Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context(论文)
Transformer模型能够学习长范围依赖,但是在语言模型中受到固定长度上下文限制,本文提出了一个新的结构:Transformer-XL。能够学习超过固定长度的依赖,同时保持了时间的连贯性,整体创新包括一个循环机制和一个新的位置编码方法。
存在的问题以及解决的方案:
在语言模型中构建长范围依赖是至关重要的,最简单的方法是提供足够的内存和计算,将全部文本一次性扔到transformer网络中解码,但这并不符合实际应用。第二种比较常规的方法是将训练文本切分为多个段落,每个段落分别送入网络中训练,但该方法仅仅可以构建段落长度大小的上下文依赖(一般只要几百个字符大小),同时段落边界以及不同段落之间不能建立这种依赖关系。本文提出的方法是重复利用隐藏状态,即从内存中提取部分上一个段落的隐藏状态和当前段落建立上下文依赖,同时对这些隐藏状态进行相对位置编码,防止时间上的不连续性。
原始Transformer的训练和评估:
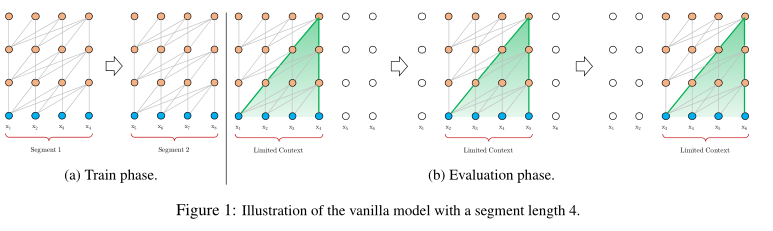
下图a表示原始transformer模型在训练过程中将输入文本切分为不同段落,每次训练仅仅构建段落内部的上下文。
图b表示在评估过程中原始transformer每次输入大小和训练时相同,但是每次只会预测出该段最后一个位置,在预测下一个位置时输入仅仅向右移动一个位置,然后以相同长度再次解码。整个过程的优点是一定程度上缓解了不同段落之间的关联性,同时扩大了字符相关性的最大长度。但该方法极大的缺点在于每次都输入较大的长度预测一个位置的结果,需要大量的计算资源,解码速度慢。
Transformer-XL中状态的重复利用(循环机制):

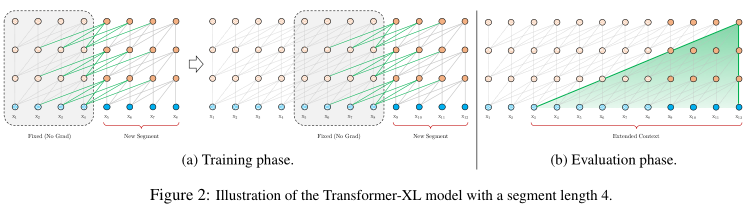
在n-1层中,前一个段落的隐藏状态和当前段落的隐藏状态concat起来,并且前一个段落的隐藏状态不计算梯度。 然后注意力的输入Q向量只由当前段落生成,K和V向量由concat后的总隐藏状态生成。 最后Q、K、V向量进行后续计算得到第n层的输入。注意力机制的计算量和复杂度变高了
疑问:应该是建立不同批量之间的联系吧,这样做不是同一个输入批量在不同层中的流动嘛
如下图a,transformer-XL在训练期间对固定长度的输入段落计算得到隐藏状态,同时通过缓存(cache)将当前段落的隐藏状态存储起来和下一个段落建立上下文联系。模型计算梯度的范围还是段落大小,但通过缓存机制可以在计算时建立更长范围的联系。有效上下文可以远远超出两个部分。
如图b,在评估阶段,transformer-XL可以再次利用前一段的隐藏状态,不用像原始transformer那样从头开始计算,可以加快解码速度。这个不完全明白呀,怎么去解码的?
Transformer-XL中相对位置编码:
位置编码为模型提供时间线索和收集信息的偏差。U是绝对位置编码,E是单词嵌入,在transformer中是直接将两者相加。不同段落输入时词嵌入向量不同,但是位置编码都是相同的,这就导致不同段落之间的位置关系不能区分,缓存机制不能建立时间的统一性,不能保持位置信息一致性。

q向量去注意k向量时不需要知道k向量的绝对位置,只需要他们之间的相对位置信息。
输入等于词嵌入向量和位置编码相加(E+U),那么q和k等于(E+U)W,注意力分数A等于q乘k的转置,
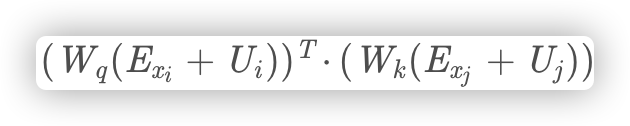
因式分解得到下面的结果:

在Transformer-XL中,将k向量的绝对位置编码换为相对位置编码,u和v分别代替c和d中的WqU(q的位置嵌入信息),u和v都是1xd的可训练参数,对不同单词的注意偏向保持一致。最后对k向量中词嵌入向量和相对位置向量用不同的权重矩阵W来映射。

最后整体逻辑:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号