高速接口自用笔记:GT基础(二)
FPGA中相同BANK的电压需要一致,以实现高效的性能。
本章是对GT基础(一)的补充。
大量搬运:公众号-数字站:
https://mp.weixin.qq.com/s/Z8ti7DIMdWEh8ogM0SQU4g
https://mp.weixin.qq.com/s/0YoA9jhBOheZFwtTDJ75aQ
老哥写的很好,推荐都去看。
小知识点:
0.MIPI是小端序;GT也是小端序;低字节数据先到来,存储在低位,写入FIFO的时候需要把他们调转到高位,因为FIFO里从高到低读出;
1.通过原语BUFDGE得到的时钟,可以去往QPLL,QPLL以及作为用户时钟(提供给PCS);
2.PMA的时钟可以来源于QPLL和CPLL,高性能情况下选择QPLL(一般当线速率大于6.6Gb/s时,必须使用QPLL,否则可以选择使用QPLL或者CPLL);
3.生成IP时,一般将QPLL的代码放到IP外部,那么用户就可以在调用多通道高速收发器时,直接把剩余的IP多次例化,共用一个QPLL;
4.注意7系列FPGA的每个差分时钟最多只能驱动12个高速收发器,且只能驱动bank内部高速收发器或者南北相邻bank内部的高速收发器;
5.GT时钟获取步骤:
1.通过原语IBUFD_GTE从引脚上取得参考时钟;
这里的参考时钟可以来源于不同引脚;
2.输入到QPLL,CPLL,或直接提供;
QPLL和CPLL也可以通过南北桥来取得其他QUAD的参考时钟;
3.取得的参考时钟去向:
1.TXOUTCLK,但其实TXOUTCLK也可以来源于很多其他渠道;
TXOUTCLK会提供给BUFG从而驱动其他单元;
2.供给给PMA;
6.老式晶振是硅晶振,而GT收发器需要低抖,10PPM的晶振,可能较为昂贵;
7.GT收发器不能使用其他BANK上的时钟,时钟路由会增加抖动和偏斜,不能满足GT收发器的需求;但是GT收发器的时钟可以通过BUFG用于其他模块;
性能:
GTX 收发器支持500 Mb/s 至12.5 Gb/s 的线路速率,GTH 收发器支持 13.1 Gb/s 的线路速率。GTX/GTH 收发器具有高度可配置性,并与 FPGA 的可编程逻辑资源紧密集成。
与 Virtex-6 FPGA 中的上一代收发器相比,7 系列 FPGA 中的 GTX/GTH 收发器具有以下新功能或增强功能:
• 2 字节和 4 字节内部数据通路可支持不同的线路速率要求。
• 具有最佳抖动性能的 QuadLC 振荡器 PLL (QPLL) 和基于通道的环形振荡器PLL。
• 高能效、自适应线性均衡器模式,称为低功耗模式(LPM, low-power mode),以及高性能、自适应决策反馈均衡(DFE, decision feedback equalization)模式,用于补偿通道中的高频损耗,同时提供最大的灵活性。
• RX 余量分析功能可提供非破坏性的二维后均衡眼图扫描。 建议初次使用的用户阅读 High-Speed Serial I/O Made Simple [Ref 1],其中讨论了高速串行收发器技术及其应用。
CORE GeneratorTM工具包含一个向导,用于自动配置 GTX/GTH 收发器,以支持不同协议的配置或执行自定义配置。GTX/GTH 收发器的数据速率范围和功能允许物理层支持各种协议。
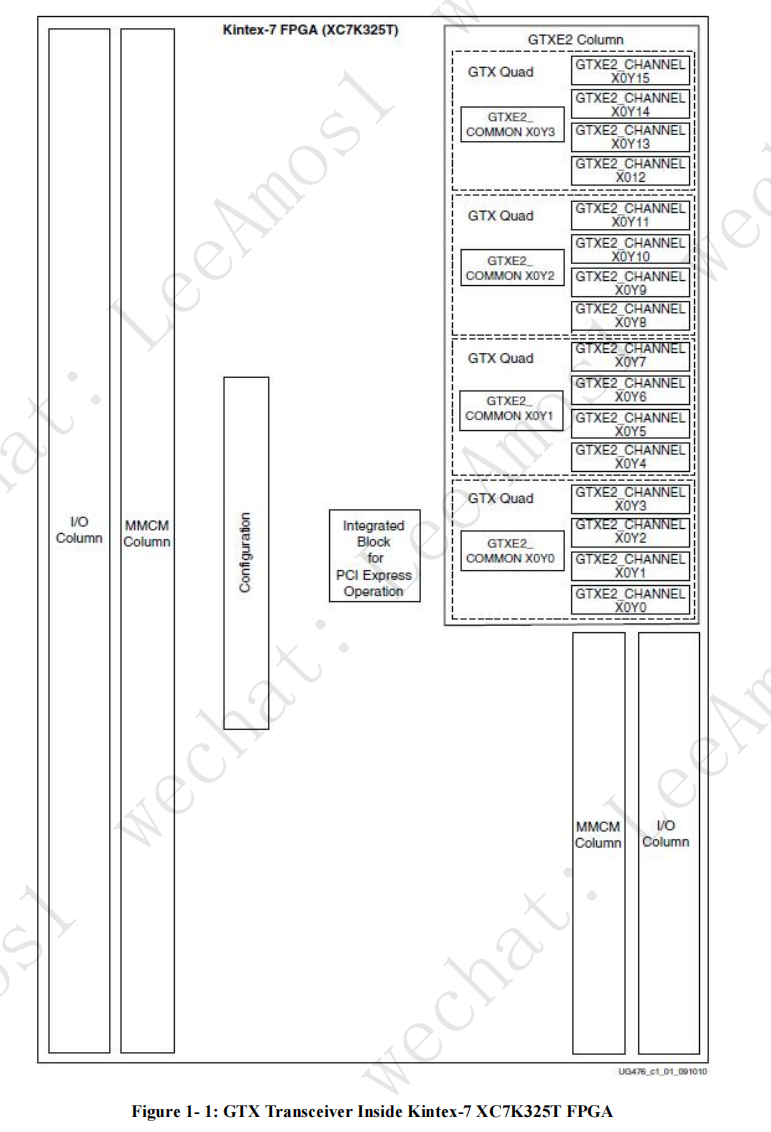
图 1-1(第 24 页)显示了 Kintex TM-7 器件 (XC7K325T) 中 GTX 收发器的布局示例。该设备有 16 个 GTX 收发器。
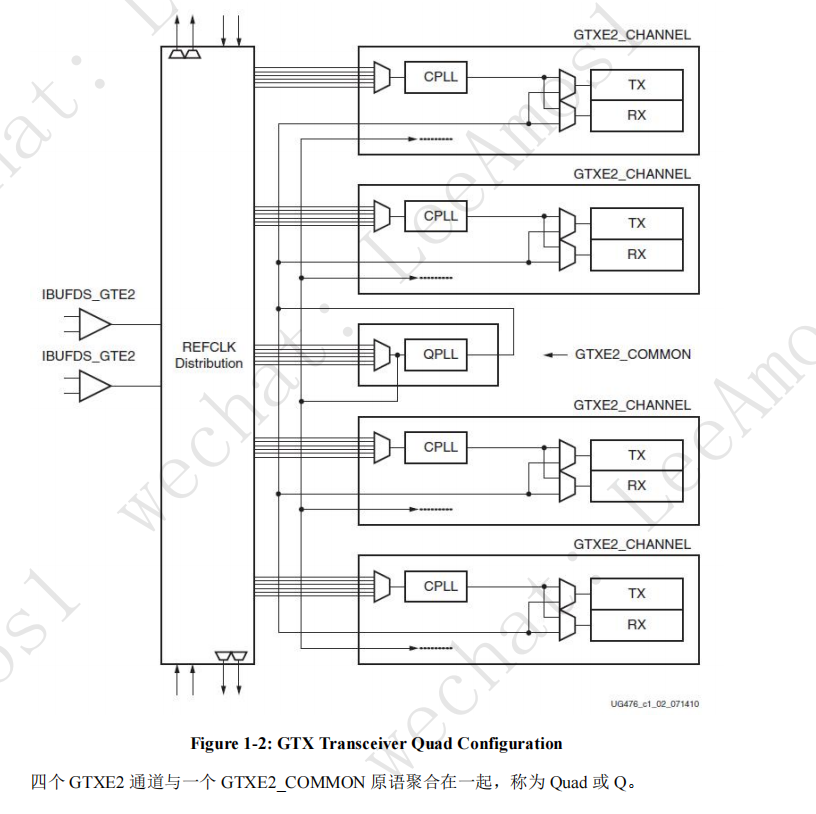
四个 GTXE2_CHANNEL 原语和一个 GTXE2_COMMON 原语组成的 Quad。
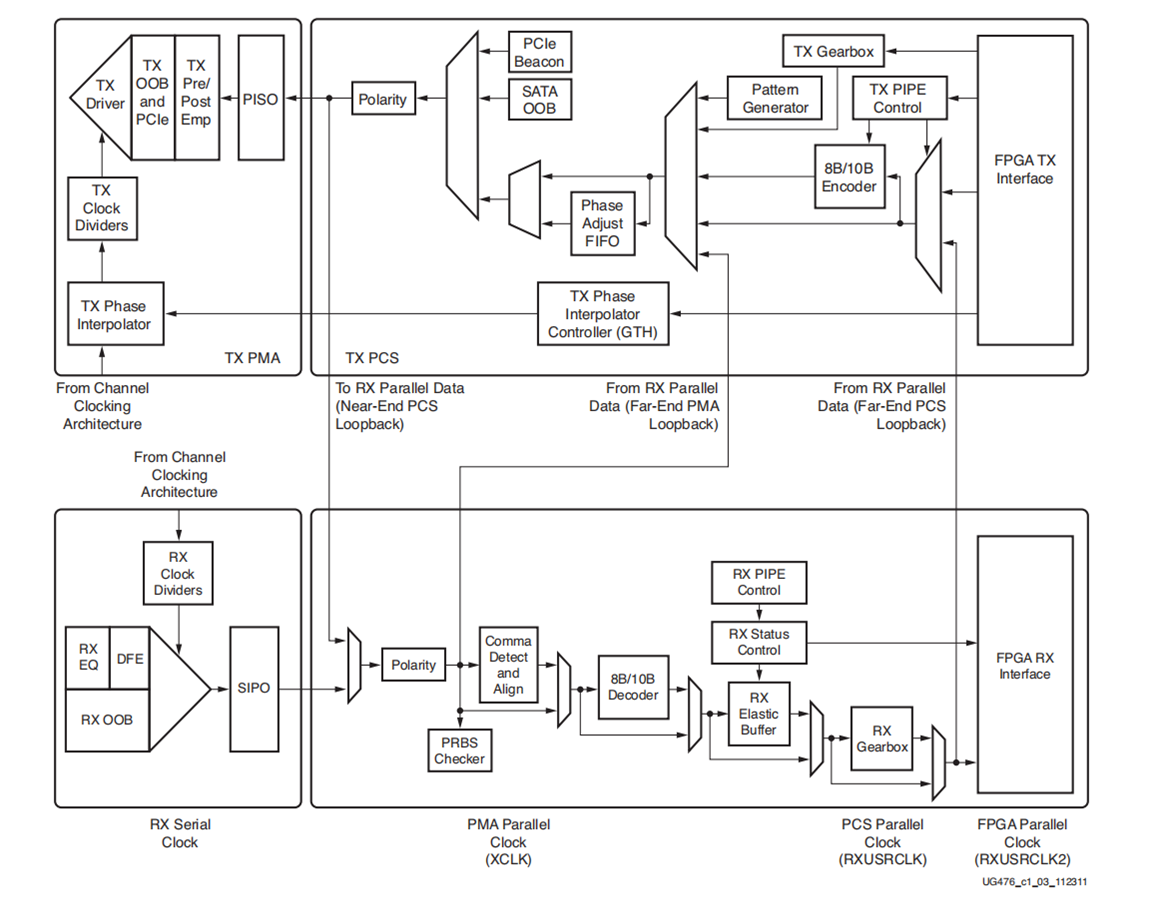
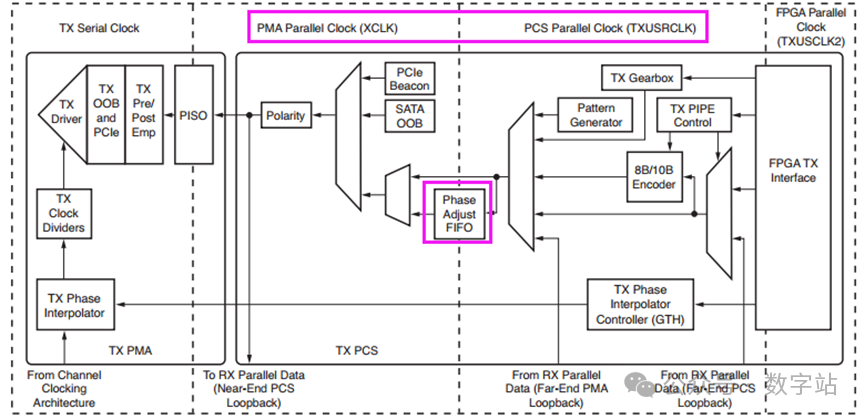
拓扑结构,PCS和PMA
一点知识
搬运自:https://mp.weixin.qq.com/s/0YoA9jhBOheZFwtTDJ75aQ
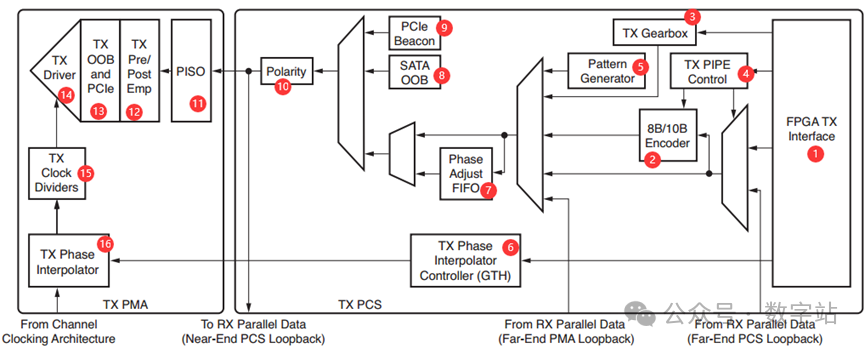
TX
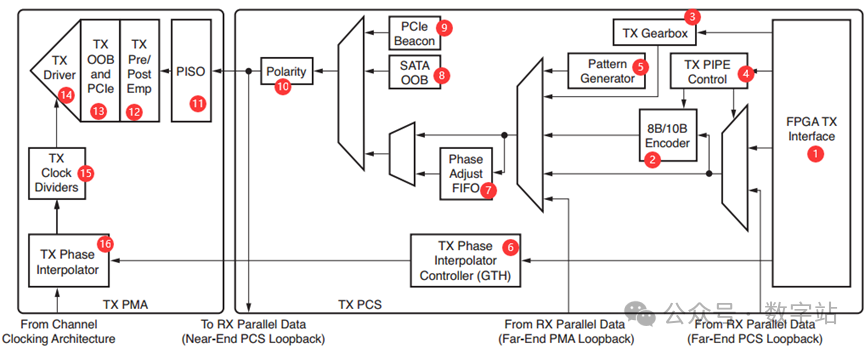
FPGA TX Interface
GTX发送通道的用户接口,用户数据通过该接口的信号输入。用户输入的数据TXDATA与用户发送时钟TXUSRCLK2上升沿对齐,数据位宽可以设置为2、4、8字节,常用数据位宽4字节,即32位。
8B/10B Encoder
对待发送的数据进行8B/10B编码。
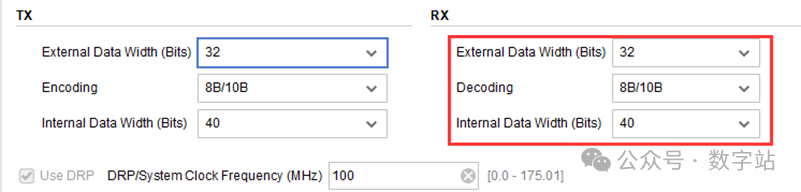
在配置IP时,可以选择发送/接收数据的编码/解码方式,如果把用户数据位宽设为32位,采用8B/10B编码,则编码后的数据位宽为40位,如下图所示。
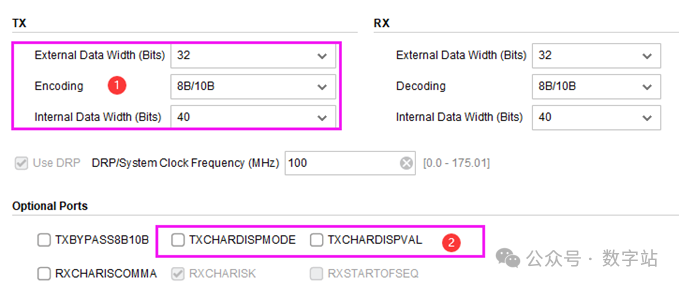
这个数据的位宽大小其实与线速率和编码方式均有关,
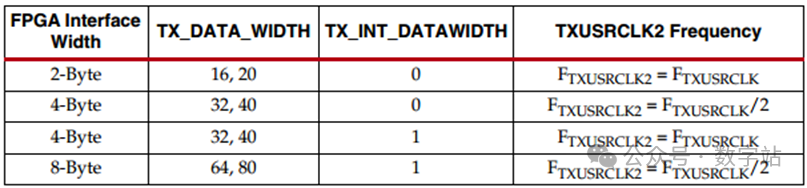
如下表所示,当使能8B/10B编码时,发送数据位宽TX_DATA_WIDTH只能设置为20、40、80。
注意表中TX_DATA_WIDTH表示一个用户数据经过8B10B编码后的数据位宽,而FPGA Interface Width表示用户接口每次传输的数据位宽,该数据与后文的TXUSRCLK2对齐。
Internal Data Width表示PCS内部并行数据一个时钟传输的数据位宽,该数据与后文的TXUSRCLK对齐。
当TX_DATA_WIDTH与Internal Data Width相等时,表示PCS内部传输一个数据只需要一个时钟,
此时TXUSRCLK的频率与TXUSRCLK2频率会相等。
如果TX_DATA_WIDTH是Internal Data Width的二倍,则PCS内部需要两个时钟才能传输一个经过8B10B编码后的用户数据,
那么TXUSRCLK的频率是TXUSRCLK2频率的2倍。
可以在后文图12的时钟关系中进行验证。
PCS内部每次可以传输2字节或者4字节数据,通过TX_IN_DATAWIDTH参数进行设置,TX_IN_DATAWI DTH为0时每次传输2字节数据,为1时每次传输4字节数据,
当线速率大于6.6Gb/S时,每次必须传输4字节数据。
因此由下表可知,当线速率为10Gb/S,使能8B/10B时,用户数据位宽只能为32或者64位,并且编码后的数据位宽均为40位。
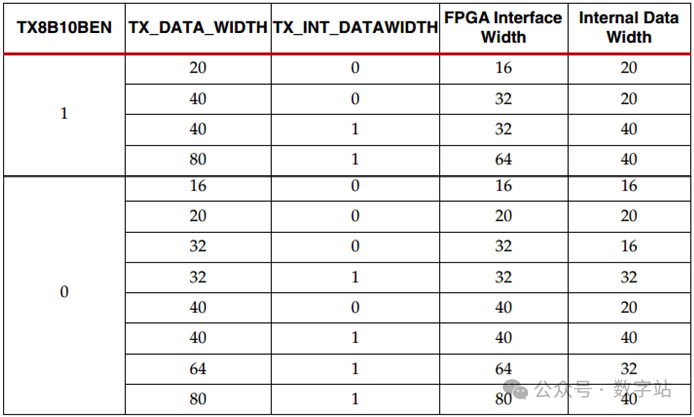
图5
当不使能8B/10B编码且线速率小于6.6Gb/S时,用户输入的数据位宽可以是16、20、32、40、64、80。
此时如果TXDATA为16/32/64,TX_DATA_WIDTH为20/40/80,
TXCHARDISPMODE和TXCHARDISPVAL端口用于将TXDATA端口从16位扩展到20位、32位扩展到40位或64位扩展到80位,
如下图所示。通过下图可知GTX先发送低字节数据,后发送高字节数据。
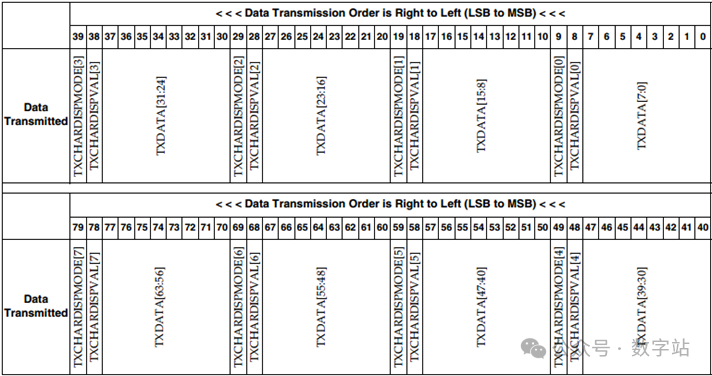
在多数情况下都是要使用8B/10B编码或者64B/66B编码的,此时TXCHARDISPMODE和TXCHARDISPVAL可以用来控制极性,与TMDS编码类似,直流均衡,硬核模块可以自己实现,用户也可以通过这两个信号自己实现。
采用8B/10B编码,每传输10bit数据,需要传输2bit无效数据。数据传输效率只有百分之八十,为了提高数据传输速率,同时保留编码方案的优势,可以使用64B/66B编码。
TX Gearbox变速箱
支持使用64B/66B编码,由图3可知,8B/10B Encoder和TX Gearbox的输入、输出都是连接的同一个端口。
因此在实际使用时,
如果不使用编码,数据直接到达数据选择器输入端,然后输出。如果使用8B/10B编码,则会经过8B/10B Encoder到达数据选择器输入端。如果使用64B/66B则经TX Gearbox到达数据选择器输入端口。在使用64B66B编码时详细讲解该部分内容。
用户的并行数据实际是64bit, PCS中会插入两bit数据让他变成66bit.(做64b/66b编码),【补充:也可能是128/130,8/10,可以参考PCIE那边的笔记】
但是PCS parallel clock 和PMA parallel clock之间的交互,它并不会一次将66位取走,比如他一次取走32位,两次才会取走64位。多余的两位就取不走了,怎么办?
每一次多两位,等到16个周期之后,就满32位了,此时TX Sync Gearbox缓存了32位了,就会告诉用户端,让他停一拍,此时TX Sync Gearbox就把积累的32位传递给PMA parallel clock这边了。
TX PIPE Control
全称为Physical Interface for PCI Express,PCIe物理层接口。如果使能PCIE接口,则该通道是PCIE的数据通道,否则将不会被使用。
Pattern Generator
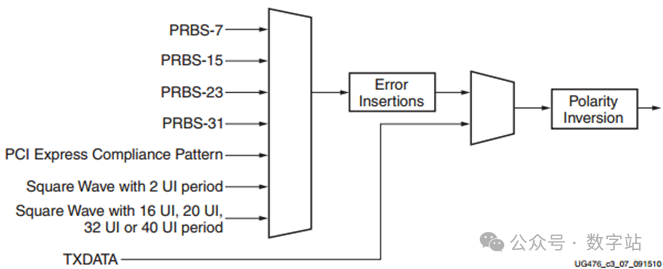
伪随机序列(Pseudo-random bit sequences,PRBS),频谱接近白噪声,一般用于高速串行通信通道传输的误码率测试。相关的设置端口如下所示,原理与M序列类似。
用于不同应用场景的测试选择

手册中显示提供了四种PRBS波形,分别是PRBS-7、PRBS-15、PRBS-23、PRBS-31,其中PRBS-7的表达式为x^7+x^6+1,输出数据每2^7-1个时钟循环一次,实现方式也很简单,几个移位寄存器加异或门就行了。
TX Phase Interpolator Controller
TX相位插值器控制器模块,允许使用PCS中的TX相位插值器PPM(百万分之一)控制器模块来控制TX PMA中的TX PI,以优化高速数据传输过程中的信号质量,保持传输的稳定性和可靠性。
Phase Adjust FIFO
相位调整FIFO缓冲器
如下图是时钟域的划分,在发送端的PCS子层里面有两个并行时钟域,分别是PMA相连的并行时钟(XCLK)和TXUSRCLK时钟。
要传输数据,XCLK速率必须与TXUSRCLK速率匹配,并且必须解决两个域之间的所有相位差。
GTX的发送数据通道包括一个FIFO缓冲器和一个TX相位对准电路,用于解决XCLK和TXUSRCLK域之间的相位差。

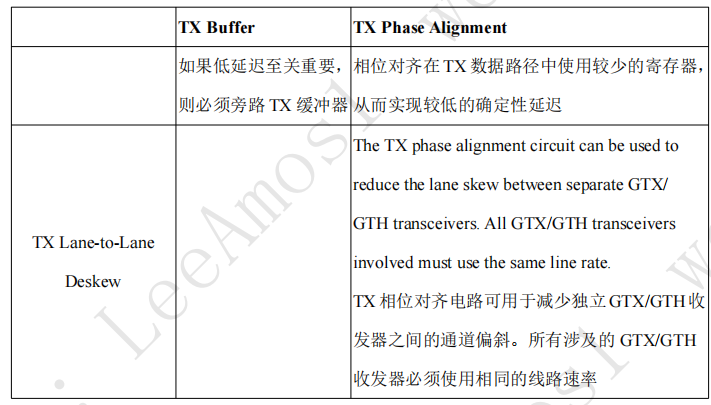
FIFO缓冲器优势就是设计比较简单,用户可以不用去管内部实现,只需要在调用IP时勾选下图中1处选项即可,缺点是FIFO的延迟比较大,导致用户把数据输入GTX到GTX输出数据的时间比较长.如果不考虑这部分延迟,推荐直接使用FIFO即可。
(这个延迟意味着两个FPGA收发器连接的时候可能会有上百个时钟周期的延时,这份延迟来源于GT触发器内部的缓冲FIFO,在某些工控的网络通信和路由器,网关的应用场景下有致命的延迟)
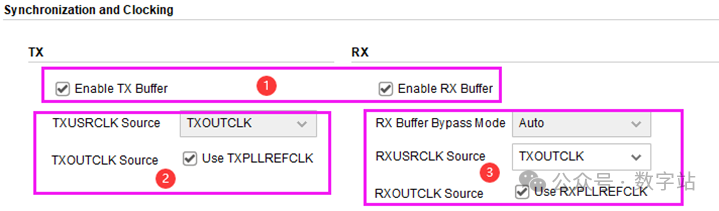
图10
如果对延时比较敏感,则可以使用相位对齐电路(Adjust FIFO),
只不过需要用户自己编写这部分控制代码,如果代码出现错误,将无法正常接收和发送数据。
在上图中还可以设置用户发送端口TXUSRCLK和用户接收端口RXUSRCLK的时钟来源,
首先应该了解下TXUSRCLK和TXUSRCLK2。
TXUSRCLK是GTX发送通道中PCS逻辑的内部时钟,TXUSRCLK的速率取决于GTXE2_CHANNEL原语的内部数据路径宽度和GTX发送通道的线路速率,计算公式如下所示。
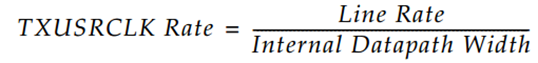
TXUSRCLK2是GTX发送通道所有信号的主同步时钟。
TXUSRCLK2和TXUSRCLK的频率关系与TX_DATA_ WIDTH、TX_INT_DATAWIDTH有关,如下图所示。
TXUSRCLK和TXUSRCLK2必须正边沿对齐,并且源时钟必须相同,两者之间的偏斜尽可能小。
一般使用BUFG、BUFH、BUFR来驱动TXUSRCLK和TXUSR CLK2。
因此一般将GTX IP输出的TXOUTCLK时钟信号作为TXUSRCLK和RXUSRCLK源时钟信号,
用户其实只需要关注TXUSRCLK2和RXUSRCLK2即可,其余两个用于IP内部,与用户关系不大。
如果IP设置为图10所示,那么时钟关系如下所示,
GTX IP输出的TXOUTCLK通过一个MMCM生成RXUSR CLK、RXUSR CLK2、TXUSR CLK、TXUSR CLK2时钟信号,(TXOUTCLK的来源之一是由CPLL或QPLL输出的)
全部输入GTX IP内部,其中RXUSRCLK2和TXUSRCLK2分别输出作为用户接收、发送的时钟信号。
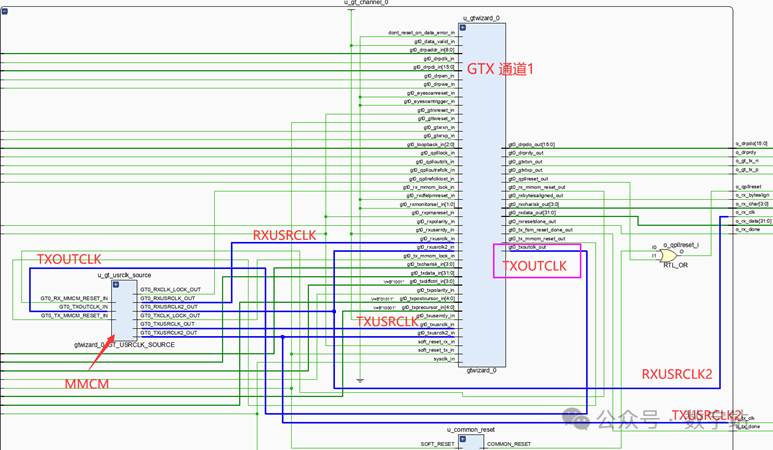
图13
图10的设置好处在于TXUSRCLK2和RXUSRCLK2信号是同一个信号,那么用户的发送端和接收端使用的是同一时钟信号,不需要跨时钟处理。
前文讲解了GTX的QPLL和CPLL等时钟信号,本文对外部时钟与发送、接收通道内部时钟的关联做简要介绍,下图是发送通道的时钟架构。
下图是发送通道内部的串行和并行时钟分频器,部分内容可以与前文的外部时钟相互对应
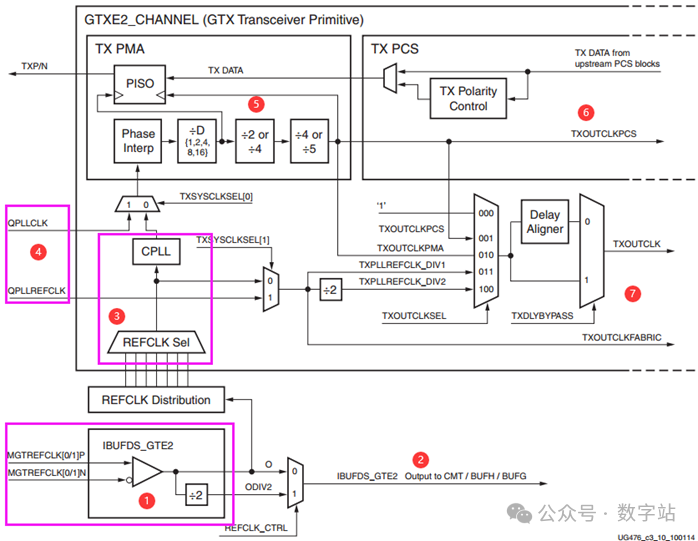
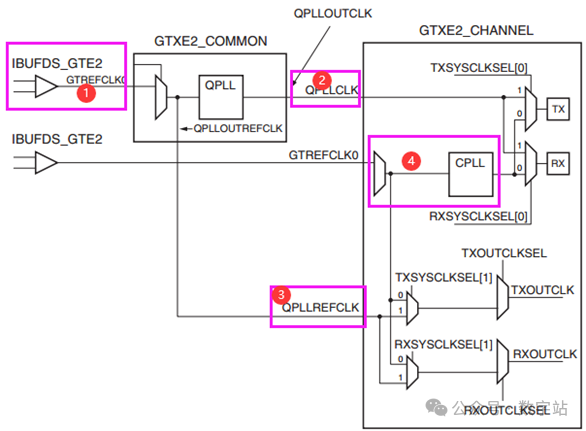
下图是前文讲解QPLL和CPLL出现的图,上下两图中1处其实都是同一个器件,
上图中IBUFGDS输出信号可以通过REFCLK_CTRL控制引脚输出到BUFG、BUFH、CMT,这是什么意思?
这就意味着GT bank的差分时钟转换为单端时钟后,可以作为其他bank的时钟信号,毕竟BUFG能够驱动FPGA内部所有时钟资源吧,不了解的可以查看前文对7系列FPGA时钟资源的讲解。
但REFCLK_CTRL这个信号由软件自动生成,用户无法控制。
上图中的3处其实与下图的4处是相同结构,均是数据选择器、CPLL,
上图4是QPLL的输出时钟和参考时钟,
其中QPLL的输出时钟QPLLCLK和CPLL的输出时钟通过TXSYSCLKSEL[0]的选择作为TX PMA的输入时钟。
该时钟输入TX PMA之后,
需要经过 Phase Interp”后被D分频,然后分为两路,
一路直接作为并串转换模块的串行时钟,
另一路继续经过两次分频作为并串转换模块并行时钟,并且输出到PCS侧作为其时钟,还输入到下半部分的数据选择器中。
这里并串转换为什么会配置一个D分频的分频器?
首先要明确这个时钟的频率能够影响什么?
作为并串转换的串行时钟,毫无疑问直接影响的就是转换后的数据的线速率,通过控制该分频器能够在一定范围内调节该通道的线速率。
这样就好回答具体原因了,每个GT bank有四个通道,但是却共用同一个QPLL,那如果四个通道的线速率均大于6.6Gb/S,但是线速率却不等,该如何实现?(大于这个速率的时候需要使用QPLL)
此时只能使用QPLL输出时钟,而QPLL输出时钟只有一个,此时就只能通过调节每个通道内部的D分频器,来实现不同通道不同线速率的目的。
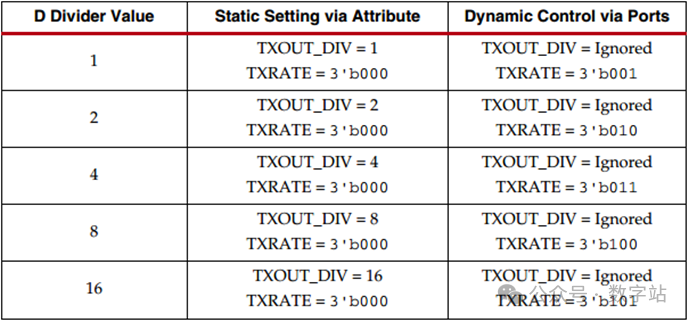
但是D分频器只能实现1、2、4、8分频,分频系数可以动态设置也可以静态设置。
当静态设置时,必须把分频系数TXOUT_DIV设置为固定值,并且将TXPATE设置为3’b000。
如果要实现动态线速率,需要在生成IP时勾选TXRATE信号,TXOUT_DIV和TXRATE必须在器件配置时选择相同的D分频器值,器件配置后,通过TXRATE动态更改D分频器值。
 ’
’
分频系数设置如下图所示,静态时通过TXOUT_DIV的值进行设置,动态时根据TXRATE的值进行设置,默认分频系数为1。
之后还要讲解下图14中后两个分频器的作用,这两个分频的输入作为并串转换模块的串行时钟,而输出作为并串转换模块的并行时钟,分频系数毫无疑问与并行数据位宽有关。
两个分频器能够组成的分频系数有8、10、16、20,由图5可知,PCS内部传输数据位宽只有16、20、32、40这几种,
即并串转换的并行数据位宽取值为16、20、32、40。可以推测串行数据是在串行时钟的双沿完成转换的,在8倍频率的时钟下将16位并行数据转换为串行数据输出,
其他分频系数转换道理类似。下图中的TXOUTCLKPCS和TXOUTCLKFABRIC用户不需要关注,没有输出到用户接口。
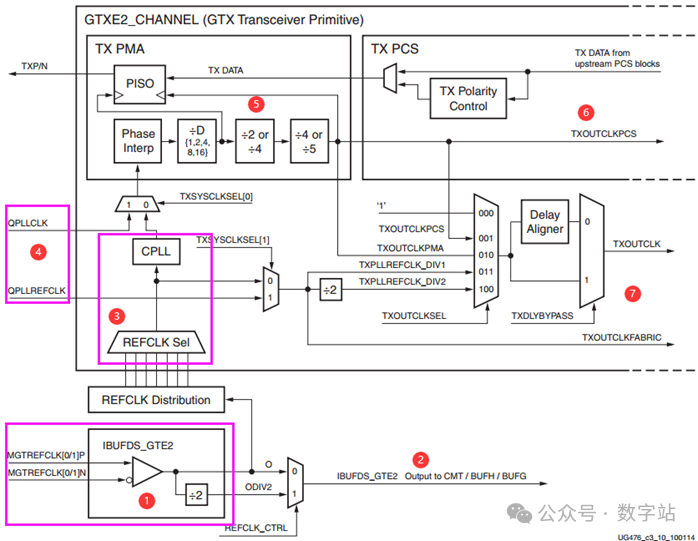
重点在于TXOUTCLK,
时钟来源可以是TXOUTCL KPCS、TXOUTCLKPMA、QPLL或者CPLL参考时钟或参考时钟二分频,
还可以选择是否对时钟来源进行延迟。
TXOUTCLK输出到BUFG,就处于“GTPE2_CHANNEL”外部了,根据用户的数据位宽,生成对应的参考时钟信号,下图是2字节或者4字节数据位宽时,可以使用的时钟结构。
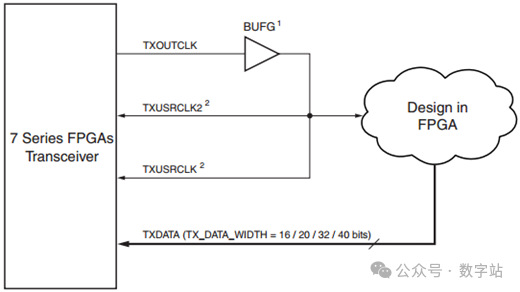
图19 单通道TXOUTCLK驱动txusrclk 2(2字节或4字节模式)
用的比较多的应该是下图所示的时钟结构,TXOUTCLK输出到BUFG,然后通过MMCM生成TXUSCLK和TXUSCLK2,其中TXUSCLK2作为用户接口的时钟信号。图13就是使用的该结构生成用户时钟信号。
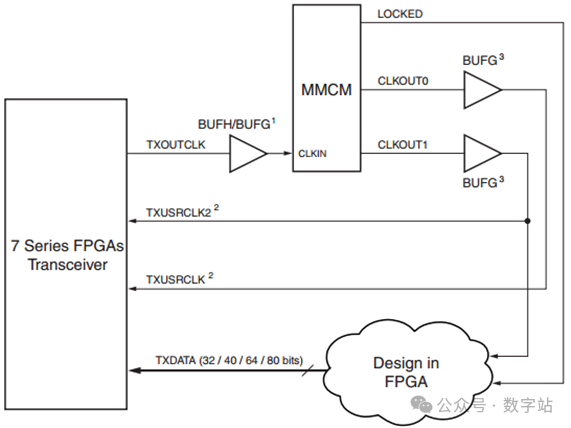
用的比较多的应该是下图所示的时钟结构,TXOUTCLK输出到BUFG,然后通过MMCM生成TXUSCLK和TXUSCLK2,其中TXUSCLK2作为用户接口的时钟信号。
图13就是使用的该结构生成用户时钟信号.
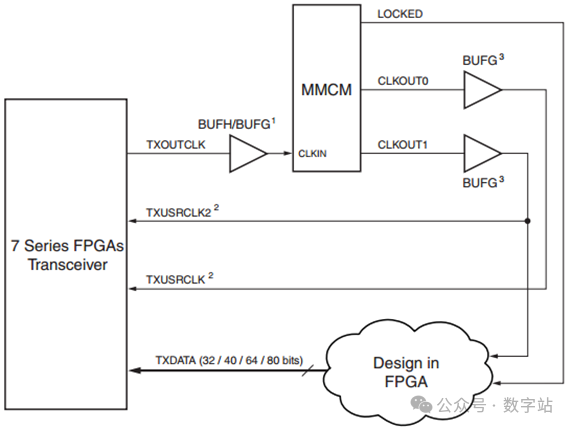
图20 单通道TXOUTCLK驱动txusrclk 2(4字节或8字节模式)
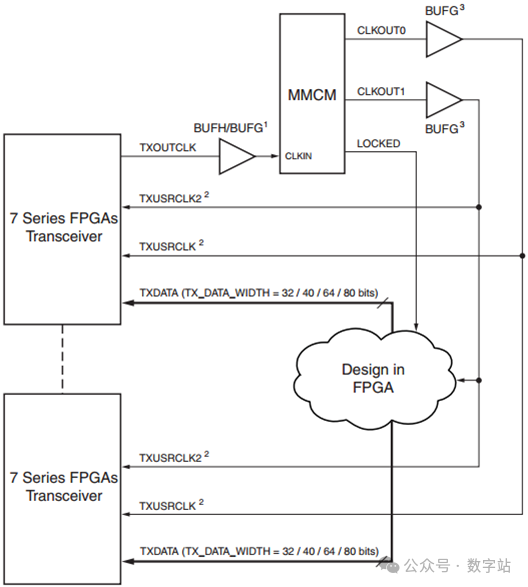
下图是单通道的TXOUTCLK通过MMCM生成TXUS RCLK和TXUSRCLK2驱动多个通道的时钟信号,这样做的好处应该是多个通道的数据都处于同一时钟域下,便于数据同步。
SATA OOB
SATA是硬盘接口,建立通信主要是通过检测OOB(Out Of Band)实现的,并且向上层传输连接情况,因此只有在使用SATA协议时,才会使用该模块,否则不用考虑。
PCIE Beacon
PICE唤醒功能,只有在使用PCIE协议时才会用到,否则不考虑。
Polarity
极性控制,这个作用比较大,主要时针对PCB设计时将差分对设计反了,模块内部可以将极性反转,从而解决PCB设计问题。
PISO串化模块
并串转换模块(parallel input Serial output),在前面讲解时钟分频时已经讲解过作用了,就是在时钟双沿将PCS发送的并行数据转换为串行数据。
TX Pre/Post Emp和TX Driver
GTX的TX驱动器是高速电流模式差分输出缓冲器,如下图所示。为了最大限度地提高信号完整性,具有差分电压控制、光标前和光标后传输预加重、校准终端电阻功能。
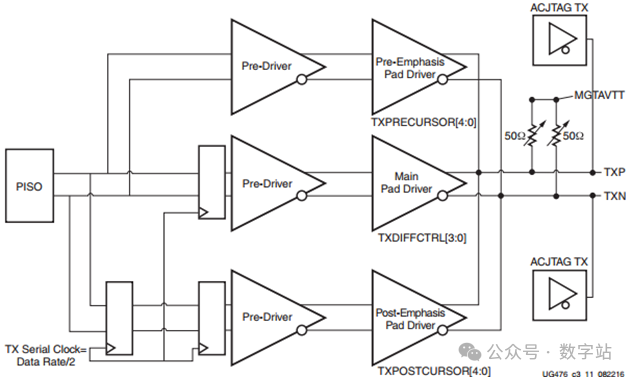
需要明白一个道理,高速信号在长距离、线速率较高的传输时,损耗是很严重的。经过损耗衰减之后,为了让接收端还能检测到数据,在发送端会做预加重和去加重处理,增大差分输出信号的摆幅等等,让其经过传输损耗之后差分信号的幅值变为零。用户只需要调节两个参数的值就可以调节预加重和去加重了,在配置IP时勾选下面两个选项即可。至于参数具体应该设置为多少,要根据实际的电路进行眼图扫描,然后确定最佳参数,关于眼图在接收通道的章节进行讲解。
TX OOB and PCIE
使用PCIE、SATA协议时才会使用的功能,否则不会用到。
TX Clock Dividers
时钟的分频模块。
PCS(Physical CodeSublayer)层
PMA(Physical Medium Attachment)层
PHY芯片
第一层:PCS,用以编码,处理跨时钟域问题,主要是数字信号的处理;
第二层:PMA,将PCS处理好的编码过的数字信号转换成模拟信号通过介质(光纤,铜缆)发送;
传统低速信号使用简单的高低电平,通过比较器和MOS管就能发送完成(LVCMOS3.3);
在高速信号的场景下,MOS管不太能满足需求,而是在PCS中使用高性能的高速DAC将数字信号通过同轴线或光纤发送;
PMA还会将编码好的数据进行串化。
RX
再次推荐:
https://mp.weixin.qq.com/s/KUPBQ_9t7fgm7LgoBNjojw
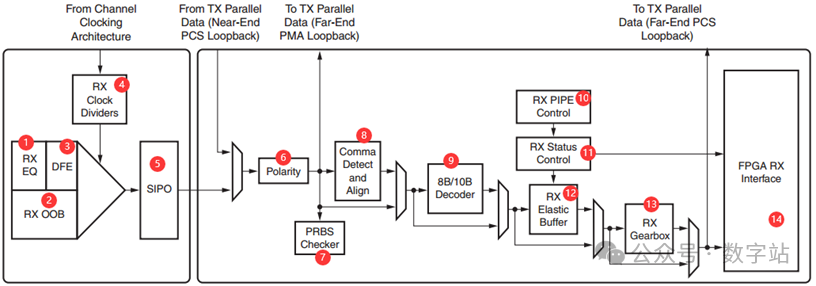
模拟前端与均衡器
从手册中可以获知,接收通道的开始部分有一个模拟前端,结构如下图所示,模拟前端一般就是对信号进行放大、滤波等等,消除信号传输过程中的一些干扰,并且然后端能够正常采集输入信号,该电路也是类似作用。
由于GTX的差分信号线速率很高,可以达到10.312Gb/S,并且传输距离可能会很长,导致接收数据的幅值可能很小,甚至达不到检测要求,
比如输入端发送时幅值有1.5V,经过几十米的光纤传输,到接收端时,幅值可能只有600mv了。
解决方式就是在发送时,通过预加重、后加重把幅值增大一点,
同时在接收时把门限降低一点,比如接收时检测幅值大于500mv就认为是高电平了,从而能够正确检测到衰减后的信号。
至于预加重、后加重、检测门限设置多少合适,这与实际的信号传输路径和线速率有关。
一般做法是当硬件条件确定后,通过眼图对所有参数进行扫描,确定一个最合适的参数,用作后续开发的值就行了。
眼图测试的目的:获得误码率最低,串扰最小的各种参数。
码间串扰
本来发送端传输的序列是二进制1011,由于信道传输过程中的干扰,最终效果如下。从第二个数据(码元)开始,每个码元都会受到前后码元的影响,导致抽样点不仅有本码元的值,还有前后码元值的干扰。

眼图:
最初为了解决眼图效果不佳的问题,在设计中加入了均衡器;
眼图张得越大意味着跳变的时间越短;
而眼图变窄意味着电路采样更难采到数据的中心位置(难以维持中心对齐),可能出现亚稳态的情况;
所以眼图的宽度可以反应采样的精准度;
眼高则由电压的高度差造成,眼高低意味着电平差减小,也就是幅值信号的衰减问题;
这涉及到接收器的检测门限问题,如果电平太小可能会造成比较器对高低电平的误判(由于衰减造成的电压减少出现的检测错误);
在发送端可能眼图很大的电路经过信道衰减可能会变得很窄,
通过特殊的滤波器~均衡器可以保障信号的可靠传输;

RX OOB
GTX接收器支持解码串行ATA(SATA)和串行连接SCSI(SAS)规范中描述的带外(OOB)序列,并支持PCI Express规范中描述的信标。
这个与SATA、PCIE这些协议有关,如果不使用这些协议,可以忽略,具体使用时在查阅手册即可。
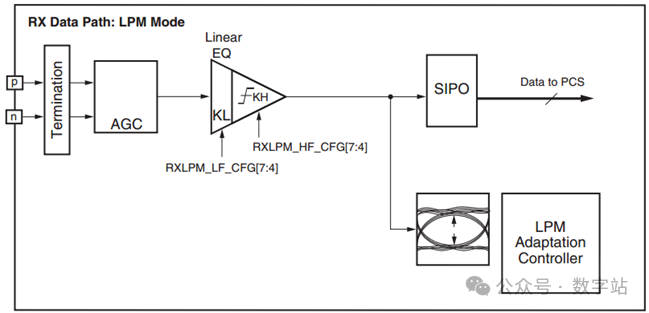
均衡器~LPM和DFE
根据功率和性能之间的系统级权衡,GTX接收通道有两种类型的自适应滤波器可以使用,分别是LPM和DFE。
如果传输过程中损耗比较小,可以使用低功耗模式(LPM)的节能自适应滤波器,(传输距离短)
对应结构如下图所示。
如果传输过程中损耗比较大,传输距离远,(通过比较长的背板光纤去传输)
此时应该使用DFE自适应滤波器,对应结构如下图所示。
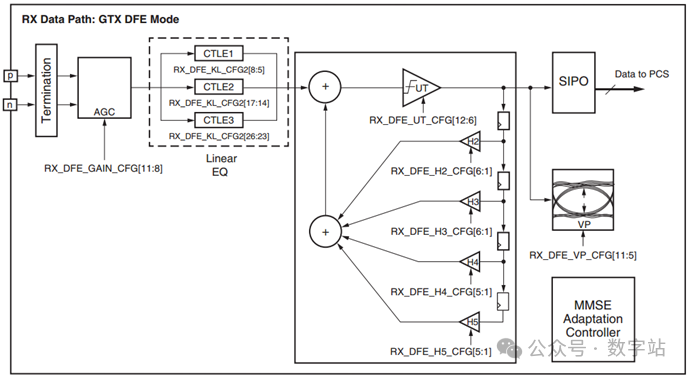
DFE通过提供更接近的滤波器参数调整来更好地补偿传输信道损耗,DFE模式是一种离散时间自适应高通滤波器,抽头值是由自适应算法设置的该滤波器的系数。
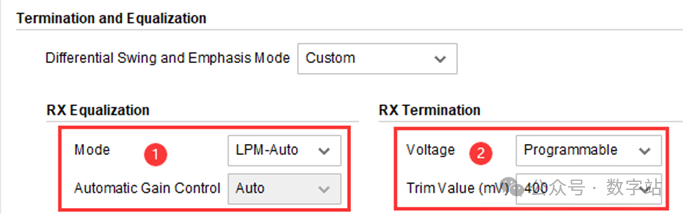
在调用IP时,如下图所示,在1处可以设置滤波器类型,短距离、低损耗首选LPM模式,节省功耗。
在2处把接收数据的幅值检测设置为可编程,之后可以通过IP端口信号gt0_txdiffctrl_in的值调节输入检测幅值。
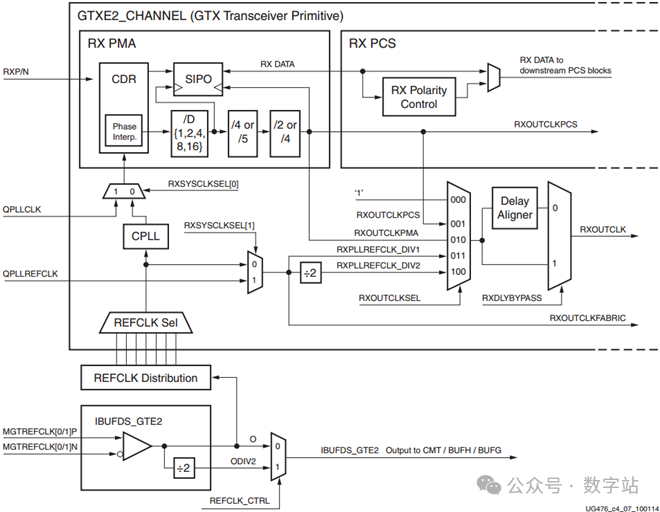
RX Clock Divider
这部分与发送通道的时钟部分一致,直接去查看发送通道的原理即可。对应框图如下所示,与发送通道一摸一样,不再赘述。
CDR
注意接收端只有一对差分数据线,并没有时钟线,接收端如何采集数据线的数据呢?接收端可以得知数据传输的频率,从而确定时钟频率,但是如何得知时钟的相位呢,
发送的时候在时钟双沿完成的并串转换。由上图知,串并转换也应该是在时钟双沿进行的,此时就需要保证时钟与数据的相位关系。
因此上图中QPLL或CPLL输出时钟进入PMA之后,需要先经过CDR调整时钟相位,然后再经过分频作为串并转换模块的串行时钟和并行时钟,
保证时钟与数据的相位关系正确。时钟数据恢复(CDR)技术是从接收的串行数据中提取恢复的时钟和数据的相位关系,CDR的结构框图如下所示。
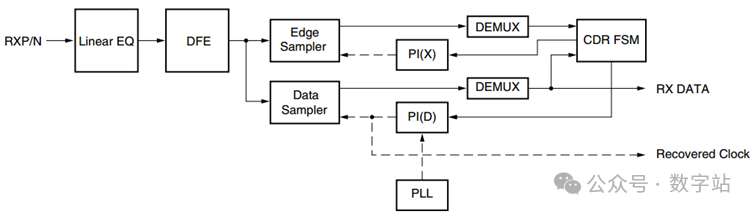
1.通过均衡器处理输入数据;
2.通过边沿采样器对数据进行采样;
3.通过PI器做类似PID的PI调整;
4.产生恢复时钟,并且将恢复时钟的相位跳变沿调整到数据的中心部分以保障相对数据的中心对齐;
CDR原理手册中是这么说的:CDR状态机使用来自边沿和数据采样器的数据确定输入数据流的相位并控制相位插值器(PI)。
边缘采样器的相位被锁定到数据流的过渡区域,而数据采样器的相位位于数据眼的中间。
具体实现方式可能就是CDR FSM能够精确控制相位,根据两个输入去调整相位偏移量,猜测是这样。
SIPO
串并转换模块,将接收的串行数据转换为并行数据,然后输出到PCS侧进行解析。
Polarity
如果PCB的RXP和RXN差分走线被意外交换,GTX接收的差分数据就会反转。
GTX接收通道可以在串并转换之后对PCS中的并行字节进行反转,以抵消差分对上的反转极性。
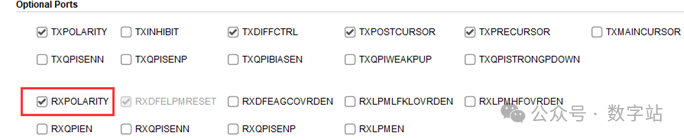
在配置IP时勾选RXPOLARITY选项,可启用接收极性控制引脚,当gt0_rxpolarity_in信号为高电平时,接收数据极性翻转。
PRBS Checker
GTX收发器接收器包括一个内置的PRBS检查器,如下图所示,能够检测四种函数对应的PRBS序列,与前文发送端生成的四种PRBS序列保持一致。
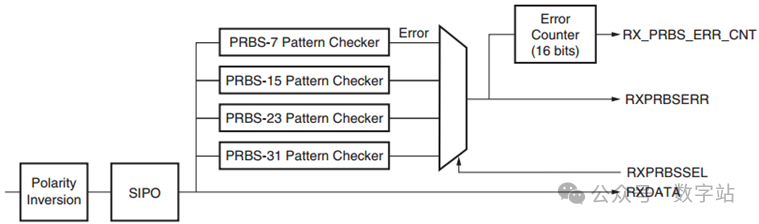
要使用内置PRBS检查器,检测序列类似必须为与发送通道发送的PRBS序列匹配。
如果输入数据被发送器反转或RXP/RXN反转,则接收数据也应通过控制RXPOLARITY反转,否则,PRBS检查器不会锁定。
当PRBS检查器运行时,会在传入数据中查找选定的PRBS序列。当它找到该模式时,它可以通过将输入数据与预期数据进行比较来检测PRBS错误。
Comma Detect and Align (类似于MIPI的BYTE对齐)
字节对齐,低速串口UART这种通信会有一个起始位,来判断一次传输的开始,但是GTX这类高速串行接口在传输数据时,并没有起始位、停止位这类标志,
那接收端如何确定每个字节的开始位置呢?下图是发送端发送一段数据,接收机可能因为上电等各种原因,并不是从第一位数据开始接收的,可能是从红色框开始接收第一个并行数据,
也可能是从蓝色框位置接收第一个数据,也可能是紫红色框处开始接收,该如何确定哪个位置开始接收数据才能正确解析出并行数据?
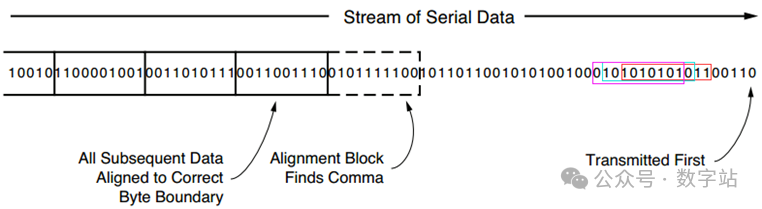
这里的功能与ISERDESE的功能其实一致,需要在合适的位置接收数据,对齐方式就是通过检测规定的K码数据来调整串并转换的起始位置。
如上图所示,首先将蓝色框中的10位数据通过8B/10B解码,如果解码结果是设定的K码,
则从蓝色框开始,每10位数据转换为并行数据去解码输出。如果蓝色框中的解码结果不是K码,
则将起始位置后移一位,把紫红色框中10位数据拿去解码,之后再进行比对,循环往复,直到检测到K码为止。
为了使对齐成为可能,发射机发送一个可识别的序列,即Comma,通常称为逗号。
接收方在传入数据中搜索逗号,当发现逗号时,将该逗号移动到一个字节边界,
以便接收的并行字与发送的并行字匹配。
如下图中1所示,字节对齐常用K码为K28.5,2处可以设置在数据的什么位置进行字节对齐检测,一般可以设置为全程检测。
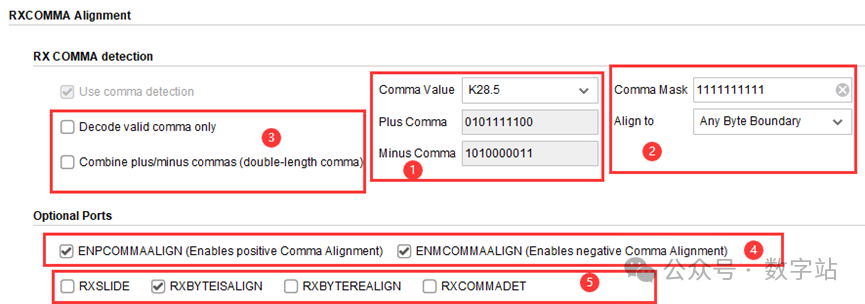
图13
2处还有个comma Mask信号,检测器支持检测部分K码的数值。
如下图所示,Mask高三位设置为0,则检测K码时,不需要检测高三位,只需要低5位满足要求即可,从而实现部分检测。但一般不会这么使用,了解即可。

图13的3处Decode valid comma only勾选后,检测器就只会检测默认的K28.5和K28.1的K码。
勾选Combine plus/minus commas使用双字节对齐检测,要求比较严格时才会使用。
查看图13中1处可知,当K码设为K28.5后,
由于8B/10B编码的极性问题,
下面会出现两种编码结果Plus Comma和Minus Comma,
两种编码的各位数据相反。检测器怎么知道检测哪种编码的K码呢?
通过使能图中4的ENPCOMMALIGN和ENMCOMMALIGN两个选项进行选择,
与其中一种模式对齐即可。
为实现字节,GTX有两种方式,一种是自动对齐,IP默认使用自动对齐。
另一种是手动对齐,勾选图13的RXSLIDE来启用手动对齐,该功能与ISERDESE一致,通过拉高一个信号来对串并转换的起始位置进行调整,
如果不是需要字符,则继续调整,会比较麻烦。
RXBYTE LS ALIGN信号为高电平时,表示已经完成字节对齐,输出给用户的数据正确。
RXBYTE RE ALIGN信号为高电平时,表示IP正在进行字节对齐。
RXCOMMAD ET为高电平表示检测到K码,该信号有效几个周期。
在线路速率大于5 Gb/s且系统噪声过大的应用中,字节对齐模块可能会错误地对齐错误的字节边界,并在没有有效数据时错误地拉高RXBYTEISALIGNED信号。
在此类应用中,应进行系统级检查,以检查RXBYTEISALIGNED是否符和数据的有效性。
8B/10B Decoder
8B/10B解码模块,将接收的10位并行数据解码位8位并行数据,具体的在8B/10B相关文章进行讲解,本文不过多叙述。
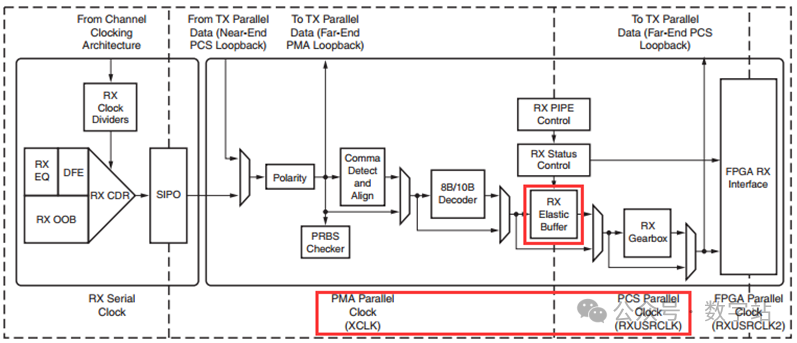
RX Elastic Buffer
弹性buffer主要用于解决PMA并行时钟域(XCLK)和PCS内部并行时钟域RXUSRCLK的跨时钟域问题。
XCLK是串并转换后,并行数据的时钟信号,由图7可知,QPLL或者CPLL的时钟经过CDR相位调整后作为串并转换模块的时钟。
而RXUSRCLK一般是由TXOUTCLK或者RXOUTCLK经过MMCM生成的,而TXOUTCLK或者RXOUTCLK的来源有几种,可能并不是CDR输出时钟,
因此XCLK和RXUSRCLK的相位不相同,即两者是异步时钟。
需要解决两个时钟域的相位差,最简单的方法就是使用buffer,如下图所示。
与发送通道一样,接收通道提供了两种解决方式,一种是通过buffer同步数据,优点是用户不需要进行控制,硬核内部即可完成同步,缺点在于延迟比较大,如果对延迟没有要求,首选buffer,IP设置如下所示。
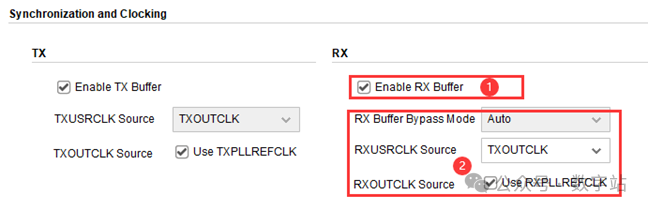
图16 使能接收通道buffer
注意如果发送通道和接收通道的协议和速率一致,可以使用TXOUTCLK生成RXUSRCLK,
原因在于同一个高速收发器的发送和接收通道共用同一个QPLL和CPLL,那么TXOUTCLK和RXOUTCLK其实可以是同一QPLL或者CPLL的参考时钟信号。
当然如果对延迟比较敏感,则可以将弹性buffer旁路,使用相位对准电路调整SIPO并行时钟域和XCLK之间的相位差,
实现从SIPO到PCS可靠数据传输。
还可以通过调整RXUSCLK来补偿温度、电压变化,从而执行RX延迟对齐。
接收相位和延迟组合对准可以由GTX收发器自动执行或由用户手动控制。
当RX恢复时钟用于提供RXUSRCLK和RXUSRCLK2时,可以旁路RX弹性buffer以减少延迟。
当RX弹性buffer被旁路时,通过RX数据路径的延迟很低且具有确定性,但时钟校正和通道绑定不可用。
RX PIPE Control与RX Geartox
这个与发送通道的 PIPE Control应该功能是一样的,与PCIE协议有关,不使用该协议时可以忽略。RX Geartox与TX Gearbox类似,只有在使用64B/66B或者64B/67B编码的时候,才会被使用,其余时间忽略。
RX Status Control及时钟校正
CDR所恢复出来的的时钟可能存在误差和偏斜;
RX Status Control对弹性buffer的一些状态进行检测,包括溢出等等,然后去做一个时钟纠正的处理。
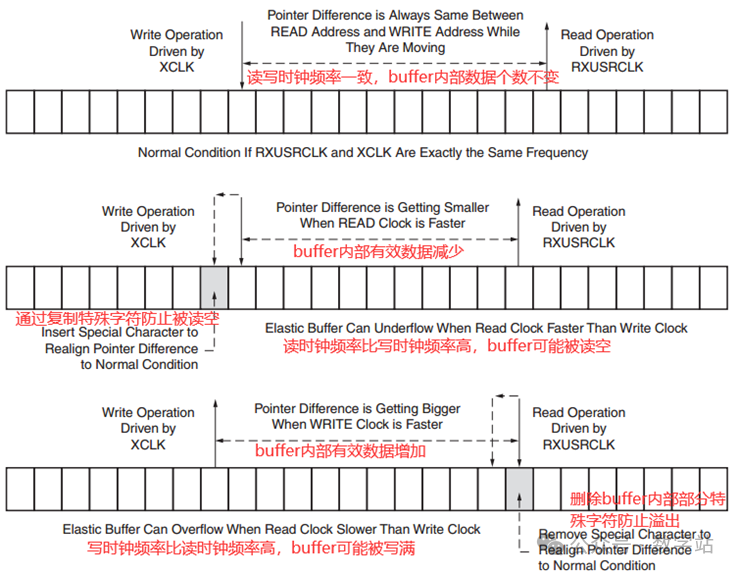
RX弹性buffer用于同步两个不同的时钟域RXUSRCLK和XCLK的数据,XCLK是从CDR恢复的时钟。
即使RXUSRCLK和XCLK以相同的时钟频率运行,频率差异也始终很小,日积月累,也会导致读写数据的速率不一致,可能造成数据溢出。
这是因为RXUSRCLK和XCLK差异决定的,并不能消除,因此提供了一种时钟纠正的方式来防止数据出现错误。
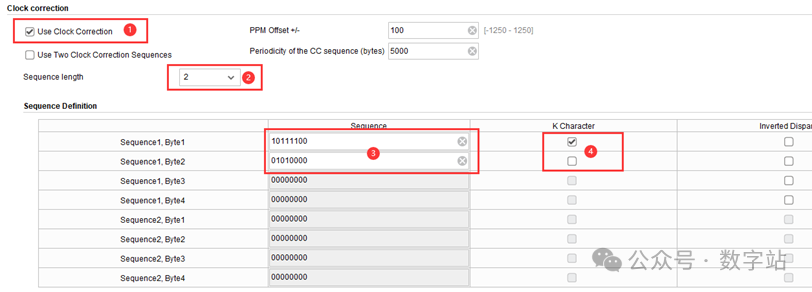
为了允许校正,发送数据时需要在有效数据中周期性的插入一个或多个特殊字符,GTX接收通道可以根据需要在弹性buffer中删除或者复制这些字符。
当弹性buffer快要装满数据时,可以删除buffer中的一些特殊字符使得buffer不被溢出。当弹性buffer快要被读空时,可以复制一些特殊字符存入buffer,防止弹性buffer被读空,最终使得弹性buffer始终保持在半满的状态。
由于XCLK和RXSUCLK频率只有微小差异,所以可以通过上述方式进行纠正,防止buffer上溢或者下溢。
上述所说的特殊字符一般为K码,IP设置如下所示,勾选1处启用时钟校正功能,在2处选择每次插入特殊字符的个数,3处设置需要插入特殊字符的数值,4处确定插入的字符是不是K码。下图插入2个特殊字符,一个是K28.5对应的8’hBC,另一个是普通字符8’h50。
通道绑定
XAUI和PCI Express等协议结合了多个串行收发器连接,以创建一个更高吞吐量的通道。每个串行收发器连接称为一个通道,
除非每个串行连接的长度完全相同,否则通道之间的偏斜会导致数据同时传输,但到达时间不同。RX buffer可以用作可变延迟模块,
信道绑定消除了GTX收发器各个通道之间的偏斜。用于绑定信道的发送通道在发送数据都同时发送信道绑定字符(或字符序列)。
当接收到序列时,GTX接收通道可以确定每个通道之间的偏斜,并调整RX buffer的延迟,以便在RX fabric用户界面上呈现无偏斜的数据。
后续在使用PCIE这种多通道协议时,
在进行详细了解,本质上发送端向每个通道同时发送一组数据,接收端检测这组数据,确定每条线路延迟,进而调整弹性buffer输出数据的延迟,来达到多个通道输出给用户的数据对齐的目的。
用户接收端口
经过前文这么久的讲述,终于来到最后GTX接收数据的用户接口了,
毫无疑问该接口的主要作用就是将接收的数据输出给用户。
该接口的所有信号与RXUSRCLK2的上升沿对齐,读取数据RXDATA的位宽可以配置为2、4或8字节,实际位宽与RX_DATA_WIDTH和RX_INT_DATAWIDTH的取值有关,与发送通道的设置一样,如下图所示。
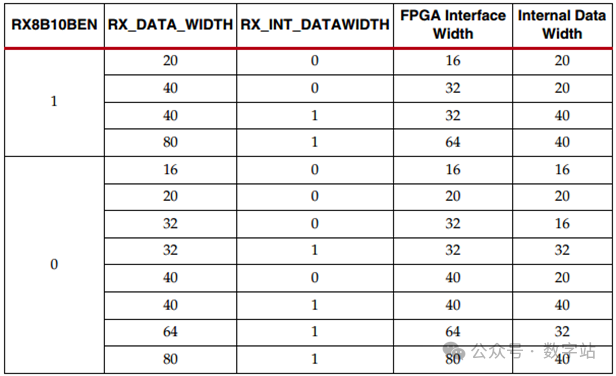
接口宽度配置7系列GTX收发器包含2字节和4字节内部数据路径,可通过设置RX_INT_DATAWIDTH属性进行配置。
FPGA接口宽度可通过设置RX_DATA_WIDTH属性进行配置。
当8B/10B解码器使能时,RX_DATA_WIDTH必须配置为20位、40位或80位,这种情况下,FPGA RX接口仅使用RXDATA端口。
当8B/10B解码器被旁路且RX_DATA_WIDTH为20、40或80时,RXDISPERR和RXCHARISK端口用于将RXDATA端口从16位扩展至20位、32位扩展至40位或64位至80位,如下图所示。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号