消息中间件-RabbitMq(高可用方案&集群搭建)
消息中间件-RabbitMq(高可用方案&集群搭建)
上一篇我们搭建了rabbit单机节点,我们知道很多个开发小组都可以通过rabbit开发(因为它有不同的虚拟主机),可是问题来了,如果rabbit宕机了,怎么玩?那自然而然就想到集群搭建了,而集群会产生一个新的问题,使用哪种方式做数据的共享,下面我们就会聊到这些问题,我们来搭建它,并且解决这个问题。也会说到内存和磁盘满了rabbit怎么告知我们,以及什么告知我们的机制。以下:
- 高可用集群搭建以及介绍方案
- 模拟停止某个节点看是否可以正常吞吐
- rabbit对于内存和磁盘的控制
搭建集群
rabbit提供的集群方案:
- cluster:
- 【普通模式】:有两种部署方式:【多机多节点、单机多节点】(下面会使用这种方式,因为服务器资源有限)
- 【问题】:
- 【不能够保障消息的万无一失】:因为我们的节点之间并没有持有真正的队列数据,而持有的是一个叫做【元数据】的东西,java客户端会帮你自动分发请求到任何一个节点,然而这些节点不一定刚好存储了你想要的东西,那当前节点就会根据他持有的元数据把你的请求分发到其他的节点,但是可能给你分发过去的节点宕机了,那你就无法获取你的数据。
- 元数据:【队列元数据】:队列的名称以及属性、【交换机】:名称以及属性 【绑定关系元数据】:交换机和队列、或者交换机和交换机 【虚拟主机】:虚拟主机中的各种绑定关系
- 【解决】:使用镜像方式
- 【优点】:速度快、所占空间少
- 【镜像模式】:每一个rabbit节点都存储相同的数据 【问题】:所占内存随着节点的个数增加,成比例增长 ,并且数据冗余(因为相同数据在不同的节点上)【解决】:有钱就行,换一个大一点内存的服务器
- 集群联邦(使得mq在不同的节点之间进行消息传递,而不需搭建集群,好处:不需要搭建集群、并且Erlang的版本不一样可以)他们就类似于插件,很少使用(所以不会写demo和展开)
- (Federation)【应用场景】:比如有三台mq,在不同的地方进行部署,北上广,那就可以使用这个,
- (Federation)【原理】:他在自己连接自己内部的交换机,当你发送想给你在北京想给上海的mq发送消息的时候,他会发送给自己本地,然后本地的federation插件会进行数据的传递,这样就减少了响应时间
- (shovel)他是不断的拉取别的节点上的数据。
【单机多节点开始搭建】:
- 【停止当前rabbit】:sudo systemctl stop rabbitmq-server
- 【启动第一个节点】:rabbitmq-server -detached
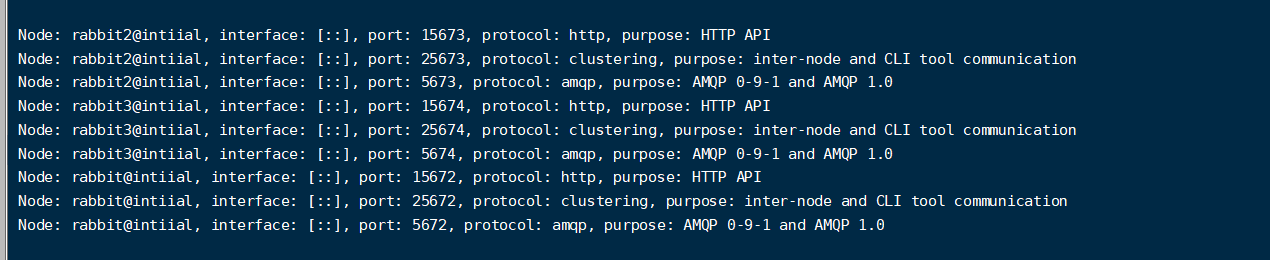
- 【启动第二个节点】:修改主机名称(rabbit2 )、修改默认端口(15673)
RABBITMQ_NODE_PORT=5673 RABBITMQ_SERVER_START_ARGS="-rabbitmq_managementlistener [{port,15673}]" RABBITMQ_NODENAME=rabbit2 rabbitmq-server -detached
- 【启动第三个节点】:修改主机名称(rabbit3 )、修改默认端口(15674)
RABBITMQ_NODE_PORT=5674 RABBITMQ_SERVER_START_ARGS="-rabbitmq_managementlistener [{port,15674}]" RABBITMQ_NODENAME=rabbit3 rabbitmq-server -detached
- 【将rabbit2加入集群】:
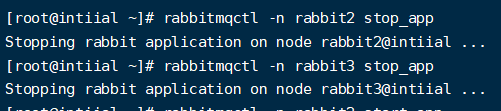
- # 停止 rabbit2 的应用 rabbitmqctl -n rabbit2 stop_app
- # 重置 rabbit2 的设置 rabbitmqctl -n rabbit2 reset
- # rabbit2 节点加入到rabbit的集群中 rabbitmqctl -n rabbit2 join_cluster rabbit --ram
- # 启动 rabbit2 节点 rabbitmqctl -n rabbit2 start_app
- 【将rabbit3加入集群】:
- # 停止 rabbit3 的应用 rabbitmqctl -n rabbit3 stop_app
- # 重置 rabbit3 的设置 rabbitmqctl -n rabbit3 reset
- # rabbit3 节点加入到 rabbit的集群中 rabbitmqctl -n rabbit3 join_cluster rabbit --ram
- # 启动 rabbit3 节点 rabbitmqctl -n rabbit3 start_app
- 使用【rabbitmqctl cluster_status】可以查询到集群状态
至此,集群搭建完毕
对集群的高可用进行检验(我们这里使用一个for循环去模拟生产者创建100个消息,然后一个消费者去获取数据,这个时候,我们随机停止一个节点,看一下时候消息依然收发正常 run)
生产者
![]() View Codepublic class ProducerCluster { public static void main(String[] args) { // 1、创建连接工厂 ConnectionFactory factory = new ConnectionFactory(); // 2、设置连接属性 factory.setUsername("admin"); factory.setPassword("admin"); factory.setVirtualHost("v1"); Connection connection = null; Channel channel = null; // 3、设置每个节点的链接地址和端口 Address[] addresses = new Address[]{ new Address("你的ip", 5672), new Address("你的ip", 5673), new Address("你的ip", 5674), }; try { // 开启/关闭连接自动恢复,默认是开启状态 factory.setAutomaticRecoveryEnabled(true); // 设置每100毫秒尝试恢复一次,默认是5秒:com.rabbitmq.client.ConnectionFactory.DEFAULT_NETWORK_RECOVERY_INTERVAL factory.setNetworkRecoveryInterval(100); factory.setTopologyRecoveryEnabled(false); // 4、使用连接集合里面的地址获取连接 connection = factory.newConnection(addresses, "生产者"); // 添加重连监听器 ((Recoverable) connection).addRecoveryListener(new RecoveryListener() { /** * 重连成功后的回调 * @param recoverable */ public void handleRecovery(Recoverable recoverable) { System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 已重新建立连接!"); } /** * 开始重连时的回调 * @param recoverable */ public void handleRecoveryStarted(Recoverable recoverable) { System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 开始尝试重连!"); } }); // 5、从链接中创建通道 channel = connection.createChannel(); /** * 6、声明(创建)队列 * 如果队列不存在,才会创建 * RabbitMQ 不允许声明两个队列名相同,属性不同的队列,否则会报错 * * queueDeclare参数说明: * @param queue 队列名称 * @param durable 队列是否持久化 * @param exclusive 是否排他,即是否为私有的,如果为true,会对当前队列加锁,其它通道不能访问,并且在连接关闭时会自动删除,不受持久化和自动删除的属性控制 * @param autoDelete 是否自动删除,当最后一个消费者断开连接之后是否自动删除 * @param arguments 队列参数,设置队列的有效期、消息最大长度、队列中所有消息的生命周期等等 */ channel.queueDeclare("queue1", true, false, false, null); for (int i = 0; i < 100; i++) { // 消息内容 String message = "Hello World " + i; try { // 7、发送消息 channel.basicPublish("", "queue1", null, message.getBytes()); } catch (AlreadyClosedException e) { // 可能连接已关闭,等待重连 System.out.println("消息 " + message + " 发送失败!"); i--; TimeUnit.SECONDS.sleep(2); continue; } System.out.println("消息 " + i + " 已发送!"); TimeUnit.SECONDS.sleep(2); } } catch (IOException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } finally { // 8、关闭通道 if (channel != null && channel.isOpen()) { try { channel.close(); } catch (IOException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } } // 9、关闭连接 if (connection != null && connection.isOpen()) { try { connection.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
View Codepublic class ProducerCluster { public static void main(String[] args) { // 1、创建连接工厂 ConnectionFactory factory = new ConnectionFactory(); // 2、设置连接属性 factory.setUsername("admin"); factory.setPassword("admin"); factory.setVirtualHost("v1"); Connection connection = null; Channel channel = null; // 3、设置每个节点的链接地址和端口 Address[] addresses = new Address[]{ new Address("你的ip", 5672), new Address("你的ip", 5673), new Address("你的ip", 5674), }; try { // 开启/关闭连接自动恢复,默认是开启状态 factory.setAutomaticRecoveryEnabled(true); // 设置每100毫秒尝试恢复一次,默认是5秒:com.rabbitmq.client.ConnectionFactory.DEFAULT_NETWORK_RECOVERY_INTERVAL factory.setNetworkRecoveryInterval(100); factory.setTopologyRecoveryEnabled(false); // 4、使用连接集合里面的地址获取连接 connection = factory.newConnection(addresses, "生产者"); // 添加重连监听器 ((Recoverable) connection).addRecoveryListener(new RecoveryListener() { /** * 重连成功后的回调 * @param recoverable */ public void handleRecovery(Recoverable recoverable) { System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 已重新建立连接!"); } /** * 开始重连时的回调 * @param recoverable */ public void handleRecoveryStarted(Recoverable recoverable) { System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 开始尝试重连!"); } }); // 5、从链接中创建通道 channel = connection.createChannel(); /** * 6、声明(创建)队列 * 如果队列不存在,才会创建 * RabbitMQ 不允许声明两个队列名相同,属性不同的队列,否则会报错 * * queueDeclare参数说明: * @param queue 队列名称 * @param durable 队列是否持久化 * @param exclusive 是否排他,即是否为私有的,如果为true,会对当前队列加锁,其它通道不能访问,并且在连接关闭时会自动删除,不受持久化和自动删除的属性控制 * @param autoDelete 是否自动删除,当最后一个消费者断开连接之后是否自动删除 * @param arguments 队列参数,设置队列的有效期、消息最大长度、队列中所有消息的生命周期等等 */ channel.queueDeclare("queue1", true, false, false, null); for (int i = 0; i < 100; i++) { // 消息内容 String message = "Hello World " + i; try { // 7、发送消息 channel.basicPublish("", "queue1", null, message.getBytes()); } catch (AlreadyClosedException e) { // 可能连接已关闭,等待重连 System.out.println("消息 " + message + " 发送失败!"); i--; TimeUnit.SECONDS.sleep(2); continue; } System.out.println("消息 " + i + " 已发送!"); TimeUnit.SECONDS.sleep(2); } } catch (IOException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } finally { // 8、关闭通道 if (channel != null && channel.isOpen()) { try { channel.close(); } catch (IOException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } } // 9、关闭连接 if (connection != null && connection.isOpen()) { try { connection.close(); } catch (IOException e) { e.printStackTrace(); } } } } }消费者
![]() View Codepublic class ConsumerCluster { public static void main(String[] args) { // 1、创建连接工厂 ConnectionFactory factory = new ConnectionFactory(); // 2、设置连接属性 factory.setUsername("admin"); factory.setPassword("admin"); factory.setVirtualHost("v1"); Connection connection = null; Channel channel = null; // 3、设置每个节点的链接地址和端口 Address[] addresses = new Address[]{ new Address("你的ip", 5672), new Address("你的ip", 5673), new Address("你的ip", 5674), }; try { // 开启/关闭连接自动恢复,默认是开启状态 factory.setAutomaticRecoveryEnabled(true); // 设置每100毫秒尝试恢复一次,默认是5秒:com.rabbitmq.client.ConnectionFactory.DEFAULT_NETWORK_RECOVERY_INTERVAL factory.setNetworkRecoveryInterval(100); // 4、从连接工厂获取连接 connection = factory.newConnection(addresses, "消费者"); // 添加重连监听器 ((Recoverable) connection).addRecoveryListener(new RecoveryListener() { /** * 重连成功后的回调 * @param recoverable */ public void handleRecovery(Recoverable recoverable) { System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 已重新建立连接!"); } /** * 开始重连时的回调 * @param recoverable */ public void handleRecoveryStarted(Recoverable recoverable) { System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 开始尝试重连!"); } }); // 5、从链接中创建通道 channel = connection.createChannel(); /** * 6、声明(创建)队列 * 如果队列不存在,才会创建 * RabbitMQ 不允许声明两个队列名相同,属性不同的队列,否则会报错 * * queueDeclare参数说明: * @param queue 队列名称 * @param durable 队列是否持久化 * @param exclusive 是否排他,即是否为私有的,如果为true,会对当前队列加锁,其它通道不能访问, * 并且在连接关闭时会自动删除,不受持久化和自动删除的属性控制。 * 一般在队列和交换器绑定时使用 * @param autoDelete 是否自动删除,当最后一个消费者断开连接之后是否自动删除 * @param arguments 队列参数,设置队列的有效期、消息最大长度、队列中所有消息的生命周期等等 */ channel.queueDeclare("queue1", true, false, false, null); // 7、定义收到消息后的回调 final Channel finalChannel = channel; DeliverCallback callback = new DeliverCallback() { public void handle(String consumerTag, Delivery message) throws IOException { System.out.println("收到消息:" + new String(message.getBody(), "UTF-8")); finalChannel.basicAck(message.getEnvelope().getDeliveryTag(), false); } }; // 8、监听队列 channel.basicConsume("queue1", false, callback, new CancelCallback() { public void handle(String consumerTag) throws IOException { } }); System.out.println("开始接收消息"); System.in.read(); } catch (IOException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } finally { // 9、关闭通道 if (channel != null && channel.isOpen()) { try { channel.close(); } catch (IOException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } } // 10、关闭连接 if (connection != null && connection.isOpen()) { try { connection.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
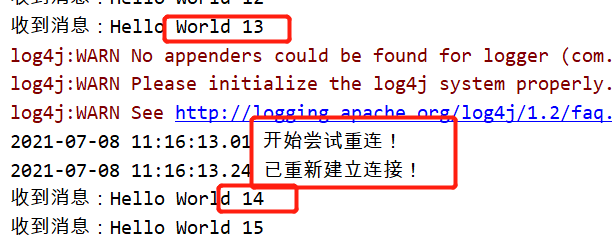
View Codepublic class ConsumerCluster { public static void main(String[] args) { // 1、创建连接工厂 ConnectionFactory factory = new ConnectionFactory(); // 2、设置连接属性 factory.setUsername("admin"); factory.setPassword("admin"); factory.setVirtualHost("v1"); Connection connection = null; Channel channel = null; // 3、设置每个节点的链接地址和端口 Address[] addresses = new Address[]{ new Address("你的ip", 5672), new Address("你的ip", 5673), new Address("你的ip", 5674), }; try { // 开启/关闭连接自动恢复,默认是开启状态 factory.setAutomaticRecoveryEnabled(true); // 设置每100毫秒尝试恢复一次,默认是5秒:com.rabbitmq.client.ConnectionFactory.DEFAULT_NETWORK_RECOVERY_INTERVAL factory.setNetworkRecoveryInterval(100); // 4、从连接工厂获取连接 connection = factory.newConnection(addresses, "消费者"); // 添加重连监听器 ((Recoverable) connection).addRecoveryListener(new RecoveryListener() { /** * 重连成功后的回调 * @param recoverable */ public void handleRecovery(Recoverable recoverable) { System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 已重新建立连接!"); } /** * 开始重连时的回调 * @param recoverable */ public void handleRecoveryStarted(Recoverable recoverable) { System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 开始尝试重连!"); } }); // 5、从链接中创建通道 channel = connection.createChannel(); /** * 6、声明(创建)队列 * 如果队列不存在,才会创建 * RabbitMQ 不允许声明两个队列名相同,属性不同的队列,否则会报错 * * queueDeclare参数说明: * @param queue 队列名称 * @param durable 队列是否持久化 * @param exclusive 是否排他,即是否为私有的,如果为true,会对当前队列加锁,其它通道不能访问, * 并且在连接关闭时会自动删除,不受持久化和自动删除的属性控制。 * 一般在队列和交换器绑定时使用 * @param autoDelete 是否自动删除,当最后一个消费者断开连接之后是否自动删除 * @param arguments 队列参数,设置队列的有效期、消息最大长度、队列中所有消息的生命周期等等 */ channel.queueDeclare("queue1", true, false, false, null); // 7、定义收到消息后的回调 final Channel finalChannel = channel; DeliverCallback callback = new DeliverCallback() { public void handle(String consumerTag, Delivery message) throws IOException { System.out.println("收到消息:" + new String(message.getBody(), "UTF-8")); finalChannel.basicAck(message.getEnvelope().getDeliveryTag(), false); } }; // 8、监听队列 channel.basicConsume("queue1", false, callback, new CancelCallback() { public void handle(String consumerTag) throws IOException { } }); System.out.println("开始接收消息"); System.in.read(); } catch (IOException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } finally { // 9、关闭通道 if (channel != null && channel.isOpen()) { try { channel.close(); } catch (IOException e) { e.printStackTrace(); } catch (TimeoutException e) { e.printStackTrace(); } } // 10、关闭连接 if (connection != null && connection.isOpen()) { try { connection.close(); } catch (IOException e) { e.printStackTrace(); } } } } }然后我们停止依次停止节点2 、3
结果是:他们从新连接后依旧收发正常(集群工作正常)
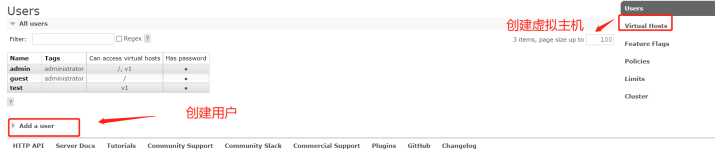
【镜像模式】:我们这里新创建一套,避免冲突
创建用户:test,把用户绑定到虚拟主机
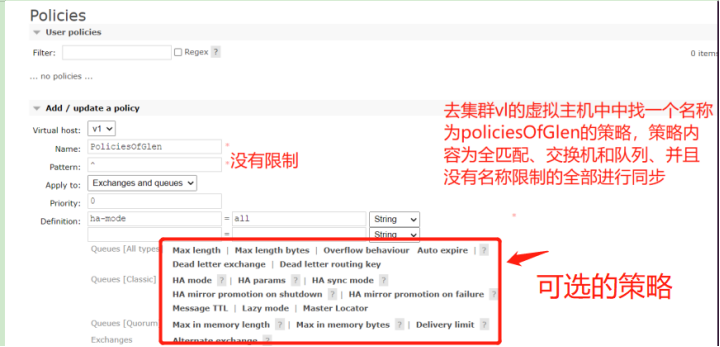
创建镜像策略
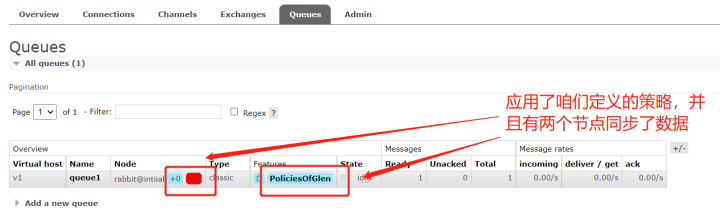
我们发现它自动进行了数据同步
现在各个节点的数据都是一样的了






内存控制
当内存使用超过配置的阈值或者磁盘剩余空间低于配置的阈值时,RabbitMQ 会暂时阻塞客户端的连接,并停止接收从客户端发来的消息,以此避免服务崩溃。当出现内存预警,可以使用【rabbitmqctl set_vm_memory_high_watermark <fractioion>】临时调整内存大小,一般设置为0.4,这里我们设置他为50m就报警【rabbitmqctl set_vm_memory_high_watermark absolute 50MB】可以看到当前就变红啦
【relative】 相对值,即前面的fraction,建议取值在0.4~0.66之间,不建议超过0.7【absolute 】绝对值,单位为KB、MB、GB![]()
【 内存翻页】
在某个 Broker 节点触及内存并阻塞生产者之前,它会尝试将队列中的消息换页到磁盘以释放内存空间。默认情况下,在内存到达内存阈值的 50%时会进行换页动作。在配置文件(/etc/rabbitmq/rabbitmq.conf)中可以进行配置预警和翻页的阈值。vm_memory_high_watermark.relative = 0.4vm_memory_high_watermark_paging_ratio = 0.75

磁盘控制
当磁盘剩余空间低于确定的阈值时,RabbitMQ 同样会阻塞生产者,这样可以避免因非持久化的消息持续换页而耗尽磁盘空间导致服务崩溃。默认情况下,磁盘阈值为50MB,表示当磁盘剩余空间低于50MB 时会阻塞生产者并停止内存中消息的换页动作 。这个阈值的设置可以减小,但不能完全消除因磁盘耗尽而导致崩溃的可能性。比如在两次磁盘 空间检测期间内,磁盘空间从大于50MB被耗尽到0MB 。一般我们是将磁盘阈值设置为与操作系统所显示的内存大小一致。
这里使用命令告诉它当剩下100个G的时候预警,但是我们总共才不到6G,所以他会立马预警 【rabbitmqctl set_disk_free_limit 100GB】




 浙公网安备 33010602011771号
浙公网安备 33010602011771号