
Bash Commands and Shell Scripts
为了考试准备一下吧
这门课对这个领域的知识教的太浅,考的却很难,必须要额外自学一点东西
Variables in Shell Scripts
首先是 Shell Scripts 中的变量概念: Shell Scripts 中的 变量只有一种类型 string
Define variable in shell scripts
对于一个变量赋值语句 a=xxx,xxx 必须是字符串 string
-
xxx是单引号括起来的a='hello': 单引号中的内容不支持 variable substitution -
xxx是双引号括起来的a="$b": 双引号中的内容支持 variable substitution -
xxx是反引号括起来的反引号
` `与$()符号的作用一致
反引号中的内容是 bash command: 注意,所有 bash command 的 output 都是 string
Access variable in shell scripts
使用符号 $ 来访问变量
$a 可以视为将变量 a 中的字符串展开,即 variable substitution
Text Processing Command: grep, sed, awk and tr
文本处理一直是 shell script 出题的大头,这里学习一下几个常用的文本处理命令
grep
grep 是 按行 对文本处理的一个重要命令
grep the line with specific string
用法一:grep 'foo' bar.txt
最朴素的 grep 用法,在 bar.txt 文件里查找所有包括 string foo 的行并打印这些行
grep the line with specific pattern
用法二:grep -E 'fooPATTERN' bar.txt
有时候我们需要查找符合某个 模式 (Pattern) 的字符串,模式用 正则表达式 (regex, regular expression) 进行表示
加上 flag -E 后,grep 能够找到所有能够匹配 pattern fooPATTERN 的行并输出
grep : flags
这里介绍一些常用的修饰 grep 的 flags:
-
-v(--invert-match)加上 flag
-v后,grep 将会输出所有不匹配的行: 例如这个命令grep -E -v '^$' bar.txt代表输出 bar.txt 中所有非空行的行由于正则表达式
^$代表一个空行,所以 grep 将会匹配上 bar.txt 中所有的空行;然而在 flag-v的作用下,grep 将会输出所有未匹配的行,即非空行 -
-o(--only-matching)加上 flag
-o后,grep 将只输出与模式 fooPATTERN 匹配的部分,一次匹配占一行,例如命令grep -E -o '[a-zA-Z]' bar.txt代表输出 bar.txt 中所有的字母,一个字母占一行(加上 flag
-o后,grep 可以视作 对整个文本处理而不是按行进行处理,因为它将输出所有匹配的模式,与行无关) -
-c(--count)加上 flag
-c后,grep 将只输出匹配的行数(因此这个 flag 可以与
-v复合:-vc输出不匹配的行数) -
-n(--line-number)加上 flag
-n后,grep 还将输出匹配行的行号 (加在匹配行之前,格式为 lineNumber:matchingLine)(同样,
-n也能与-v复合,在输出不匹配行的同时输出不匹配行的行号)
sed
接下来是 sed 命令,sed 实际上是 linux 里一个带有 interface 的文本编辑器
以命令行的形式对 sed 进行调用即是 sed 命令,sed 也是 按行 对文本进行操作的,其可以实现文本的行插入,删除与替换
其基础语法是 sed '[script]' bar.txt
这里,script 的语法其实和 diff 命令后显示的行的增删情况很相似
add a line (a/i)
在 bar.txt 的第二行后添加新一行文本 "Joker": sed '2aJoker' bar.txt
在 bar.txt 的第三行前添加新一行文本 "Skull": sed '3iSkull' bar.txt
delete lines (d)
删除 bar.txt 的第二行: sed '2d' bar.txt
删除 bar.txt 的第一到第三行: sed '1,3d' bar.txt
删除 bar.txt 的第三到最后一行: (使用 $ 符号): sed '3,$d' bar.txt
show lines (p)
显示 bar.txt 的第二到第五行: sed -n '2,5p' bar.txt (注意一定要加 flag -n)
change lines (c)
将 bar.txt 的第二到第五行修改为 "mona": sed '2,5cmona' bar.txt
(相当于先将第二至五行删除,再在新的第二行前添加一行 "mona")
search data
接下来是 sed 命令的高阶用法,script 语法变得更加复杂: 不同的成分之间将用 / 进行分隔
并且,script 是支持正则表达式的,可以用正则表达式而不是纯字符串来匹配模式
找到 bar.txt 所有包含 "oo" 的行:sed -n '/oo/p' bar.txt (这与 grep "oo" bar.txt 的作用相同)
找到 bar.txt 所有不包含 "oo" 的行 (即删除所有包含 "oo" 的行并输出剩余的部分): sed '/oo/d' bar.txt (这与 grep -v "oo" bar.txt 的作用相同)
将 bar.txt 中所有包含 "oo" 的行中第一次出现的 "oo" 修改成 "kk": sed 's/oo/kk/' bar.txt
只替换每行中第一次出现的字串显然不具有很大的应用价值,我们加上标识符 g 来将所有 "oo" 替换成 "kk": sed 's/oo/kk/g' bar.txt
awk
awk 实际上也是一种文本编辑语言,语法上和 C 很类似,因此比 shell script 还容易理解
正因为如此,我们能在 awk 命令中执行 awk 语言的脚本,这使其能完成很复杂的文本格式化功能
根据未老师的介绍,sed 命令倾向于将一行看作一个整体修改,而 awk 则倾向于将一行看作很多字段的集合 (类似于表格)
awk 的基础语法是 awk '[awk script]' bar.txt
这里介绍 awk 最基础的一个用法,即 awk script 呈现 condition {action} 的语法结构
-
输出 bar.txt 中所有字段数等于 \(3\) 的行 (分隔符为空格或制表符):
awk 'NF==3' bar.txt(实际上是awk 'NF==3 {print $0}' bar.txt的简写) -
输出 bar.txt 中所有字段数等于 \(3\) 的行 (分隔符为逗号
,):awk -F',' 'NF==3' bar.txt -
输出 bar.txt 中所有字段数等于 \(3\) 的行中的第一与第三个字段 (分隔符为空格或制表符):
awk 'NF==3 {print $1, $3}'
NF 是 awk 的内建变量,记录的是当前行的字段数,还有其他的内建变量,例如:FS (字段分隔符,默认为任何 blank 字符), length (当前行的长度), NR (当前行的行号)
另外,我们甚至能在 awk script 用 awk 语言编写程序 (和 C 语法极其相似),来完成一系列复杂的文本格式化
Eg. 1
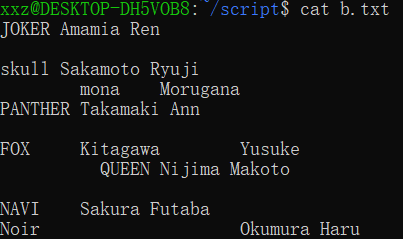
对于这一系列杂乱的字段,我们想将其整理成一行中每两个字段间只保留一个空格作为分隔符
这一过程用 C 语言来实现可以说非常简单,但是 shell script 中我一时半会真的想不出来
此时,我们直接使用 awk 命令作为 shell 与 C 语言的桥梁: awk 'NF!=0 {{for (i=1; i < NF; ++i) printf "%s ", $i} print $NF}' b.txt
是不是一下变得简单多了:我们先用 NF!=0 条件去掉空行,再进行 {} 中的 action 阶段: 这里就几乎全是 C 语言的语法了
效果如下:

Eg. 2
这是期中 Quiz 的一个题目,当时没有接触过 sed, awk, tr 命令的我可以说是一筹莫展
在学会这些命令以后,这种题可以说是迎刃而解

(将被若干空格,制表符,换行符等 [:space:] 符号分隔的字段整理成一行一个的形式,并且进行去重)
一行 shell script 就可以解决: tr '[[:space:]]' '\n' < $1 | awk 'NF != 0 && !a[$0]++' (思路来自 zrz)
真的很妙,直接用 awk 语言定义了一个桶,对字段进行统计,这样就完成了去重 (注意,缺省的 action 默认是 print $0)
如果想要做的更绝点,可以只用一个 awk 命令 (虽然这样本质上就是用 C 来写而不是 shell script 了),即 awk '{for (i = 1;i <= NF; ++i) {{if (a[$i] == 0) print $i} a[$i]++}}' $1
总而言之,awk script 中可以包含这些内容: BEGIN{} (在文本处理前执行的 action), {} 逐行处理文本时执行的 action,END{} 处理完所有文本后执行的 action,而不在 {} 中的则是条件 condition (可缺省)
另外,awk 也能像 sed 一样通过字符串或正则表达式进行模式匹配,这里就不多展开了,有 grep 与 sed 完成模式匹配的相关操作已经足够了
tr
tr 命令的应用就比较简单粗暴了,其完成的是对指定文本/模式的替换,和 sed 's/.../.../g' file 的功能几乎一致 (sed 更强大,其不仅能转换字符,还能转换模式)
语法如下 tr '[SET1]' '[SET2]' < bar.txt,SET1 与 SET2 可以是字符集,也可以是字符串,但并不是模式!因此它不支持正则表达式描述的模式匹配,只能够匹配字符串或字符集
-
将 bar.txt 中所有的空白字符 (空格,制表符...) 全部转换为换行符:
tr '[[:blank:]]' '\n' < bar.txt -
将 bar.txt 中所有的小写字母转换为大写字母:
tr '[[:lower:]]' '[[:upper:]]' < bar.txt(注意,当 SET1 与 SET2 是一一对应的关系时,字符的转换才一一对应) -
删除 bar.txt 中的所有空字符 (空格,制表符,换行符...) 使其称为一条连续的字符串:
tr -d '[[:space:]]' < bar.txt(使用 flag-d进行删除) -
使 bar.txt 中所有连续的字母缩减成只有一个 (例如,"ooookay!" 缩减为 "okay!"):
tr -s '[[:alpha:]]' < bar.txt(使用 flag-s)

