
搜索技术架构-押韵精灵
欢迎访问我的押韵精灵,是一个在线查询押韵的诗、词、歌、字的工具网站,包含双押多押等。
上一篇谈到了如何用阿里云搭建这样的网站,本文记录下该网站的整体架构,话不多说直接上图:
搜索技术架构

数据源
数据可以直接从开源的地方下载或者自己弄个爬虫获取,这里给大家推荐一个C#爬虫和几个java爬虫:https://www.cnblogs.com/VectorZhang/p/5478711.html, https://www.zhihu.com/question/31427895, 爬虫的架构几乎都大同小异。这里以Abot爬虫为例
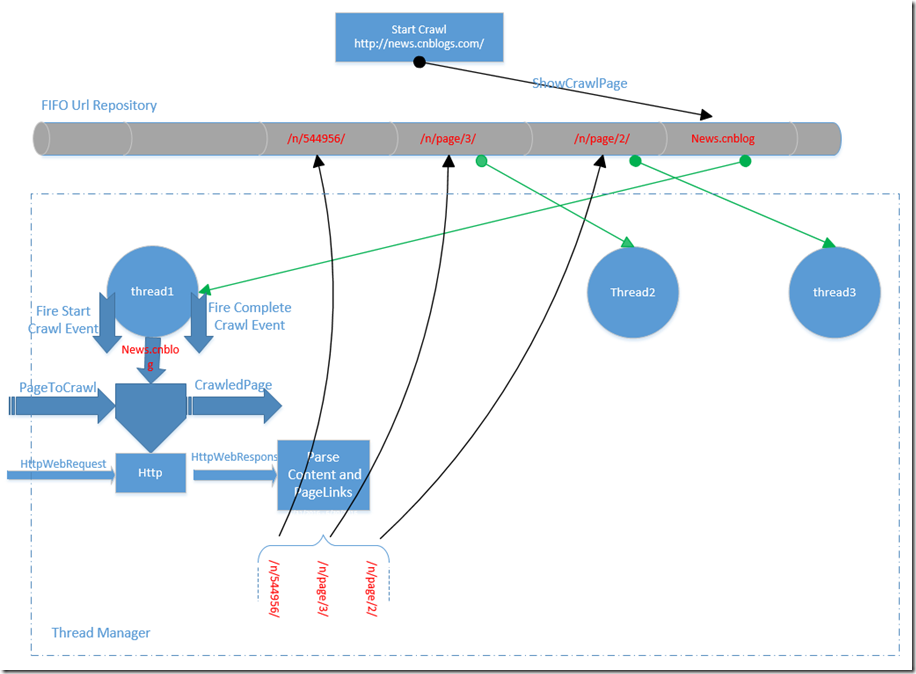
上图中 绿色的箭头表示线程从Url Repository获取需要爬取的Url, 黑色的箭头表示线程将未爬取Url放入Url Repository。
主要的模块有:
1) Url Repository 存储所有需要爬取的Url,底层的实现采用了ConcurrentQueue,因此是线程安全的,也满足了先进先出的规则。
2) Thread Manager 管理所有的爬取线程,线程个数默认是当前处理器的个数,也可以通过Config 指定。
3) Robots 处理robots.txt 的模块,Abot 直接封装了NRobotsPatched 来解析robots.txt
4) LinkParser解析当前爬取到的page 中的链接,Abot 很大程度上利用了HtmlAgilityPack
5) Crawled Url Repository 存储已经爬取的Url,Abot 内部有多个实现
6) Http download 采用了HttpWebRequest 和 HttpWebResponse
7) Memory Monitor 主要是监控内存使用等等,可以通过Config设置爬虫的内存使用上限等
8) Event 相关,主要是在适当的时候触发像Start Crawl 等事件
未来规划
- 数据是一次性预处理到mysql以及一次性dump到搜索引擎,未来可以实现T+1全量dump以及通过爬虫增量进引擎
- 干预的数据目前只有黑名单而且是召回后干预,未来需要将干预数据落到引擎
- 指标只有曝光UV和搜索UV,点击率等指标还需要完善,列表点击并未形成闭环
- 缺乏点击率 和 用户纬度的特征,导致目前精排能力有限,成语和词语没有打散处理
- 用户登录功能缺失,未来加入微信扫描登录功能
- 资金有限,资源有限,ES存储的数据只保留的少数几天,有条件了直接购买阿里云ES服务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号