

python基础---->常用模块
一、前言:
模块:用一部分代码实现了某个功能的代码集合,类似于函数式编程,定义一个函数完成某个功能呢,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成;
模块分为三种:自定义模块、第三方模块、内置模块
二、sys模块
用于提供对Python解释器相关的操作:
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称 7 sys.stdin 输入相关 8 sys.stdout 输出相关 9 sys.stderror 错误相关
三、os模块
用于提供系统级别的操作:
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 os.curdir 返回当前目录: ('.') 4 os.pardir 获取当前目录的父目录字符串名:('..') 5 os.makedirs('dir1/dir2') 可生成多层递归目录 6 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname 8 os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 10 os.remove() 删除一个文件 11 os.rename("oldname","new") 重命名文件/目录 12 os.stat('path/filename') 获取文件/目录信息 13 os.sep 操作系统特定的路径分隔符,win下为"\\",Linux下为"/" 14 os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" 15 os.pathsep 用于分割文件路径的字符串 16 os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix' 17 os.system("bash command") 运行shell命令,直接显示 18 os.environ 获取系统环境变量 19 os.path.abspath(path) 返回path规范化的绝对路径 20 os.path.split(path) 将path分割成目录和文件名二元组返回 21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 os.path.isabs(path) 如果path是绝对路径,返回True 25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
四、time模块
常用表示时间方式: 时间戳,格式化的时间字符串,元组(struct_time)
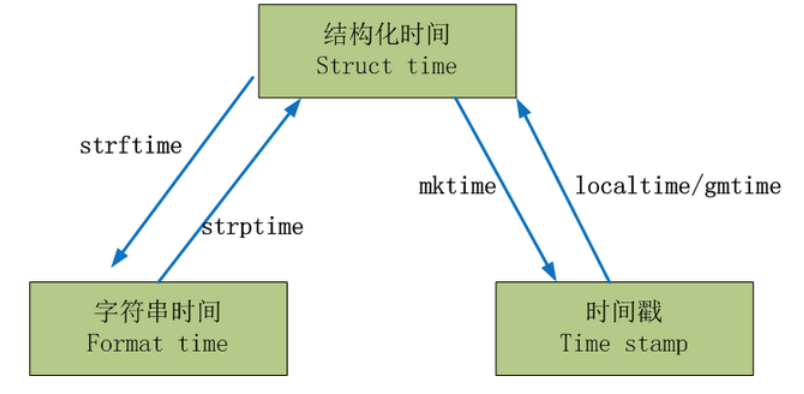
# struct_time转换成format_time %a 本地(locale)简化星期名称 %A 本地完整星期名称 %b 本地简化月份名称 %B 本地完整月份名称 %c 本地相应的日期和时间表示 %d 一个月中的第几天(01 - 31) %H 一天中的第几个小时(24小时制,00 - 23) %I 第几个小时(12小时制,01 - 12) %j 一年中的第几天(001 - 366) %m 月份(01 - 12) %M 分钟数(00 - 59) %p 本地am或者pm的相应符 一 %S 秒(01 - 61) 二 %U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 %w 一个星期中的第几天(0 - 6,0是星期天) 三 %W 和%U基本相同,不同的是%W以星期一为一个星期的开始。 %x 本地相应日期 %X 本地相应时间 %y 去掉世纪的年份(00 - 99) %Y 完整的年份 %Z 时区的名字(如果不存在为空字符) %% ‘%’字符
实例:结合sys,time模块实现进度条
进度百分比
import sys import time def view_bar(num, total): rate = float(num) / float(total) rate_num = int(rate * 100) r = '\r%d%%' % (rate_num, ) sys.stdout.write(r) sys.stdout.flush() if __name__ == '__main__': for i in range(0, 100): time.sleep(0.1) view_bar(i, 100)
五、random模块
random.random() # 0~1 随机浮点数 random.randint(1,100) #随机整数1~100 random.randrange(1,7) #随机整数,不包括7 random.choice('hello world') #随机获取一个字符 random.choice(['1','2','3',]) #随机获取一个元素 random.sample([1,2,3,4,5],3) #random.sample的函数原型为:random.sample(sequence, k)从指定序列中随机获取指定长度的片
实例:生成随机验证码
版本一:
import random def check_code(): check_code = "" for i in range(4): num = random.randint(0,9) #随机选择0~9 A1Z1 = chr(random.randint(65,90)) #随机选择A~Z a1z1 = chr(random.randint(97,122)) #随机选择a~z add = random.choice([num,A1Z1,a1z1]) #随机选择其中一个 check_code = "".join([code,str(add)]) #拼接一次选到的元素 return check_code #返回验证码# print(check_code())
版本二:
import random checkcode = '' for i in range(4): current = random.randrange(0,4) if current != i: temp = chr(random.randint(65,90)) else: temp = random.randint(0,9) checkcode += str(temp) print checkcode
五、re模块
python中re模块提供了正则表达式相关操作
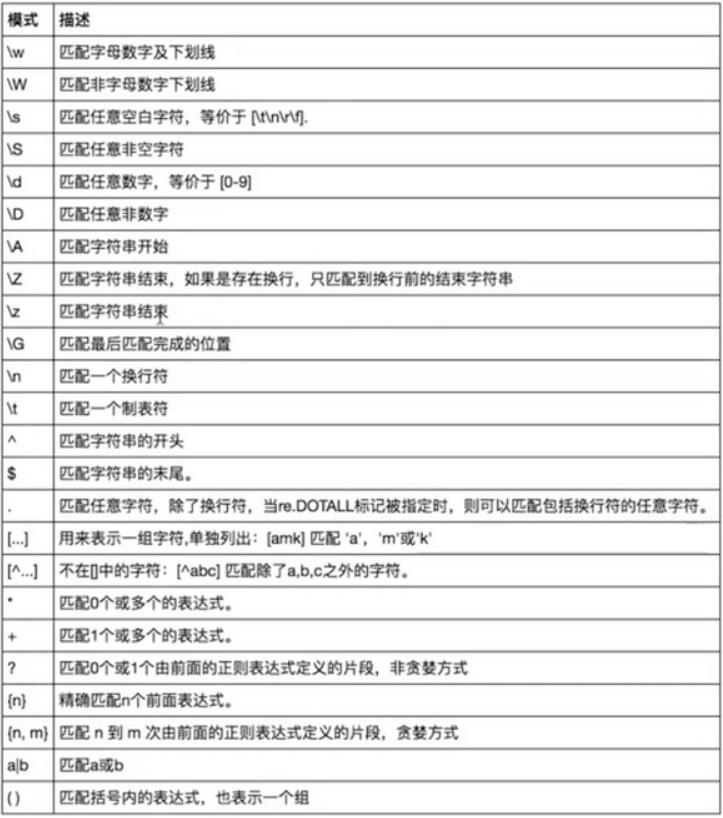
1 次数: 2 * 重复零次或更多次 3 + 重复一次或更多次 4 ? 重复零次或一次 5 {n} 重复n次 6 {n,} 重复n次或更多次 7 {n,m} 重复n到m次
其中提供的方法有:
match、search、findall、sub、split
import re #1 print(re.findall('e','clint love you') ) #['e', 'e'],返回所有满足匹配条件的结果,放在列表里 #2 print(re.search('e','clint love you').group()) #e,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 #3 print(re.match('e','clint love you')) #None,同search,不过在字符串开始处进行匹配,完全可以用search+^代替match #4 print(re.split('[ab]','abcd')) #['', '', 'cd'],先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割 #5 print('===>',re.sub('c','C','clint love you')) #===> Clint love you,不指定n,默认替换所有 print('===>',re.sub('l','L','clint love you',1)) #===> cLint love you print('===>',re.subn('c','C','clint love you')) #===> ('Alex mAke love', 2),结果带有总共替换的个数 #6 obj=re.compile('\d{2}') print(obj.search('abc123eeee').group()) #12 print(obj.findall('abc123eeee')) #['12'],重用了obj
几个匹配的实用例子:


# 邮箱表达式 email = r'^[a-aA-Z0-9_-]+@[a-aA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$' # 例如: # clint1801@163.com # 472400995@qq.com # s180231943@stu.cqupt.edu.cn 企业邮箱 ''' 你会发现 后面 \. 这是什么意思? 因为 . 表示匹配任意除换行符"\n"外的字符,而我们要匹配邮箱中的 . 所以 需要用到 \ \ 表示转义字符 注: 小括号():匹配小括号内的字符串 中括号[]:匹配字符组内的字符 大括号{}:匹配的次数 '''
# 手机号表达式 phone = r'^1[3578]\d{9}$'
IP的正则表达式:
这里讲的是IPv4的地址格式,总长度 32位=4段*8位,每段之间用 . 分割, 每段都是0-255之间的十进制数值。
将0-255用正则表达式表示,可以分成一下几块来分别考虑:
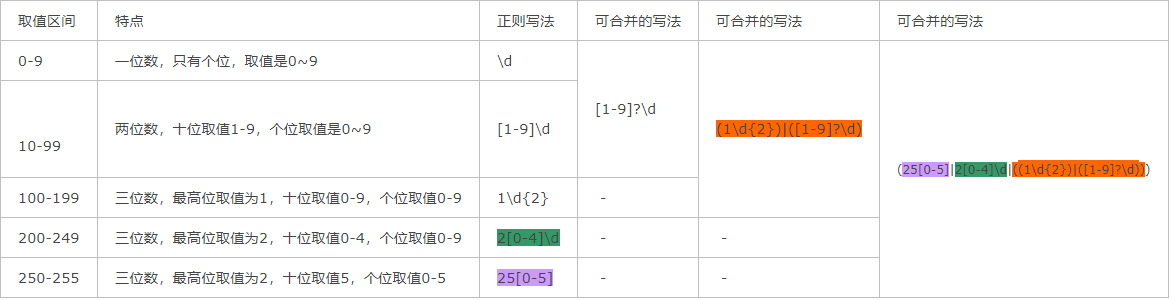
IP地址格式可表示为:XXX.XXX.XXX.XXX,XXX取值范围是0-255,前三段加一个.重复了三次,再与最后一段合并 或者 前一段与加 . 重复三次的后三段合并,组成IP地址的完整格式。
# IP地址 正则表达如下: 一、 ip =r'^((25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))\.){3}(25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))$' 二、 ip = r'^(25[0-5]|2[0-4]\d|[0-1]?\d?\d)(\.(25[0-5]|2[0-4]\d|[0-1]?\d?\d)){3}$'
六、shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length]) 将文件内容拷贝到另一个文件中
import shutil shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst) 拷贝文件
shutil.copyfile('f1.log', 'f2.log')
shutil.copymode(src, dst) 仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log')
shutil.copystat(src, dst) 仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copymode('f1.log', 'f2.log')
shutil.copy(src, dst) 拷贝文件和权限
shutil.copymode('f1.log', 'f2.log')
shutil.copy2(src, dst) 拷贝文件和状态信息
shutil.copy2('f1.log', 'f2.log')
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None) 递归的去拷贝文件夹
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
shutil.rmtree(path[, ignore_errors[, onerror]]) 递归的去删除文件
shutil.rmtree('folder1')
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
# 将 /DjangoProJ/a/test 下的文件打包放置当前程序目录 import shutil ret = shutil.make_archive("cc", 'gztar', root_dir='/DjangoProJ/a/test') # 将 /DjangoProJ/a/test 下的文件打包放置 /DjangoProJ/a/目录 import shutil ret = shutil.make_archive("/DjangoProJ/a/cc", 'gztar', root_dir='/DjangoProJ/a/test ')
七、hashlib模块
用于加密相关的操作,代替了md5模块和sha模块,主要提供 sha1, sha224, sha256, sha384, sha512, blake2b, blake2s和MD5等;
特点:
1.内容相同则hash运算结果相同,内容改变则hash值则改变
2.不可逆推
3.相同算法:无论校验多长的数据,得到的哈希值长度固定。
import hashlib # ######## md5 ######## hash = hashlib.md5(bytes('898oaFs09f',encoding="utf-8")) hash.update(bytes('admin',encoding="utf-8")) print(hash.hexdigest())
八、json和pickle模块
前言
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化
为什么要序列化?
持久保存状态:
'状态'会以各种有结构的数据类型形式被保存在内存中;
内存是无法永久保存数据的,程序运行了一段时间,断电或者重启内存则会清空程序这段段时间保存的数据;
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),下次程序执行能够从文件中载入之前的数据继续执行,这就是序列化。
跨平台数据交互:
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling;
Python中用于序列化的两个模块:json(用于【字符串】和 【python基本数据类型】 间进行转换)、pickle(用于【python特有的类型】 和 【python基本数据类型】间进行转换)
Json有四个功能:dumps、dump、loads、load
pickle也有四个功能:dumps、dump、loads、load
json使用:
import json dic={'name':'clint','age':18,'sex':'男'} print(type(dic)) #<class 'dict'> j=json.dumps(dic) print(type(j)) #<class 'str'> f=open('序列化对象','w') json.dump(dic,f) f.close()
序列化和反序列化
import json # 序列化 info = {'name':'clint','age':'18'} with open('a','w') as f: f.write(json.dumps(info)) # 反序列化 with open('a','r') as f: info = json.loads(f.read()) print(info)
pickle使用:
import pickle dic={'name':'clint','age':18,'sex':'男'} print(type(dic)) #<class 'dict'> j=pickle.dumps(dic) print(type(j)) #<class 'bytes'> f=open('序列化对象_pickle','wb') #wb是写入bytes,j是'bytes' pickle.dump(dic,f) f.close() # 反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read()) # 等data=pickle.load(f) print(data['age'])
九、configparser模块
configparser用于生成和修改常见配置文档,其本质上是利用open来操作文件
1、获取所有节点
import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') ret = config.sections() print(ret)
2、获取指定节点所有键值对
import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') ret = config.items('section1') print(ret)
3、获取指定节点下所有键
import configparser config = configparser.ConfigParser() config.read('xxxooo', encoding='utf-8') ret = config.options('section1') print(ret)
4、增删改查节点
import configparser config = configparser.ConfigParser() config.read('example.ini',encoding = 'utf-8') #删除整个标题 config.remove_section('bitbucket.org') #删除标题下的option config.remove_option('topsecret.server.com','port') #添加一个标题 config.add_section('info') #在标题下添加options config.set('info','name','clint') #判断是否存在 print(config.has_section('info')) #True print(config.has_option('info','name')) #True #将修改的内容存入文件 config.write(open('new_example.ini','w'))
十、paramiko模块
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,fabric和ansible内部的远程管理就是使用paramiko
下载安装:
# paramiko 模块内部依赖pycrypto,所以先下载安装pycrypto pip3 install pycrypto pip3 install paramiko
使用:
# -*- coding:utf-8 -*- # @Author : Clint import paramiko ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('192.168.178.1', 8000, 'clint', '123456') stdin, stdout, stderr = ssh.exec_command('df') print(stdout.read()) ssh.close() # 执行命令 - 用户名+密码
十一、shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写,key必须为字符串,而值可以是python所支持的数据类型
import shelve f=shelve.open(r'sheve.txt') # f['stu1']={'name':'clint','age':18,'hobby':['basketball','sporting']} # f['stu2']={'name':'eve','age':18,'hobby':'watching movie'} print(f['stu1']['hobby']) f.close()
十二、logging模块
用于便捷记录日志且线程安全的模块,python的logging模块提供了标准的日志接口,通过它存储各种格式的日志,logging的日志可以分为 debug、info、warning、error、critical5个级别
# -*- coding:utf-8 -*- # @Author : Clint import logging logging.basicConfig(filename='log.log', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=10) logging.debug('debug') logging.info('info') logging.warning('warning') logging.error('error') logging.critical('critical') logging.log(10, 'log')
2019-05-18 10:01:23 AM - root - DEBUG -logg: debug 2019-05-18 10:01:23 AM - root - INFO -logg: info 2019-05-18 10:01:23 AM - root - WARNING -logg: warning 2019-05-18 10:01:23 AM - root - ERROR -logg: error 2019-05-18 10:01:23 AM - root - CRITICAL -logg: critical 2019-05-18 10:01:23 AM - root - DEBUG -logg: log

