

样本不均衡对模型的影响
在做项目的时候,发现在训练集中,正负样本比例比例在1:7左右,虽然相差不多(但在实际获取的样本比例大概在1:2000左右),所以有必要探讨一下在样本不均衡的情况下,这些训练数据会对模型产生的影响。
在实际的模型选取中,采用了SVM和textCNN这两种模型对文本进行分类,下面分别看一下这两种模型在样本不均衡的情况下,其泛化能力的体现(搜集其他人做过的实验与总结,参考博客附于文章末尾)
SVM
理论上来说,SVM实现分类的方法是以支持向量为参照,选取硬间隔最大的超平面,其超平面的选取只与支持向量有关,所以不是很care到底两边还有多少个点。但是当一类样本远多于另一类样本时,可见以下图:
假设真实数据集如下:
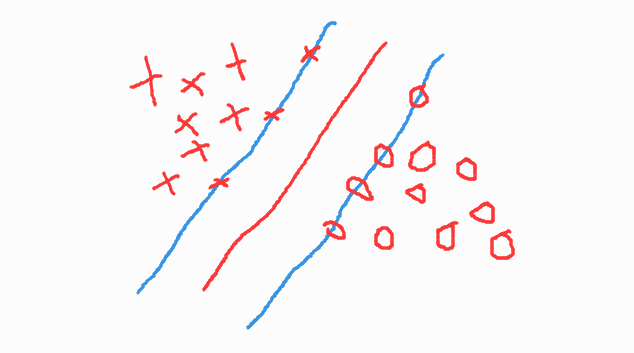
由于负类样本量过少时,可能会出现下面这种情况:

使得分隔超平面偏向负类。严格意义上,这种样本不平衡不是因为样本数量的问题,而是因为边界点发生了变化。(本应出现在更左侧的圈圈,没有纳入到样本集中)
当样本不可分时,也会出现这种情况,即分隔超平面偏向负类。将会导致对比例大的样本造成过拟合,也就是说预测偏向样本数较多的分类,这样就会降低模型的泛化能力,往往准确率(accuracy)很高,但auc很低。
CNN
由于项目中也使用了textCNN对不均衡样本进行了训练与预测,需要看看样本不均衡对CNN造成了多少影响。
实验数据与使用的网络
数据:CIFAR-10,共有10类(airplane,automobile,bird,cat,deer,dog, frog,horse,ship,truck),每一类含有5000张训练图片,1000张测试图片。
网络:点我,网络包含3个卷积层,还有10个输出节点(当然我们的模型架构和这个例子不同)。在这里只是为了看样本不均衡对CNN的影响。
类别不平衡数据的生成
直接从原始CIFAR-10采样,通过控制每一类采样的个数,就可以产生类别不平衡的数据。下图是11次对10个类别的采样样本比例图:
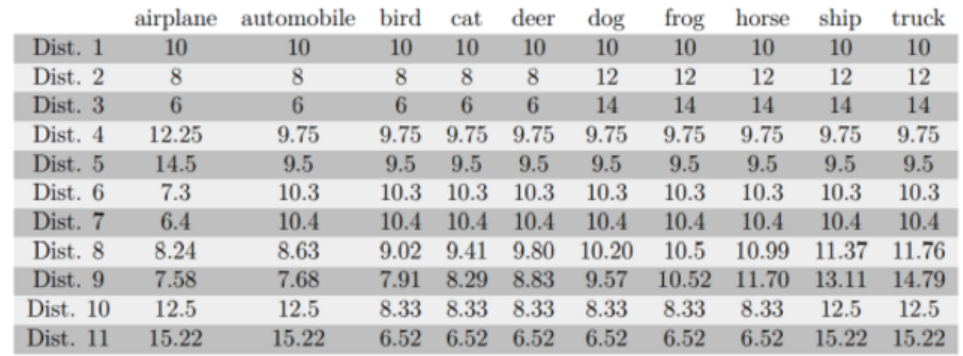
Dist. 1:类别平衡,每一类都占用10%的数据。
Dist. 2、Dist. 3:一部分类别的数据比另一部分多。
Dist. 4、Dist 5:只有一类数据比较多。
Dist. 6、Dist 7:只有一类数据比较少。
Dist. 8: 数据个数呈线性分布。
Dist. 9:数据个数呈指数级分布。
Dist. 10、Dist. 11:交通工具对应的类别中的样本数都比动物的多
类别不均衡数据的训练结果
以上数据经过训练后,每一类对应的预测正确率(accuracy)如下:
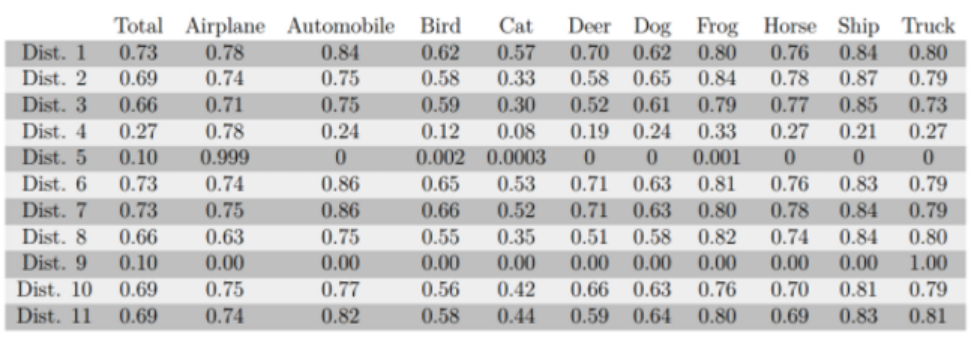
Total表示总的正确率,由各类准确率加权得到,从实验结果可以看出:
- 类别完全平衡时,结果最好。
- 类别“越不平衡”,效果越差。比如Dist. 3就比Dist. 2更不平衡,效果就更差。同样的对比还有Dist. 4和Dist. 5,Dist. 8和Dist. 9。其中Dist. 5和Dist. 9更是完全训练失败了。
采用过采样训练的结果
通过过采样对数据进行平衡,得到的测试结果为:
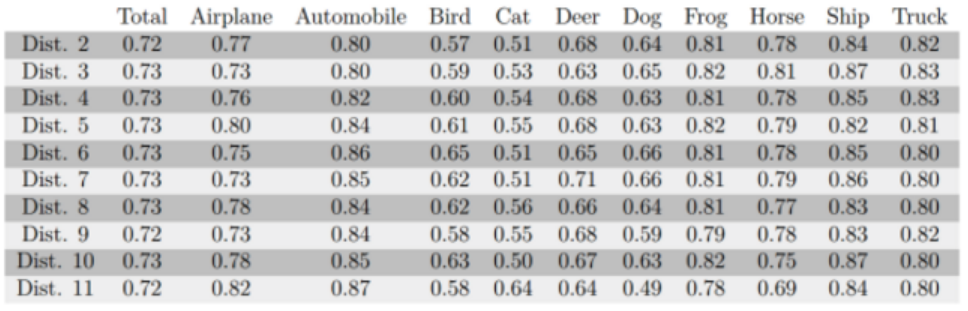
发现效果上来了,过采样前后的性能对比见下图:
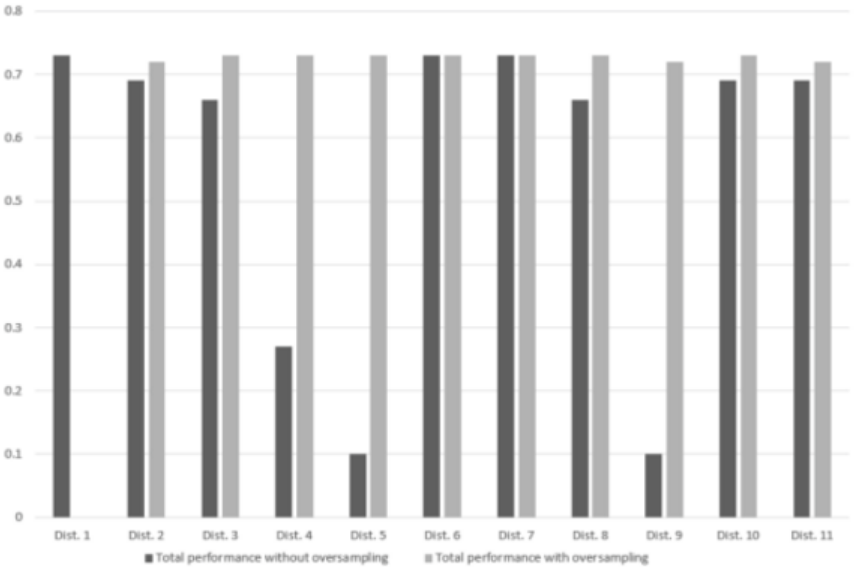
可以看出CNN确实对训练样本中类别不平衡的问题很敏感。
如何解决数据不平衡问题?
一。 对数据进行重采样
1. 过采样(over-sampling)
对小类的数据样本进行采样来增加小类的数据样本个数,即过采样(over-sampling ,采样的个数大于该类样本的个数)。
2. 欠采样(under-sampling)
对大类的数据样本进行采样来减少该类数据样本的个数,即欠采样(under-sampling,采样的次数少于该类样本的个素)。
一些经验:
- 考虑对大类下的样本(超过1万、十万甚至更多)进行欠采样,即删除部分样本;
- 考虑对小类下的样本(不足1为甚至更少)进行过采样,即添加部分样本的副本;
- 考虑尝试随机采样与非随机采样两种采样方法;
- 考虑对各类别尝试不同的采样比例,比一定是1:1,有时候1:1反而不好,因为与现实情况相差甚远;
- 考虑同时使用过采样与欠采样。
二。 扩充数据集
三。 尝试其他分类指标
类别不均衡的情况下,准确率可能不会很work,因此要采用其他更有说服力的评价分类指标:
- 混淆矩阵(Confusion Matrix):使用一个表格对分类器所预测的类别与其真实的类别的样本统计,分别为:TP、FN、FP与TN。
- 精确度(Precision)
- 召回率(Recall)
- F1得分(F1 Score):精确度与召回率的加权平均。
四。 尝试产生人工数据
ps:有一个类别样本很少,就是通过这种方式产生的,待我仔细了解后再加进来
五。 尝试不同分类算法
决策树往往在类别不均衡数据上表现不错。
六。 尝试对模型进行惩罚
你可以使用相同的分类算法,但是使用一个不同的角度,比如你的分类任务是识别那些小类,那么可以对分类器的小类样本数据增加权值,降低大类样本的权值(这种方法其实是产生了新的数据分布,即产生了新的数据集,译者注),从而使得分类器将重点集中在小类样本身上。一个具体做法就是,在训练分类器时,若分类器将小类样本分错时额外增加分类器一个小类样本分错代价,这个额外的代价可以使得分类器更加“关心”小类样本。如penalized-SVM和penalized-LDA算法。
七。 尝试一个新的角度理解问题
我们可以从不同于分类的角度去解决数据不均衡性问题,我们可以把那些小类的样本作为异常点(outliers),因此该问题便转化为异常点检测(anomaly detection)与变化趋势检测问题(change detection)。
异常点检测即是对那些罕见事件进行识别。如通过机器的部件的振动识别机器故障,又如通过系统调用序列识别恶意程序。这些事件相对于正常情况是很少见的。
变化趋势检测类似于异常点检测,不同在于其通过检测不寻常的变化趋势来识别。如通过观察用户模式或银行交易来检测用户行为的不寻常改变。
参考博客:
SVM相关:http://www.cnblogs.com/xiangzhi/p/4638235.html
CNN相关:https://blog.csdn.net/heyc861221/article/details/80128212
样本不均衡解决方法:
https://blog.csdn.net/gdufs_phc/article/details/80044173
https://blog.csdn.net/weixin_38111819/article/details/79214815
感谢以上作者。
