Batch Normalization & layer normalization
BN回顾
首先Batch Normalization 中的Normalization被称为标准化,通过将数据进行平和缩放拉到一个特定的分布。BN就是在batch维度上进行数据的标准化。BN的引入是用来解决 internal covariate shift 问题,即训练迭代中网络激活的分布的变化对网络训练带来的破坏。BN通过在每次训练迭代的时候,利用minibatch计算出的当前batch的均值和方差,进行标准化来缓解这个问题。虽然How Does Batch Normalization Help Optimization 这篇文章探究了BN其实和Internal Covariate Shift (ICS)问题关系不大,本文不深入讨论,这个会在以后的文章中细说。
一般来说,BN有两个优点:
降低对初始化、学习率等超参的敏感程度,因为每层的输入被BN拉成相对稳定的分布,也能加速收敛过程。
应对梯度饱和和梯度弥散,主要是对于使用sigmoid和tanh的激活函数的网络。
当然,BN的使用也有两个前提:
minibatch和全部数据同分布。因为训练过程每个minibatch从整体数据中均匀采样,不同分布的话minibatch的均值和方差和训练样本整体的均值和方差是会存在较大差异的,在测试的时候会严重影响精度。
batchsize不能太小,否则效果会较差,论文给的一般性下限是32。
再来回顾一下BN的具体做法:

训练的时候:使用当前batch统计的均值和方差对数据进行标准化,同时优化优化gamma和beta两个参数。另外利用指数滑动平均收集全局的均值和方差。
测试的时候:使用训练时收集全局均值和方差以及优化好的gamma和beta进行推理。
可以看出,要想BN真正work,就要保证训练时当前batch的均值和方差逼近全部数据的均值和方差。
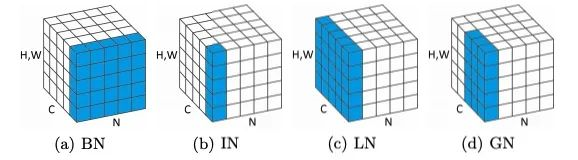
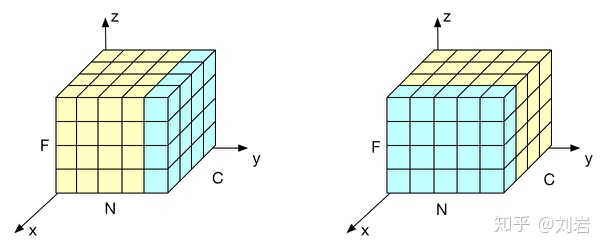
BN如右侧所示,它是取不同样本的同一个通道的特征做归一化;LN则是如左侧所示,它取的是同一个样本的不同通道做归一化。
关于LN具体了解:
https://zhuanlan.zhihu.com/p/54530247

 浙公网安备 33010602011771号
浙公网安备 33010602011771号