Branchformer
创新点:
- 为了改善模型性能,在ASR任务中一种有效的方法是融合全局和局部特征,为了使模型更加灵活,本文提出的方法不同与Comformer。
- 通过实验发现,模型对局部和全局特征提取在每一层发挥了不同的作用,并发现不同层局部和全局重要程度不同。
模型结构图:
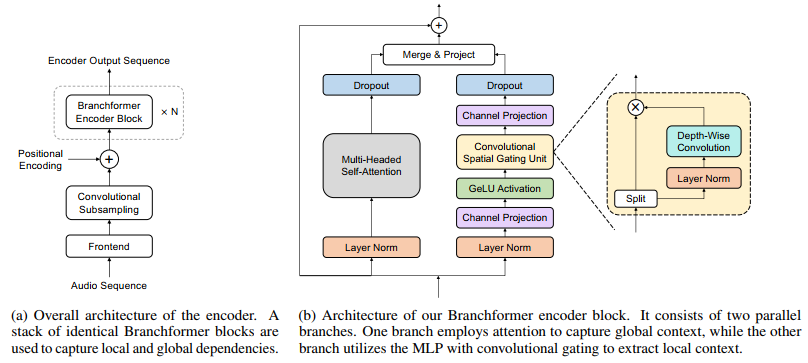
通过模型结构图可以发现,Branchformer和Comformer结构的不同,Branchformer是将全局和局部特征并行提取,相互之间是独立的,并且关于局部特征的提取是原则了cgMLP方法,两种特征最后可以通过不同方式进行结合。
比较重要的实验结果:
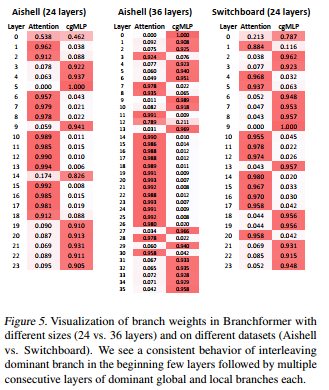
根据作者的实验可以发现在不同大小的模型中,关于注意力获取的全局信息和cgMLP获得的局部注意力对模型不同层提取的特征重要程度有很大的差异。
关于cgMLP代码:
import torch from espnet.nets.pytorch_backend.nets_utils import get_activation from espnet.nets.pytorch_backend.transformer.layer_norm import LayerNorm class ConvolutionalSpatialGatingUnit(torch.nn.Module): """Convolutional Spatial Gating Unit (CSGU).""" def __init__( self, size: int, #2048 kernel_size: int, #31 dropout_rate: float, use_linear_after_conv: bool, gate_activation: str, ): super().__init__() n_channels = size // 2 # split input channels self.norm = LayerNorm(n_channels) self.conv = torch.nn.Conv1d( n_channels, n_channels, kernel_size, 1, (kernel_size - 1) // 2, #15 groups=n_channels, # ) if use_linear_after_conv: self.linear = torch.nn.Linear(n_channels, n_channels) else: self.linear = None if gate_activation == "identity": self.act = torch.nn.Identity() else: self.act = get_activation(gate_activation) self.dropout = torch.nn.Dropout(dropout_rate) def espnet_initialization_fn(self): torch.nn.init.normal_(self.conv.weight, std=1e-6) torch.nn.init.ones_(self.conv.bias) if self.linear is not None: torch.nn.init.normal_(self.linear.weight, std=1e-6) torch.nn.init.ones_(self.linear.bias) def forward(self, x, gate_add=None): """Forward method Args: x (torch.Tensor): (N, T, D) gate_add (torch.Tensor): (N, T, D/2) Returns: out (torch.Tensor): (N, T, D/2) """ x_r, x_g = x.chunk(2, dim=-1) #chunk(2,dim=-1)表示将x以倒数第二个维度切分为2份 x_g = self.norm(x_g) # (N, T, D/2) x_g = self.conv(x_g.transpose(1, 2)).transpose(1, 2) # (N, T, D/2) if self.linear is not None: x_g = self.linear(x_g) if gate_add is not None: x_g = x_g + gate_add x_g = self.act(x_g) out = x_r * x_g # (N, T, D/2) #两份进行逐元素乘法,对应元素相乘 out = self.dropout(out) return out class ConvolutionalGatingMLP(torch.nn.Module): """Convolutional Gating MLP (cgMLP).""" def __init__( self, size: int, #256 linear_units: int, #2048 kernel_size: int, #31 dropout_rate: float, use_linear_after_conv: bool, #false gate_activation: str, ): super().__init__() self.channel_proj1 = torch.nn.Sequential( torch.nn.Linear(size, linear_units), torch.nn.GELU() ) self.csgu = ConvolutionalSpatialGatingUnit( size=linear_units, #2048 kernel_size=kernel_size, #31 dropout_rate=dropout_rate, use_linear_after_conv=use_linear_after_conv, gate_activation=gate_activation, ) self.channel_proj2 = torch.nn.Linear(linear_units // 2, size) def forward(self, x, mask): if isinstance(x, tuple): xs_pad, pos_emb = x else: xs_pad, pos_emb = x, None xs_pad = self.channel_proj1(xs_pad) # size -> linear_units xs_pad = self.csgu(xs_pad) # linear_units -> linear_units/2 xs_pad = self.channel_proj2(xs_pad) # linear_units/2 -> size if pos_emb is not None: out = (xs_pad, pos_emb) else: out = xs_pad return out

 浙公网安备 33010602011771号
浙公网安备 33010602011771号