7.12考试总结(NOIP模拟12)[简单的区间·简单的玄学·简单的填数]
即使想放弃,也没法放弃最想要的东西,这就是人
前言
这次应该是和 SDFZ 一起打的第一场比赛吧。
然而我还是 FW 一个。。。
这次考试也有不少遗憾,主要的问题是码力不足,不敢去直面正解,思考程度不够。
改题也比较费劲,记录:
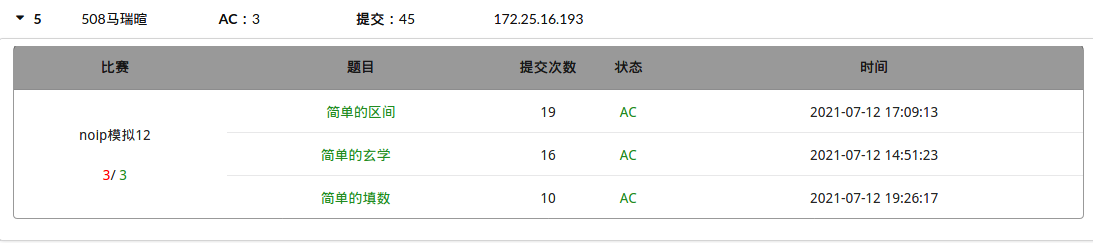
T1 简单的区间
背景
这个题和上一场比赛的第三题一样令人感到亲切,还是在第一时间内想到了单调栈求左右边界。
然后就想到了昨天考试题的恶心程度,想都没想,码完一个单调栈优化的暴力之后就走了。
得分:30pts(\(code\));
解题思路
这个题的做法其实有三种,一种是递归运算的正解,另一种是码量极大的主席树(可持久化权值线段树记录个数)。
这里分别给出官方题解和 zxb 的\(code\);

然后就是来自于 pyt 的 vetor 做法了。
第一步也是运用单调栈求出左右区间,再次不做过多赘述。
接下来就是类似于入阵曲的做法了,求出前缀和(存到 q 数组里)后对于 \(\bmod\;k\) 意义下的不同的余数的数量。
然后就是运用启发式合并的思想进行处理了。
对于暴力左区间的情况,假设当前扫到了 i 合法节点为 j 最大值的下标为 pos 。
满足 \(q_j\) 与 \(q_i+s_{pos}\) 在 \(\bmod\;k\) 意义下相同的序列就是 k 的倍数。
因为,我们只需要在右区间内的符合条件的点的个数。
所以,直接在 vector 里二分查找出右端点和 pos 在 vector 中的下标,相减就是个数了。
同样的 对于暴力右区间的算法也是如此,有一些不同。
- 注意: 在存储余数为 0 的 vector 数组里要先放进去一个 0 ,因为在暴力右区间的时候会有左端点-1,可能会在序列里没有这个数,并且与入阵曲相似,前零位和的余数也为 0 ,
- 另外,还有注意一下前缀和的区间端点问题。
code
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch>'9'||ch<'0')
{
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9')
{
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return x*f;
}
const int N=5e6+10,M=5e6+10;
int n,mod,ans,top,s[N],sta[N],l[N],r[N],q[N];
vector<int> v[M];
inline void Sta_Init()
{
sta[++top]=1;
l[1]=1;
for(int i=2;i<=n;i++)
{
while(top&&s[sta[top]]<=s[i])
{
r[sta[top]]=i-1;
top--;
}
l[i]=sta[top]+1;
sta[++top]=i;
}
while(top) r[sta[top--]]=n;
}
inline int workl(int li,int ri,int pos)
{
int sum=0;
for(int i=li;i<=pos;i++)
{
int res=(q[i-1]+s[pos]%mod+mod)%mod;
int ls=lower_bound(v[res].begin(),v[res].end(),pos)-v[res].begin();
int rs=upper_bound(v[res].begin(),v[res].end(),ri)-v[res].begin();
sum+=max(rs-ls,0ll);
}
return sum;
}
inline int workr(int li,int ri,int pos)
{
int sum=0;
for(int i=pos;i<=ri;i++)
{
int res=(q[i]-s[pos]%mod+mod)%mod;
int ls=lower_bound(v[res].begin(),v[res].end(),li-1)-v[res].begin();
int rs=upper_bound(v[res].begin(),v[res].end(),pos-1)-v[res].begin();
sum+=max(rs-ls,0ll);
}
return sum;
}
#undef int
int main()
{
#define int register long long
#define ll long long
n=read();
mod=read();
for(int i=1;i<=n;i++)
s[i]=read();
Sta_Init();
for(int i=1;i<=n;i++)
q[i]=(q[i-1]+s[i])%mod;
v[0].push_back(0);
for(int i=1;i<=n;i++)
v[q[i]%mod].push_back(i);
for(int i=1;i<=n;i++)
if(i-l[i]<r[i]-i)
ans+=workl(l[i],r[i],i);
else ans+=workr(l[i],r[i],i);
printf("%lld",ans-n);
return 0;
}
T2 简单的玄学
背景
对于 70pts 的柿子,相信各位都可以很快地搞掉:
也就是:
不难发现对于 \(m<10^6\) 的数据,直接暴力算 \(2^n\) 后的 m 项,然后求一个 \(\gcd\) 就可以了。
但是,取 \(\bmod\) 之后的 \(\gcd\) 就不是原来的 \(\gcd\) 了!
例如:7 和 11 在 \(\bmod\;4\) 的意义下的 \(\gcd\) 是 3 但是他们本身的 \(\gcd\) 是 1 。
于是我们骗到 70pts 的幻想破灭了(可惜考场上的我太傻没有想到这个反例。。)
让我们看一下官方题解:

意会一下之后,我们发现分母的约数只能是 2 的倍数,然后我们就可以求分子上阶乘的 2 的次数。
发现是有一定规律的:每隔 \(2^i\) 就会有一个 \(2^i\) 的倍数,所以就可以 \(\mathcal{O(log_2m)}\) 求出。
但是,更大的该怎么办呢??,不难发现,如果 \(m>\bmod\) 那么分子在 取 \(\bmod\) 之后一定是 0 ,
因此我们只需要求出公约数之后输出两次分母就好了。
code
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch>'9'||ch<'0')
{
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9')
{
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return x*f;
}
const int mod=1e6+3;
int n,m,base,ans=1;
inline int ksm(int x,int p)
{
int ans=1;
p=p%(mod-1);
while(p)
{
if(p&1) ans=ans*x%mod;
p>>=1;
x=x*x%mod;
}
return ans;
}
#undef int
int main()
{
#define int long long
#define ll long long
n=read();
m=read();
base=ksm(2,n);
int poww=1,sum=0;
while((poww=poww*2)<=m-1)
sum+=(m-1)/poww;
if(m>=mod)
{
int tmp=ksm(ksm(2,sum),mod-2);
base=tmp*ksm(base,m-1)%mod;
printf("%lld %lld",base,base);
return 0;
}
for(int i=1;i<m;i++)
ans=ans*(base-i)%mod;
ans=ans*ksm(ksm(2,sum%(mod-1)),mod-2)%mod;
base=ksm(2,(((m-1)%(mod-1))*(n%(mod-1))+mod-1-sum)%(mod-1))%mod;
printf("%lld %lld",(base-ans+mod)%mod,base%mod);
return 0;
}
T3 简单的填数
背景
这个题思考的不多,码了个暴力就走了,然后小的数据点 TLE 大的直接 WA ,人傻了。
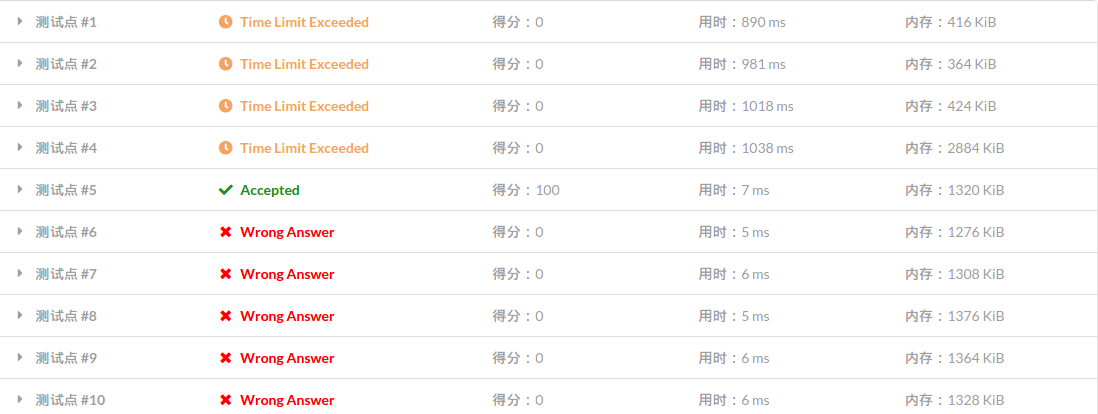
解题思路
先看一下官方题解:

然后我们发现根本看不懂。。。
开两个 pair 数组分别记录贪心到现在位置的最大值以及现在最大值的数量(也就是 up)。
同样的,用 down 记录最小值以及其数量。
对于没有数的位置,直接贪心的向后算就好了( up 类似于二进制, down 类似于五进制)。
对于有数的位置(假设现在要填进去的数为 up 和 down ,现在有的数是 s[i])分为以下几种情况
-
\(s_i>up\) 或者 \(s_i<down\) 表示这个序列不可能实现,直接输出 -1 。
-
\(s_i=up\) 或者 \(s_i=down\) 直接该怎样算怎样算就好了。
-
\(s_i<up\) 对于 up 的值,储存为 \(s_i\),数量记为 2 (因为后面的数要尽量地大)。
-
\(s_i>down\) 同样的,对于 down 值,也是储存为 \(s_i\) ,但是数量要储存为 1 (因为后面的要尽量的小)。
剩下的就与 down 没有什么关系了,主要运用 up 数组 逆推,特判一下第 n 位,之后尽量对于没有数的挑着大的选就好了,需要用一个数组记录一下每一个数的出现次数。
code
#include<bits/stdc++.h>
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch>'9'||ch<'0')
{
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9')
{
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return x*f;
}
const int N=2e5+10;
int n,ans[N],s[N],vis[N];
pair<int,int> up[N],down[N];
inline void Up_True(int pos,int num)
{
if(num<s[pos])
{
cout<<-1;
exit(0);
}
up[pos].first=s[pos];
up[pos].second=2;
}
inline void Up_False(int pos)
{
if(up[pos-1].second==1)
{
up[pos].first=up[pos-1].first;
up[pos].second=2;
return ;
}
up[pos].first=up[pos-1].first+1;
up[pos].second=1;
}
inline void Get_Up()
{
for(int i=2;i<=n;i++)
{
int temp;
if(up[i-1].second==2) temp=up[i-1].first+1;
else temp=up[i-1].first;
if(s[i]&&s[i]!=temp) Up_True(i,temp);
else Up_False(i);
}
}
inline void Down_True(int pos,int num)
{
if(num>s[pos])
{
cout<<-1;
exit(0);
}
down[pos].first=s[pos];
down[pos].second=1;
}
inline void Down_False(int pos)
{
if(down[pos-1].second<5)
{
down[pos].first=down[pos-1].first;
down[pos].second=down[pos-1].second+1;
return ;
}
down[pos].first=down[pos-1].first+1;
down[pos].second=1;
}
inline void Get_Down()
{
for(int i=2;i<=n;i++)
{
int temp;
if(down[i-1].second==5) temp=down[i-1].first+1;
else temp=down[i-1].first;
if(s[i]&&s[i]!=temp) Down_True(i,temp);
else Down_False(i);
}
}
int main()
{
n=read();
for(int i=1;i<=n;i++)
s[i]=read();
up[1].first=up[1].second=down[1].first=down[1].second=1;
Get_Up();
Get_Down();
if(!s[n]) vis[ans[n]=up[n-1].first]++;
else ans[n]=s[n];
for(int i=n-1;i>=1;i--)
{
ans[i]=min(up[i].first,ans[i+1]);
if(vis[ans[i]]>=5) ans[i]--;
vis[ans[i]]++;
}
printf("%d\n",ans[n]);
for(int i=1;i<=n;i++)
printf("%d ",ans[i]);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号