data port descriptions.
|
Name |
Direction |
Clock Domain |
Description |
|---|---|---|---|
|
USER_DATA_S_AXI_TX |
|||
|
s_axi_tx_tdata[0:(8n–1)] or s_axi_tx_tdata[(8n–1):0] |
Input |
user_clk |
Outgoing data. n is the number of bytes computed as Number of lanes x Lane Width.
|
|
s_axi_tx_tready |
Output |
user_clk |
Asserted when signals from the source are accepted and when outgoing data is ready to send. |
|
s_axi_tx_tlast(1) |
Input |
user_clk |
Signals the end of the frame. |
|
s_axi_tx_tkeep[0:(n–1)] or s_axi_tx_tkeep[(n–1):0](1) |
Input |
user_clk |
Specifies the number of valid bytes in the last data beat; valid only while s_axi_tx_tlast is asserted. s_axi_tx_tkeep is the byte qualifier that indicates whether the content of the associated byte of s_axi_tx_tdata is valid or not. The Aurora 8B/10B core expects the data to be filled continuously from LSB to MSB. There cannot be invalid bytes interleaved with the valid s_axi_tx_tdata bus. |
|
s_axi_tx_tvalid |
Input |
user_clk |
Asserted when outgoing AXI4-Stream signals or signals from the source are valid. |
|
Notes: 1.This port is not available if the Streaming interface option is chosen. |
|||
|
Name |
Direction |
Clock Domain |
Description |
|---|---|---|---|
|
USER_DATA_M_AXI_RX |
|||
|
m_axi_rx_tdata[0:8(n–1)] or m_axi_rx_tdata[8(n–1):0] |
Output |
user_clk |
Incoming data from channel partner (Ascending bit order). |
|
m_axi_rx_tlast(1) |
Output |
user_clk |
Signals the end of the incoming frame (asserted for a single user clock cycle). |
|
m_axi_rx_tkeep[0:(n–1)] or m_axi_rx_tkeep[(n–1):0](1) |
Output |
user_clk |
Specifies the number of valid bytes in the last data beat. |
|
m_axi_rx_tvalid |
Output |
user_clk |
Asserted when outgoing data and control signals or data and control signals from an Aurora 8B/10B core are valid. |
|
Notes: 1.This port is not available if the Streaming interface option is chosen. |
|||
注意下图是Aurora 8B/10B协议的高速收发器传输数据的帧格式,
在前文讲解Aurora 8B/10B协议时详细讲解过,注意SCP和ECP以字节为单位。
因此接收用户数据之后,可能会像之前自定义PHY那样去对数据进行拼接,但是这些事情都是在Aurora 8B/10B IP内部完成的,用户不需要关心,只需要了解即可。

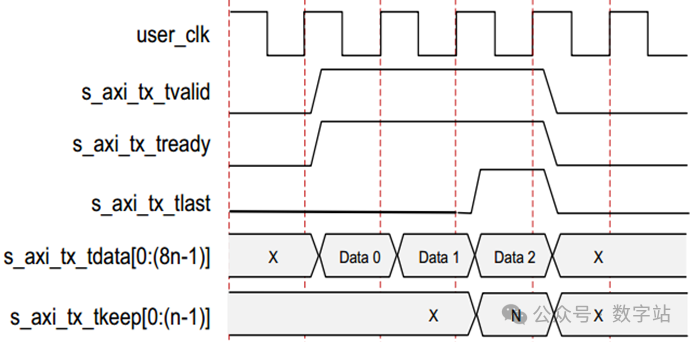
户发送端口的时序如下图所示,待发送数据位宽为n字节,发送的数据量为3n字节,需要三个时钟传输。
s_axi_tx_tready拉高表示AXI4_Steram接口已准备好接收数据。
起始位/SCP/放置在通道的前两个字节上,以指示帧的开始,然后前n–2个用户数据字节放在通道上。
由于/SCP/需要偏移,每个用户数据的最后两个字节总是延迟一个周期,并在下一时钟的前两个字节发送。
s_axi_tx_tlast拉高表示结束用户数据传输,通过s_axi_tx_tkeep总线上的相应值,实现任意字节的传输。
下图中的s_axi_tx_tkeep设置为N,表示最后一个数据拍中的所有字节都有效。
当s_axi_tx_tlast拉高时,s_axi_tx_tready在下一个时钟周期拉低,
内核利用数据流中的间隙发送最终偏移数据字节和停止位/ECP/,指示帧结束。
s_axi_tx_tready在下一个周期重新拉高,以允许数据传输继续进行。
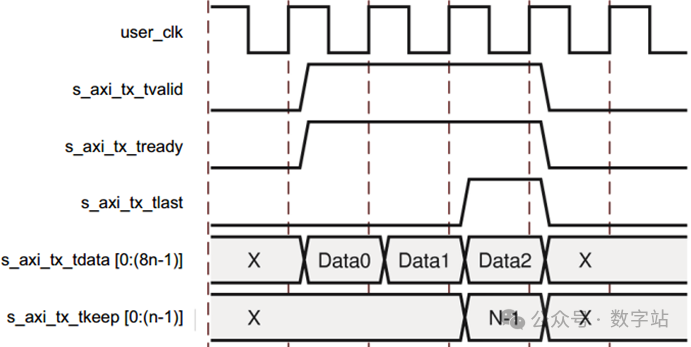
Aurora 8B/10B每次传输的数据必须是偶数字节,如果用户数据为奇数字节,则会在数据末尾添加一个Pad字符变为偶数字节。
如下图所示,用户最后一个数据宽度为n-1字节,IP内部在组帧时,会在有效数据末尾添加一个Pad字符。(KEEP也要改变的)
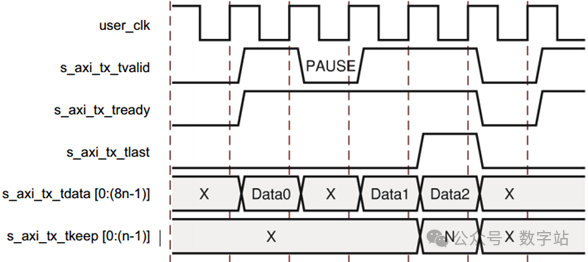
用户接口使用帧格式传输数据,支持暂停数据传输功能,如下图所示。通过拉低s_axi_tx_tvalid并发送空闲序列来暂停前n个字节后的数据流,直到s_axi_tx_tvalid拉高为止。
从前文可知,时钟补偿的优先级是最高的,所以数据传输可能会被时钟补偿序列打断,对应时序图如下所示。时钟补偿序列会在每10000字节的通道上产生12字节的开销。
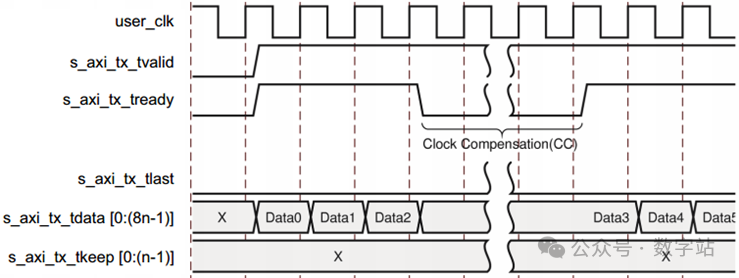
接收端口内部没有用于存储用户数据的缓冲器,因此在接收端口信号中没有m_axi_rx_tready信号。
m_axi_rx_tvalid信号与Aurora 8B/10B内核各帧的第一个数据同时拉高,m_axi_rx_tlast与各帧的最后一个数据同时拉高,m_axi_rx_tkeep端口指示每帧最后一个数据中的有效字节数,
m_axi_rx_tkeep信号仅在m_axi_rx_tlast拉高时有效。接收数据的时序如下图所示,m_axi_rx_tvalid为高电平时表示m_axi_rx_tdata对应数据有效,其余时间无效。
手册中还对该接口传输的效率做了计算,通过一个公式可以计算,也就是计算起始位、停止位、空闲数据、时钟补偿序列所带来的开销,
从而得到数据传输速率,最终通道越多,数据位宽越大、帧越长,效率越高。
用户数据位宽采用8字节、4通道传输一帧数据长度为1000,则效率可以达到99.14%。有兴趣的可以查看手册,获取具体计算方式。
流接口(Streaming Interface)
初始化后,除了发送时钟补偿序列时,通道始终可用于写入。
该接口特别简单,但是输入和输出数据位宽必须与数据信号位宽保持一致,不能传输任意字节数据。
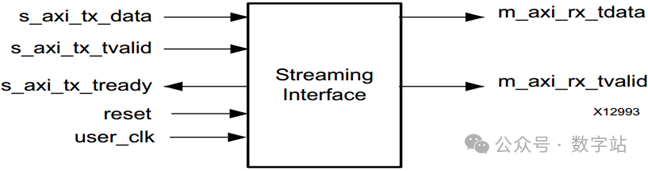
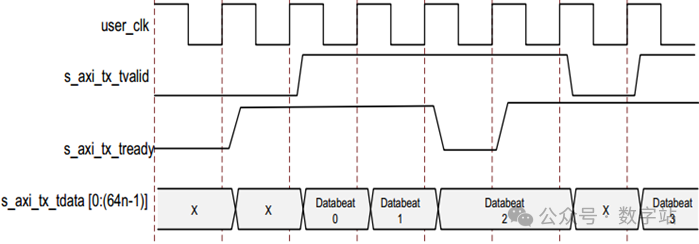
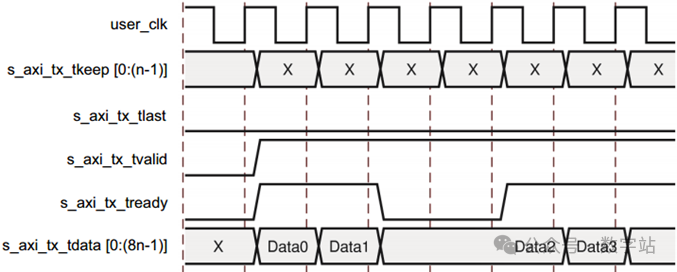
Aurora 8B/10B内核通过拉高s_axi_tx_tready来表示已准备好传输数据。
一个周期后,用户逻辑拉高s_axi_tx_tvalid信号并将数据置于s_axi_tx_tdata,开始传输数据,如下图所示。
在下图中,发送数据D0和D1之后,Aurora 8B/10B内核拉低就绪信号s_axi_tx_tready,直到下一个时钟周期s_axi_tx_tready信号再次拉高时才会传输数据D2。
然后,用户逻辑在下一个时钟周期拉低s_axi_tx_tvalid,在s_axi_tx_tvalid和s_axi_tx_tready都拉高之前不传输数据。
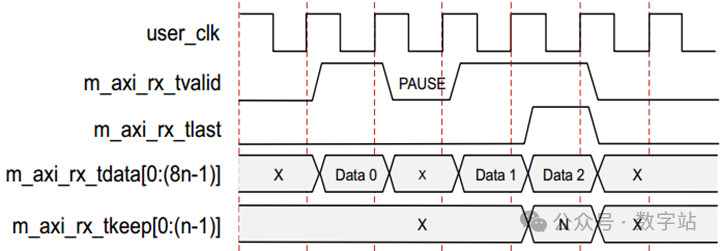
接收

流模式下不做对齐,因为没用KEEP,建议使用帧模式。
流控端口
一些差别:
UFC:在UFC 握手期间提供报文,
握手拉低后在DATA通道提供UFC数据;
前文在Aurora 8B/10B协议中讲解了两种流量控制(UFC和NFC)的基本原理,
本节介绍xilinx的Aurora 8B/10B IP如何使用这两种流量控制。
注意只有使用成帧接口的内核才有两个可选的流量控制接口。
本地流量控制(NFC)控制全双工通道接收端的数据传输速率,用户流控制(UFC)为控制操作提供高优先级消息。
只有在配置IP时开启UFC功能,后续生成的IP才会有相应的功能,IP配置界面如下所示,当选定帧格式传输数据时,可以单独启用UFC功能,也可以同时启用UFC和NFC功能。
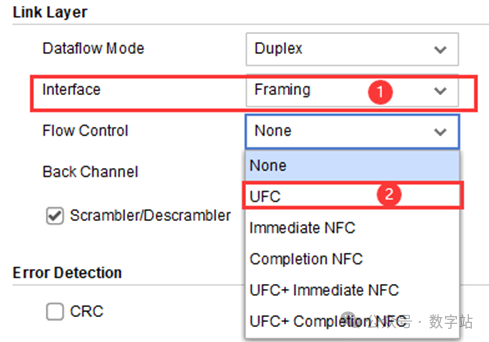
UFC对应的端口信号如下图所示,先看接收端的数据信号,就是axi_stream接口,与接收数据端口一致,因为UFC数据也是通过用户数据端口发送的。
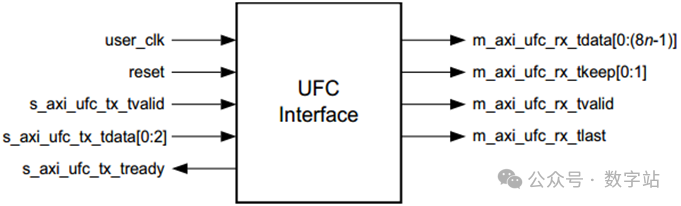
注意axi_ufc_tx_tdata并不是需要传输的UFC数据,而是UFC数据个数。
下图是UFC传输数据格式,第一字节是UFC传输的开始字符,SIZE表示其后面UFC字符长度,axi_ufc_tx_tdata的值就是SIZE对应数值,位宽也是一致的。
UFC消息的长度为SIZE取值乘2加2,即SIZE*2+2。因为SIZE长度只有三位,因此UFC消息大小可以是2到16之间的任意偶数字节。

UFC数据是通过s_axi_tx_tdata信号传输的,s_axi_ufc_tx_tready拉高后的第一个时钟开始。
当s_axi_tx_tdata端口用于UFC数据时,内核会解拉低s_axi_tx_tready。
手册给出用户发送数据和UFC消息的机制如下,当s_axi_tx_tready有效时发送用户数据,否则发送UFC数据。

注意:只有在完成当前UFC请求后才能提出新的UFC请求且IP可能不支持背靠背UFC请求。
下图显示了传输单周期UFC消息的程序,在这种情况下,4字节的UFC消息通过4字节的发送数据接口发送。
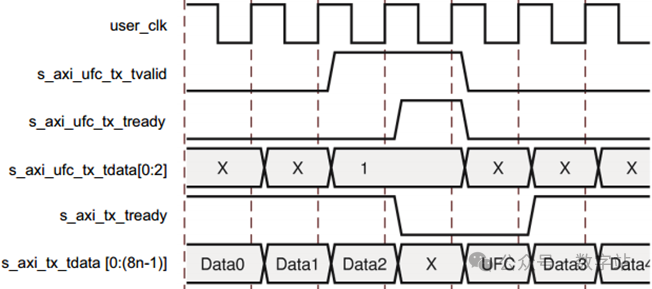
注意:s_axi _tx_tready信号在这两个周期内无效,Aurora 8B/10B内核利用数据流中的这一间隙来传输UFC报头和消息数据。
如下图所示,位宽为2字节的用户发送数据接口传输4字节的UFC消息。
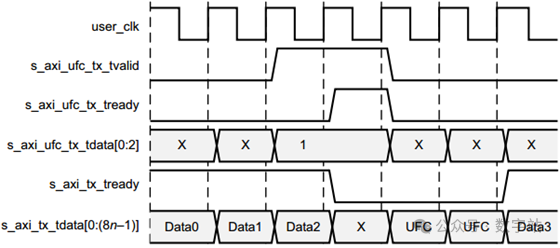
s_axi_tx_tready被拉低三个周期,
一个周期用于在s_axi_ufc_tx_tready周期内发送的ufc报头,
两个周期用于UFC数据。
当Aurora 8B/10B内核收到UFC消息时,通过专用的UFC AXI4-Stream接口将数据输出给用户。
接收的UFC消息位于m_axi_ufc_rx_tdata端口,m_axi_ufc_rx_tvalid表示消息数据的开始,m_axi_ufc_rx_tlast表示结束,m_axi_ufc_rx_tkeep用于显示消息最后一个周期内m_axi_ufc_rx_tdata上的有效字节数。
下图显示了一个具有4字节数据接口的Aurora 8B/10B内核接收4字节UFC消息。
m_axi_ufc_rx_tkeep设置为4‘hF,表示接口只有四个最高有效字节有效。
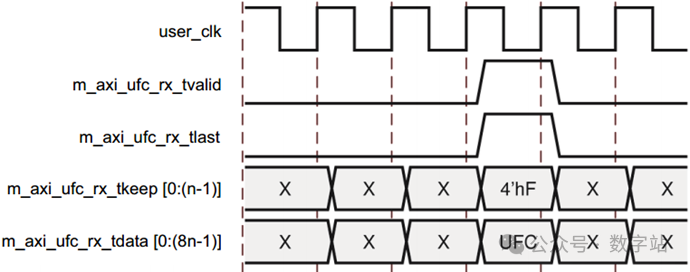
图22 接收单周期UFC消息下图显示了一个具有4字节接口的Aurora 8B/10B内核接收8字节消息,输出数据帧有两个周期长,
m_axi_ufc_rx_tkeep在第二个周期设为4‘hF,表示所有四个字节的数据都有效。
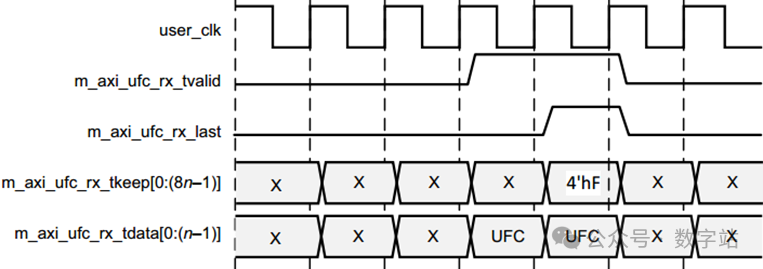
NFC界面
Aurora 8B/10B协议包括本地流量控制(NFC)接口如下图所示,通常用于防止接收端的FIFO溢出。
该接口允许接收器通过指定必须放入数据流的空闲数据个数来控制数据接收速率,
甚至可以通过请求发送器暂时只发送空闲信号(XOFF)来完全关闭数据流。
NFC接口包括一个用于发送nfc消息的请求(s_axi_nfc_tx_tvalid)和一个确认(s_axi_nfc_tx_tready)端口,
以及一个用于指定所请求的空闲周期数的4位s_axi_nfc_tx_tdata端口。
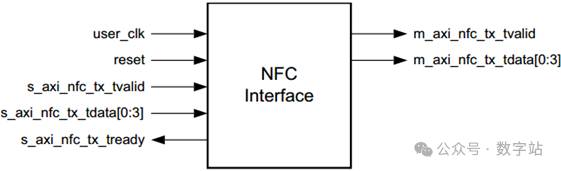
图24 Aurora 8B/10B内核NFC接口如果需要使用NFC接口,则在配置IP时需要勾选下图的四个NFC选项之一,NFC有完成模式和立即模式两种,前文也讲述过两者区别,一般使用立即模式比较好。
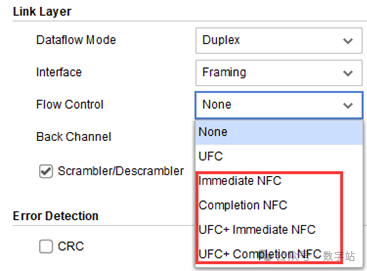
前文详细讲解过NFC实现的机制和原理,本质就是接收端FIFO快要溢出时,像发送端传输一个NFC消息,让发送端在指定周期内发送空闲字符,停止发送数据,
高速收发器A解析NFC消息之后,可能会暂停发送用户数据(蓝线暂停),而是发送空闲数据(黄线发送),接收端接收空闲数据会直接丢弃,不会存入接收FIFO,通过上述机制来防止接收FIF溢出。
NFC的优先级低于UFC,这是因为发送的UFC消息也不会存入接收端的FIFO中,即UFC的传输对接收端的FIFO溢出没有影响。
高速收发器A的发送端通过在请求的时间间隔内暂停发送用户数据,来响应接收端的NFC控制。
这段时间除了可以发送空闲序列之外,暂停还可以传输UFC和NFC数据,因为这些都没有存储在接收端的FIFO中。
发送端暂停的时间与接收端通过NFC传输的数据有关,NFC的数据格式如下图所示,长度为两字节。第一个字节是本地流控制开始字符(SNF),第二个字节是数据字符,称为命令字节。

如下图所示,当数据端口s_axi_tx_tdata发送NFC空闲字符时,s_axi_tx_tready为低电平,此时不能传输用户数据。
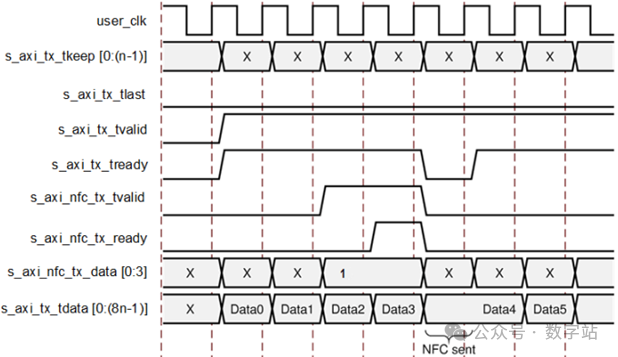
NFC在握手期间传递报文,握手拉低后传递NFC数据,但NFC数据只有命令,或者说延迟的标识;
表1 NFC暂停字段编码
|
PAUSE |
暂停间隔(符号) |
|
0000 |
0(XON) |
|
0001 |
2 |
|
0010 |
4 |
|
0011 |
8 |
|
0100 |
16 |
|
0101 |
32 |
|
0110 |
64 |
|
0111 |
128 |
|
1000 |
256 |
|
1001~1110 |
保留 |
|
1111 |
无限(XOFF) |
下图显示收到NFC消息时用户发送数据的端口时序。
在这种情况下,NFC数据为0001,请求发送端口发送两个空闲数据拍。
IP拉低用户接口的数据应答信号s_axi_tx_tready,
直到发送足够的空闲数据来满足请求。下图中内核在即时NFC模式下运行,NFC空闲被立即插入。Aurora 8B/10B内核也可以在完成模式下运行,在完成模式下,NFC空闲仅插入帧之间。
由上述叙述可知,UFC是需要用户去控制s_axi_tx_tdata来传输数据的,而NFC由于是发送的空闲数据,因此用于其实不需要干预其数据信号。
状态和控制接口
Aurora 8B/10B内核的状态和控制端口允许应用程序监控信道并使用收发器的内置功能。
本节提供了状态和控制接口、收发器串行I/O接口以及专用于单工模块的初始化端口的图表和端口描述。
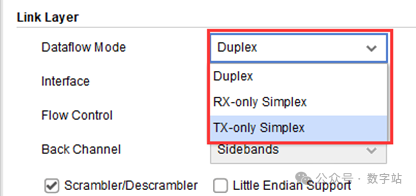
如下图所示,在配置IP时,需要选择使用全双工还是单工模式,默认使用全双工模式传输数据。
下图表示不同模式下,状态信号和控制信号类型的区别。

下表列出了一些比较常用的控制信号和状态信号,一些不常用的可以自行参考手册,这里列多了就没有看下去的耐心了,所以列的都是重要的。
表2 状态和控制端口
|
信号 |
I/O |
含义 |
|
channel_up |
O |
Aurora 8B/10B通道初始化完成且通道准备好数据传输时置位。 |
|
lane_up[0:m–1] |
O |
每位代表一个通道,该通道初始化成功时对应位置位。 |
|
frame_err |
O |
检测到通道帧或协议错误,将该信号拉高一个时钟。 |
|
hard_err |
O |
检测到硬错误时拉高,直到Aurora 8B/10B内核复位。 |
|
soft_err |
O |
在传入的串行流中检测到软错误时拉高。 |
|
Reset |
I |
复位Aurora 8B/10B内核,高电平有效,必须保持至少六个user_clk周期。 |
|
gt_reset |
I |
当模块首次上电时拉高,复位收发器的PCS和PMA。该信号使用init_clk_in消抖,且必须拉高六个init_clk_in周期。 |
|
link_reset_out |
O |
热插拔计数到期时变为高电平。 |
|
init_clk_in |
I |
当gt_reset有效时user_clk停止,建议init_clk_in的频率低于GT参考时钟输入频率。 |
1、软件错误:在高速收发器的运行过程中,由于通道噪声等因素的影响,数据传输可能会遇到错误。
8B/10B编码技术能够检测出所有单比特数据错误以及大多数多比特数据错误。当检测到这些错误时,会拉高软错误(soft_err)信号。
如果在短时间内检测到大量软错误,系统将执行复位操作。
2、硬件错误:Aurora 8B/10B可以监控每个收发器的硬件错误。硬件错误可能包括接收端或发送端buffer溢出、发送端和接收端时钟源频率差异超过100ppm等。
当检测到过多的软错误时,这可能触发硬件错误,会拉高硬件错误(hard_err)信号。
一旦检测到硬件错误,Aurora 8B/10B IP会自动进行复位并尝试重新初始化。
如果该问题得到解决,通道可以重新初始化,并建立新的连接。
3、帧错误:Aurora 8B/10B IP可以检测axi_stream的帧错误,帧错误可能包括空帧、连续的帧开始符号或连续的帧结束符号。
检测到帧错误后,拉高帧错误(frame_err)信号。
Aurora 8B/10B在上电、复位或硬错误后自动初始化,直到通道准备就绪。
lane_up总线指示通道中的哪些通道已完成通道初始化程序。
只有在内核完成整个初始化程序后,channel_up才会置位。
在channel_up有效之前,Aurora 8B/10B内核无法接收数据。
Aurora 8B/10B IP包含reset和gt_reset两个复位信号,前者用于复位除高速收发器以外的逻辑功能,后者用于复位高速收发器,本文以全双工模式讲解复位。
Aurora 8B/10B内核的复位至少拉高六个user_clk时间周期,channel_up会在三个user_clk周期后拉低,如下图所示。

图30 双工内核中的复位拉高下图显示了复位高速收发器的时序,gt_reset至少拉高六个init_clk_in时间周期。
由于user_clk是由txoutclk生成的,当高速收发器复位时,txoutclk会停止产生,因此经过几个时钟之后user_clk也会停止产生,之后channel_up拉低。

图31 双工内核中的gt_reset拉高两个复位信号的上电时序应该如下所示,开始均处于高电平,当首先拉低gt_reset,当高速收发器复位完成,稳定产生user_clk之后,reset才拉低,然后对逻辑部分完成复位。
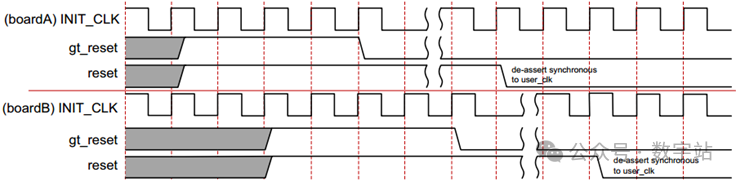
当内核工作过程中,如果要进入复位状态,应该遵循以下时序。首先应该拉高reset,让内核逻辑进入复位,之后拉高gt_reset,防止停止产生user_clk后内核逻辑卡死。

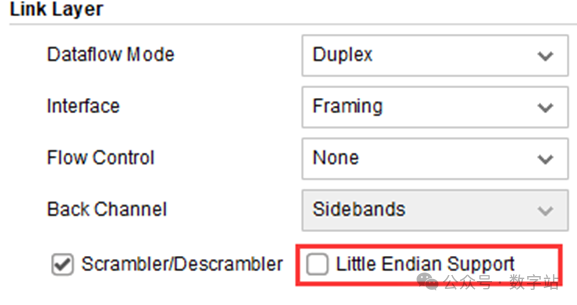
注意该IP的用户数据的大端模式可以更改为小端模式,更改方式如下图所示,在配置IP时勾选“Little Endian Support”即可。
延迟时间
通过Aurora 8B/10B内核的延迟是由通过协议引擎(PE,FPGA可编程逻辑实现)和收发器的管道延迟引起的。
PE流水线延迟随着AXI4流接口宽度的增加而增加,收发器延迟取决于所选收发器的特性和属性。
注意:这些延迟不包括因Aurora 8B/10B通道两端之间的串行连接长度(PCB走线等)而产生的延迟。下图显示了默认配置下数据路径的延迟,延迟可能因设计中使用的收发器和IP配置而异。

Aurora 8B/10B内核吞吐量取决于收发器数量和目标线路速率。
使用20%的Aurora 8B/10B协议编码开销和0.5 Gb/s至6.6 Gb/s的线路速率范围计算单通道设计和16通道设计的吞吐量,得到吞吐量范围[0.4,84.48]Gb/s。
本文的重点在于前两部分,用户需要着重了解用户接口以及流控原理和实现方式,才能够正常使用该IP。
通过本文的分析可知,该IP就是对GTX收发器的上层封装、内部完成组帧和接收端字节对齐、流控、时钟补偿、CRC校验等等功能。
相比自定义PHY,该IP更加简单,增加流控功能后接收端接收数据会更加准确,防止数据溢出,
缺点在于用户不能操作GTX,GTX的发送通道和接收通道必须使用buffer同步数据,不能使用相位对齐电路,导致数据延迟会比较大。如果设计对延时比较敏感,可能该IP将不再适用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号