

PCI-Express-Technology(四)
PCIe支持三个地址空间,与PCI中的三个地址空间完全相同:
n 配置空间(Configuration)
n 内存地址空间(Memory)
n IO地址空间(IO)
如我们在Chapter 1中所讨论的,配置空间是由PCI引入的,软件通过配置空间就可以用一种标准化的方法来对设备的状态进行控制和检查。PCIe对PCI软件具有向后兼容性,所以PCIe中仍然支持配置空间,并且支持它的原因也和PCI一样,即用一种标准化的方法来对设备的状态进行控制和检查。更多关于配置空间的信息(目的、如何访问、大小、内容等等)请参阅Chapter 3。
尽管配置空间出现的意义是来放置和保持一些标准化的结构(PCI-defined Header、Capability Structure能力结构等等),但是PCIe设备也会经常的将一些设备特定(device-specific)的寄存器映射到设备自身的配置空间中。在这种情况下,映射到配置空间的设备特定寄存器常用来作为控制寄存器(control)、状态寄存器(status)或者指针寄存器(pointer),而不是用来存储数据。
在PC的早期阶段,IO设备的内部寄存器/存储是通过IO地址空间(IO Address,它是由intel定义的)来访问的。然而,由于IO地址空间的一些限制和不良影响(在这里我们暂不讨论),这种地址空间很快就失去了软件和硬件厂商的青睐。这使得IO设备的内部寄存器/存储被映射到了memory地址空间(Memory Address Space,内存地址空间),一般被称作内存映射IO或者简称MMIO(Memory-Mapped IO)。然而,因为早期的软件是使用IO地址空间来访问IO设备的内部寄存器/存储的,所以实际中常用的做法是将一套设备特定寄存器既映射到内存地址空间,也映射到IO地址空间。这使得新的软件可以使用内存地址空间,也就是通过MMIO,来对设备的内部位置进行访问。而传统(旧)的软件也依然可以运行,因为它依然可以通过IO地址空间来访问设备的内部寄存器。
对于更加新型的设备,如果它们不再依赖老旧的传统软件并且也不需要考虑对传统操作的兼容问题,那么它们一般只要将内部寄存器/存储映射到内存地址空间(MMIO)即可,而不需要请求IO地址空间来进行映射。实际上,PCIe协议中不鼓励使用IO地址空间,支持这种操作仅仅是因为一些传统遗留问题,并有可能在未来新版本的协议中被弃用。
如图 4‑1所示,图中展示了一种通用的内存和IO的映射。内存映射的大小是这个系统可使用地址范围(通常由CPU的可寻址范围决定)的一个函数。PCIe中IO映射的大小被限制为32bits(4GB),虽然其实很多使用Intel兼容(x86)处理器的计算机中仅有低16bit(64KB)被使用。PCIe可以支持的内存地址大小达到64bit。
图 4‑1给出的映射示例仅展示了EP所声明使用的MMIO和IO,但是这种能力并不是EP所独有的。它对于Switch和RC来说也是一种很普通的能力,Switch和RC内部也存在着可以通过MMIO和IO地址来进行访问的设备特定寄存器。
图 4‑1展示了被PCIe设备声明的两种不同类型的MMIO:可预取MMIO(Prefetchable MMIO,P-MMIO)和不可预取MMIO(Non-Prefetchable MMIO,NP-MMIO)。了解这两种内存空间之间的区别是十分重要的。可预取空间有两个意义十分明确的属性:
n 读操作不存在副作用。(Reads do not have side effects)
n 允许写合并(Write merging is allowed)
将MMIO的一个区域定义为可预取的,这样就可以推测性的提前获取该区域中的数据,以预测Requester在不久的将来可能需要比当前实际请求更多的数据。之所以这种小型的Caching(Minor Caching)数据操作是安全的,是因为读取这些数据并不会改变目标设备的任何状态信息,也就是说读取某个位置并不会带来副作用。例如,如果一个Requester请求从一个地址中读取128byte数据,那么Completer可以在给出此次请求的128byte之后也预取出下一个128byte,而当下一个128byte被请求时数据早已经被Completer从内存空间中预取出来了,这样就提高了性能。然而如果Requester再也没有请求额外的数据,那么Completer就需要将预取的数据清除掉,释放自身的Buffer空间。如果读取数据的行为改变了对应地址上的数值(或者有其他的什么副作用),那么就将会无法恢复被清除的数据了。然而对于可预取空间来说,读取行为并没有任何副作用,因此它总是可以回退并且在稍后也能获得原始的数据,因为原始的数据一直都不变的存放在那里。
你也许会想知道什么样的内存空间会存在读取操作的副作用。举一个例子,一个内存映射的状态寄存器,它被设计成在读取时自动清除自己,这样可以减少程序员在读取这个状态后还需要额外步骤来清除这些比特的操作。
做这种可预取和不可预取的区分,对于PCI的意义要大于PCIe,因为PCI总线协议中的事务并没有包含传输量大小的信息。如果设备都在同一条总线上交换数据,那么没有传输量大小的信息也不是什么问题,因为在同一总线上会有实时的握手信号来指示Requester什么时候收到了足够的数据完成了事务。但是如果数据的传输需要跨过一个Bridge来到另一条总线,那么情况就不像刚才一样简单了,因为对于跨到不同总线的读操作来说,Bridge在收集另一条总线上的数据时需要去猜测传输数据总量。如果猜错了传输量的大小则会增加延时而降低性能,因此在这种情况下若拥有预取的权限则对提升性能会有不小的帮助。这就是为什么将内存空间指定为可预取的概念在PCI中很有好处。由于PCIe请求中包含了传输量大小的信息,所以可预取空间并不像以前在PCI中那样引人关注了,但是为了向后兼容性,PCIe还是继承了这种概念。

图 4‑1通用的Memory与IO的地址映射
图 4‑1通用的Memory与IO的地址映射
一个系统中的每个设备对地址空间的数量和类型可能都有不同的要求。例如,一个设备可能有256byte大小的内部寄存器/存储需要通过IO地址空间来访问,而另一个设备中可能有16KB的内部寄存器/存储需要通过MMIO来访问。
基于PCI的设备不允许自己来决定哪些地址可以用来访问它们内部的位置,做这些决定是系统软件负责的工作(例如BIOS和操作系统内核)。因此设备必须为系统软件提供一个途径用来确定设备对地址空间的需求。一旦软件知道了设备对地址空间的需求是什么样的,并假设这个需求是可以被满足的,软件就会给对应的设备分配一段可用的地址范围和相应的地址空间类型(IO、NP-MMIO、P-MMIO)。
这些都是通过配置空间Header中的基地址寄存器BARs(Base Address Registers)来完成的。如图 4‑2所示,一个Type 0 Header拥有6个可用的BAR(每个大小为32bit),而一个Type 1 Header只拥有2个BAR。Type 1 Header是存在于所有Bridge设备中的,这意味着每个Switch端口和RC端口都会拥有1个Type 1 Header。Type 0 Header只存在于非Bridge设备中,例如EP。关于这里的一个例子可以参阅图 4‑3。
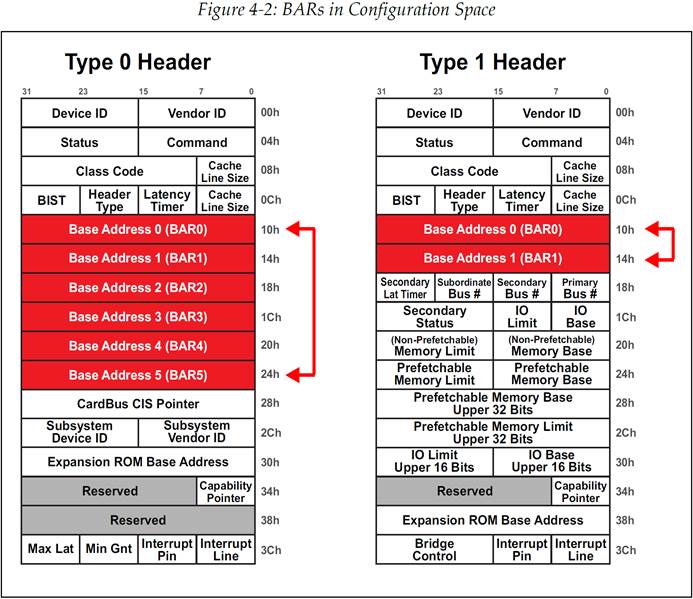
图 4‑2配置空间中的BARs
系统软件必须首先确定设备所需地址空间的大小和类型。设备的设计者知道设备中需要通过IO或者MMIO访问的内部寄存器/存储的总体大小。设备的设计者还知道当这些寄存器被访问时设备将会如何工作(例如读取操作是否有副作用)。这将决定设备所需要的是可预取MMIO(读取操作无副作用)还是不可预取MMIO(读取操作有副作用)。知道了这个信息之后,设备设计者将BARs的低位bit固定为某个值,以此来指示需要请求的地址空间的大小和类型。
BARs的高位bit是软件可进行写入的。一旦系统软件通过检查BARs的低位bit确定了设备所请求的地址空间的大小和类型,系统软件就会将分配给这个设备的地址范围的基地址写入BAR中。由于一个EP(使用Type 0 Header)拥有6个BARs,它最多可以请求6个不同的地址空间。然而,一般实际中请求6个不同的地址空间并不常见。绝大多数设备会请求1到3个不同的地址范围。
并不是所有的BARs都需要被实现。如果一个设备并不需要使用所有的BAR来映射自己的内部寄存器,那么多余的BARs将会被固定为全0,以此来通知软件这些BARs并没有被实现。
一旦BARs被编程写入(programmed),设备内的内部寄存器或者本地内存(local memory)就可以通过BARs中所写入的地址范围进行访问。任何时候,当设备发现一个请求事务的地址是映射到自己的一个BAR时,它就会接收这个请求事务,因为它自己就是这个请求的目标设备。

图 4‑3 PCIe设备中对Type 0、Type 1 Header的用法
图 4‑4展示了设置建立一个BAR的基础步骤,在本例中,要请求一个4KB大小的不可预取内存(NP-MMIO,non-prefetchable memory)。在图中,展示了BAR在配置过程中的三个节点:
\1. 在图 4‑4中的(1),我们可以看到BAR处于未初始化的状态。设备的设计者已经将低位bit固定为一个数值,来指示需要的memory的大小和类型,但是高位bit(可写可读的)则仍然是用X来表示,这代表它们的值还未知。系统软件将会首先把每个BAR都通过配置写操作来将可写入的bit写为全1(当然,被固定的低位bit不会受到配置写操作的影响)。在图 4‑4的(2)中展示的BAR就是处于第二阶段的样子,除了被固定的低位bit以外,所有的bit都被写为1。
写为全1这个操作是为了确定最低位的可写入的bit(least-significant writable bit)是哪一位,这个bit的位置指示了需要被请求的地址空间的大小。在本例中,最低位的可写入的bit为bit 12,因此这个BAR需要请求2的12次方(或者说是4KB)的地址空间。如果最低位的可写入的bit为bit 20,那么这个BAR就要请求2的20次方(1MB)的地址空间。
\2. 在软件将BARs中所有可写bit都写为1后,软件将从BAR0开始,依次读取每个BAR的数值,以此来确定各个BAR要请求的地址空间的大小和类型。表 4‑1中总结了本例中对BAR0进行配置读的结果。
\3. 这个过程中的最后一步就是系统软件为BAR 0分配一个地址范围,因为对于软件来说现在已经知道了BAR 0请求的地址空间的大小和类型。图 4‑4的(3)中展示了BAR处于第三阶段的样子,此时系统软件已经将一块地址区域的起始地址写入了BAR 0中。在本例中,这个起始地址为F900_0000h。
到这里为止,对BAR 0的配置就完成了。一旦软件启用了命令寄存器(Command register,偏移地址04h)中的内存地址译码(memory address decoding),那么这个设备就会接受所有地址在F900_0000h-F900_0FFFh(4KB大小)范围内的memory请求。

表 4‑1对BAR 0写入全1后再读取BAR 0时的结果

图 4‑4设置建立32bit不可预取内存的BAR
在上一个例子中,我们看到了通过BAR 0来请求不可预取内存地址空间(NP-MMIO)。在当前的例子中,如图 4‑5所示,BAR 1和BAR 2被用来请求一块64MB的可预取内存地址空间。这里使用了两个连续相连的BAR是因为这个设备支持这个内存地址空间的请求使用64bit地址,这意味着如果需要的话,软件给它分配的地址空间可以超过4GB地址边界(并非必要)。由于地址可以是64bit位宽,因此必须将两个连续相连的BAR一起使用。
跟上面一样,将BAR在配置过程中分为3个节点:
\1. 在图 4‑5中的(1),我们可以看到一对BAR都处于未初始化的状态。设备的设计者已经将低位BAR(在本例中为BAR 1)中的低位bit固定为一个数值,来指示需要的memory的大小和类型,但是高位BAR(BAR 2)中的bit则都是可读可写的,没有被固定。系统软件的第一步就是把每个BAR都通过配置写操作来将可写入的bit写为全1。在图 4‑5的(2)中展示的BAR就是处于第二阶段的样子,除了BAR 1中被固定的低位bit以外,所有的bit都被写为1。
\2. 如上一个例子所述,系统软件已经评估过BAR 0。因此软件的下一步就是读取下一个BAR(BAR 1),并对其进行评估,以此来确定设备是否正在请求更多的地址空间。一旦BAR 1被读取,软件就会发现设备正在请求更多的地址空间,并且所请求的地址空间类型为可预取内存地址空间(P-MMIO),这个地址空间可以被分配为64bit地址范围的任何一个位置。由于这个地址空间请求支持64bit地址,那么下一个连续相连的BAR(本例中为BAR 2)就会被当做是BAR 1的高32bit。因此软件也会读取BAR 2的内容。然而,软件并不会对BAR 2进行像对BAR 1一样的低位bit的评估,因为软件仅仅是将BAR 2简单的当做BAR 1发起的64bit地址请求的高32bit。表 4‑2中总结了本例中对两个BAR都写入全1后再进行配置读的读取结果。
\3. 这个过程中的最后一步就是系统软件为这一对BAR分配一个地址范围,因为对于软件来说现在已经知道了这一对BAR请求的地址空间的大小和类型。图 4‑5的(3)中展示了这两个BAR处于第三阶段的样子,软件已经通过两次配置写操作将分配的地址区域的64bit起始地址写入BAR 1与BAR 2的组合体中。在本例中,高位BAR的bit 1(BAR pair的bit 33)被置为1,低位BAR的bit 30(也是BAR pair的bit 30)也被置为1,这表示其实地址为2_4000_0000h。两个BAR中所有其他的可写bit都已被清零。
到这里为止,BAR Pair(BAR 1和BAR 2)的配置就已经完成了。一旦软件启用了命令寄存器(Command register,偏移地址04h)中的内存地址译码,那么这个设备就会接受所有地址在2_4000_0000h-2_4300_0000h(64MB大小)这个范围内的memory请求。

图 4‑5设置建立64bit可预取内存的BAR

表 4‑2将两个BAR都写入为全1后的读取结果
让我们在前面两个例子的基础上继续,我们假设当前的Function还需要请求IO空间,如图 4‑6所示。在图中,进行请求的BAR(本例中为BAR 3)在配置过程中分为3个节点:
\1. 在图 4‑6中的(1),我们可以看到BAR 3处于未初始化的状态。系统软件此前已经将每一个BAR都写入了全1(写入BAR中可写的bit,不可写的不受影响),并且已经对BAR 0、BAR 1 BAR 2组成的BAR Pair进行了评估。现在软件要继续看看设备是否还需要通过BAR 3来请求更多的地址空间。图 4‑6中的状态(2)展示了BAR 3被写入全1后的样子。
\2. 软件现在将会读取BAR 3的内容,以此来评估请求地址空间的大小和类型。表 4‑3中总结了本次配置读的读取结果。
\3. 读取BAR 3的内容之后,软件就知道了这个地址空间请求是要请求256byte大小的IO地址空间,那么软件的最后一步操作就是要为设备分配一个IO地址空间范围,并将这个地址范围的起始地址写入BAR 3。图 4‑6中的状态(3)所展示的BAR 3就是完成了写入起始地址的样子。在我们的例子中,这个设备的起始地址为16KB,所以bit 14是被置为1的,也就是说基地址为4000h,所有的高位bit都是清0的。
到目前为止,对BAR 3的配置已经完成了。一旦软件启用了命令寄存器(Command register,偏移地址04h)中的IO地址译码,那么这个设备就会接受并响应所有地址在4000h-40FFh(256Byte大小)这个范围内的IO事务。

图 4‑6 IO BAR的设置建立

表 4‑3 IO BAR被写入全1后再读取的读取结果
在讲解了前面的三个示例之后,我们可以很明显的发现,软件必须按顺序来对BARs进行评估,即BAR 0—BAR 1—BAR 2—BAR 3这样的顺序。
大多数时候,Function并不需要启用全部的6个BAR。即使是在我们上面举的例子中,也仅仅是使用了6个BAR中的4个。如果上面例子的基础上并不需要继续请求更多的地址空间,那么设备的设计者需要将BAR 4和BAR 5的所有bit都强制固定为全0。这样的话,即使软件也对BAR 4和BAR 5用配置写来写入全1,BAR 4和BAR 5的值(全0)也不会受到配置写的影响。在对BAR 3进行完评估(evaluate)之后,软件需要继续去评估BAR 4。一旦软件检测到BAR 4中没有bit被置为1(因为BAR 4的所有bit都被强制固定为0),软件就知道这个BAR并没有被使用,然后继续去评估下一个BAR(也就是BAR 5)。
即使软件发现了一个BAR并没有被使用,所有的BAR也都必须被评估。在PCI或者PCIe中,并没有规定说一定要以BAR 0来作为第一个用来请求地址空间的BAR。如果设备的设计者需要的话,他们也可以选择比如说BAR 4来作为第一个请求地址空间的BAR,并将BAR 0、BAR 1、BAR 2、BAR 3、BAR 5的所有bit都强制固定为0。这也再一次说明了软件必须按照顺序对Header中的每一个BAR都进行评估。
在PCIe协议的2.1版本中新加入的一个特性,支持改变BAR中所请求的地址空间的大小,这种特性是通过在扩展配置空间内定义一个新的能力结构(Capability Structure)来实现的。新的Capability Structure使得Function能够公布(advertise)它可以操作的地址空间的大小,然后让软件根据实际可用的系统资源来选用Function所公布的地址空间大小中的某一种。例如,如果一个Function理想情况下要拥有2GB的可预取内存地址空间(Prefetchable Memory Address Space),但是它也可以只使用1GB、512MB或者256MB的P-MMIO进行操作,假如说系统软件无法容纳更大的、大于256MB的地址空间请求,那么系统软件应该就只能使Function请求256MB的地址空间。
一旦一个Function的BAR们都被编程写入了,这个Function就知道自己所拥有的地址范围了,这意味着这个Function将会把任何目的地址在这一范围内的事务都声明为自己的,这个地址范围就是被写入它的某一个BAR的地址范围。这本身没什么问题,但是更重要的是要认识到,Function要“看到”它应该声明的事务的唯一办法是,它上方的Bridge需要将这些事务向下转发到这个目标Function所连接的相应的链路。因此,每个Bridge(例如Switch的端口和RC端口)都需要知道它下方所存在的可用地址范围,这样Bridge才能确定哪些请求需要从它的主接口(Primary interface,它在上方)被转发到它的次级接口(Secondary interface,它在下方)。如果一个请求的目标地址是这个Bridge下方Function的BAR中的地址,那么这个请求就应该被转发到Bridge的次级接口。
在Bridge的Type 1 Header中有Base寄存器和Limit寄存器,而Bridge下方的地址范围将会被编程写入这两种寄存器。在每个Type 1 Header中可以看到有3套Base和Limit寄存器。之所以需要三套是因为一个Bridge下的地址范围可以被分成三类:
n 可预取内存空间(P-MMIO)
n 不可预取内存空间(NP-MMIO)
n IO空间(IO)
为了解释这些Base和Limit寄存器是如何工作的,让我们在上一节的例子上继续进行讲解,并将上一节例子中那个已经完成BAR配置的EP放在一个Switch的下方,如图 4‑7所示。图中也列出了这个Function中各个BAR所拥有的地址范围。
对于每个下方存在EP的Bridge来说,它的Base和Limit寄存器都需要被编程写入,但在开始这个写入过程之前,我们先来关注一下连接到我们示例EP的Bridge,也就是Switch的Port B。

图 4‑7设置建立Base和Limit寄存器值的示例的拓扑
Type 1 Header有两对可预取内存base/limit寄存器。被称为Prefetchable Memory Base/Limit的寄存器要储存可预取地址范围的低32bit地址信息。如果这个Bridge支持对64bit地址进行译码,那么另一个被称为Prefetchable Memory Base/Limit Upper 32bits寄存器就也需要被启用,要用它来储存地址范围的高32bit,也就是bit[63:32]。图 4‑8中展示了软件应该写入这些寄存器的值,以此来指示这个Bridge(Switch的Port B)下方的可预取地址范围为2_4000_0000h-2_43FF_FFFFh。这些寄存器的每个字段的含义都被总结在了表 4‑4中。
下面对表 4‑4中内容进行复述。
n Prefetchable Memory Base寄存器:
n 值为4001h。
n 用法为,寄存器的高12bit用来存放32bit BASE地址的高12bit,也就是[31:20]。Base地址中的低20bit全是0,这意味着Base地址总是在1MB边界上对齐。
寄存器的低4bit用于指示Bridge中是否支持64bit地址译码,这4bit值为1则意味着Upper Base/Limit寄存器要被启用。
n Prefetchable Memory Limit寄存器:
n 值为43F1h。
n 用法与Base寄存器相似,这个寄存器的高12bit用来存放32bit LIMIT地址的高12bit,也就是[31:20]。Limit地址的低20bit为全1(16进制下都是F)。这个寄存器的低4bit和base寄存器的低4bit含义相同。
n Prefetchable Memory Base Upper 32bits寄存器:
n 值为00000002h。
n 用法为,这个寄存器用来存放这个端口下方可预取内存的64bit BASE地址的高32bit。
n Prefetchable Memory Limit Upper 32bits寄存器:
n 值为00000002h。
n 用法为,这个寄存器用来存放这个端口下方可预取内存的64bit Limit地址的高32bit。

图 4‑8示例中Prefetchable Memory Base/Limit 寄存器的值

表 4‑4示例中Prefetchable Memory Base/Limit 寄存器的含义
不可预取内存空间只支持32bit地址,这一点不同于可预取内存空间范围。因此对于不可预取内存空间来说,只有1个base寄存器和1个limit寄存器。按照图 4‑7的示例,Port B的Bridge中的Non-Prefetchable Memory Base/Limit寄存器应该被写入的值被展示在图 4‑9中。这些寄存器的每个字段的含义都被总结在了表 4‑5中。
下面对表 4‑5中内容进行复述。
n Non-Prefetchable Memory Base寄存器:
n 值为F900h。
n 用法为,寄存器的高12bit用来存放32bit BASE地址的高12bit,也就是[31:20]。Base地址中的低20bit全是0,这意味着Base地址总是在1MB边界上对齐。
寄存器的低4bit必须要为0。
n Non-Prefetchable Memory Limit寄存器:
n 值为F900h。
n 用法与Base寄存器相似,这个寄存器的高12bit用来存放32bit LIMIT地址的高12bit,也就是[31:20]。Limit地址的低20bit为全1(16进制下都是F)。这个寄存器的低4bit和base寄存器的低4bit含义相同。
寄存器的低4bit必须要为0。

图 4‑9示例中Non-Prefetchable Memory Base/Limit 寄存器的值

表 4‑5示例中Non-Prefetchable Memory Base/Limit 寄存器的含义
这个例子展示了一个很有趣的情况,那就是实际上Port B下方的EP所拥有的NP-MMIO范围大小为4KB,但是Port B的配置空间却表示出了1MB的范围,这远大于4KB。这是因为Type 1 Header中的base/limit寄存器只能用来表示地址的[31:20]。低20bit也就是[19:0],则会被隐去。因此内存空间base/limit寄存器所能标志的最小范围就是1MB。
在我们的例子中,EP请求并被授予了4KB的NP-MMIO(F900_0000h-F900_0FFFh)。而Port B中NP-MMIO的base/limit寄存器被写入的值则指示了这个Port下存在的NP-MMIO大小为1MB(F900_0000h-F90F_FFFFh),或者说是1024KB。这意味着有1020KB的内存地址空间(F900_1000h-F90F_FFFFh)被浪费了。即使这样,这些被浪费的地址空间也一定不能被分配给其他的EP,否则这会导致对数据包的路由机制无法工作。
类似于可预取内存范围,Type 1 Header中IO base/limit寄存器也有两对。被称为IO Base/Limit的寄存器用于存放IO地址范围的低16bit地址信息。若这个Bridge支持32bit IO地址的译码操作(现实设备中很少见),那么就要启用IO Base/Limit Upper 16Bits寄存器来存放地址信息的高16bit,也就是IO地址范围的[31:16]。按照我们的前面的示例,在图 4‑10中给出了软件要写入这些寄存器的值,以此来表示这个Bridge(Port B)之下存在的IO地址范围为4000h-4FFFh。这些寄存器的每个字段的含义都被总结在了表 4‑6中。
下面对表 4‑6中内容进行复述。
n IO Base寄存器:
n 值为40h。
n 用法为,寄存器的高4bit用来存放16bit BASE地址的高4bit,也就是[15:12]。Base地址中的低12bit全部被设置为0,这意味着Base地址总是在4KB边界上对齐。
寄存器的低4bit用于指示Bridge中是否支持32bit地址译码,这4bit值为1则意味着Upper Base/Limit寄存器要被启用。
n IO Limit寄存器:
n 值为40h。
n 用法与Base寄存器相似,这个寄存器的高4bit用来存放16bit LIMIT地址的高4bit,也就是[15:12]。Limit地址的低12bit为全1(16进制下都是F)。这个寄存器的低4bit和base寄存器的低4bit含义相同。
n IO Base Upper 32bits寄存器:
n 值为0000h。
n 用法为,这个寄存器用来存放这个端口下方IO地址空间的32bit BASE地址的高16bit。
n IO Limit Upper 32bits寄存器:
n 值为0000h。
n 用法为,这个寄存器用来存放这个端口下方IO地址空间的32bit Limit地址的高16bit。

图 4‑10示例中IO Memory Base/Limit 寄存器的值

表 4‑6示例中IO Base/Limit 寄存器的含义
在这个例子中,我们又看到了一种情况,Bridge被编程写入的地址空间要远大于其下方的Function所拥有的的实际IO地址空间。例子中EP拥有的地址空间为256Byte(4000h-40FFh)。而Port B被编程写入的值却表示其下方存在的IO地址空间为4KB(4000h-4FFFh)。同前面讨论MMIO时一样,这也是Type 1 Header的一种局限。对于内存地址空间来说,低12bit(bit[11:0])的值是被隐去的,因此能被指定的IO地址范围的最小值就是4KB。这种局限比内存范围中的1MB最小窗口(1MB minimum window)要更加严重。在基于x86(Intel兼容)的系统中,处理器仅支持16bit的IO地址空间,而由于IO地址信息仅有bit[15:12]是可以被指定在Bridge中,这就意味着一个系统中最多就只能有16个(2^4)不同的IO地址范围。
并不是每个PCIe设备都会使用全部的3种地址空间(P-MMIO、NP-MMIO、IO)。实际上,PCIe协议中不鼓励使用IO地址空间,支持这种操作仅仅是受一些传统遗留因素影响,并有可能在未来新版本的协议中被弃用。
我们来假设这种情况,一个EP中并没有请求使用所有的3种地址空间,那么对于这样的设备上方的Bridge来说,它的base和limit寄存器应该被配成什么值呢?首先,我们肯定不能简单地就把它们写入全0,因为低位的被隐去的地址bit依然是不同的(base中低位bit认为全0,limit中低位bit认为全F),这依然会表示出一个有效的地址范围。所以为了解决这些情况,就必须令base寄存器中的写入值大于limit寄存器的写入值。例如,如果一个EP并没有请求IO地址空间,那么这个Function上方直接相连的Bridge将会把IO Limit寄存器写为00h,将IO Base寄存器写为F0h。由于Base地址大于Limit地址,Bridge会知道这是一个无效的设置,并以此来认定其下方没有Function拥有IO地址空间。(这里原书中有误,写成了将limit配置为大于base,这个错误在errata中已经列出)
这种使base和limit寄存器无效化配置的方法对于所有的3种base/limit寄存器都是可行的,而不只是针对IO base/limit寄存器。
为了确保你已经理解了设置建立BARs和Base/Limit寄存器的规则和方法,请仔细查看图 4‑11,以保证你对它们的正确认知。我们简单的对示例系统进行了扩展,在Switch的Port A下方加入了另一个EP以及它所请求的地址空间。要记得,Type 1 Header中也含有2个BAR,它们也可以请求地址空间。而一个Bridge的Base/Limit寄存器表示的地址空间范围并不包括Bridge自身的BAR所请求的地址空间,也就是说Base/Limit寄存器只表示Bridge下方存在的地址空间。

图 4‑11最终的地址路由示例建立
在前几个小节中所讲述的设置建立BARs和Base/Limit寄存器的目的,是为了确保流量(traffic)可以被正确的路由到它的目的Function,之后目的Function就可以看见这些流量中的事务并声明对这些事务的所有权。在例如PCI的这种共享总线(Share-Bus)结构中,所有的流量对于总线上的每个设备都是可见的。只有当流量的目的地在另一条总线,也就是必须跨越一个Bridge时,才会对请求进行路由。由于PCIe链路是点对点的(point-to-point),那么在设备间发送事务时就需要更多的路由操作了。

图 4‑12多端口的PCIe设备有进行路由的职责
如图 4‑12所展现的这样,一个PCIe拓扑使用独立的、点对点的链路来将各个设备与它们的一个或多个邻设备(neighbors)相连接。当流量到达链路接口的入站端(inbound side,或称为ingress port入口端口),这个端口将会进行错误校验,然后做出如下的三个决定中的一个:
\1. 接收这个流量并在自身内部使用它。
\2. 将这个流量转发至相应的出站(outbound,或者egress出口)端口。
\3. 拒绝这个流量,因为入口端口自身既不是这个流量的预期的目标,也不是一个用来对它进行转发的接口。(注意,还存在其他可能的原因导致流量被拒绝)
假设一条链路处于完全可工作状态,那么每个设备的接收接口(入口端口ingress port)必须对到达的三种链路流量进行检测和评估:Ordered Sets(命令集)、DLLPs(Data Link Layer Packets数据链路层包)以及TLPs(Transaction Layer Packets事务层包)。Ordered Sets和DLLPs对于链路来说是本地的,因此它们不用被路由到另一条链路。TLP可以并且也有可能需要被从一条链路搬移到另一条链路,这种操作所基于的路由信息存在于数据包的Header中。
对于像RC和Switch这样具有多个端口的设备来说,它们可以在端口之间转发TLPs,它们有时也被称作Routing Agent(路由媒介)或是Routing Element(路由元件)。它们会接受目标为自身内部资源的TLP,也会将TLP在自身入口端口和出口端口之间进行转发。
有趣的是,Switch需要支持Peer-to-Peer的路由,但是对于RC来说这项功能是可选的。Peer-to-Peer流量通常是一个EP向另一个EP发送数据包。
EP只有一条链路,并且它永远不希望看到一个目的地不是它自己的流量,对于它来说只会简单地接受或者拒绝输入的TLPs,而不会进行转发。
TLP可以被基于地址路由(Memory或IO),可以被基于ID路由(Bus—Device—Function),或者还可以被隐式路由(routed implicitly)。具体使用的路由办法要根据TLP类型来决定。表 4‑7总结了TLP类型和路由方法的对应关系。

表 4‑7 PCIe TLP类型对应的路由方法
可以发现,Message是唯一一种支持多种路由方法的TLP类型。PCIe协议中定义的大多数message使用的是隐式路由,然而由厂商定义的message则根据需要也可以使用地址路由或者ID路由。
在隐式路由中,不使用地址或者ID这种路由信息;相反,这个数据包是根据包头中的一个代码(code)来进行路由的,这个代码指示的目的地是拓扑结构中一个已知的位置,例如RC。这种方法简化了使用隐式路由的message路由。
Message事务在PCI和PCI-X中并没有被定义,但是在PCIe中被引入。加入Message作为一种数据包类型的主要的原因是,为了继续进行PCIe的设计目标之一,也就是大幅度地减少以前PCI中的边带信号(sideband signals)的使用,例如中断pins、错误pins、电源管理信号等等。因此,大多数的边带信号都被带内(in-band)数据包所替代,这些数据包的形式就是Message TLP。
要使用带内Message来替代边带信号,就需要一种方法来将这些Message路由到正确的收件方(recipient)那里去,而Message的收件方位于一个由数量众多的点到点链路组成的拓扑结构中。隐式路由利用了这样一个事实:Switch和其他的路由元件是可以理解上行(upstream)和下行(downstream)的概念的,且RC是位于整个拓扑结构的最顶端,而EP则是位于拓扑结构的底部。因此举例来说,一个Message可以使用一个简单的代码来表示它应该被送往RC,或者是要被送往下行的所有设备。上述的这种能力能够有效的减少对定义地址范围或是ID列表的需要,而原本是需要针对不同的Message来定义特定的地址范围或是ID列表才能完成路由。
不同类型的隐式路由的相关内容可以参阅“Implicit Routing”一节。
像大多数其他串行传输技术一样,PCIe使用拆分事务协议(Split Transaction Protocol),它允许一个目标设备接收一个或多个请求,然后再使用单独的完成包来对这些请求进行响应。相比于在PCI中使用等待态(wait-state)或是延迟传输(retry)来处理访问目标时出现的延迟,拆分事务协议是一种显著的进步。拆分事务协议不再使用通过试探目标是否处于ready才进行访问的高延迟传输机制,而是使用目标设备自己发起响应的方式,无论何时只要目标设备处于ready,它都能自己发起响应,而这个响应所对应的请求是此前就已经给到目标设备的了。这种方式使得每个事务的完成都至少需要两个单独的TLP——Request(请求包)和Completion(完成包),而我们后面将会讲到,对于一个单独的读请求,可能会有多个完成包返回。图 4‑13展示了一个拆分事务中的Request-Completion的组成,这个例子的场景是软件从EP读取数据。

为了减少Request-Completion延迟所带来的开销和损失,MWr(Memory Write)事务是Posted的,这意味着从Requester的角度来说,当这个Posted事务刚从Requester发出去,就认为它已经完成了。如果想帮助理解,可以将术语“Posting(邮寄)”和邮政系统(postal system)联系到一起,因为“邮寄”一个MWr和邮寄一封信十分相似。一旦你将要邮寄的信放入邮局邮箱,你就会相信邮政系统会把它送出去,而不必去等待投递的确认。这种方法比等待整个Request-Completion传输完成要快的多。但是,在所有的邮寄方案中都会存在不确定性,事务是否、何时在最终的接收方被成功完成,这是不确定的。
在PCIe中,尽管所有的Posted MWr会带来不确定性,但是相比于这种方法获得的收益来说,这种不确定性是比较少量且可以接受的。相比之下,对IO和配置空间的写操作几乎都会影响设备的行为,且这种影响还是实时与这两种写操作相关联的。因此,对于这样的写请求来说,非常有必要知道它们是否完成以及什么时候完成。基于这样的原因,IO写和配置写必须要是Non-Posted的,它们总是需要收到一个返回的完成包来报告自身操作的状态。
总结来说,Non-Posted事务需要完成包,Posted事务不需要完成包而且也永远不应该收到一个完成包。表 4‑8列出了哪些PCIe事务是Posted的,哪些是Non-Posted的。
下面对表 4‑8的内容进行复述:
n Memory Write:
所有的Memory Write请求都是Posted的。不需要返回完成包(Completion)。
n Memory Read和Memory Read Lock:
所有的Memory Read请求都是Non-Posted的。需要由Completer返回一个带有数据的Completion(这个Completion由一个或多个TLP组成),Completer通过Completion来传递Requester所请求的数据以及当前Memory Read事务的状态。若发生了错误,那么返回的用于报告错误状态的Completion将不含有数据。
n AtomicOP:
所有的AtomicOP请求都是Non-Posted的。需要由Completer返回一个带有数据的Completion,这个Completion中包含了目标位置的原始值。
n IO Read和IO Write:
所有的IO请求都是Non-Posted的。对于IO Write和失败的Read来说,需要返回一个不含有数据的Completion。而对于成功的Read来说,则需要返回一个带有数据的Completion。
n Configuration Read和Configuration Write:
所有的Configuration请求都是Non-Posted的。与IO请求类似,对于Configuration Write和失败的Read来说,需要返回一个不含有数据的Completion。而对于成功的Read来说,则需要返回一个带有数据的Completion。
n Message:
所有的Message请求都是Posted的。虽然路由方法是取决于Message类型的,但是Message都被认为是posted请求。
简单总结来说,只有Memory Write和Message是 Posted的。

表 4‑8 Posted和Non-Posted事务
如图 4‑14所示,每个TLP都含有一个3个或4个DW(12或16byte)的Header。在TLP Header中含有Format和Type这两个字段,它们用来定义剩余的Header的内容,并决定这个TLP在拓扑结构中传递时所使用的路由方法。

图 4‑14 TLP通用的3DW和4DW Header
下方的表 4‑9中总结了TLP Header中的Format和Type字段的编码含义。

表 4‑9 TLP Header中Format和Type字段编码含义
当TLP在入口端口(ingress port)被接收到,首先要在物理层和数据链路层对TLP进行错误检查。如果检查无错,那么再由事务层来检查当前TLP使用的是哪种路由方法。基础的步骤为:
\1. Format和Type字段确定了TLP Header的大小、数据包的格式和类型。
\2. 根据TLP所使用的路由方法(与Type相关),设备将确定这个TLP的预期接收者是否就是自己。如果确实就是自己,那么设备将接受(或者说是消耗)这个TLP,否则设备将会把这个TLP转发到相应的出口端口(egress port)——根据该出口的排序和流控规则。
\3. 如果设备既不是TLP的预期接收方,且设备也并不位于前往预期接收方的路径上,那么它通常会通过一个状态字段为Unsupported Request(UR)的完成包来拒绝这个TLP。

一旦配置完了系统地址并且也允许开始执行事务,设备将会检查输入的TLP并使用相应的配置字段域来对数据包进行路由。下面的小节将会对PCIe结构中的TLP路由机制基础特点和功能进行描述。
ID路由是用来指向一个逻辑位置——Bus Num,Device Num,Function Num,或者一般称为BDF,这个逻辑位置一般是拓扑结构中的一个Function。ID路由这种机制对PCI和PCI-X协议中用于配置事务路由的方法是兼容的。在PCIe中,ID路由仍然会被用来路由配置包,同时它还可以用来路由完成包和一些Message。
PCIe支持的拓扑结构的上限与PCI和PCI-X一样:
\1. 一个系统中可以存在的最大总线数量为256,因为Bus号是8bit位宽的。这个总线数量包括了Switch产生的内部总线。
\2. 每条总线上最多可以有32个设备,因为Device号是5bit位宽的。一个老式的PCI总线或是Switch、RC的内部总线的下方可以挂载不止一个设备,然而外部的PCIe链路(external PCIe Links)就必须要是点到点的(point-to-point),也就是说外部PCIe链路下方只能挂载一个设备。下行端口(Switch或RC的下行端口)会强制将外部链路的Device号定为Device 0,因此每个外部EP都总会是Device 0。除非使用了替代路由ID解释(Alternative Routing-ID Interpretation,ARI),若使用了ARI那么这个外部Device将没有Device号,关于ARI的更多内容请参阅“IDO(ID-based Ordering)”一节。
\3. 每个设备中最多可以有8个内部Function,因为Function号是3bit位宽的。
如果一个收到的TLP中的Type字段表示了这个TLP要使用ID路由,那么TLP Header中的ID字段(Bus,Device,Function)就要用来执行路由检查(routing check)。有两种情况:使用3DW Header来进行ID路由,或者使用4DW Header来进行ID路由(这只可能出现在Message路由中)。图 4‑15展示的是一个用于ID路由的3DW Header,图 4‑16展示的是一个用于ID路由的4DW Header。

图 4‑15 3DW TLP Header中的ID路由字段

图 4‑16 4DW TLP Header中的ID路由字段
对于ID路由,一个EP只会简单地根据自己的BDF来检查TLP Header中的ID字段。每当Function在自己的链路上接收到一个Type 0配置写时,Function将会从配置写事务的TLP Header的byte8-9中“捕获(Capture)”到自己的Bus号和Device号。Function必须将Bus号和Device号存储下来,而具体是存在什么地方,协议中并没有特别指定。保存下来的Bus和Device号被可以被用作Requester ID,例如当这个EP发起请求后,请求的Completer可以将这个Requester ID放进完成包内来让完成包被顺利路由返回,Requester ID就是这个完成包用来路由的信息。

图 4‑17一个使用ID路由的入站TLP在进行Switch的路由检查
对于一个使用ID路由的TLP来说,一个Switch端口首先要检查这个TLP的预期目的地是不是端口自身,这种检查是通过将端口自身的BDF与TLP Header中的目标ID进行比较来进行的,如图 4‑17中的(1)所示。与EP一样,每个Switch端口将会从上行端口发现的每次配置写(Type 0)事务中,捕获到自己的Bus号和Device号。如果TLP中的目标ID与Switch端口的ID相同,那么Switch端口就会消耗掉(consume)这个TLP,也就是不再转发到其他地方而是自己使用。如果这两个ID字段并不相同,那么Switch端口将会检查这个TLP的目标位置是否在自己的下方。这个检查的方式是,通过检查次级总线号寄存器(Secondary Bus Number Register)和从属总线号(Subordinate Bus Number Register)来查看TLP的目标总线号是否在Switch端口下方的从属总线范围内(包括范围边界)。如果在范围内,那么就将这个TLP向下转发。图 4‑17中的(2)所表示的就是这项检查。如果数据包到达Switch的上行端口,但是没有与端口的BDF相匹配,且也不在从属总线范围内,那么它就会被作为上行端口的UR(Unsupported Request)来处理。
如果上行端口确定了所接收到的TLP的目的地是其下方的一个设备(也就是这个TLP的目标总线在上行端口的从属总线范围内),那么上行端口就会将TLP向下转发,Switch所有的下行端口都会对这个TLP做跟上面一样的检查。每个下行端口都会检查自己是不是TLP的目的地,如果是,那么这个端口将会消耗掉这个TLP而其他端口将会忽略这个TLP。如果TLP的目的地并不是任何一个下行端口,那么下行端口们都会再去检查TLP的目标设备是否在自己下方的从属总线范围中。如果有一个下行端口检查到了这个TLP的目标设备在自己的下方,那么这个端口就会将TLP转发至自己的次级总线,且其他下行端口将会忽略这个TLP。
在这一节中,很重要的一点是要记住Switch中的每一个端口(Port)都是一个Bridge,因此它们都有自己的配置空间,并且它们的配置空间Header必然是Type 1 Header。尽管在图4-17中只展示了上行端口的Type 1 Header,但是实际上每个端口(每个P2P Bridge)都有自己的Type 1 Header,并且在每个端口收到TLP时都会执行上面所述的两次检查。
使用地址路由的TLP引用的内存(系统内存和内存映射IO)和IO地址映射和PCI/PCI-X中事务引用的是一样的。如果一个Memory请求的目标地址小于4GB(即一个32bit地址),那么这个TLP必须使用3DW Header。而如果它的目标地址大于4GB(即一个64bit地址),那么这个TLP就必须使用4DW Header。IO请求的地址被限制为32bit,并且仅当为了支持传统的旧功能时才能被使能。
当TLP Header中的Type字段表示这个TLP使用地址路由时,那么就要用Header中的Address字段来执行路由检查。Address字段可以是32bit也可以是64bit的。
对于IO和32bit的Memory请求,它们所使用的3DW Header如图 4‑18所示。因此,这些TLP的目标内存映射寄存器(Memory-Mapped Registers)会存在于4GB内存边界以内。
对于64bit的Memory请求,它们所使用的4DW Header如图 4‑19所示。因此,这些TLP的目标内存映射寄存器(Memory-Mapped Registers)会存在于4GB内存边界之上。

图 4‑18 3DW TLP Header中的地址路由相关字段

图 4‑19 4DW TLP Header中的地址路由相关字段
如果一个EP收到了一个地址路由的TLP,那么EP将会用其自身配置Header中的每一个BAR(Base Address Register基地址寄存器)与TLP Header中的Address字段进行比对,如图 4‑20所示。由于EP只有一个链路接口,因此它只会接受或者拒绝数据包,而不会对其进行转发。如果TLP Header中的Address字段与EP的某一个BAR所指示的地址范围相匹配,那么EP就会接受这个TLP。更多的关于BARs是怎么样被使用的内容请参阅“基地址寄存器BARs(Base Address Registers)”一节(原书126页)。

图 4‑20 EP对输入TLP的地址进行检查
对于Switch端口来说,如果一个输入的TLP使用的是地址路由,那么端口会首先检查这个TLP的目标地址是否就是端口本身,这种检查是通过将Switch端口自身Type 1 Header中的两个BAR与TLP Header中的Address进行比对来实现的,如图 4‑21中的步骤1所示。如果TLP Header中的Address字段与某个BAR的地址范围相匹配,那么就说明这个Switch端口就是TLP的目的,端口将会消耗掉这个TLP。如果并未匹配任何一个BAR的地址范围,那么Switch端口将会检查Base/Limit寄存器对,以此来确定这个TLP的目标Function是否在本端口之下。如果Request的目标是IO空间,那么端口将会检查IO Base寄存器和IO Limit寄存器,如图 4‑21中步骤2a所示。而如果Request的目标是Memory空间,那么端口将会检查不可预取Base/Limit寄存器和可预取Base/Limit寄存器,如图 4‑21中步骤2b所示。更多关于Base/Limit寄存器对是如何被评估的信息,请参阅“Base寄存器和Limit寄存器(Base and Limit Registers)”一节。

图 4‑21 Switch检查使用地址路由的入站TLP的路由信息
为了能理解Switch中基于地址的TLP路由,最好要记住一点,每个Switch端口自身都是一个Bridge。下面的步骤描述的是一个Bridge(也就是Switch端口)接收一个基于地址路由的TLP:
图 4‑21 Switch检查使用地址路由的入站TLP的路由信息
为了能理解Switch中基于地址的TLP路由,最好要记住一点,每个Switch端口自身都是一个Bridge。下面的步骤描述的是一个Bridge(也就是Switch端口)接收一个基于地址路由的TLP:
\1. 如果TLP的目标地址与Switch端口的其中一个BAR地址范围相匹配,那么这个Bridge(Switch端口)就会消耗掉这个TLP,因为其自身就是这个TLP的目的地。
\2. 如果TLP的目标地址落在端口的Base/Limit寄存器所表示的范围内,那么这个TLP就会被转发到次级接口(Secondary Interface),也就是向下转发。
\3. 若以上两个条件都不符,且主接口(Primary Interface)上没有其他的Bridge声明拥有这个TLP,那么这个TLP将被Switch主接口当做UR(Unsupported Request)来处理。
\1. 如果TLP的目标地址与当前Switch次级接口(Secondary Interface)的其中一个BAR地址范围相匹配,那么这个Bridge(Switch端口)就会消耗掉这个TLP,因为其自身就是这个TLP的目的地。
\2. 如果TLP的目标地址落在端口的Base/Limit寄存器所表示的范围内,那么这个TLP将被Switch次级接口当做UR(Unsupported Request)来处理(除非这个端口是Switch的上行端口,在这种情况下,这个数据包可能是一个Peer-to-Peer的事务,它将会被转发至下行的另一个端口上,而不是之前接收这个TLP的端口)。
\3. 若以上两个条件都不符,那么这个TLP将会被转发至主接口(上行端口),因为这个TLP目的地既不是当前的端口Bridge,也不是这个Bridge之下的任何一个Function。
在PCIe 2.1版本中,新加入了通过指定一个地址范围来进行多播的能力。任何接收到的TLP,只要其地址落在被指定为多播范围的地址范围之内,它的路由或者接受(routed/accepted)就要根据多播规则来处理。虽然这个多播的地址范围不一定会被保留在一个Function的BARs中,也不一定会存在于Bridge的Base/Limit寄存器对中,但是它也需要通过合适的方式被接受或转发。更多的关于多播功能的信息请参阅“Multicast Capability Register”一节。
隐式路由通常被一些Message数据包所使用,它是基于路由元件的感知能力,即路由元件知道拓扑结构具有上行和下行方向,并且拓扑的最顶部是RC。这使得一些简单的路由方法可以不需要去分配目标地址或是ID就能进行路由。由于RC一般都集成了电源管理(power management)、中断(interrupt)和错误处理逻辑(error handling logic),这使得RC基本上是大多数PCIe Message的发送者或者接收者。
有些Messages使用地址或者ID路由,而不是隐式路由,那么对于这些Message来说,它们的路由机制就跟前面几节描述的ID路由和地址路由相同。然而,对于绝大多数Message来说,使用的路由机制是隐式路由。隐式路由的目的是为了模仿边带信号(side-band signal)的行为,之所以要这样是因为PCIe的设计目标之一就是要尽可能的把原本PCI中的边带信号都清除干净。PCI中的这些边带信号一般是用于Host将一个事件通知给所有的设备,或者是设备将一个事件通知给Host。在PCIe中,我们使用Message TLPs来传输这些事件,而不是通过边带信号。在PCIe中被定义了Message的事件类型有:
n 电源管理(Power Management)
n INTx传统中断信号(INTx legacy interrupt signaling)
n 错误信号(Error signaling)
n 锁定事务的支持(Locked Transaction support)
n 热插拔信号(Hot Plug signaling)
n 厂商特定信号(Vendor-specific signaling)
n 插入卡插槽功耗限制设置(Slot Power Limit settings)
对于隐式路由来说,使用TLP Header中的子字段(sub-field)来确定Message的目的地。图 4‑22展示了一个使用隐式路由的Message TLP Header。

图 4‑22 4DW Message TLP Header中的隐式路由相关的字段
表 4‑10展示了一个Message的TLP Header中Type字段的含义。如表中所示,最高的2bit用于指示这个数据包是一个Message,剩下的低3bit用于指示这个Message使用的路由方法。需要注意,Message TLP不管使用哪种路由操作,都只会使用4DW Header。若使用地址路由,那么就用byte8-15来组成64bit地址;若使用ID路由,那么就用byte8和9来组成目标BDF。

表 4‑10 Message请求Header中Type字段的用法
像Switch这样的路由元件(Routing Element)需要考虑TLP到达了哪个端口,以及TLP的路由子字段是否对这个端口来说是合适的。举例来说:
\1. 一个Switch的上行端口可以合法的接收一个广播Message。上行端口将会把这个广播Message复制一份,并向它的所有下行端口都转发。如果一个Switch的下行端口接收了一个隐式路由的广播Message(这意味着这个Message将会向上行移动),这是一种错误,它将被当做畸形TLP(Malformed TLP)来处理。
\2. 一个Switch的下行端口可以接收隐式路由目的地为RC的Message,下行端口将会把这个Message转发给上行端口,因为路由元件知道RC永远在上行。而Switch的上行端口并不会从外界接受一个隐式路由目的地为RC的Message,因为这意味着它会向下转发,但是RC却在拓扑结构的上方。
\3. 如果隐式路由Message表示它会终止在其接收者的位置,那么接收它的Switch端口将会消耗掉这个Message,而不是将其转发。
\4. 对于使用地址路由或者ID路由的Message来说,Switch会按照一般对地址或ID的检查方式来决定是接收它们还是转发它们。
DLLP和Ordered Set的流量并不会被从Switch或者RC的入口端口路由到出口端口。这些数据包只会通过物理层到物理层的链路进行传输,从一个端口移动到另一个端口。
DLLP起源于PCIe端口的数据链路层,先经过物理层,接着离开端口并在链路上传输,然后到达对端端口。在对端端口上,DLLP先经过物理层,然后最终到达数据链路层,DLLP在这里被处理和消耗。DLLP不会继续沿着端口向上到达事务层,因此它并不存在路由。
相似的,Ordered-Set数据包起源于物理层,然后离开端口并通过链路传输,最终到达对端端口。在对端端口上,Ordered-Set在物理层就被处理和消耗。由于Ordered-Set也不会继续沿着端口向上到达数据链路层或者事务层,因此它也不存在路由。
正如本章所讨论的那样,只有TLP会被Switch和RC进行路由,它们起源于源端口的事务层,结束于目的端口的事务层。
原文: Mindshare
译者: Michael ZZY
校对: Karl DGR
欢迎参与 《Mindshare PCI Express Technology 3.0 一书的中文翻译计划》
https://gitee.com/ljgibbs/chinese-translation-of-pci-express-technology


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具