

ENGG1340 Computer Programming II
课程内容笔记,自用,不涉及任何 assignment,exam 答案
Notes for self use, not included any assignments or exams
Module 0
主要介绍了几种远程登录 CS department 主机的方式
-
\(SSH\) (安全外壳协议, Secure shell)
先使用 SSH 登入gatekeeper服务器,再登入academy服务器
若使用 HKUVPN 可直接 SSH 登入 academy 服务器
SSH 连接在命令提示符中进行,因此只能通过指令交互,无 GUI (图形界面,Graphical User Interface) -
X2Go Client
-
\(SFTP\) (SSH 文件传输协议,SSH File Transfer Protocol)
与 SSH 相同,无法直接登入academy服务器且无 GUI
适合进行远端与近端的文件传输 -
FileZilla (一种 SFTP Client)
Module 1
-
Why Linux?
- 开源 (open-source software)
- 海量的软件开发工具 (software development tools)
- 免费
-
Using Linux Shell
Linux 中的 Shell 是一种基于文本的程序 (text-based program),其接受用户的指令并执行相应的任务 (类似 win 中的命令提示符 cmd)
本课程中使用的 Shell 为 Bash Shell
Shell commands:
- directory management

- file management

- a special use for cat command

- other useful commands
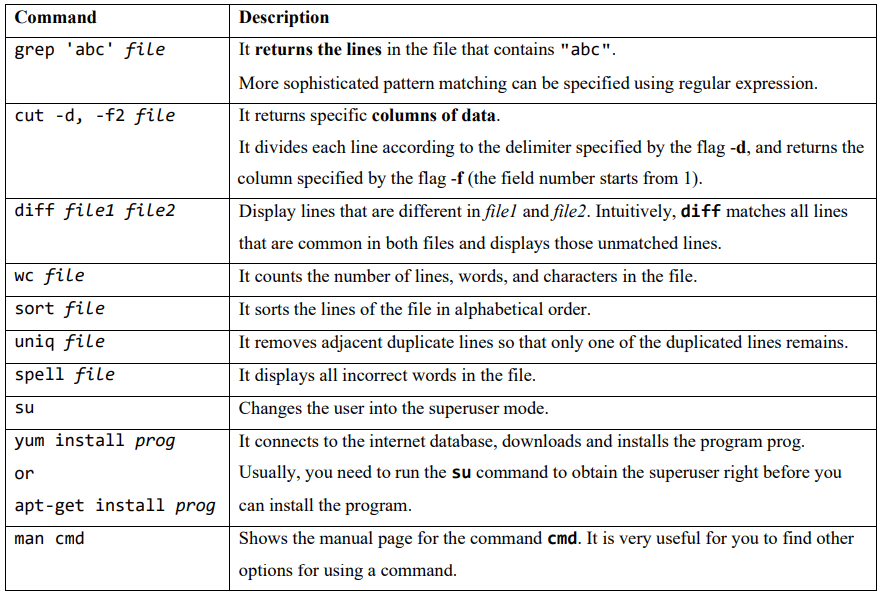
有关这些命令的 flag 以及详细用法查阅原 pdf
需要重点认识文件比较命令diff file1 file2的原理:它给出了一个将file1按行转化为file2的方案
Use of vi editor:
vi 编辑器是 unix/linux 系统中的一种基于命令行的文本编辑器 (command-line text editor),没有图形用户界面
在 shell 中使用 vi filename 来用 vi 编辑器打开文件 filename,如果没有这个名字的文件,vi 编辑器将会新建一个
vi 编辑器有两种模式:
- 插入模式 Insert mode: 编辑文本所用的模式,按 \(I\) 启用
- 命令模式 Command mode:执行命令所用的模式,按 \(Esc\) 启用。首次打开某个文件 vi 编辑器将会处于命令模式

File permission:
-
intro
Linux 系统中,每个文件与目录都被赋予了两个属性,所有者 (ownership) 与访问权限 (permission, or access rights)
所有者属性分为三种:- 用户 User:用户 User 是文件的所有者
- 组 Group:一个组 Group 包含很多用户,同组的用户对某文件的访问权限是相同的
- 其他用户 Other
对于每类所有者,文件与目录访问权限也分为三种:
- 读 Read:文件的可读权限意味着允许打开并浏览文件,目录的可读权限意味着允许浏览目录中的内容
- 写 Write:文件的可写权限意味着可以对一个文件进行修改,目录的可写权限意味着可以添加,删除或重命名目录中的文件
- 执行 Execute
-
display permission
使用ls -l命令可以显示文件或目录的 permission indicator
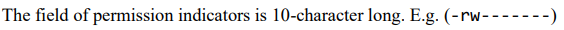

第一个字符 (\(-/d\)):\(-\) 代表文件 file,\(d\) 代表目录 directory
后九个字符分为三组,分别指示用户/组/其他用户的读/写/执行权限 -
change permission
使用命令chmod来改变文件/目录的权限,具体格式为chmod [who][operator][permissions] filename
[who]代表修改的所有者

[operator]代表改变的操作 (add/remove/set permission)
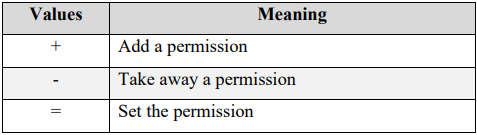
[permission]代表需要添加/去除的权限

下例描述了给文件file的 其他用户 (other) 添加 读写 (read & write) 权限的过程

Standard I/O, file redirection & Pipe
-
file descriptor
Shell 中的命令经常关联一些开放文件。我们使用 文件标识符 file descriptor 来标记这些文件的类型。具体来说

标准错误 (stderr) 文件用来储存命令执行失败弹出的错误信息 -
redirection operator
通常来讲,当我们执行命令的时候,输出会在屏幕上显示。我们可以使用 重定向符 redirection operator>将输出重定向至文件 file.txt 中
例如,我们想将命令ls -l的结果输出至文件 file.txt 中,可以如下例使用重定向符



以下是几个重定向符>,>>,<, 与<<的含义与它们的常见用法
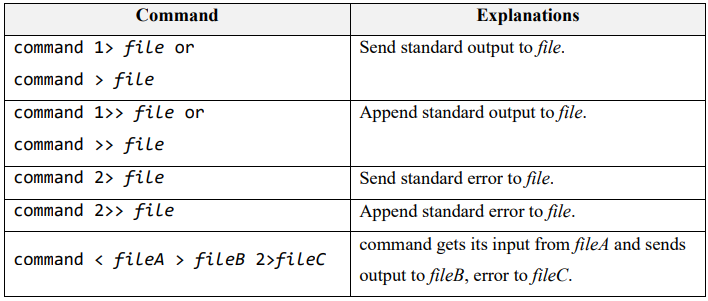
将标准输出与标准错误重定向至同一个文件 result.txt

对于 a.cpp,先使用命令g++ a.cpp -o a编译为可执行文件 a,再使用./a < in.txt > out.txt文件输入输出。这样就不用在程序内部使用freopen重定向了 -
pipe
有时我们想将某个程序的输出重定向作为另一个程序的输入:例如

此时,Shell 将会打印出所有包含 Jan 26 的行
然而,这个方法创建了一个中介文件 file.txt。有什么方法可以直接将ls的结果重定向至grep中而不用创建一个临时文件进行存储呢
我们可以用管道 pipe|来做到


Searching for files/directories (find)
命令 find 的格式如下

例:我们想由 当前目录 (current directory) 开始寻找所有前缀为 hello. 的 文件
$ find . -name "hello.*" -type f
(注意:. 代表的是当前目录 current directory)
Searching inside a file (grep) and regular expression
-
grep using regular expression
之前我们介绍了grep命令:grep 'abc' file即搜索并打印文件 file 中所有包含字符串 abc 的行
而grep命令的全称为 全局正则表达式打印 (Global regular expression print),其参数是可以使用正则表达式表示的,具体格式为

(不使用 flag-E时使用的是原始的根据给出字符串搜索打印) -
正则表达式中的特殊字符
.
字符.匹配任意的单个字符 (any single character)
例:'n..d' 匹配 'nMMd'^与$
字符^必须匹配行首,字符$必须匹配行尾
例:'^apple' 不能匹配 '* apple*' 因为行首字符是空格而不是 'a'?,+与*

例:
'abc?' 匹配 'abc' 或者 'ab'
'abc+' 匹配 'abc' 或者 'abccccc'
'abc*' 匹配 'ab', 'abc' 或者 'abcccccccc'
也可以配合使用,如 'a.*c' 可以匹配任意由 'a' 开头,'c' 结尾的字符串- 小括号
()
代表一串字串,例:
'(co)+' 匹配 'co' 或者 'coco' 或者 'cocococo',字符+对子串 'co' 起效果
若不加小括号,'co+' 中的字符+就只对字母 'o' 起效果了 - 中括号
[]
中括号匹配中括号中的字符集中的任意一个字符,例:
'[0123456789]' 或 '[0-9]' 匹配 \(0\) 到 \(9\) 中的任意一个整数
'[A-Z]' 匹配任意一个大写字母
'[A-Za-z]' 匹配任意一个字母 (大小写都有) - 大括号
{}
大括号用于表示某个模式重复的次数 (更加精确的?,+与*)
'a' 可以匹配 'a' 或 'aa'
'a' 可以匹配 'aaa' 或 'aaaa' 或 'aaaaaaa'
-
extension of 2

Module 2
介绍了 编写 .sh 脚本的方法与 Git (一种分散式版本控制系统,distributed version control system)
Module 3
C++ 基础,这个就是小 case 了,在这里记录一些边边角角
编译命令 g++ -pedantic-errors -std=c++11 hello.cpp -o hello
identifier 即变量名 variable name
operator 运算符 & operand 运算数
Division By Zero 错误是 runtime error,并不会产生编译错误信息
运算符的 precedence (优先级) 与 associativity (结合律)
使用 () 来 override precedence & associativity
逻辑运算中的 short-circuit evaluation (短路求值)
类型转换 Type Conversion:
- lower type promoted to higher type
例:3(int, lower type)/2.0 (double, higher type),operand \(3\) 类型由int转为double,此时 operator/执行双精浮点数除法 - In assignment statements, the value of the right side is converted to the type of the left
例:int x = 2.5等号右边的 \(2.5\) 因为被赋给int型变量,其类型由double(2.5)转化为int(2)
escape sequence

控制流 (flow of control)

Specifying Block statement : C/C++ V.S. Python
Python : 缩进 Indentation
C/C++ : {}
switch-case statement:


见该例,着重注意 break 在 switch 语句中的处理
当 case 中的 expression 与 switch 中的 expression 匹配时,将会执行该 case 下的所有语句,直至遇到 break

(缺少 break 的 switch 语句,case 7: 下的所有语句都被执行)
Module 4
这一章还是挺重要的,之前没有接触过
主要介绍了 Multiple Source File,File Dependency 文件依赖 与 makefile
Separate Compilation
-
Multiple Source Files
之前我所接触的都是 Single Source File
一个源文件一次编译一次运行,不用脑子
这是因为我没有接触过大型的 project: Multiple Source Files 有两个优势- 将各种 features 与主程序 main 分离,提升代码组织性与可读性
- 允许其他程序复用 features
具体来说,我们将需要分离的 feature 从 main 源文件 (.cpp) 中取出
其 声明 (declaration) 组织在自定义的头文件 (.h) 中,定义 (definition) 组织在另一源文件 (.cpp) 中 (这样是为了防止同样的文件被 include 多次)
(main 源文件
gcd_main.cpp)

(gcd 源文件 gcd.cpp,包含 gcd 的定义)

(gcd 头文件 gcd.h,包含 gcd 的声明)

注意,所有的源文件都需要被编译 (头文件不需要被编译,它可以视作一个宏) -
编译过程 Compilation Process

分别是 预处理 (处理头文件), 编译 (将代码编译成组合代码 Assembly code), 汇编 (将 Assembly Code 编译成机器码 machine code,此时是.obj文件的形式), 链接 (将所有的obj文件都链接在一起)

- Separate Compilation
可以发现 pre-process, compilation 与 assembly 过程均是独立的,只需要单一的目标源文件
因此,在 link 之前,我们可以分别对每个源文件进行前三个编译过程以得到 object codes,再进行 link 过程对其进行连接得到最终的 executable
这样的编译方案称为 Separate Compilation
Separate Compilation 有以下几个优点- 允许对不同的源文件分别进行编写与编译,并且分别测试其 object codes 的运行情况
- 对某个 project 进行修改时,只有受影响的源文件需要重编译 (recompile) : 这样可大大减少编译时间
- 只向用户提供 object codes 用于运行,从而隐藏真正的类型实现
例子:

对 gcd.cpp, gcd_main.cpp 分别编译得到 object codes gcd.o 与 gcd_main.o
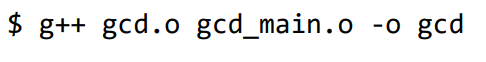
当所有源文件均生成 object codes 后,进行 link 过程得到 final executable gcd
- File Dependency 文件依赖性

上图展示了一个简单的文件依赖树。举例来说,若对源文件 calc.cpp 进行修改,则 calc.o 需要重编译并与未修改的 lcm.o 与 gcd.o 进行 link 以生成 final executable
(可看出 separate compilation 的优越性:lcm.o 与 gcd.o 都不需要进行重编译)
当情况更加复杂时,我们需要借助其它的工具来简化重编译过程
Using the make tool
- The make tool
当源文件被修改时, Linux 的make命令能够很方便的对受到影响的文件进行重编译 (recompile) 与链接 (link)
make尝试避免不必要的重编译与文件的重新生成
为了实现这个功能,我们需要向make命令提供文件的依赖性:储存文件依赖性的文件应被命名为MakeFile

MakeFile文件的格式如上
有几个小注意,g++中的-c参数代表进行预处理,编译,汇编三个步骤,因此最终产生的是 object codes
-o参数代表自定义生成程序的名称,而不是采取默认名称

makeworking procedure
我们将需要 生成 (generate / regenerate) 的文件称为目标文件 (target)
make在进行工作时 (我以伪代码的形式展示,大体思路相同)
File MakeFile[] // MakeFile is a tree
int upToDate(string FileName) {
if (MakeFile[FileName] == NULL) return 0;
for (i iterate through sons) {
if (sons.LastModificationTime > MakeFile[FileName].Lastmodification time)
return 0;
}
return 1;
}
void make(string FileName) {
for (i iterate through sons) {
if (!upToDate(i)) make(i);
}
if (upToDate(FileName))
return; // if the current file is up to date after its dependency is updated, then return
recompile(MakeFile[FileName]); // using the command in the MakeFile
MakeFile[FileName].LastModificationTime = CurrentTime;
}
make(target); // target is the root of MakeFile (usually)
采用这样的策略,能够使得某个源文件被修改后,需要 regenerate 的文件数目最少
-
make奇淫技巧 1 :MakeFile 中的变量
在 MakeFile 中,可以定义变量来指代文件

用$(variableName)进行文本替换

另外,MakeFile 中定义了默认的三个变量@,<与^,它们分别指代


注意:头文件.h是不用进行编译的! -
make奇淫技巧 2:假目标 Phony Target
我们可以通过 MakeFile 与假目标简化命令

以clean命令为例
当 directory 中没有名为clean的文件时,执行make clean
make将会发现clean是过时的 (因为它根本就不存在),于是执行 MakeFile 中记录的命令
以这种形式简化了命令的调用
但当目录中存在名为clean的文件时,make可能会发现clean并不是过时的,于是不会执行 MakeFile 中的命令
为了解决这个问题,我们在.PHONY中声明clean是一个假目标:在.PHONY中声明的目标文件,即使其并没有过时,也将会被 regenerate
Module 5
介绍了函数和递归的概念,很简单
Function
Pass by value / Pass by reference
Global / Local variable
Variable Scope (还记得 Lexical Scope)
Recursive
-
Recursive Definition

-
Stack Overflow
-
Recursion V.S. Iteration
Module 6
介绍了数组 Array 与 stringez
-
Array Initialization
int a[5] = {0, 1, 2, 3, 4}
int a[] = {0, 1, 2}(未指定数组大小,自动根据后面的元素个数分配:a[3])
注意这种初始化方法 (copy blocks of data to an array) 只能在定义数组的时候使用
不能使用它来修改已经被定义的数组 -
Pass an Indexed Variable / Whole Array to Function
将数组中的值传入函数有 pass by value 或 pass by reference (函数定义中对应的形参要加上&运算符) 两种方式
若将整个数组传入函数,表现为 pass by reference (将具体的数组指针传入)
如果是 2 维数组,函数形参中的定义应该包括其第二维度int a[][4]或int (*a)[4]
这是因为,一维数组的名称是一个指向数组首元素的指针,首元素的类型是int
而二维数组的名称也指向数组首元素,而该首元素是一个数组,其类型是int [4] -
char
char 与 int
ASCII 码: A character-encoding scheme
'A'=65
小写字母的 ASCII 值大于大写字母
字符串是以\0结尾的字符数组 (zero-terminated string) -
string object
读入不带空格的字符串cin
读入带空格的字符串 (读取包括空格的所有字符直到行末)getline(cin, s)
可用 char 数组来对 string 变量赋值
char a[] = "Tim"; string c; c = a; -
排序
选择排序 Selection sort: 不稳定
冒泡排序 Bubble sort:稳定
Module 7
这一节主要介绍 File I/O,structure 与 class
这节课里 File I/O 用的是 头文件 fstream 中的 ifstream 类与 ofstream 类,与之前常用的 freopen 有点区别,记录一下
File I/O 文件输入输出
在 include 头文件 fstream 后,可以定义 ifstream 类对象与 ofstream 类对象
-
ifstream类对象
ifstream fin;定义一个名为fin的ifstream类对象
fin.open(s.c_str());打开名字为字符串 s 的文档 (这里也可直接传入双引号扩起的字符串)
fin.fail()在 open 过后判断打开文档是否成功
在打开文档过后,将这个对象当作cin一样使用 (extraction operator>>)
fin.close()最后一定要记得关闭文档 -
ofstream类对象
ofstream fout;定义一个名为fout的ofstream类对象
(与fin的成员函数相同,流程相同,打开文档过后将该对象当作cout一样使用)
当进行文件输出使用 open 打开某文件时,若工作目录中没有该文件,将会自动创建一个新的使用该名称的文件
若存在该文件,该文件中原本的内容将会被清空,再对清空后的文件中输出内容
如果想要保留文件中原本的内容,并将输出重定向到原本文件内容的末尾,可以在 open() 中添加参数 ios::app
fout.open("receipt.txt", ios::app);
-
关于 EOF (End of File)
文件读取到 EOF 结束
表达式fin>>x的返回值:- 若数据被成功读取,返回 true
- 若已经到达 EOF,无法继续读取数据,返回 false
记得之前我们在使用函数
getline()读取一整行时,传入的是cin
相应的,在使用文件读入时,我们传入ostream类的对象fin(或其他名字)
例getline(fin, str);
同样,getline(fin,str)也有返回值- 若数据成功读取,返回 true
- 若已经到达 EOF,无法继续读取,返回 false
-
input string stream 输入字符串流
include 头文件sstream后
我们可以定义istringstream类的对象,并用某个string类型的字符串进行初始化

接下来,我们就可以通过该输入字符串流进行输入

(对于进行初始化的字符串str,我们可以将其内容视作是控制台中输入的内容:因此可以向int型变量中输入)
同样的,对于表达式input_string_stream >> variable的返回值- 数据以成功读取,返回 true
- 若已经到达 EOS (End of String),无法继续读取,返回 false
这个输入字符串流之前没有接触过,贴一个程序理解一下

-
String output formatting (String 输出格式)
这个知识点感觉比较实用,介绍了很多利用 修饰符 output manipulator 规定输出格式的方法
在使用修饰符进行 IO formatting 时,一般来说,带参数的修饰符需要 include 头文件 iomanip,而不带参数的修饰符只需要 include 头文件 iostream- Default Floating-Point Notation

这些均是 significant digits 超过 \(6\) 的情况 - showpoint Manipulator:输出小数位的修饰符

下面是使用了showpoint修饰符的结果:输出了全 \(0\) 的小数部分 - fixed 与 scientific 修饰符
fixed:输出浮点数小数点固定位数 (可用setprecision()进行设定,默认为 \(6\) 位小数)
scientific: 以科学计数法形式输出浮点数

- setprecision 修饰符
在不加fixed或scientific修饰符时,setpresicion(n)限制浮点数的最大有效位数为 \(n\) (这也意味着,当有效位数小于等于 \(n\) 的浮点数被 setprecision 后,输出与原来一致)

当与fixed或scientific修饰符一起使用时,setprecision(n)控制浮点数的小数位数为 exactly \(n\)
注意,这里的小数取舍与传统的四舍五入不同:若第 \(n+1\) 及其后的位数 \(\leq 5\) (例如 \(0.xxx5, 0.xxx4999\)) 则全部舍弃,反之 (例如 \(0.xxx50001, 0.xxx6000\)) 则进 \(1\)


- setw 修饰符
setw(n)修饰符控制接下来输出的内容所占的列数为 \(n\),默认为右对齐 (right-justified) - setfill 修饰符
当使用 setw 时,空白的列数将会用空格填充。我们用修饰符setfill(c)指定用来填充空白列数的字符

- left/right 修饰符
使用left与right来指定 setw 的对齐方式

- Default Floating-Point Notation
Struct & Class
这两个都比较熟悉了,Struct 是 C++ 对 C 结构体的承袭,而 Class 则是对 Struct 的扩展
两者的最主要区别就是是否可以定义成员函数 member function
平时使用时还是多多使用 class 吧,它是 OOP 的基础,对象 object 就是 class 类的实例 instance
-
Declaration
再次强调头/源文件的分离

例:对于自定义的Product类,我们自定义头文件"product",并将类的声明写在头文件中 (包括成员变量,成员函数的参数表与返回值),再编写一个源文件对类进行实现
这样做的原因是为了使得Product类能在多个源文件中进行使用,而 C++ 虽然支持多次声明,但只允许一次实现



-
Compiling multiple files process
- Compile source code to object code


- Link the object code

Module 8
这个模组介绍了 Pointers (指针),Dynamic Memory (动态内存)
都是很重要并且较为深入的内容——这一部分之前有接触,但是并不熟练,更要好好学习 (复习时最好看下 slides)
着重理解运算符 *: 定义指针/解引用 与 &: 定义引用/取地址】
关于 dynamic array 与 linked list 内容,请看 Module 8 Slides
-
Memory Address
main memory 是由许多 memory cells/locations 组成的
其中每一个 memory cell 都有其独特的 memory address
因此,对于我们定义的每一个变量 (variable) 都有- 存储在 memory cell 中的变量 值 (value)
- 对应的 memory address
\(\mathtt{int}\) 变量占连续的 \(4\) 个 memory cells (\(4 \ bytes=32\ bits\))
对于占有 \(>1\) 个 memory cells 的变量,其 memory address 是开头的 memory cell 的 addressthe \(\mathtt{address-of}\) operator
&: 取地址符,返回某个变量的 memory address -
Pointer Variable 指针变量
指针 (pointer) 指向 memory address,指针变量是存储指针的变量 (或者可以这么说,指针变量存储的是地址值 (address value))
定义指针变量type *variable_name,type 决定了指针的类型
这里又不得不提到运算符*的两种用法:- Pointer declaration: 定义指针变量,如
int *a - Dereference a pointer:
*后接地址 (指针) 代表直接对该地址进行访问 (即该地址存储的变量),例对于a = 3,*(&a)的值是 \(3\)
注意,指针变量也有对应的 memory address: 因此,对指针变量取地址得到的是该指针变量的 memory address
- Pointer declaration: 定义指针变量,如
-
Struct/Class Pointer 类/结构体指针
对于类/结构体指针,我们可以使用运算符->来访问成员函数/变量 (member access function)
对于类指针 \(a\),a->fun()\(=\)(*a).fun() -
空指针与 NULL
指针变量可以用 \(\mathtt{NULL}\) 进行初始化
\(\mathtt{NULL}\) 的意思是未储存任何地址,存储 NULL 的指针称作空指针 (NULL pointer) -
动态变量 dynamic variable

动态变量使用的是 dynamic memory,只能通过指针进行定义
int *a; // a 是一个 int 型指针,其的地址储存在 ordinary memory 中
a = new int; // 此时,我们为指针 a 分配了一片 dynamic memory (``int`` 型,因此是 $8$ 个字节)
// new type 将会返回 type 对应大小的 dynamic memory address
*a = 8; // 我们通过 dereference operator 对该指针指向的 dynamic memory 进行操作,因此可以将这一片 memory 视作 dynamic variable
-
Pointers and Functions
将指针作为函数参数,并传入变量的地址,其效果与传引用 (pass by reference) 相同 -
Pointers and Arrays
在之前 coursera PKU C++ 课程上已经了解过:数组指针指向数组开头元素的地址
数组的名字就是该数组的指针
因此,对于a[100]
int *p = a,\(p\) 与 \(a\) 完全一致
*(a+i)即a[i] -
new and delete
new关键词将分配对应 type 的 dynamic memory cells,并返回这一片 memory 的地址给指针
关于 nothrow:

delete关键词将会释放对应指针中所分配的 dynamic memory (当某个指针被 delete 过后,该指针就成了 "野指针",最好将其用 NULL 赋值变为安全的空指针)
若某指针是一个动态数组指针 (其指向动态数组首元素的地址),在 delete 时这样写delete [] a
Module 9
这一个模组介绍了 STL. easy!
Standard Template Library (STL)
- Containers (容器): storing items
- Iterators (迭代器): accessing items
- Algorithms (算法): manipulating items
Vector

List

注意,STL list 不提供下标访问 [],因此访问第 \(i\) 个元素的效率不高
Map
用 BST 来实现,因此查询是 \(O(\log n)\) 的

重载运算符英文:operator overload

iterator 访问 (*itr).first, (*itr).second
重复 key: multimap
Vector, List and Map: Performance Comparison

Iterator
- declaration

::Scope resolution operator - traversing the containers

*: dereference operator - Type of iterators
迭代器分为 前向迭代器 (forward iterator), 双向迭代器 (bidirectional iterator), 随机访问迭代器 (random access iterator)

vector 的迭代器是随机访问迭代器,而 list 与 map 均是双向迭代器
Iterator V.S. Pointer
可以发现 Iterator 与 Pointer 的许多相似之处:均指向特定的 items, 且在访问该 item 时都使用 dereference operator *

Generally speaking, iterators are designed to avoid low-level memory manipulation. It is usually easier to work with iterators.
Algorithm
- SORT
我们向 sort 中传入 begin 迭代器与 end 迭代器
同时,对于int类型指针 pointer,我们也能传入 sort,sort 将自动将其转化为随机访问迭代器
sort 无法对 list 与 map 进行排序: 因为 list 与 map 的迭代器类型都是双向迭代器
\(O(n\log n)\)
Module 10
简单简单,介绍了 C 语言的基础
这里就简单记录一下学到的英语名词
Conversion Specifier
即 $d, %f, %s 这些格式转换符
学到了一个新的: %g 能够输出 double, float 的同时去除后缀 \(0\)
另外,在标识符中间添加数字能够达到 setw() 的效果: 这个技巧在 gp 中也用到了
"%10s" 字符串占 \(10\) 宽度且右对齐 (right-justified);"%-10s" 字符串占 \(10\) 宽度且左对齐 (left-justified)
String Literal
这是字符串常量的意思
Null Character
即 \0,字符串的末尾标识符
使用 printf("%s") 输出字符串时,只输出 Null character \0 之前的部分
使用 scanf(%s) 读入字符串时,系统将自动在末尾补充 null character
C V.S. C++
有许多在 C++ 中熟悉的语法,在 C 中可能都不适用
-
for (int i = 1; ...)
在 for 循环中的临时 iterator 可以在 for 中直接进行定义
然而,用gcc编译器编译时会弹出错误
在 c99 标准中这一写法得到了支持,所以解决的方法是在gcc编译器后加上参数-std=c99 -
pass by reference
在 C++ 中,一个常见的 pass by reference 方法是将形参的类型定义为 reference
例如void swap(int& a, int& b)
然而这一写法在 C 中并不受支持
在 C 中实现 pass by reference 的方法是通过传入地址,并使用指针来操作
void swap_in_C(int* a, int* b) { // pointers as parameters
int c = *a;
*a = *b;
*b = c;
}
swap_in_C(&a, &b); // pass addresses
-
string functions
C++ 的 STL 中提供了 string 类对字符串进行操作,十分方便
其底层的代码仍然是用 char 数组来定义字符串的
C 中的字符串操作全部通过 char 数组来完成:在 include<string.h>后,可以使用以下字符串函数

注意:当使用strcpy(s1, s2)与strcat(s1, s2)时进行拷贝/连接,前一个字符串必须要有足够的空间
否则可能会出现 array access out of bound 错误 -
关于 dynamic memory allocation
在 C++ 中,我们用new (type)来分配动态内存,返回一个 type 类型的指针指向分配的空间;并使用delete进行动态内存的释放
而 C 中并不提供对new与delete关键字的支持
话是这么说,C 中的 dynamic memory allocation 实际上与 C++ 也差不多,只不过语法上稍微复杂一点在 include
<stdlib.h>库后,可以使用malloc()与free()函数进行 dynamic memory allocation,且可以使用 NULL 空指针
malloc()的 definition:void* malloc(int size)其参数是需要分配的空间大小,返回一个 void 类型的指针
可以这么说:new type(in C++) \(=\)(type)* malloc(sizeof type)(in C)
而free(void*)的用法与 delete 差不多: free 释放掉的内存一定是之前被 allocate 过的,否则就会造成运行时错误 -
Struct (C) V.S. Class (C++)
Structs: 所有成员公有 (public), 没有成员函数 (包括 constructor/destructor)
其本质上只是一个数据集合,不提供 OOP 支持
C++ 的 OOP 性质来自 Class,而 Class 即是支持 OOP 的 Struct
(注意,C++ 中的 struct 与 C 中的 struct 是不同的概念:C++ 中的 struct 本质上是成员公有的 class,它也能支持 OOP)在 C 中,实例化 struct 的语法是
struct [struct_name] [instance_name]: 注意前面是有一个 struct 的! (可以通过typedef进行简化)
这一点与 C++ 不同,C++ 中可以直接通过[struct_name] [instance_name]定义实例
GDB debugger
了解一下就行了,这是最 primitive 的 debugger
现在各个开发环境都自带方便的 debug 功能,不用再再 terminal 上 debug 了
