
在以前我做开发的时候,经常会遇到需要向数据库中添加假数据的需求,有时又需要使用批量的随机数据来验证接口或是方法的稳定性以及容错测验。那个时候我还不知道有类似于 jmockdata 或是 easy-random 的数据生成工具,就只有傻傻地用姓名库和for循环来构造数据。
后来我知道了 jmockdata,也用过 easy-random,不过使用体验并不是很好。例如 jmock 会复用对象导致循环引用时无法转json, easy-random 构造自定义数据有点麻烦,总的来说它们和我预想的构建模式并不是很相符。我还是期望那种更加自由的、能凭直觉就定义数据构建方法的构建工具,比如 weight 和 height 能使用不同的随机方式,而不只是简单的范围随机。
而mock-data就实现了我的想法。例如实现基础的数据构建,就像下面这样:
MockDataCreator creator = new MockDataCreator();
// 就像new Random.next一样,随机基础类型的数据
int i = creator.mock(int.class);
// 随机包装类型
int inte = creator.mock(Integer.class);
// 随机数组
int[] ints = creator.mock(int[].class);
// 指定数组大小
int[][] intsArray = creator.mock(new int[2][3]);
// 随机日期
Date date = creator.mock(Date.class);
不过这也是最基本的,构建自定义对象才是重点,毕竟这是用来做自定义数据的。我个人觉得这样的方式还是比较符合直觉的:
MockDataCreator creator = new MockDataCreator();
creator.getConfig()
// 开启级联构建并对默认值进行替换
.autoCascade(true).forceNew(true)
// 设定weight的范围
.fieldValue(Person::getWeight, new DoubleRandomCreator(3D, 200D))
// 设定height的范围
.fieldValue(Person::getHeight, new DoubleRandomCreator(10D, 260D))
// 如果需要,也可以设定其他double类型的默认范围
.fieldValue(double.class, new DoubleRandomCreator(0D, 1000D));
// 开始构建
Person person = creator.mock(Person.class);
其中的DoubleRandomCreator实际上是实现的DataCreator接口,开发者可以通过实现这个接口来自定义构建方式:
public interface DataCreator<R> extends TypeGetter {
/**
* 生成数据
*
* @param src 构建源信息。当此构造器绑定的类是通过{@link MockDataCreator#mock(Class)}的方式传入时,field为空。<br>
* 例如此构造器绑定Person对象,而此时通过MockDataCreator.mock(Person.class)方式进入此构造器时,field对象为空。但其内部可能存在的Person则不会为空。<br>
* 也就是说,只有在{@link MockDataCreator#mock(Class)}传入的类与此构造器绑定类相同时,返回的目标对象在构造时传入的field为空。
* @param creator 当前所使用的数据创建器。
* @return 生成的数据
*/
R mock(MockSrc src, MockDataCreator.Creator creator);
/**
* 构建器匹配的类型列表,如果有特殊需求可以自己重写方法,在列表中放入匹配的类。这样构建匹配的类时就会调用这个构建器来构建
*/
@Override
default List<Class<?>> types() {
List<Class<?>> list = new ArrayList<>();
try {
Method method = this.getClass().getMethod("mock", MockSrc.class, MockDataCreator.Creator.class);
Class<?> type = method.getReturnType();
list.add(type);
} catch (NoSuchMethodException ignored) {
}
return list;
}
}
所以实际上就只需要实现一个方法就可以了,MockSrc里面包括了目前的构建目标信息,便于开发者进行选择构建。mock-data 也为接口构建提供了接口构建器,让MockDataCreator可以自动选择合适的实现类来完成接口的构造工作,内置的List、Set和Map就是使用的接口构建器,这样所有实现这三个接口的类(例如ArrayList、HashSet、HashMap等)都可以自动构建对应的对象,而不需要对它们重新设置。
当然,循环依赖生成的是独立对象,并且可以自定义每个类的循环深度。不过这些都是比较基础的功能,还不能达到我心中的便捷,毕竟如果需要构建出一个假的“真实”数据,开发者还是需要自己去设定每一个属性或是类的构建模型。虽然也可以通过结合 JavaFaker 的方式解决,但不够优雅,所以在 mock-data 在3.0版本加入了属性数据池模型,开发者只需要构建一个属性数据池,就可以让MockDataCreator优先使用数据池中的数据。这样做似乎与 JavaFaker 很相似?并不是,属性数据池包括了三个目标: 类型(Class)、属性名(支持正则匹配)、数据池(数据对象数组)。类型 与 属性名 用来指定 数据池 的适用目标。使用方式就像下面这样:
MockDataCreator creator = new MockDataCreator();
FieldDataPool dataPool = new FieldDataPool()
// 自动识别同类型属性,包括int类型的所有名称中包含age的属性,忽略大小写,例如age、nominalAge
.like(Person::getAge, 23, 24, 25, 26, 27)
.next()
// 添加FRUIT类的数据池,则会对所有的FRUIT类进行数据池选取,忽略名称
.type(Person.FRUIT.class)
.values(Person.FRUIT.APPLE)
.next()
// 对Date类的所有名称中能匹配`.*day`和`.*time`的属性进行数据池选取
.type(Date.class)
.values(new Date[]{new Date()}, ".*day", ".*time").next();
// 设置属性数据池
creator.fieldDataPool(dataPool);
// 开始构建
Person person = creator.mock(Person.class);
这样似乎也不优雅?确实,所以 mock-data 实际上是提供了一个数据池框架,开发者完全可以通过继承FieldDataPool来构建配置文件填充的数据池。并且在 mock-data 的test包中其实也实现了一个properties的数据池,只需要把数据池信息写在properties中就可以控制数据池填充了,就像这样:
int#age=[22, 23, 24, 25, 25, 27]
int#nominalAge=[23, 24, 25, 25, 27, 28]
double#height=[120, 130, 140, 150, 160, 170, 180, 190, 200]
double#weight=[40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160]
String#name=["假装这个名字", "这么长的姓名"]
String#nickname=["小明", "小红", "小张", "小丽"]
java.util.Date#birthday=["1998-01-08", "1998-03-08", "1998-05-08", "1998-07-08"]
详细内容可以看 这里。
也就是说,mock-data 集成了完善的虚拟数据构建模型,并且泛型的兼容性与性能也还不错,具体可以看下下面的图片:
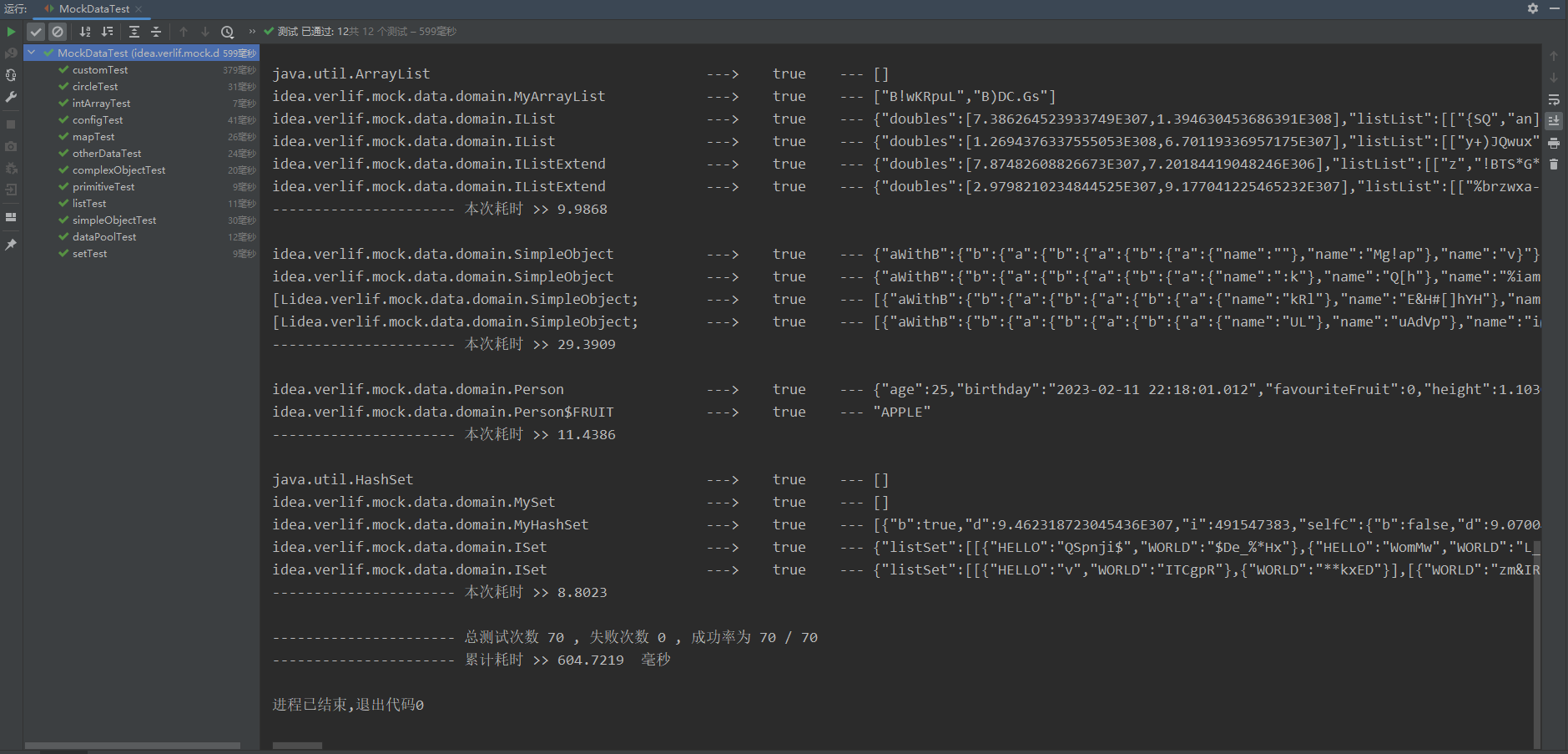
具体的测试内容可以把代码 clone 下来,在test包下查看。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号