高速接口自用笔记:GT基础(一)
参考:
https://blog.csdn.net/Reborn_Lee/article/details/120681972
https://blog.csdn.net/m0_56222647/article/details/136730026
https://docs.amd.com/v/u/en-US/ug476_7Series_Transceivers
https://blog.csdn.net/qq_41186941/article/details/123452014
UG470, 7 Series FPGAs Configuration User Guide provides more information on the configuration.
UG471, 7 Series FPGAs SelectIO Resources User Guide provides more information on the I/Oblocks.
UG472, 7 Series FPGAs Clocking Resources User Guide provides more information on the mixedmode clock manager (MMCM) and clocking
名词和概念解释:
PHY和物理层:
千兆以太网中的osi模型:
PHY-MAC-事务层
PHY将4b编码成为5b数据,通过四对差分对通过一定的规则发送;
PHY芯片的任务就是编码和发送;
接收PHY通过CDR(数字时钟恢复),通过识别每一个跳变沿,使用锁相环调整相位,
最后根据PHY所传输的数据恢复出时钟,而且此时的时钟相位会处于最佳采样点(中心对齐);
CDR所恢复出中心对齐的时钟信号可以最大限度保障所采集数据的正确(因为中心对齐不存在SU和H的违例情况);
串化:Serdes(可参考:https://github.com/ljgibbslf/Chinese-Translation-of-PCI-Express-Technology-/blob/main/1%20%E8%83%8C%E6%99%AF.md)
通常情况下FPGA操作的信号都是并行的,通过Serdes可以接收或接收串行信号;
198X年,IBM发明了8/10编码;
8/10:K/D
8:3-5
3-4
5-6
{4,6}
这是用以消除连续高低电平的编码方式。
https://www.cnblogs.com/YINBin/p/11011232.html
https://www.cnblogs.com/xingce/p/16326139.html
串化的必要性:
克服问题. 通过上一章对 PCI 历史的回顾,我们知道,并行总线的性能被一些问题所限制,图2‑3 展示了其中的三个问题。
首先,回想一下,并行总线使用公共时钟;信号在一个时钟沿被输出,然后在下一个时钟沿被接收方接收。
这个模型的第一个问题来自于信号从发送端传输到接收端所花费的时间,称为渡越时间。
渡越时间必须小于一个时钟周期,否则将会出问题,这使得难以通过继续减小时钟周期来提升速度。
因为若需要继续减小时钟周期,为了让信号渡越时间依然小于时钟周期,需要更短的布线并减少负载的设备数量,但是最终这样的做法都会到达极限并且越来越不现实。
第二个造成并行模型性能受限的因素是使用公共时钟时,时钟到达发送方和接收方的时刻不一致,这称为时钟偏斜。
电路板设计人员尽力去减小时钟偏斜的值,因为时钟偏斜将会降低信号传输时序预算,但是这种偏斜永远无法彻底消除。
第三个因素是信号偏斜,它指的是多比特位宽数据的各个位到达接收端的时刻存在差异。
显然,这样的多位宽数据在所有的比特都到达且稳定之前都不能被接收方采样,这使得我们必须去等待最慢的那一比特。
一般来说这些GMII,LVDS ADC这样的并行接口只能跑125MHZ或250MHZ左右,跑上千MHZ就做不到了;

为什么要用Serdes?
单纯使用综合逻辑实现串化(并行数据串行发出),需要八倍甚至十倍于其的时钟,这就会造成对时钟的高要求;
而FPGA内部直接综合实现使用的是LUT和REG,这些通用资源难以满足大几百上千的速率需要,所以需要用到ASIC硬核生成的电路来处理;
Serdes都是设备内的固定硬核电路;
差分:GT口的差分电平标准是CML,是一种电流驱动型的电平标准。
每个通道都使用差分信号进行传输,差分信号是指每次传输一个信号时同时发送它的正信号和负信号(D+ 和 D-,这两种信号振幅相同相位相反),
如图2‑4 所示。当然,这样会将引脚增加一倍,但是相对于单端信号而言,差分信号在高速传输上的两个明显的优点足以抵消其引脚数方面的不足:它提高了噪声容限,并降低了信号电压。
差分信号的接收端将会接收这一对相位相反的信号,用正信号的电压减去其反相信号的电压,得到它们的差值,以此来判定这个比特的逻辑电平值。
差分传输设计内置了抗噪声干扰的设计,因为它要求成对的差分信号必须位于每个设备的相邻的引脚上,它们的走线也必须彼此非常靠近,以保持合适的传输线阻抗。
因此,任何因素在影响差分对中的一个信号的时候,都会同等程度且同样方向地影响到另一个信号。
但是接收端所在意的是它们的差值,而这些噪声干扰并不会改变这个差值,所以带来的结果就是大多数情况下噪声对信号的影响并不会引起接收端对比特值的错误判别。

7 系列 FPGA 的 GTX/GTH 收发器通道简称为 GTX/GTH 收发器。
• GTXE2_CHANNEL/GTHE2_CHANNEL 是实例化原语的名称,用于实例化一个GTX/GTH收发器通道。
• GTXE2_COMMON/GTHE2_COMMON 是实例化一个 Quad PLL (QPLL) 的原语名称。
• Quad 或 Q 是由四个 GTX/GTH 收发器通道、一个 GTXE2_COMMON/GTHE2_COMMON原语、两个差分参考时钟引脚对和模拟电源引脚组成的聚合或集合。
PCIE,SATA,SRIO,SFP都是GT口实现的协议;
8B/10B:K码与控制字符
https://www.uisrc.com/portal.php?mod=view&aid=297
https://www.quchao.me/4186/
8b/10b编码是将一个8b的数用10b来表示,其中高三位采用的3b/4b编码,低5位采用的5b/6b编码。8b/10b编码分为控制码编码和数据编码,控制码以kx.y表示,数据码以Dx.y表示,
其中x为8比特数低5位的十进制编码,y为8比特数高三位的十进制编码。例如:一个8比特的数据6Ah,二进制表示为0110 1010,高三位为011,十进制表示为3,低五位为01010,十进制表示为10,所以编码前可以用D10.3表示。
8b/10b编码具有如下的特点:
- 3b/4b编码后的结果不会超过3个0或者3个1
- 5b/6b编码后的结果不会超过4个0或者4个1
- 8b/10b编码后的结果0,1个数差别最多是2个,即10比特的数中只能出现4个0+6个1,5个0加5个1,6个0加4个1三种情况。
- 对数据而言,8b/10b编码后不会出现连续的5个0或者连续的5个1
8B/10B编码最初由IBM公司的Albert X.Widemer和Peter A.Franaszek发明,并应用于ESCON(200M互连系统)中。 它是mBnB编码中的一个特例。
8B/10B编码方法是把8bit代码组合编码成10bit代码,代码组合包含256个数据字符编码和12个控制字符编码,
分别记为Dx. y和Kx.y。 通过仔细选择编码方法可以获得不同的优化特性。 这些特性包括满足串行/解串行器功能必须的变换; 确保“0” 码元与“1” 码元个数的一致, 又称为直流均衡;
确保字节同步易于实现(在一个比特流中找到字节的起始位); 以及对误码率有足够的容忍能力和降低设计复杂度。
8B/10B编码方案是把8bit数据分成2个子分组: 3个最高有效位(y)和5个最低有效位( x)。
代码字按顺序排列,从最高有效位到最低有效位分别记为H、 G、 F和E、 D、 C、 B、 A。 3bit的子分组编码成4 bit,记为j、 h、 g、 f;
5 bit的子分组编码成6bit,记为i、 e、 d、 c、 b、a,其映射关系如下图所示,4bit和6bit的子分组再组合成10bit的编码值。

编码时,低5bit原数据 EDCBA经过5B/6B编码成为6bit码abcdei,高3bit原数据HGF经3B/4B成为4bit码fghj,
最后再将两部分组合起来形成一个10bit码abcdeifghj。10B码在发送时,按照先发送低位在发送高位的顺序发送。

将8bit数据分成3bit和5bit两组,分别对应10bit中的4bit和6bit,直流平衡代码的不平衡度就是通过“0” 的个数减去“1” 的个数来计算得到的。
如果4bit和6bit的各分组中“0”和“1” 的个数相等,称为完美平衡代码,或称为完美的直流平衡代码,无需补偿,但是这种情况是不可能的。
因为在4bit的子分组中,16种编码中只有6 种是完美平衡的,这对于3bit的8种编码值是不够的。 同时,在6bit的子分组中也只有20种编码是完美平衡的,对于5bit的32种编码值也是不够的。
由于4 bit和6bit的两个子分组都是偶数个位数,而不平衡度不可能是“+1” 或“-1”,因此,在8B/10B编码方案中还要使用不平衡度为“+2” 和“-2” 的值。
在编码过程中,用一个极性偏差( running disparity,RD)参数表示不平衡度,在不平衡时用2个10 bit字符表示一个8位字符,
其中一个称为RD- ,表示“1” 的个数比“0” 的个数多2个,
另一个称为RD+ ,表示“0” 的个数比“1” 的个数多2个。这种不平衡差值为2的数需要采用2个10bit 表示1个8bit,主要用于K码的控制字符。

8B/10B编码中将K28.1、K28.5和K28.7作为K码的控制字符,称为“comma”。
在任意数据组合中,comma只作为控制字符出现,而在数据负荷部分不会出现,因此可以用comma字符指示帧的开始和结束标志,或始终修正和数据流对齐的控制字符。
5B/6B编码和3B/4B编码的映射有标准化的表格,可以通过基于查找表的方式实现。
使用 “不一致性(Disparity)”来描述编码中"1"的位数和"0"的位数的差值,
它仅允许有"+2"( "0"比"1"多两个)、"0"( "0"与"1"个数相等)以及"-2"("1"比"0"多两个)这三种状况。
由于数据流不停地从发送端向接收端传输,
前面所有已发送数据的不一致性累积产生的状态被称为“运行不一致性(Runing Disparity,RD)”。
RD仅会出现+1与-1两种状态,分别代表位"1"比位"0"多或位"0"比位"1"多,其初始值是-1。Next RD值依赖于Current RD以及当前6B码或者4B码的Disparity。根据Current RD的值,
决定5B/4B和 3B/4B编码映射方式,如下图所示。



这样,经过8B/10B编码以后,连续的“1”和“0”基本上不会超过5bit,只有在使用comma时,才会出现连续的5个0或1。接收端的数据解码过程如下图所示:

GT是什么?
参考链接:https://zhuanlan.zhihu.com/p/46052855
随着信息技术的快速发展,板卡、芯片之间的数据传输速率越来越高。由于受到物理限制,采用并行的方式无法实现远距离高速数据传输,
因此串行传输目前已成为主流的高速数据传输的方式。要想实现高速数据流的串行传输,必不可少的一个核心器件是SerDes(SERializer/DESerializer,其核心功能是实现数据的串并\并串转换。
表1 RocketIO的种类和对应的速率
|
种类 |
MGT |
GTP |
GTX |
GTH |
GTZ |
GTY |
|---|---|---|---|---|---|---|
|
最高速率(Gbps/s) |
6.5 |
6.63.753.2 |
12.5 6.66.5 |
16.31613.1 11 |
28.05 |
32.75 30.5 |
Xilinx公司在Virtex-2 Pro及更高级的FPGA芯片内集成了SerDes硬核,Xilinx公司将其称为RocketIO模块。在FPGA设计中使用RocketIO模块可以实现片间的高速数据传输。同时也可以以RocketIO为基础,通过在其上层(数据链路层)增加协议,实现不同应用环境下的专用接口,如SGMII(SerialGigabit Media Independent Interface)接口、10G以太网接口、Aurora接口、RapidIO接口等。Xilinx FPGA芯片中集成的RocketIO模块的版本和对应的最大数据传输速率如表2.1所示,其中同一种RocketIO模块在不同的芯片中支持不同的最高速率。
它是集成在FPGA芯片内部的固定电路, 因此我们只需要关心该固定电路与FPGA的逻辑部分接口时序即可;
它是串行收发器, 发送出去只有1bit数据, 而接收端也是1bit线。 但FPGA与该器件的接口数据是多bit的, 因此该收发器同时也是一个高速并串转换器;
它是高速收发器, 一般线速率可达Gbps, GT分为不同系列, 在不同的系列中有不同的速度。
GT(包括GTX、 GTH和GTP)是Xilinx在高速SerDes的基础上, 增加了其他模块, 如LVDS、 PLL、 8b/10b编解码+绕解码等(具体可以看Xilinx相关文档, 如ug476)形成的一个高速串行收发器, GT是Gigabit Transceiver的意思, 它是实现当下一些高速串行接口的基础: 如PCIe、 RapidIO等
在XILINX 7Z035 FGG676中有两个这样的BANK,每个BANK提供四对高速收发器,所以总的来说是8对高速收发器;
但高速接口收发对并不是以对喂单位,而是QUAD,一个QUAD包括四对,而最多五个QUAD可以分享一堆高速接口的参考时钟(BUFDS GTE),这是由于时钟的驱动能力决定的;
我所使用的开发板:
光口两个各用一对;
PCIEX4用了四对;
SATA两个各用了一对;
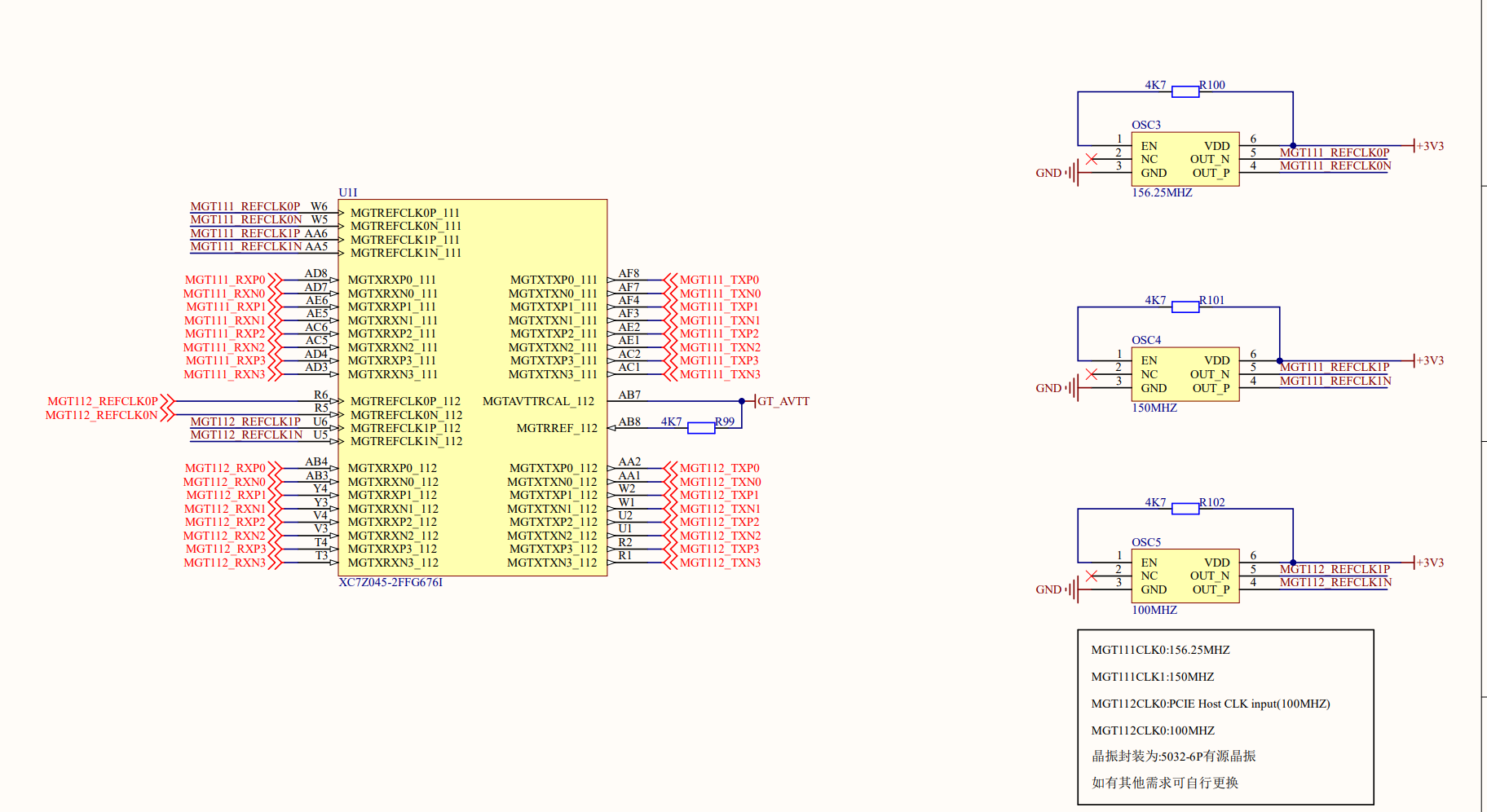
多个参考时钟可以让不同的GT对能使用不同的参考时钟;
Quad:四个 GTXE2_CHANNEL 原语和一个 GTXE2_COMMON 原语组成Quad。

通过IBUFDS_GTE2获得参考时钟,分配给各个差分对;
不同GT差分对可以选取不同的参考时钟,这里可以看到这个QUAD输入的参考时钟有两个,
可以使用同一对也可以使用不同的差分对;
例如,PCIE和光口就需要选取不同的参考时钟来提供时钟;
GTXE2_COMMON
GTXE2_COMMON是时钟共享资源,给一个QUAD内的GT引脚提供时钟;
GTXE2_COMMON的时钟来自原语GTE系列
GTXE2_COMMON 原语包含一个 LC 振荡器 PLL (QPLL)。 每个 GTXE2_CHANNEL 原语由一个通道 PLL、一个发送器和一个接收器组成。图 1-3 展示了 GTXE2_CHANNEL 原始设备的拓扑结构。
GTHE3/4的COMMON则包含两个QPLL,这是架构不同的差别;

拓扑结构


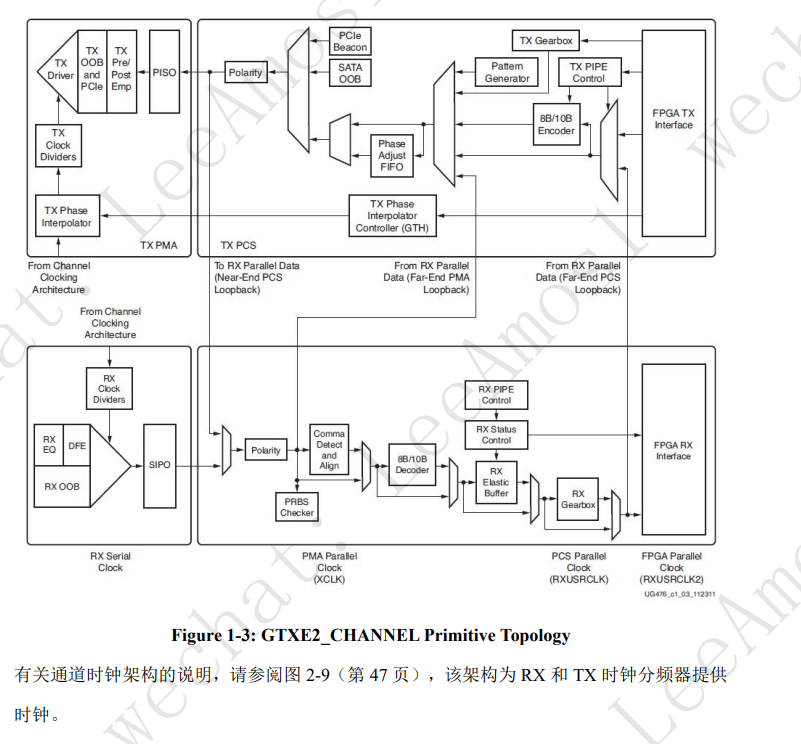
图2 RocketIO GTX/GTH结构图
图2所示为RocketIO GTX/GTH的结构图,从图中可以看出RocketIO分为发送和接收两大部分,
每一部分又分为PCS(Physical CodeSublayer)层和PMA(Physical Medium Attachment)层。
注意,此处的PCS层和PMA层是GTX/GTH接口的,要注意与前面介绍的10G以太网接口的PCS和PMA区分。
https://mp.weixin.qq.com/s?__biz=MzU1MzI4ODA5OA==&mid=2247485294&idx=1&sn=887f6b727da6f3649f3666b24053a8b1&chksm=fbf46fa3cc83e6b5ff6697e8fd8bd80da69edad887c529ec88d5a9e8302d0c0c74a25eb048c1&token=464518486&lang=zh_CN&scene=21#wechat_redirect
同时,如果GTX/GTH上面跑的是Aurora协议或者是SGMII或者是RapidIO,那么也同样有不同的PCS/PMA(虽然有不同,但其核心都是Rocket IO GTX/GTH的PCS和PMA) 。

搬运和补充:
PCS:物理编码层,TX-PCS中可以产生测试样例bist数据(pattern generator, pcie beacon, sata oob),可以发送出去,再接收端接受,从而测试物理连接是否正常。
PMS:物理媒介层
用户的并行数据实际是64bit, PCS中会插入两bit数据让他变成66bit.(做64b/66b编码),【补充:也可能是128/130,8/10,可以参考PCIE那边的笔记】
但是PCS parallel clock 和PMA parallel clock之间的交互,它并不会一次将66位取走,比如他一次取走32位,两次才会取走64位。多余的两位就取不走了,怎么办?
每一次多两位,等到16个周期之后,就满32位了,此时TX Sync Gearbox缓存了32位了,就会告诉用户端,让他停一拍,此时TX Sync Gearbox就把积累的32位传递给PMA parallel clock这边了。
Phase Adjust 相位补偿FIFO;
Polarity:奇偶校验,8B/10B
TX Pre/Post:预加重和后加重,用以保障信号完整性的物理层优化技术;
PMA都是串行数据。
TX Serial Clock 是串行时钟,是端口串行速率的一半,原因是上升沿和下降沿都发送数据。
例如5Gb的速度,Clock是2.5GHZ,归因于其的DDR工作模式;

Rx-PMA中有CDR(时钟恢复模块),依赖refclk,从数据中将时钟恢复出来。
Comma Detect & Align:类似于MIPI中通过移位寄存器检测同步码的方法,可参考我的MIPI模块解码方法;
Rx-PCS中有checke模块,检查TX发过来的bist数据是否正确(如果有),验证物理层是否工作正确。

IBUFDS_GTE2
引脚上的时钟信号需要接入专用的高速接口时钟原语;

HROW是全局时钟放在水平方向还是垂直方向的节点,ODIV2是输出给用户逻辑用的,可以分选二分频或者不分频或者直接拉低降低功耗。


IBUFDS_GTE2输出的信号可以用于:
参考时钟(这会给到其他的QUAD);
给COMMON(QPLL)提供时钟,而QPLL会由此提供时钟给CHANNEL的CPLL;
给CHANNEL(CPLL);
IBUFDS_GTE2 Primitive: Gigabit Transceiver Buffer Introduction IBUFDS_GTE2 is the gigabit transceiver input pad buffer component in 7 series devices.
The REFCLK signal should be routed to the dedicated reference clock input pins on the serial transceiver,
and you should instantiate the IBUFDS_GTE2 primitive in your design.
See the 7 Series FPGAs GTX/GTH Transceivers User Guide (UG476) for more information on PCB layout requirements, including reference clock requirements.
IBUFDS_GTE2_inst : IBUFDS_GTE2
generic map (
CLKCM_CFG => TRUE, -- Refer to Transceiver User Guide
CLKRCV_TRST => TRUE, -- Refer to Transceiver User Guide
CLKSWING_CFG => '11' -- Refer to Transceiver User Guide
)
port map (
O => O, -- 1-bit output: Refer to Transceiver User Guide:
ODIV2 => ODIV2, -- 1-bit output: Refer to Transceiver User Guide:可用于用户使用的同步时钟,但也未必需要使用,不用的话配置成10降低功耗即可;
CEB => CEB, -- 1-bit input: Refer to Transceiver User Guide
I => I, -- 1-bit input: Refer to Transceiver User Guide
IB => IB -- 1-bit input: Refer to Transceiver User Guide
);


COMMON:共享时钟资源,在要求性能的情况下是必须使用的,不用的时候使用的就是CHANNEL的CPLL;UG476 P33
参考时钟进入QPLL完成输出,提供给用户端口;
通过SEL来选择需要参考的时钟;
这里的QPLL0OUTCLK是提供给物理层GT口的;



CPLL相较于QPLL性能较低,输出频率的范围更宽,一般是建议使用QPLL;
IBERT 眼图测试原理
IBERT 是 Xilinx 提供的一个用于 GT 辅助调试的 IP,首先明确一下,这是 一个IP。
所以ibert有两种使用方法:
1.直接使用example design进行独立使用;
2.集成到某个工程中进行使用;ibert 最常用的两个用途是:
1.基于 PRBS 模块的 误码率检查;
2.基于眼图扫描模块的测量近端眼图;这里我们主要对基于眼图 扫描模块的测量近端眼图展开介绍。
IBERT IP 的测试原理是就是将同一组收发器的 TX 和 RX 进行短接,TX 发 送端通过发送某种特定序列的数据流;
在 RX 接收端接收后, 通过比对发送和 接收的数据, 从而得出误码率和眼图信息来验证开发板 GTP 部分工作的稳定性。
眼图测试即误码率测试,测试的原理框图如图 1-3所示,我们使用光纤将收发器 的 TX 和 RX 进行短接,
实现 lookback(环回模式)。环回模式是 FPGA 收发器数 据路径特殊配置模式,
它将数据流返回数据源端。该功能可以用来检查或测试 近端收发器或者远端收发器收发链路是否正常工作以及判断通信链路信号质量。
IP核配置:GTX和GTP并不相同;
GTP:


这里选择125MHZ是因为选择了PCIE的对应时钟;
但其实也可以选择PLL1的时钟,即使时钟来源于0脚;
这是因为GTP似乎有两个QPLL;
而GTX的这个选项是有所不同的;

第二页:
参考时钟需要选择对应频率的,此处的1代表125MHZ的时钟,0是光口的100MHZ;
GTX:

相较于GTP,这里只能选是否使用QPLL;
如果不使用,我觉得会接到CPLL上;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号