
拿到机器学习数据后,该如何对数据进行划分?
在处理机器学习任务时,我们都需要使用数据,当然,有时候数据集可以很大,有时候数据集数量不是很理想,那么如何针对这些数据得出更加有效的模型呢?
大型数据集
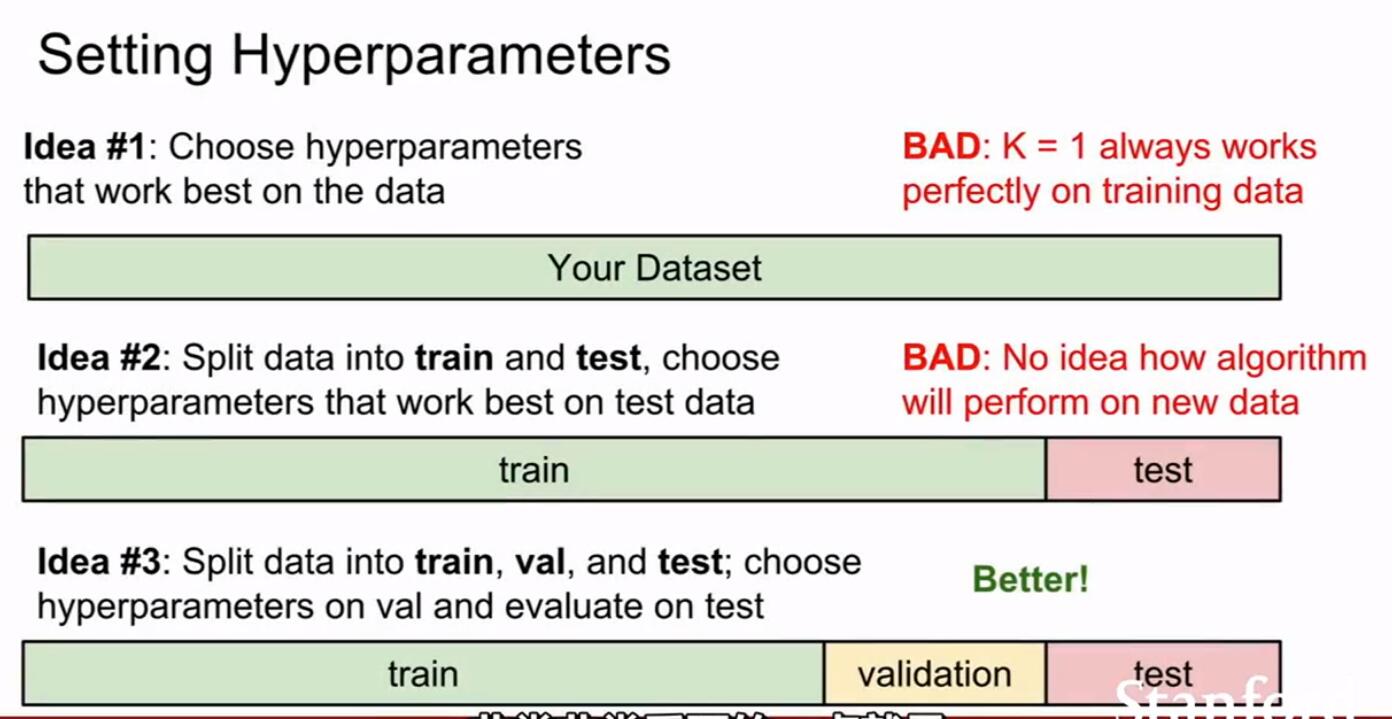
Idea #1: 当我们拿到数据集后,如果将所有数据进行训练的话
这样会导致模型见过所有的数据,如果再用这些数据进行测试的话,效果会非常好,但我们知道,这其实是一种过拟合现象,我们的模型在当前数据集中,永远表现很好。
Idea #2: 当我们拿到数据集后,将数据集划分成训练集(train set)和测试集(test set)的话
这样我们使用训练集训练模型,使用测试集来找到最佳超参数时,其实,这个test不能代表在全新的未见过的数据上的表现,这样会导致,我们选择的超参数,可能只是在这个测试集上表现良好。
(最佳方案!!)Idea #3: 当我们拿到数据集后,将数据集划分成训练集(train set)、验证集(validation set)和测试集(test set)的话
我们可以使用训练集来训练模型,并使用验证集来选择合适的超参数,最后使用全新的测试集来衡量模型的泛化能力。
数据集不是很充分
当我们没有大量数据时,没办法做上面那种任性的操作,我们可以尝试一种新的办法。
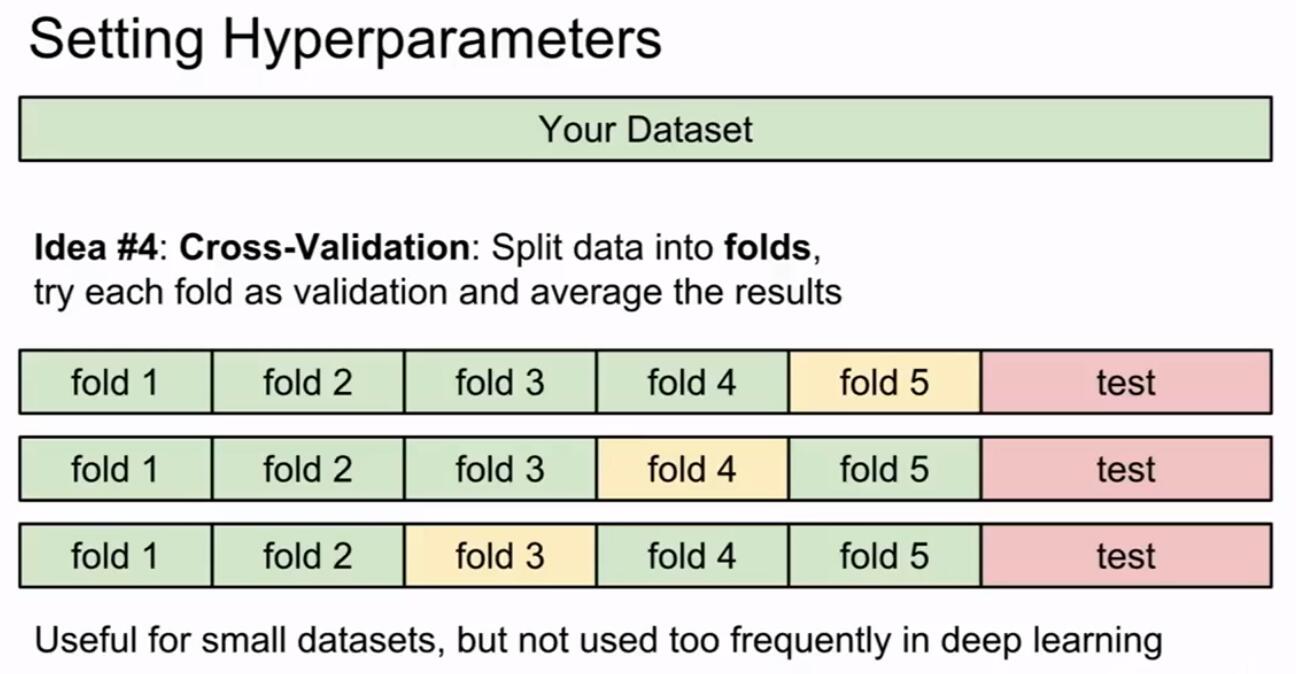
交叉验证,这个时候就登场了,它其实和上面的思想差不多,就是我们单独把测试集先抽出来,然后把剩余的部分切分,循环当训练集和验证集,上图中黄色的就是验证集,绿色的是训练集。

