SpringCloud-Netflix( Hystrix)
SpringCloud-Netflix(Hystrix)
However, when a microservice is called, a microservice may go down, or it cannot return resources for a long time due to network reasons, then the entire system resources will be quickly consumed, or even cause an avalanche of the entire system service. So in order to solve these problems, service circuit breakers and service degradation are introduced
- 【Service circuit breaker】:If the target service invocation time is slow or there are a large number of timeouts, subsequent requests will not continue to request the target service, but will directly return the downgraded logic. When the target service is restored, the circuit breaker mechanism is automatically shut down.
- 【Service degradation】:In short, when the master solution doesn't work, we switch to the backup solution. For example, when service A calls service B, and service B goes down, the request fails. Then we can return a message like "system busy" or "service under development" to the user, which will degrade the data service. In fact, downgrading is also divided into active downgrade and passive downgrade
- 【Proactive downgrade】:When a service has a lot of concurrency, shut down some irrelevant services。
- 【Passive degrading】:If the service call is abnormal, then we return an alternate piece of data, as in the example above. Back System Busy。
In order to solve the problem of service circuit breaker in a distributed architecture, SpringCloud Netflix integrates a hystrix component, which is used to automatically open the circuit breaker of a service if the call to a service exceeds a certain number of times and the failure rate exceeds a certain value, and a fallback written by us is executed. In this article, I will talk about its use and design principles, and after talking about this set of Netflix use, I will talk about its source code.
Usage of Hystrix(alone)
我们现在有个统一的api工程,当前端调用api工程的时候,api使用resttemplate远程调用订单的微服务,然后我们在订单的微服务中让线程睡3s(用来模拟服务端返回慢),然后我们设置响应时间为1s,看看加入hystrix后会不会熔断。
统一的api模块中增加hystrix的pom
![]() View Code
View Code<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>订单的微服务模块中增加一个接口模拟订单创建,并且在接口中睡3s
![]() View Code@RestController public class OrderController { @GetMapping("orders") public String hystrixDemo(){ try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } return "success"; } }
View Code@RestController public class OrderController { @GetMapping("orders") public String hystrixDemo(){ try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } return "success"; } }在统一的api中远程调用订单模块,并且增加hystrix配置(在5s内,超过20次请求,并且失败率超过50%,则默认触发熔断)
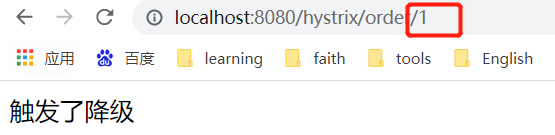
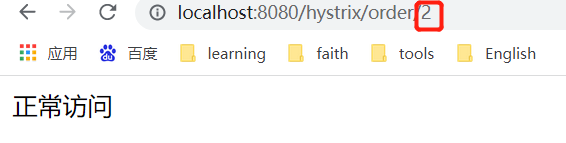
![]() View Code@RestController public class HystrixController { @Autowired private RestTemplate restTemplate; // HystrixCommandProperties @HystrixCommand(commandProperties = { //最小请求阈值(当在配置时间窗口内达到此数量的失败后,进行短路) @HystrixProperty(name="circuitBreaker.requestVolumeThreshold",value ="10"), //睡眠时间窗口(触发熔断后等待的时间) @HystrixProperty(name="circuitBreaker.sleepWindowInMilliseconds",value ="5000"), //错误百分比 @HystrixProperty(name="circuitBreaker.errorThresholdPercentage",value ="50") },fallbackMethod = "fallback") @GetMapping("/hystrix/order/{num}") public String hystrix(@PathVariable("num") int num){ if (num%2==0){ return "正常访问"; } return restTemplate.getForObject("http://localhost:9092/orders",String.class); } //我们在orderService中睡眠了3s,而默认的超时时间是1s,那这个时候就自动触发了服务降级 public String fallback(int num){ return "触发了降级"; } }
View Code@RestController public class HystrixController { @Autowired private RestTemplate restTemplate; // HystrixCommandProperties @HystrixCommand(commandProperties = { //最小请求阈值(当在配置时间窗口内达到此数量的失败后,进行短路) @HystrixProperty(name="circuitBreaker.requestVolumeThreshold",value ="10"), //睡眠时间窗口(触发熔断后等待的时间) @HystrixProperty(name="circuitBreaker.sleepWindowInMilliseconds",value ="5000"), //错误百分比 @HystrixProperty(name="circuitBreaker.errorThresholdPercentage",value ="50") },fallbackMethod = "fallback") @GetMapping("/hystrix/order/{num}") public String hystrix(@PathVariable("num") int num){ if (num%2==0){ return "正常访问"; } return restTemplate.getForObject("http://localhost:9092/orders",String.class); } //我们在orderService中睡眠了3s,而默认的超时时间是1s,那这个时候就自动触发了服务降级 public String fallback(int num){ return "触发了降级"; } }我们这里用num来控制正常访问,如果输入的num是2则返回正常访问。如果是1的话则会真正调用订单的微服务,而订单的微服务睡了3s所以肯定会对服务进行降级。
当我们连续调用订单模块之后,我们发现,使用num=2进行正常调用,则发现订单模块的微服务已经被熔断了。因为我们上面配置了5s,5s后我们再次请求num=2发现服务又自动恢复了。



Usage of Hystrix(integrate with openfeign)
我们还是使用统一api模块去调用各个微服务。
首先还是在统一的api模块中引入hystrix的pom
![]() View Code
View Code<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>并且在配置文件中加上【feign.hystrix.enabled=true】
新建一个类(实现前面继承商品接口的标注FeignClient注解的类),并且重写方法,用于返回服务降级的信息
![]() View Code//当feign触发了降级之后,他需要返回降级的消息,这个类会在标注了FeignClient的类上作为属性 public class GoodsServiceFallBack implements IGoodsServiceFeignClient { @Override public String getGoodsById(int id) { return "查询商品信息异常,Hystrix触发了降级保护机制"; } }
View Code//当feign触发了降级之后,他需要返回降级的消息,这个类会在标注了FeignClient的类上作为属性 public class GoodsServiceFallBack implements IGoodsServiceFeignClient { @Override public String getGoodsById(int id) { return "查询商品信息异常,Hystrix触发了降级保护机制"; } }并且把这个类交给spring进行托管。
![]() View Code@Configuration public class HystrixConfiguration { @Bean public GoodsServiceFallBack goodsServiceFallBack() { return new GoodsServiceFallBack(); } }
View Code@Configuration public class HystrixConfiguration { @Bean public GoodsServiceFallBack goodsServiceFallBack() { return new GoodsServiceFallBack(); } }在商品模块中用外面传递的数字模拟控制服务响应慢
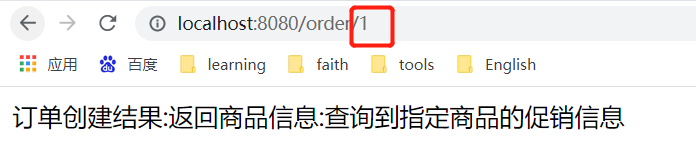
![]() View Code/** * 根据ID查询商品信息 * @return */ @GetMapping("/goods") public String getGoodsById(int id){ log.info("收到请求,端口为:{}",port); //这里也是为了模拟服务响应超时 if (id%2==0){ try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } } return "返回商品信息"; }
View Code/** * 根据ID查询商品信息 * @return */ @GetMapping("/goods") public String getGoodsById(int id){ log.info("收到请求,端口为:{}",port); //这里也是为了模拟服务响应超时 if (id%2==0){ try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } } return "返回商品信息"; }当我们对一个服务多次访问失败的情况下,这个服务就会自动降级


Principle of Hystrix
Hystrix默认10s内达到20次请求,并且超过50%的请求是失败的,那么就会触发熔断,熔断后,在5s内,请求不会落到目标请求上去,而是直接返回fallback给到客户端。
熔断状态:
Open: 意味着接下来的请求不会发送到服务端 ,而是直接返回fallback
Closed:服务通信正常
Half-Open:熔断的自动恢复机制
熔断的原理:
当一个请求过来后,判断是否触发了熔断,如果已经触发了熔断,那就返回服务降级的逻辑,如果没有那就对当前时间窗口(底层使用了滑动窗口对数据进行了统计)的健康请求数量进行检查,判断是否大于20次,如果大于20次,那就去汇总总的错误数量,如果大于50%则开启熔断


 浙公网安备 33010602011771号
浙公网安备 33010602011771号