
第十周实验报告:实验三 查找和排序
20162317袁逸灏 第十周实验报告:实验三 查找和排序
实验内容
- 补充查找和排序的方法
- 对补充的方法进行正常、异常、边界的测试。
实验要求
- 完成教材P302 Searching.Java ,P305 Sorting.java中方法的测试
不少于10个测试用例,提交测试用例设计情况(正常,异常,边界,正序,逆序),用例数据中要包含自己学号的后四位 - 重构你的代码
把Sorting.java Searching.java放入 cn.edu.besti.cs1623.(姓名首字母+四位学号) 包中
把测试代码放test包中
重新编译,运行代码 - 参考 http://www.cnblogs.com/maybe2030/p/4715035.html 在Searching中补充查找算法并测试
- 补充实现课上讲过的排序方法:希尔排序,堆排序,桶排序,二叉树排序等
测试实现的算法(正常,异常,边界)
实验过程
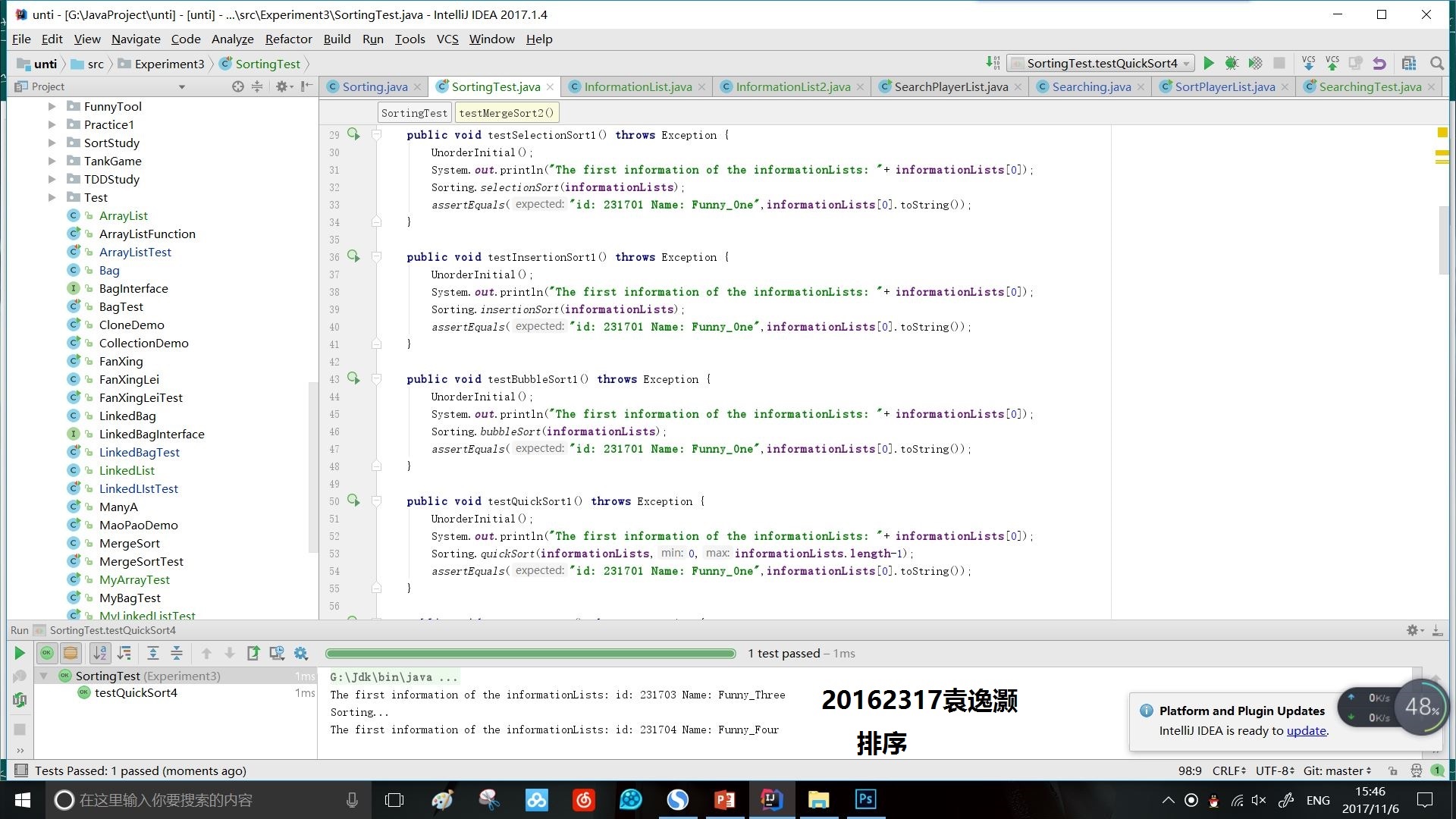
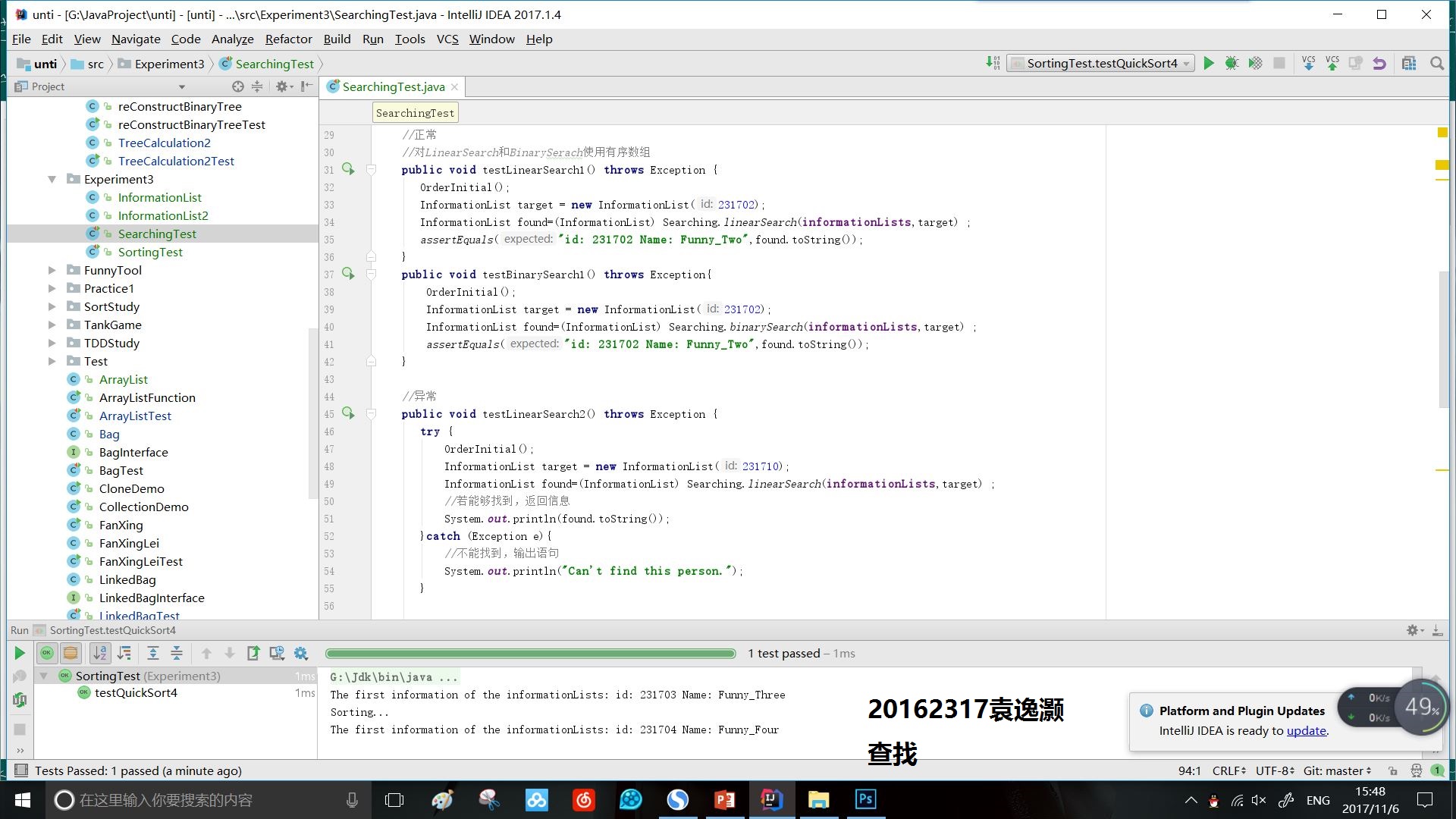
- 实验3.1
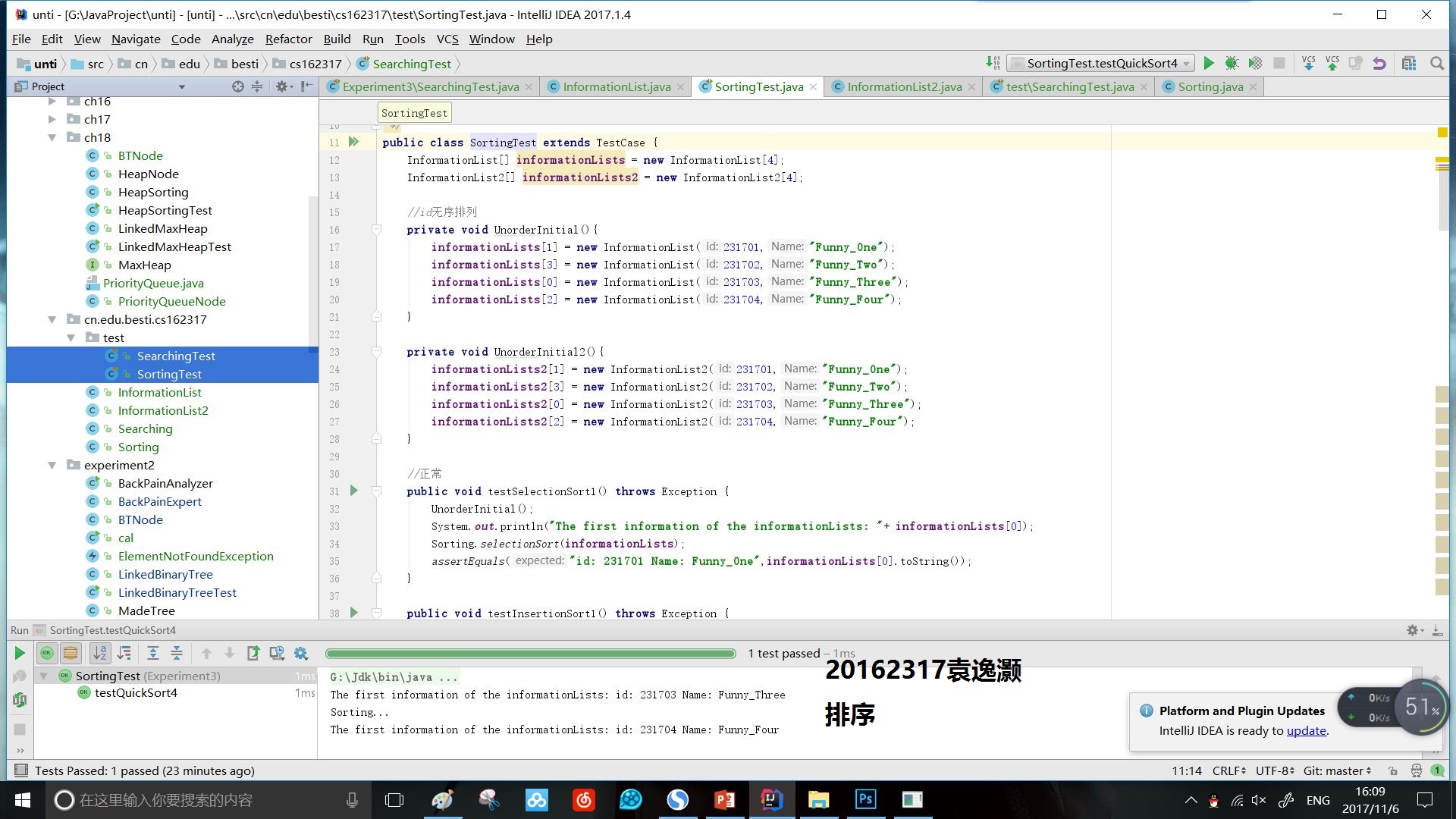
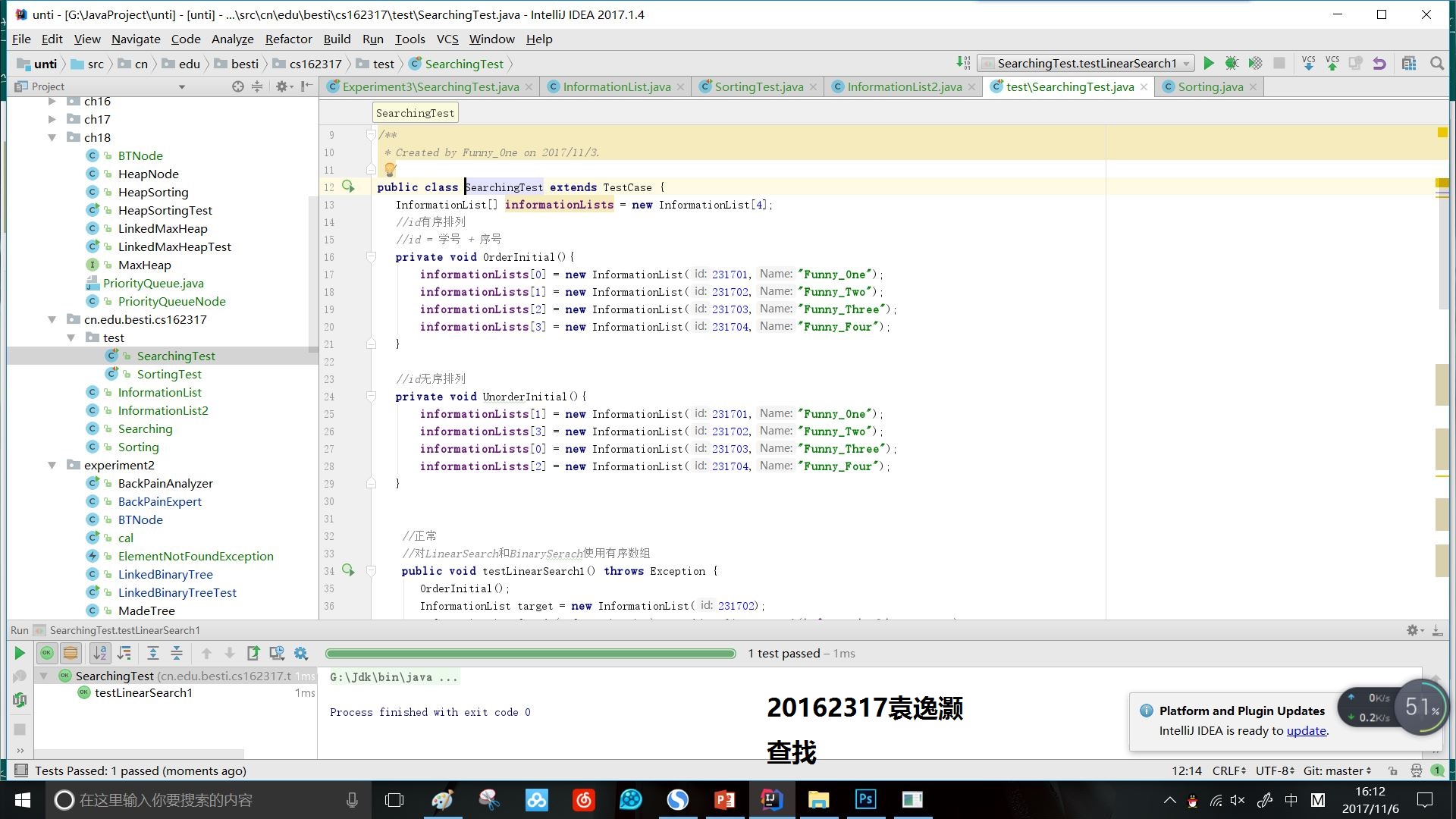
- 实验3.2
- 实验3.3
七大查找算法,该博客在原来学的顺序查找和二分查找的基础上新加了5种查找方法:
一、插值查找
插值查找可以说算是二分查找的高级版,它与二分查找的区别在于不会根据数据量来取中间的目标,而是做到了自适应,能够根据索引的目标(target)来选择离自己范围近的区间。插值查找减少了比较次数,加快了查找的效率,适合用于大数据。
二分查找中的查找点的取法:
mid=(low+high)/2
插值查找中查找点的取法:
mid=low+(key-a[low])/(a[high]-a[low])*(high-low)
实现代码:
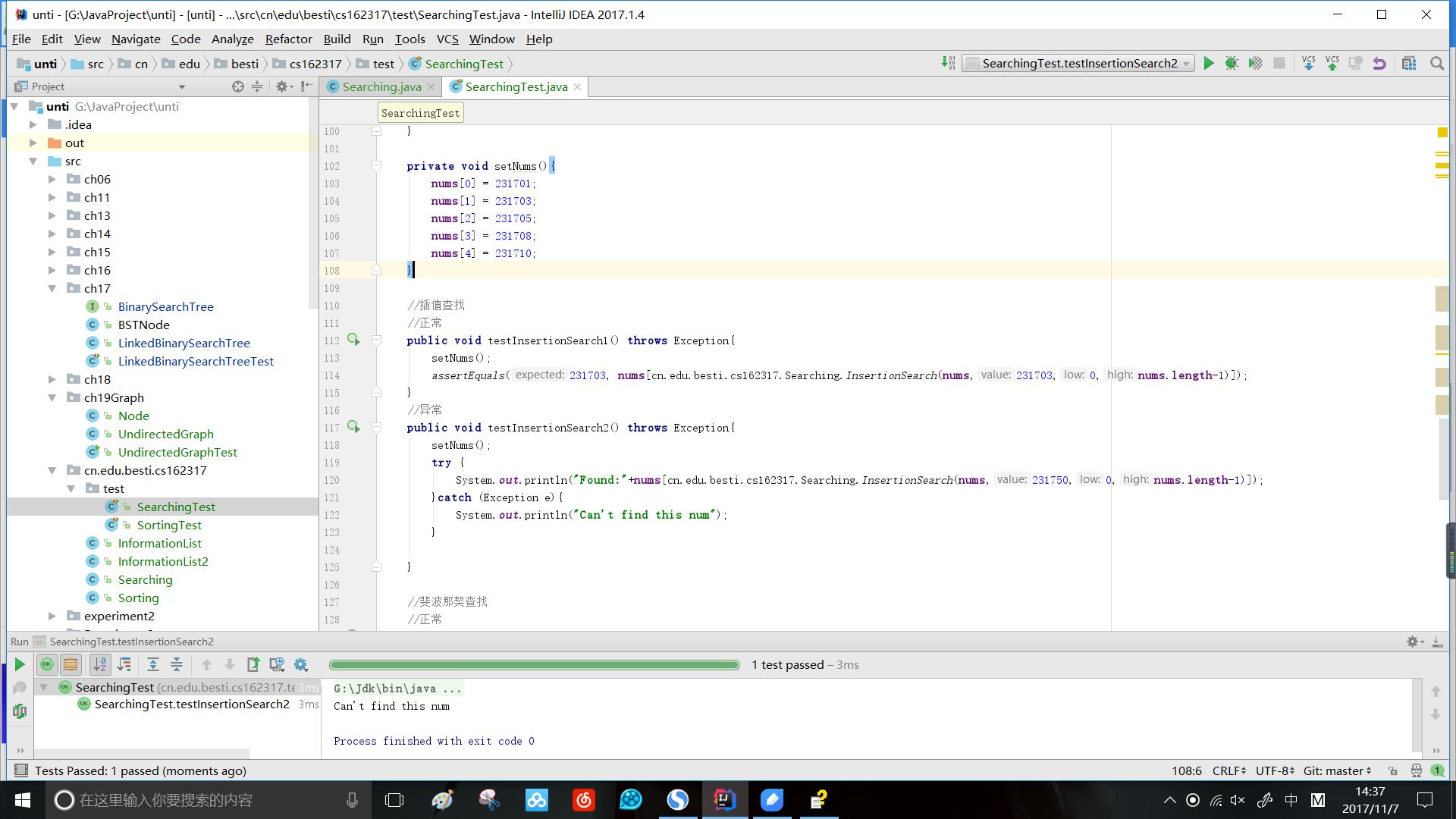
public static int InsertionSearch(int [] data,int value,int low, int high){
int result=0;
int mid = low+(value-data[low])/(data[high]-data[low])*(high-low);
if(data[mid]==value){
result=mid;
}
if(data[mid]>value){
result= InsertionSearch(data,value,low,mid-1);
}
if(data[mid]<value){
result= InsertionSearch(data,value,mid+1,high);
}
return result;
}
效果:
局限性:
说过,这种查找是二分查找的高级版,所以查找的数据要是有序的,无序的话会导致查找失败。
时间复杂度:查找成功或者失败的时间复杂度均为O(log2(log2n))。
二、斐波那契查找
斐波那契查找法也是二分查找的一种提升,运用了黄金比例的概念[用到了斐波那契数列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….(从第三个数开始,后边每一个数都是前两个数的和)]来选择查找点。
流程:
- 创建斐波那契序列的数组,方便调用。
- 将包含索引目标(target)的长度扩充到某个斐波那契序列数组中的某一个数减一。
- 为何要是某个斐波那契序列数组中的某一个数减一而不是该数或加一??
假设当前数在斐波那契序列数组中的下标为k,斐波那契序列数组为f[],通过斐波那契序列的特性可以知道:f[k] -1 = (f[k-1]+f[k-2])-1 = f[k-1] - 1) + 1 + (f[k-2]-1)中间的1就是我们的查找点,因为在一种情况下,查找点只有一个,所以是1,这样也好用于递归,同时也可以得知,斐波那契的二分查找点为 min = low+(f[k-1]-1)。
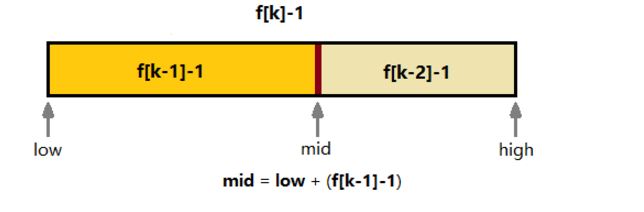
若是使数组长度为f[k]的话。已知f[k]=f[k-1]+f[k-2],虽说可以f[k]=(f[k-1]-1)+1+f[k-2]或f[k]=f[k-1]+1+(f[k-2]-1)但这有两种结构,不便于递归。
若是使数组长度为f[k]+1的话,已知f[k]+1 = (f[k-1]+f[k-2])+1,此时的1并不在中间,而是在最外面。
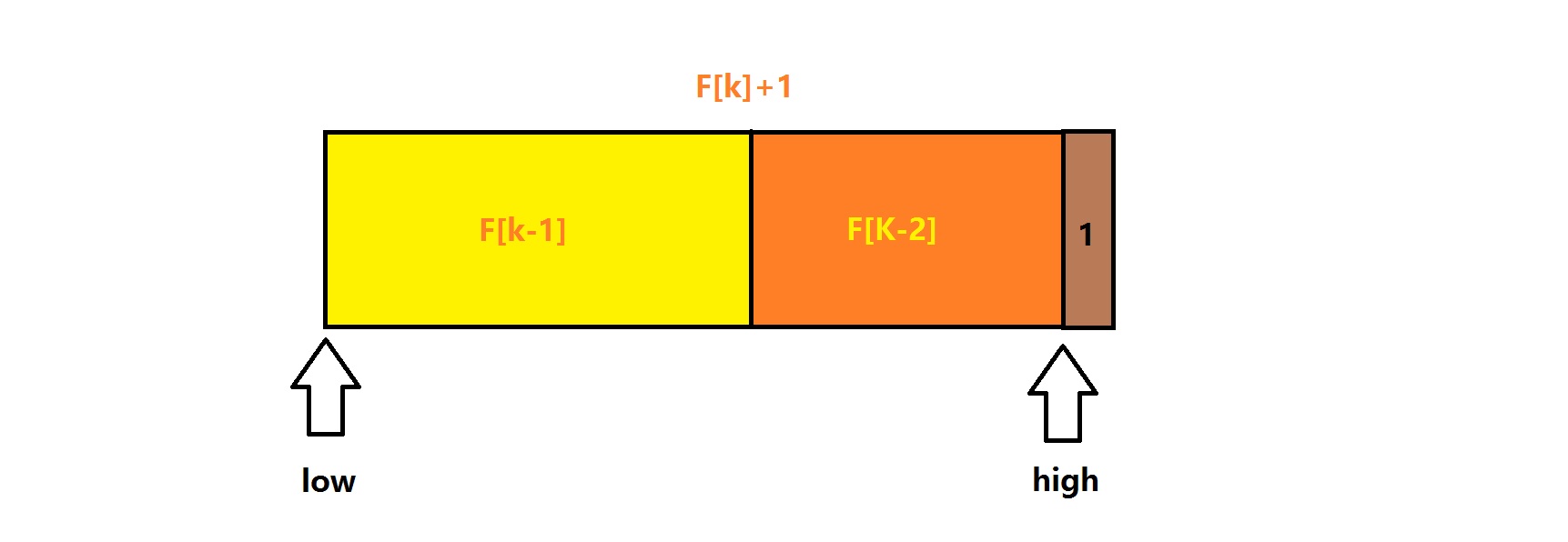
这样就不能获得查找点了。
二分查找中的查找点的取法:
mid=(low+high)/2
斐波那契中的查找点的取法:
mid=low+(f[k-1]-1)
实现代码:
public static String fibonacciSearch(int[] table,int keyWord){
String str="";
boolean judge= false;
//确定需要的斐波那契数
int i = 0;
while(getFibonacci(i)-1 == table.length){
i++;
}
//开始查找
int low = 0;
int height = table.length-1;
while(low<=height){
int mid = low + getFibonacci(i-1);
if(table[mid] == keyWord){
judge = true;
break;
}else if(table[mid]>keyWord){
height = mid-1;
i--;
}else if(table[mid]<keyWord){
low = mid+1;
i-=2;
}
}
if (judge){
str ="关键字为:"+keyWord+",查询结果为:"+keyWord;
}else {
str = "找不到该目标";
}
return str;
}
/**
* 得到第n个斐波那契数
* @return
*/
private static int getFibonacci(int n){
int res = 0;
if(n == 0){
res = 0;
}else if(n == 1){
res = 1;
}else{
int first = 0;
int second = 1;
for(int i = 2;i<=n;i++){
res = first+second;
first = second;
second = res;
}
}
return res;
}
效果:
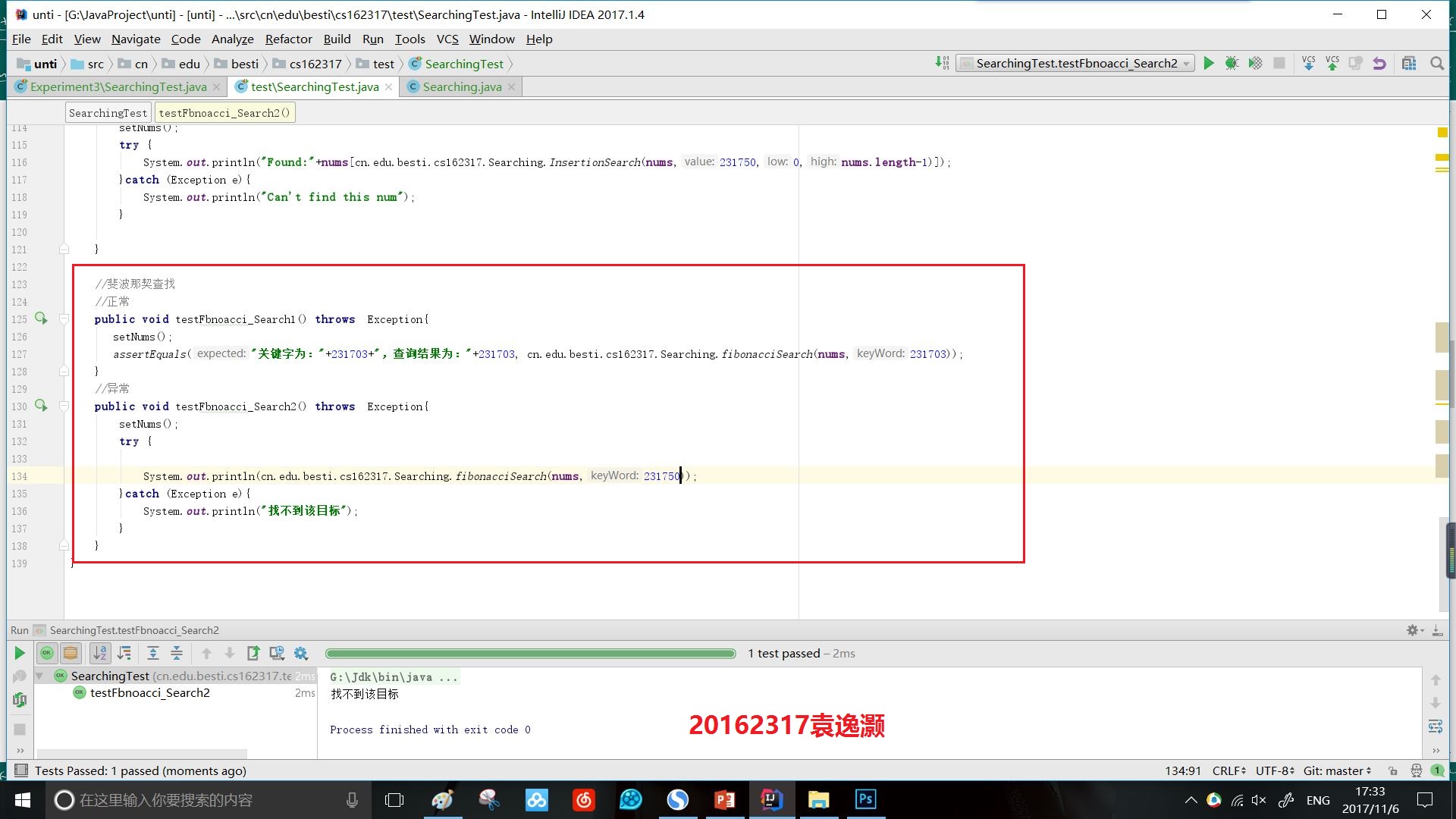
时间复杂度: 最坏情况下,时间复杂度为O(log2n),且其期望复杂度也为O(log2n)
局限性:
只能对有序序列进行查找。
三、树表查找
先将数据构建成一棵二叉查找树,然后直接调用二叉查找树的find方法即可。
//二叉查找算法
public static int binaryTreeSearch(LinkedBinarySearchTree tree,Comparable<Integer> target){
return (int) tree.find(target);
}
效果:
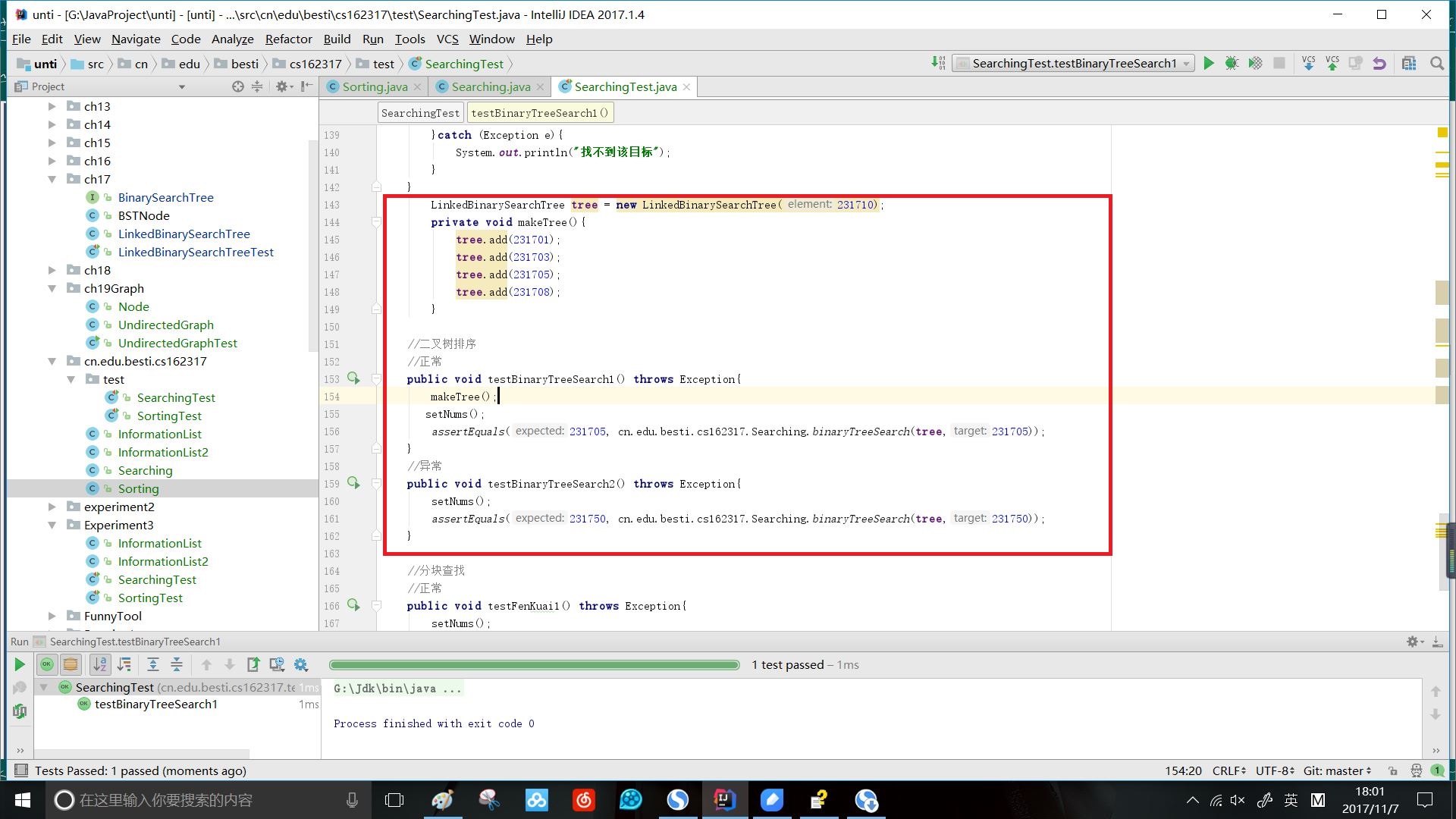
时间复杂度: 插入和查找的时间复杂度均为O(logn),但是在最坏的情况下仍然会有O(n)的时间复杂度
缺点:数据插入次序不对导致退化树的出现会大大减慢查找效率。
四、分块查找
分块查找是将数据分成若干块,每块数据可以不为有序,但块与块间要有序。如第二块的最小值要大于第一块的最大值。然后将每块中的最大值提出来做索引,并将每一块的第一个数据的下标记录下来。索引目标(target)与每一块的最大值做比较,若小于说明该索引目标位于当前最大值的块中,然后再用线性查找在对应块中查找出来。
如图:
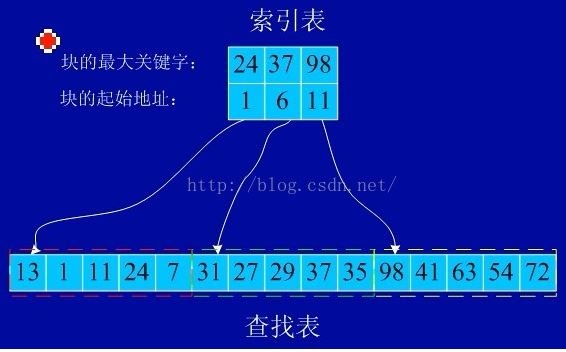
实现代码
//分块查找
//索引表
static List<Integer> index = new ArrayList<>();
static List<Integer> position = new ArrayList<>();
//以2个为一块
public static void Block(int[] num,int target,int part) {
// 存放数组中的最大值
int time=0;
if ((num.length/part-1)==0){
time =1;
}else {
time=num.length/part-1;
}
if(part<num.length) {
int i = 0;
for (int times = 1; times <= part; times++) {
//分块步骤
int temp1 = 0, temp2 = 0;
//如果是最后一次...
if (times == part) {
for (; i < num.length - 1; i++) {
if (num[i + 1] > num[i]) {
temp1 = num[i + 1];
} else {
temp1 = num[i];
}
if (temp1 > temp2) {
temp2 = temp1;
}
}
position.add(i - time);
} else {
//正常情况3个为一部分
for (int index = 0; index < time; index++, i++) {
if (num[i + 1] > num[i]) {
temp1 = num[i + 1];
} else {
temp1 = num[i];
}
if (temp1 > temp2) {
temp2 = temp1;
}
}
position.add(i - time);
}
index.add(temp2);
i++;
}
//查找步骤
boolean judge = false;
for (int s = 0; s < index.size(); s++) {
if (judge) {
break;
}
if (target <= index.get(s)) {
for (int o = position.get(s); o < num.length; o++) {
if (target == num[o]) {
System.out.println("目标为:" + target + " 目标已找到,在数组的第" + o + "个位置");
break;
} else {
if (o == num.length - 1) {
System.out.println("目标为:" + target + " 目标无法找到...");
}
}
judge = true;
}
}
}
}else {
System.out.println("你不能分成那么多块!");
}
}
效果:
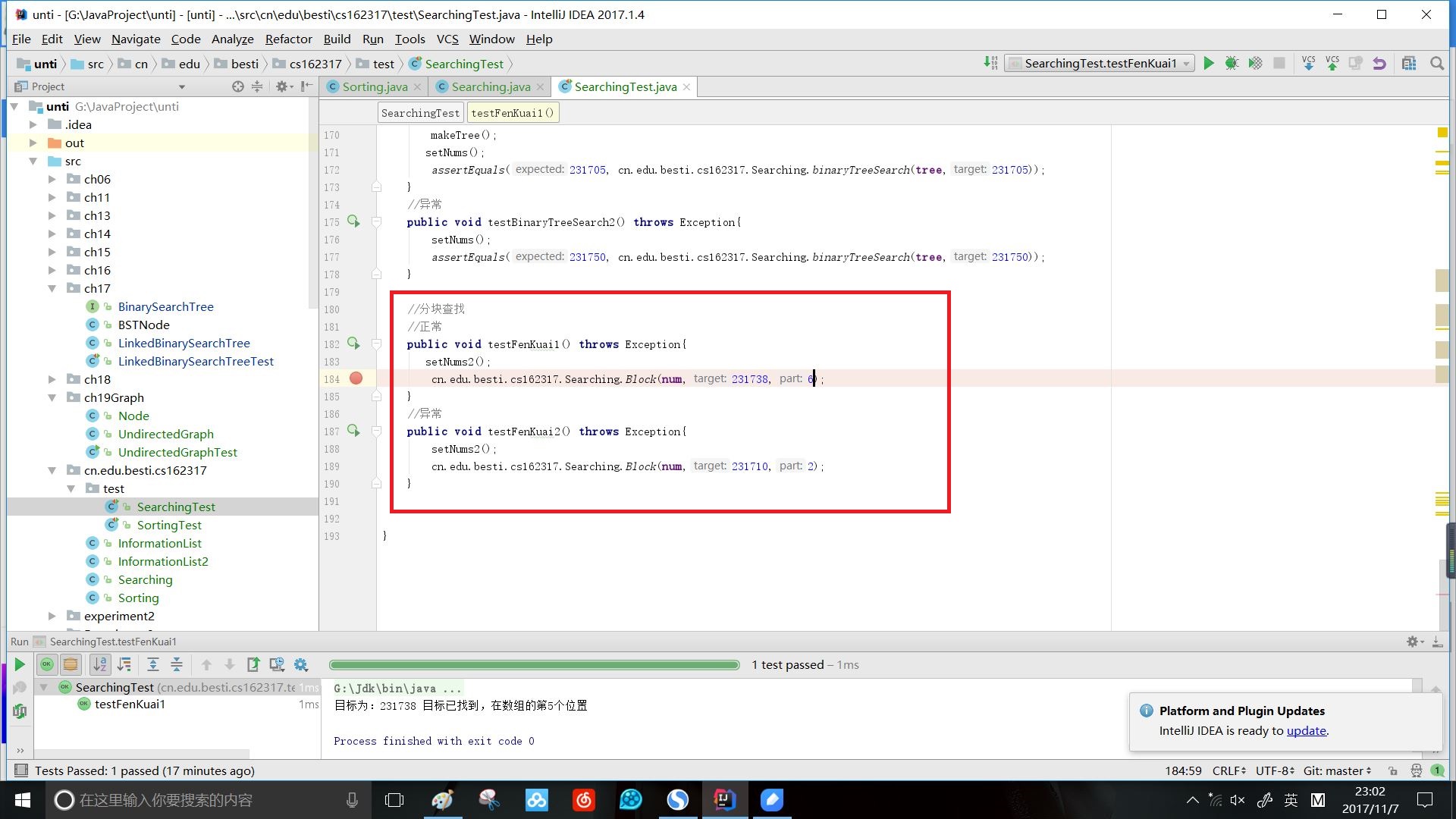
时间复杂度:O(n)~O(log2n)
优点:适用范围大;查找效率高
缺点:需要将待查表分块排序,并且要增加一个存储空间用来存储索引表
五、哈希查找
哈希查找首先是让数据通过某种方式(除法方法、折叠方法、平方取中方法等)来构建哈希函数,从而得到每个数据在哈希表中的下标。同时要考虑冲突(两个元素或关键字映射到表中同一个位置的情形)问题,通过解决冲突(链式方法、开放地址方法)的方式来对方式进行处理,然后将数据传入哈希表中。查找的时候目标通过同一方式来获得目标在哈希表中的下标位置,同时也要留意会不会该目标在哈希表中存在冲突的情况。
实现代码:
//哈希查找
/*
* 在哈希表中查找目标索引(target)
* 已经添加好数据的哈希表
* 哈希规则
* 目标
*/
public static void searchHash(int[]hash,int rule,int target){
//用除法方法得到目标的哈希函数
int targetPostion = target % rule;
//若查找的数据属于冲突...
while (hash[targetPostion]!=0&&hash[targetPostion]!=target){
//...开放寻址法
targetPostion = (targetPostion++) % rule;
}
if(hash[targetPostion]==0||hash[targetPostion]!=target){
System.out.println("查找失败,不存在该数");
}else if (hash[targetPostion]!=0&&hash[targetPostion]==target){
System.out.println("查找目标为:"+target+",查找成功,位于哈希表中第"+targetPostion+"位");
}
}
/*
* 将数据插入哈希表
* 哈希表
* 哈希函数规则
* 数据
*/
public static void insertHash(int[] hash,int rule,int data){
//用除法方法来获取数据在哈希表中的存储位置
int position = data % rule;
//若存在冲突,选择冲突解决办法:此处用开放寻址法
while (hash[position]!=0){
position = (position++) % rule;
}
//若不存在冲突,将数据传入哈希表中
hash[position] = data;
}
效果:
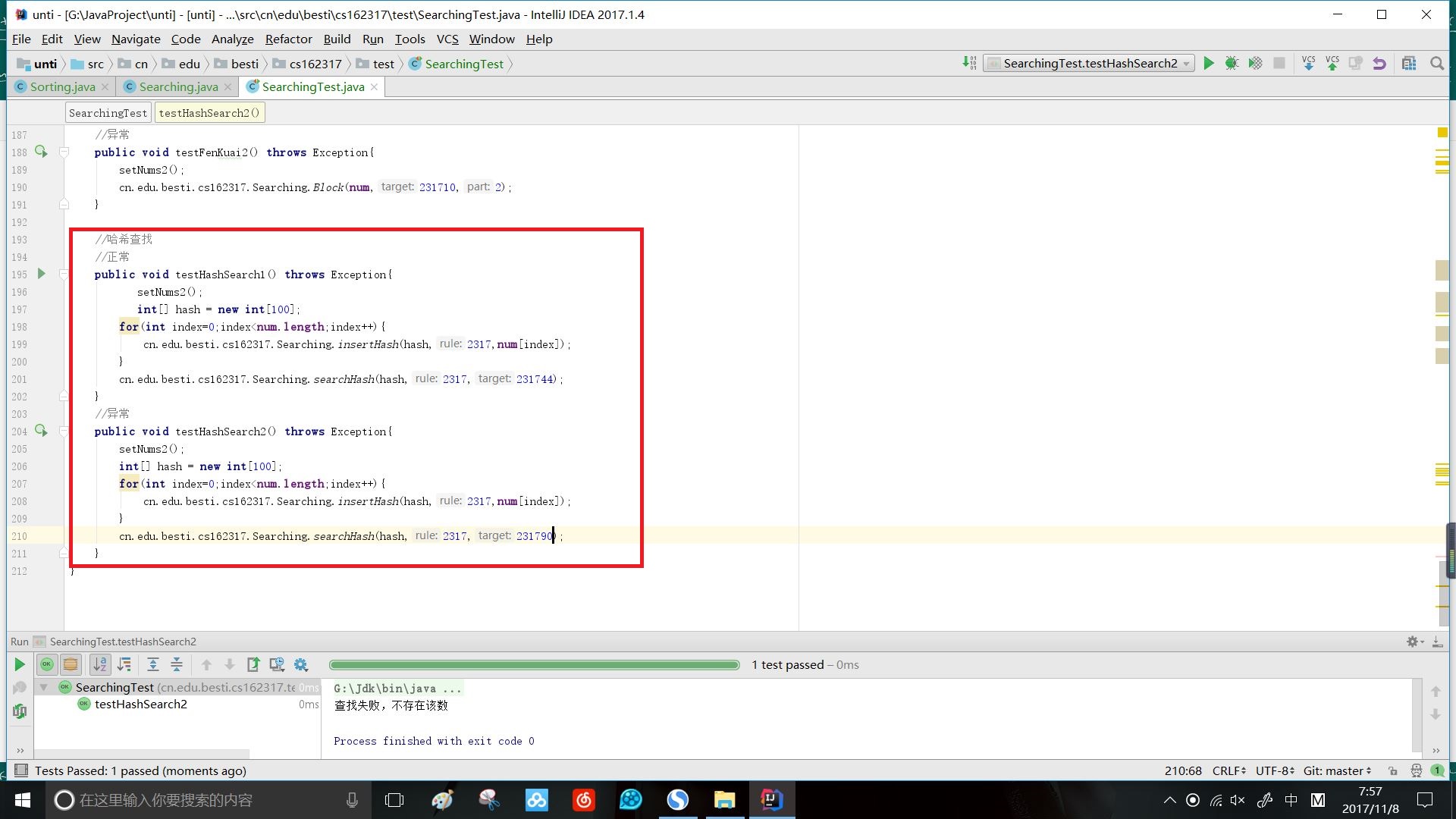
- 实验3.4
一、希尔排序
二、堆排序
三、桶排序
四、二叉树排序
.
一、希尔排序
希尔排序是将一个长的数组分割成k个短的序列,将每个短序列进行排序,使其成为有序的短序列。每次分割的组数要减少而每组中包含数据的数量要增加。最后得到跨度为1,即完整的序列,再用一次插入排序即可。
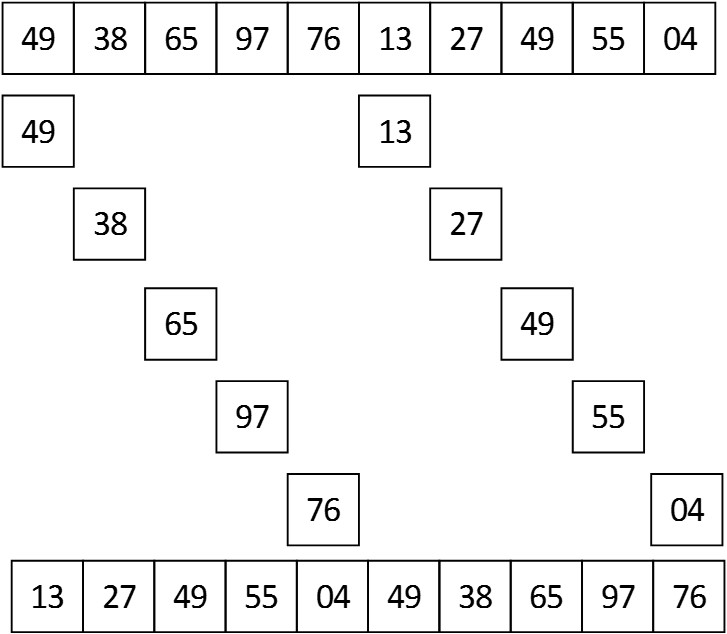
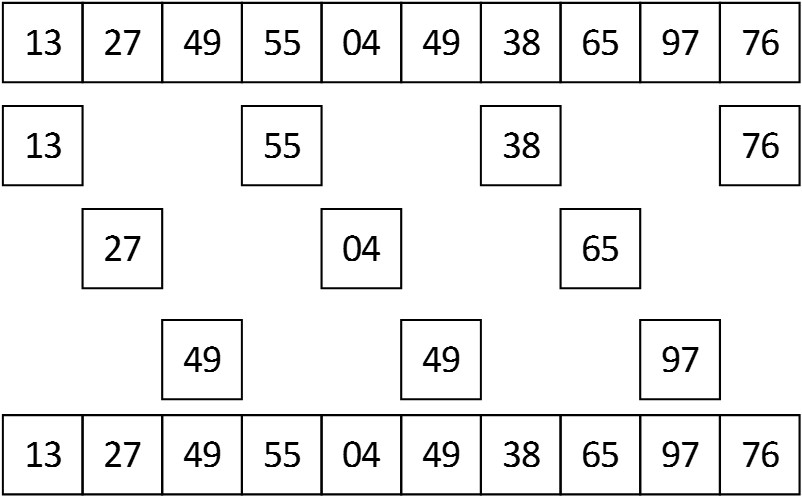
分割的方法是:
若数组num长度为偶数,分割次数times(即分割出来的组数)为num.length/2,若为奇数,则分割次数为num.length/2+1。每组包含数据的数量nums初始为2,跨度gap为num.length/2,每分割完一次后times = times-2,nums = nums + 2,gap = gap - 2直到gap<1为止。
实现代码:
public static void shellSort1(int[] num){
//获得最大间隔
int gap=num.length/2;
//次数
int time=0;
//从数组中获得的个数
int nums = 2;
//存放数字
List<Integer> numList = new ArrayList();
//存放下标
List<Integer> positionList = new ArrayList();
if (num.length%2==0) {
time = num.length / 2;
}else {
time = num.length/2+1;
}
//排序
while (gap>=1) {
//获得多少组
for (int times = 1,index=0; times <= time; times++,index++) {
//每组多少个
//用一变量temp来承载当前index
int temp = index;
for (int i=1;i<=nums;i++){
//将当前数加入数据列表中,用来排序
numList.add(num[temp]);
//将当前下标加入到下标列表中
positionList.add(temp);
temp = temp+gap;
if(temp>num.length-1){
break;
}
}
//对数据列表进行排序
insertionSort2(numList);
while (!positionList.isEmpty()){
num[positionList.remove(0)] = numList.remove(0);
}
}
gap = gap-2;
nums = nums+2;
time = time-2;
}
bubbleSort1(num);
}
最后的冒泡排序是为了捡漏,虽然这和开始直接用插入或冒泡排序等形式相同,但效率不一样。
Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。
效果:
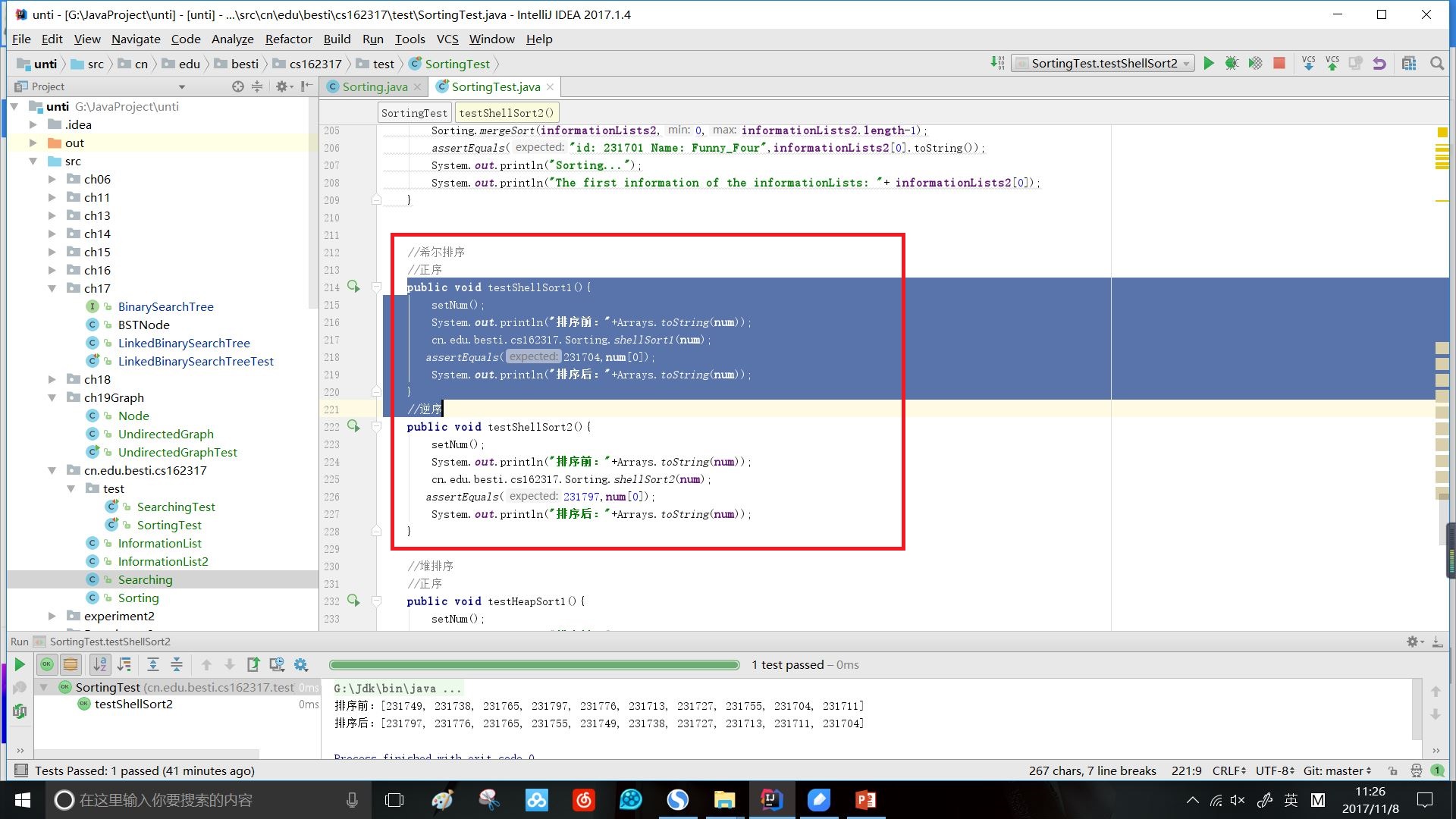
时间复杂度:最坏为O(nlogn),最好为O(1)
二、堆排序
堆排序的思路很简单:由堆的性质可以知道,最大堆的所有非叶结点的结点都大于其子结点。因此可以每次将堆的堆顶记录输出;同时调整剩余的记录,使他们重新排成一个堆。重复以上过程,就能最终得到一个有序的序列。由于18章中有做堆排序的要求,因此直接引用。
效果:
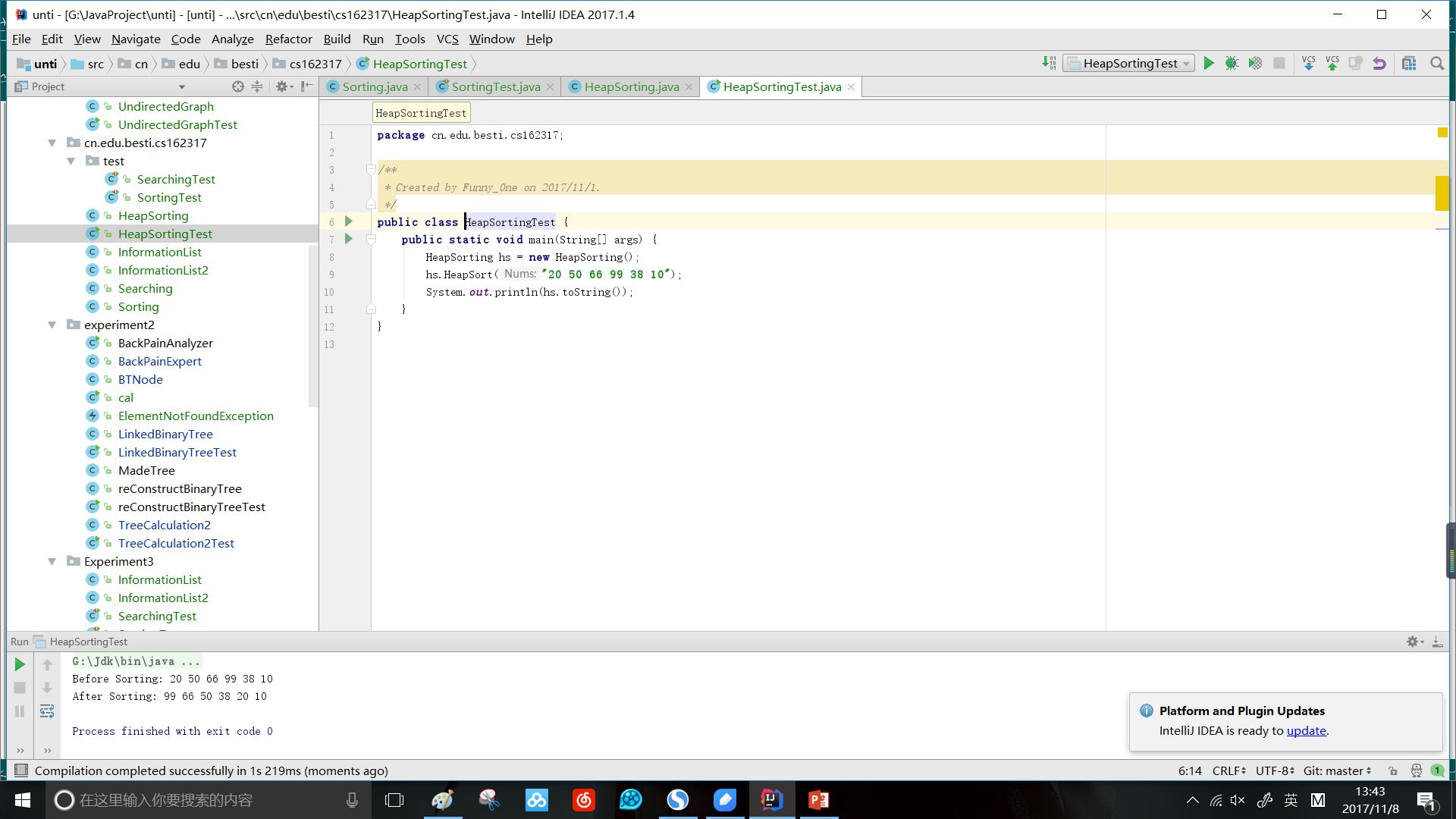
堆排序适合于数据量非常大的场合,例如到达了百万数据量。
这是逆序的情况,要正序只要构键一个最小堆即可。
时间复杂度:最坏情况O(nlogn),最好情况O(1)
三、桶排序
桶排序是一种利用空间换取时间的排序策略,理论上采用与序列记录一样数目的桶,就可以达到线性的时间复杂度。。
实现代码:
//桶排序
public static void bucketSort1(int[] arr){
int n=0;
int temp1=0,temp2=0;
//找到数组中的最大值
for (int index=0;index<arr.length;index++){
if (index!=arr.length-1){
if(arr[index+1]>arr[index]){
temp1 = arr[index+1];
}else {
temp1 = arr[index];
}
}
if(temp1>temp2){
temp2 = temp1;
}
}
//设n为桶的最大数量
n = (temp2 /10)+1;
List[] bucket = new List[n];
for (int index=0;index<bucket.length;index++){
//桶
List<Integer> a = new ArrayList<>();
bucket[index] = a;
}
//遍历目标数组
for (int index=0;index<arr.length;index++){
//获取对应桶下标
int bucketposition = arr[index]/10;
//将数据加入对应桶下标的桶中
bucket[bucketposition].add(arr[index]);
}
int i=0;
String result= "排序后:";
//添加完后再对桶堆里的每个桶列表进行排序并将每个桶输出
for(int index=0;index<bucket.length;index++){
insertionSort2(bucket[index]);
while (!bucket[index].isEmpty()){
arr[i] = (int) bucket[index].get(0);
result+=bucket[index].remove(0)+",";
i++;
}
}
System.out.println(result);
}
效果:
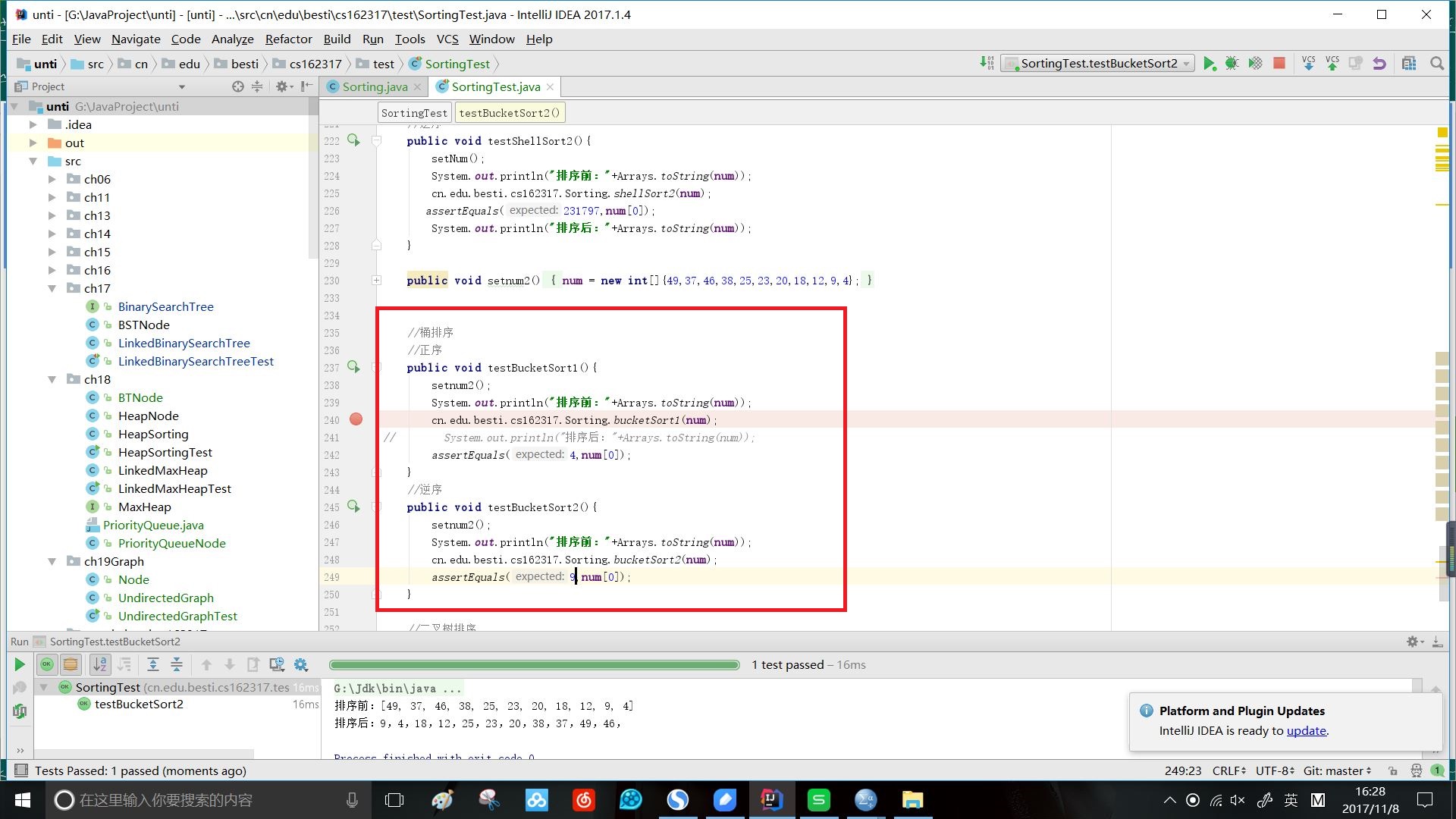
时间复杂度:最坏情况O(n^2),最好情况O(n)
四、二叉树排序
二叉树排序比较简单,在一棵二叉查找树中:
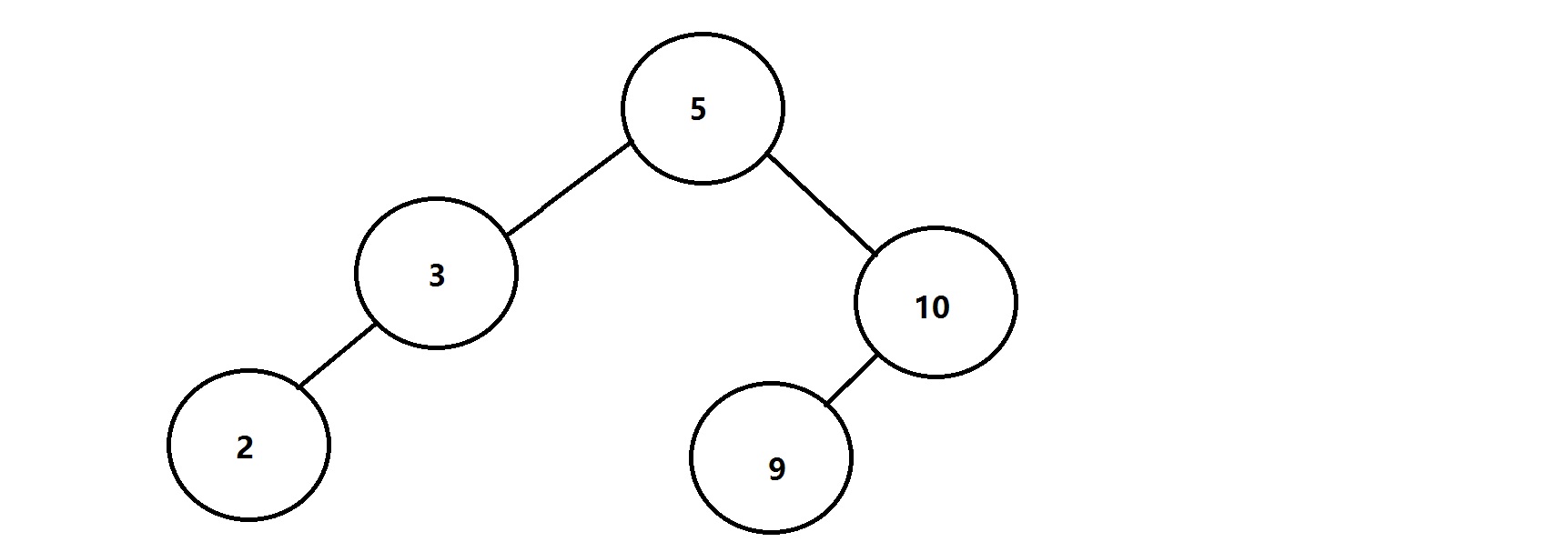
中序遍历为:2 3 5 9 10
已经排好了顺序,因此二叉树排序只要中序遍历即可。
效果:
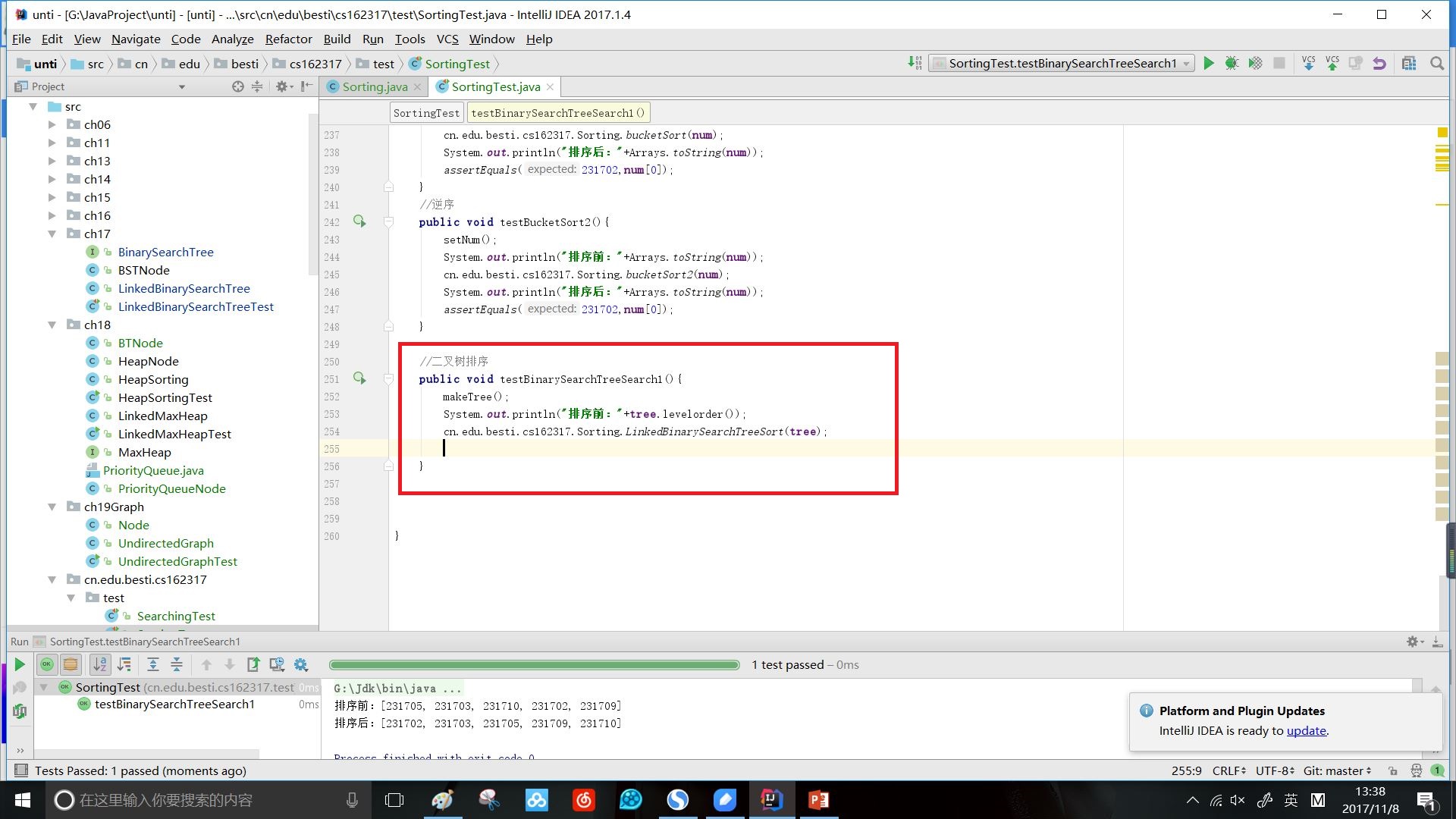
时间复杂度:最坏情况O(n^2),最好情况O(n)
实验知识点
- 线性查找
- 二分查找
- 哈希方法
- 二叉查找树
- 堆
