

Flask------一些面试题
1.请手写一个flask的hello world。
hello.py中
#coding = utf-8 # 第一步:导入Flask类 from flask import Flask app = Flask(__name__) @app.route("/") def helloworld(): return "<h1>hello world</h1>" if __name__ == " __main__": app.run(debug=True)
2.Flask框架的优势及适用场景?
优势:
1.轻量;(Micro Framework)
2.简洁
3.扩展性好*
4 第三方库的选择面广,开发时可以结合自己喜欢用的轮子,也可以结合强大的python库
5.核心(werzeug和jinja2),jinja2就是指模板引擎。
应用场景:
适用于小型网站,适用于开发web服务的API;
开发大型网站也毫无压力,但是代码架构需要开发者自己设计;
Flask和Nosql数据库的结合优于django
3.Flask框架组件
flask_sqlalchemy:将Flask和SQLAlchemy很好的结合在一起,如django中的ORM操作
flask_script:用于生成命令,在项目根目录路径下使用命令;例如:python manage.py runserver
flask_migrate:用来实现数据库迁移(依赖flask_script)
flask-session:session放在redis里面
blinker:信号-触发信号
PS:# flask中的信号blinker 信号主要是让开发者可是在flask请求过程中定制一些行为。 或者说flask在列表里面预留了几个空列表,在里面存东西。 简言之,信号允许某个'发送者'通知'接收者'有事情发生了
4.Flask蓝图的作用
# blueprint把实现不同功能的module分开.也就是把一个大的App分割成各自实现不同功能的module.
# 在一个blueprint中可以调用另一个blueprint的视图函数, 但要加相应的blueprint名.
通常情况下,我是使用flask框架的项目组织结构是这样的:
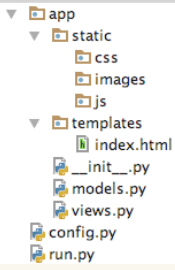
我们看看视图方法:
#views.py from app import app @app.route('/user/index') def index(): return 'user_index' @app.route('/user/show') def show(): return 'user_show' @app.route('/user/add') def add(): return 'user_add' @app.route('/admin/index') def adminindex(): return 'admin_index' @app.route('/admin/show') def adminshow(): return 'admin_show' @app.route('/admin/add') def adminadd(): return 'admin_add'
#从视图方法中,我们看到有6个视图,分别对应admin,user两个不同用户的3个功能index,add,show.
这样写显然没问题,但是明显与python提倡的模块化冲突;
当然根据Pythonic特点,我们肯定希望尽可能的把代码尽量的模块化,让我们的代码看起来更加的优雅和顺畅,这个时候flask.Blueprint(蓝图)就派上用场了
一个蓝图定义了可用于单个应用的视图,模板,静态文件等等的集合
上面的例子中只有两个组件(模块)admin,user,我们可以创建名为admin.py和user.py的两个文件,分别在里面创建两个蓝图的实例对象admin,user.
#admin.py from flask import Blueprint,render_template, request admin = Blueprint('admin',__name__) @admin.route('/index') def index(): return render_template('admin/index.html') @admin.route('/add') def add(): return 'admin_add' @admin.route('/show') def show(): return 'admin_show' #要想创建一个蓝图对象,你需要import flask.Blueprint()类并用参数name和import_name初始化。import_name通常用__name__,一个表示当前模块的特殊的Python变量,作为import_name的取值。
#user.py
from flask import Blueprint, render_template, redirect user = Blueprint('user',__name__) @user.route('/index') def index(): return render_template('user/index.html') @user.route('/add') def add(): return 'user_add' @user.route('/show') def show(): return 'user_show'
视图函数已经分开了 再看看view.py
#view.py from app import app from .admin import admin from .user import user #这里分别给app注册了两个蓝图admin,user #参数url_prefix='/xxx'的意思是设置request.url中的url前缀, #即当request.url是以/admin或者/user的情况下才会通过注册的蓝图的视图方法处理请求并返回 app.register_blueprint(admin,url_prefix='/admin') app.register_blueprint(user, url_prefix='/user')
再看看使用蓝图后的项目结构:
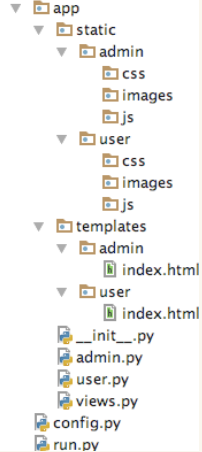
如果项目不大的话就没有必要使用蓝图了,我们甚至可以把除了所有css,js,html的代码都写到一个文件中去。
5.列举Flask使用的第三方组件
# 第三方组件:
Wtforms:快速创建前端标签、文本校验
dbutile:创建数据库连接池
gevent-websocket:实现websocket
# 自定义Flask组件
auth认证
参考flask-login
6.简述Flask上下文管理流程。
Flask中有两种上下文,请求上下文和应用上下文
request和session都属于请求上下文对象。
request:封装了HTTP请求的内容,针对的是http请求。举例:user = request.args.get('user'),获取的是get请求的参数。
session:用来记录请求会话中的信息,针对的是用户信息。举例:session['name'] = user.id,可以记录用户信息。还可以通过session.get('name')获取用户信息
current_app和g都属于应用上下文对象。
current_app:表示当前运行程序文件的程序实例。
g:处理请求时,用于临时存储的对象,每次请求都会重设这个变量。比如:我们可以获取一些临时请求的用户信息。
当调用app = Flask(_name_)的时候,创建了程序应用对象app;
request 在每次http请求发生时,WSGI server调用Flask.call();然后在Flask内部创建的request对象;
app的生命周期大于request和g,一个app存活期间,可能发生多次http请求,所以就会有多个request和g。
最终传入视图函数,通过return、redirect或render_template生成response对象,返回给客户端。
他们的区别:
请求上下文:保存了客户端和服务器交互的数据。 应用上下文:在flask程序运行过程中,保存的一些配置信息,比如程序文件名、数据库的连接、用户信息等
# a、简单来说,falsk上下文管理可以分为三个阶段: 1、'请求进来时':将请求相关的数据放入上下问管理中 2、'在视图函数中':要去上下文管理中取值 3、'请求响应':要将上下文管理中的数据清除# # b、详细点来说: 1、'请求刚进来': 将request,session封装在RequestContext类中 app,g封装在AppContext类中 并通过LocalStack将requestcontext和appcontext放入Local类中 2、'视图函数中': 通过localproxy--->偏函数--->localstack--->local取值 3、'请求响应时': 先执行save.session()再各自执行pop(),将local中的数据清除
7.Flask中g的作用
g:gloal
1.g对象是专门用来来保存用户数据的;
2.g对象在一次请求中的所有的代码的地方,都是可以使用的
# g是贯穿于一次请求的全局变量,当请求进来将g和current_app封装为一个APPContext类, # 再通过LocalStack将Appcontext放入Local中,取值时通过偏函数在LocalStack、local中取值; # 响应时将local中的g数据删除
8.如何编写flask的离线脚本
9.Flask中上下文管理主要是涉及到了哪些相关的类?并描述类主要的作用
RequestContext #封装进来的请求(赋值给ctx) AppContext #封装app_ctx LocalStack #将local对象中的数据维护成一个栈(先进后出) Local #保存请求上下文对象和app上下文对象
10.为什么要Flask把Local对象中的值stack维护程一个列表
# 因为通过维护成列表,可以实现一个栈的数据结构,进栈出栈时只取一个数据,巧妙的简化了问题。 # 还有,在多app应用时,可以实现数据隔离;列表里不会加数据,而是会生成一个新的列表 # local是一个字典,字典里key(stack)是唯一标识,value是一个列表
11.Flask中多app应用如何编写?
请求进来时,可以根据URL的不同,交给不同的APP处理。蓝图也可以实现
#app1 = Flask('app01') #app2 = Flask('app02') #@app1.route('/index') #@app2.route('/index2')
源码中在DispatcherMiddleware类里调用app2.__call__,
原理其实就是URL分割,然后将请求分发给指定的app。
之后app也按单app的流程走。就是从app.__call__走。
12.在Flask中实现WebSocket需要什么组件?
gevent-websocet
13.wtforms组件的作用?
定义:WTForms是一个支持多个web框架的form组件,主要用于对用户请求数据进行验证。
两种导入方式:
from wtforms import Form from flask_wtf import FlaskForm 需要设置csrf
安装:
pip3 install wtforms
作用:
快速创建前端标签、文本校验:如django的ModelForm
14.Flask框架默认的session处理机制?
15.解释Flask框架中Local对象和threadinglocal对象的区别?
# a.threading.local
作用:为每个线程开辟一块空间进行数据存储(数据隔离)。
问题:自己通过字典创建一个类似于threading.local的东西。 storage = { 4740: {val: 0}, 4732: {val: 1}, 4731: {val: 3}, }
# b.自定义Local对象
作用:为每个线程(协程)开辟一块空间进行数据存储(数据隔离)。
class Local(object): def __init__(self): object.__setattr__(self, 'storage', {}) def __setattr__(self, k, v): ident = get_ident() if ident in self.storage: self.storage[ident][k] = v else: self.storage[ident] = {k: v} def __getattr__(self, k): ident = get_ident() return self.storage[ident][k] obj = Local() def task(arg): obj.val = arg obj.xxx = arg print(obj.val) for i in range(10): t = Thread(target=task, args=(i,)) t.start()
16.SQLAlchemy中的session和scoped_session的区别?
# Session:
由于无法提供线程共享功能,开发时要给每个线程都创建自己的session
打印sesion可知他是sqlalchemy.orm.session.Session的对象
# scoped_session:
为每个线程都创建一个session,实现支持线程安全
在整个程序运行的过程当中,只存在唯一的一个session对象。
创建方式:通过本地线程Threading.Local()
# session=scoped_session(Session)
创建唯一标识的方法(参考flask请求源码)
17.SQLAlchemy如何执行原生SQL?
# 使用execute方法直接操作SQL语句(导入create_engin、sessionmaker)
engine=create_engine('mysql://root:pwd@127.0.0.1/database?charset=utf8')
DB_Session = sessionmaker(bind=engine)
session = DB_Session()
session.execute('select * from table...;')
18.ORM的实现原理?
# ORM的实现基于以下三点
映射类:描述数据库表结构,
映射文件:指定数据库表和映射类之间的关系
数据库配置文件:指定与数据库连接时需要的连接信息(数据库、登录用户名、密码or连接字符串)
19.DBUtils模块的作用?
# DBUtils是数据库连接池模块
使用模式:
1、为每个线程创建一个连接,连接不可控,需要控制线程数
2、创建指定数量的连接在连接池,当线程访问的时候去取,不够了线程排队,直到有人释放*
两种写法:
1.用静态方法装饰器,通过直接执行类的方法来连接使用数据库;
2.通过实例化对象,通过对象调用方法使用语句;
20.SQLAlchemy中的如何为表设置引擎和字符编码?
sqlalchemy设置编码字符集,一定要在数据库访问的URL上增加'charset=utf8',否则数据库的连接就不是'utf8'的编码格式
1. 设置引擎编码方式为utf8:
engine = create_engine('mysql://root:root@localhost:3306/test2?charset=utf8',echo=True)
2. 设置数据库表编码方式为utf8:
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/sqldb01?charset=utf8")
class UserType(Base): __tablename__ = 'usertype' i d = Column(Integer, primary_key=True) caption = Column(String(50), default='管理员') # 添加配置设置编码 __table_args__ = { 'mysql_charset':'utf8' }
这样生成的SQL语句就自动设置数据表编码为utf8了,__table_args__还可设置存储引擎、外键约束等等信息。
21.SQLAlchemy中如何设置联合唯一索引
通过'UniqueConstraint'字段来设置联合唯一索引
__table_args=(UniqueConstraint('h_id','username',name='_h_username_uc'))
#h_id和username组成联合唯一约束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号