并发编程-(volatile)可见性&有序性
并发编程-(volatile)可见性&有序性
【可见性】:就是两个线程对同一个变量进行修改线程a修改后,线程b没有读取到修改后的数据,类似于数据库中的脏读。
【有序性】:在java内存模型中,允许编译器和处理器对指令进行重新排序,在单线程的时候不影响,但是在多线程的时候,就会影响执行结果的正确性。
【volatile】:java提供的一种解决上面的这两种问题的方式,底层是cpu提供的#Lock指令。
可见性
模拟两个线程,两个线程对同一个数据进行改变,看看线程a改变了数据,线程b是否可以觉察,运行下面的代码,我们发现,main线程对flag进行修改,并不能停止我们执行while循环的线程,这就是线程可见性问题。
private static boolean flag=false; public static void main(String[] args) throws InterruptedException { Thread thread=new Thread(()->{ int i=0; while (!flag){ i++; } }); thread.start(); System.out.println("thread began execute"); Thread.sleep(100); flag=true; } }
如何解决线程可见性问题呢
1.实际上我们只要增加volatile即可,可以这样认为,加了这个关键字后,当其中一个线程修改了一个变量后,其他的线程对应也可以看见修改后的内容,其实jvm中有做深度优化(活性失败),在底层优化后while(!flag)就变成了【whild(true)】,volatile就是禁止这样优化,从而让程序正常的运行。
2.我们可以让线程睡一下,实际上即使是0睡0毫米,cup也会进行切换,切换后,我们的数值就会重新加载,起到正常运行的目的
3. 可以打印 i 的数值,这其实是一个 io 的操作,底层有synchronize的锁,变量也会重新加载。


可见性是什么导致的
我们都知道cup是核心的资源,我们不能让cpu资源的浪费,为了充分利用cpu资源的,我们想出了一系列方案,但是在这一系列方案去优化cpu的使用率的时候,我们就碰到了可见性的问题。这些优化的方案为:
- 给CPU增加高速缓存
- 给操作系统中增加进程和线程这样的东西
- 编译器层面:上面提到的jvm的深度优化就是一个例子
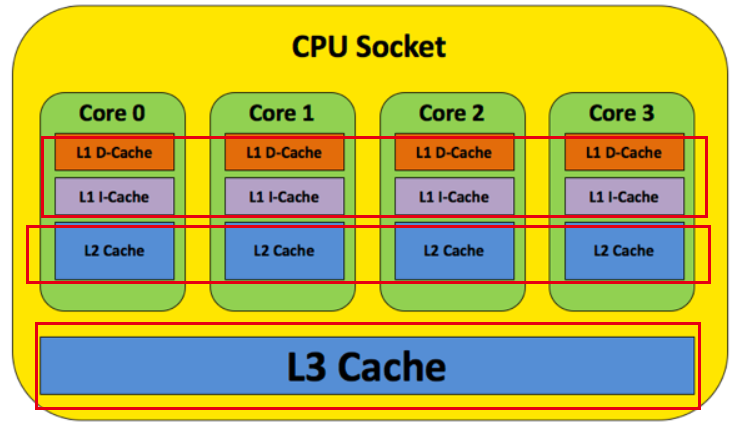
CPU的高速缓存
因为cpu的处理速度和内存读写的速度差距较大,那就造成了cpu读取内存数据的时候消耗很长时间,那能不能像我们做分布式开发的时候的那样,把数据缓存在Redis中,从而减少性能的消耗,减少时间呢,是的cpu的高速缓存就是类似这样做的,cpu的高速缓存就是介于CPU处理器和内存之间的临时数据交换的缓冲区。他的流程就是当cpu读取数据的时候,当缓存中没有数据,才去内存中读取。实际上在cpu中设计了三层缓存,每一个cpu中都有三个缓存,L1和L2是cpu独立存在的,其中L2缓存和L3是共享的,L1缓存中分为数据缓存(L1D)和指令缓存(L1I)
我们知道了缓存行的存在,就明白了为什么上面的代码main修改了变量flag,但是执行i++的线程却不能感应到的原因了,这就是缓存一致性问题,那么如何解决?这里引入一个概念缓存行
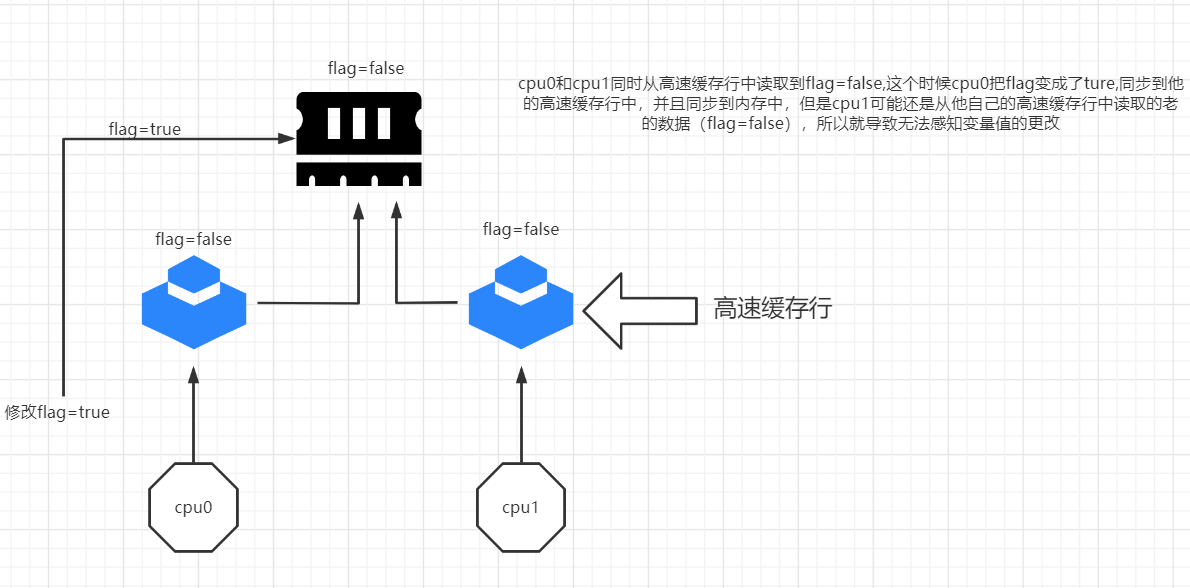
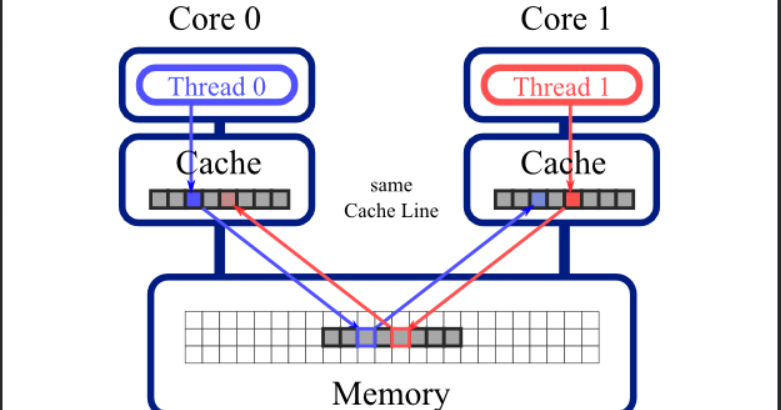
缓存行
cpu的缓存是由多个缓存行组成的,cpu每一次读取数据的时候都只会加载一段数据,缓存行是cpu和内存交互的最小工作单元,在x86的架构中,每个缓存行是64个字节,所以cpu在读取数据的时候,一次就读取64个字节。因为在高速缓存的时候,涉及到一个伪共享的问题,那什么是伪共享?
伪共享
现在主流的缓存行都是64Bytes大小的,试想,如果两个线程同时修改同一个缓存行中的变量,那势必会造成互相竞争,缓存行一次读取了【ABCDEFGH,】线程1要修改A的数值,线程2要修改B的内容,当线程1修改了A的数值线程0的缓存行就会失效,当线程2修改B的数值的时候,那线程a的缓存行就会失效,这样就耗费了性能,这就是伪共享。那么怎么解决这个问题,那就要用到【对齐填充】了。
对齐填充
既然他每次都cpu每次都要读取64Bytes,但是这64个Bytes中可能加载了伪共享情况的发生,那我们能不能每次只加载一个数据,其余都给他自动填充成别的数据,这样时候就避免了伪共享的发生,其实对齐填充就是这样做的,当我们只要操纵【ABCDEFGH】中的A的时候,那我们就第一个数据就只读取A,其余的位数就这样A*******
一个例子说明对齐填充的性能
// 对齐填充 public class ValuePadding { protected long p1, p2, p3, p4, p5, p6, p7; protected volatile long value = 0L; protected long p9, p10, p11, p12, p13, p14; protected long p15; } public class CacheLineExample implements Runnable { public final static long ITERATIONS = 500L * 1000L * 100L; private int arrayIndex = 0; private static ValuePadding[] longs; public CacheLineExample(final int arrayIndex) { this.arrayIndex = arrayIndex; } @Override public void run() { long i = ITERATIONS + 1; while (0 != --i) { longs[arrayIndex].value = 0L; } } static void runTest(int NUM_THREADS) throws InterruptedException { Thread[] threads = new Thread[NUM_THREADS]; longs = new ValuePadding[NUM_THREADS]; for (int i = 0; i < longs.length; i++) { longs[i] = new ValuePadding(); } for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(new CacheLineExample(i)); } for (Thread t : threads) { t.start(); } for (Thread t : threads) { t.join(); } } } public class Test { public static void main(final String[] args) throws Exception { for (int i = 1; i < 10; i++) { System.gc(); final long start = System.currentTimeMillis(); CacheLineExample.runTest(i); System.out.println(i + " Threads, duration = " + (System.currentTimeMillis() - start)); } } }对齐填充
不对齐填充(把CacheLineExample中的对齐填充的类替换即可)
// 不对齐填充 public class ValueNoPadding { //8字节 protected volatile long value = 0L; }
tips:我们发现对齐填充明显比不对齐填充运行的要快得多,在java8中我们使用@Contended 去避免伪共享的问题,但是前提是你必须设置jvm的参数



缓存一致性问题
上面说了给cpu加上缓存是一种解决方案,但是这就又导致了缓存一致性问题【可见性】,缓存不一致问题,正如上述讲的demo,main修改了flag没有影响到别的线程的数据,其实我们可以进行锁的方式解决,就是当我的某一个线程在修改内存的数据的时候,阻塞别的线程,或者,我们是不是可以只对某个缓存行进行加锁呢,这样别的线程就不用阻塞,从而提高了性能,那就引出了两个概念。
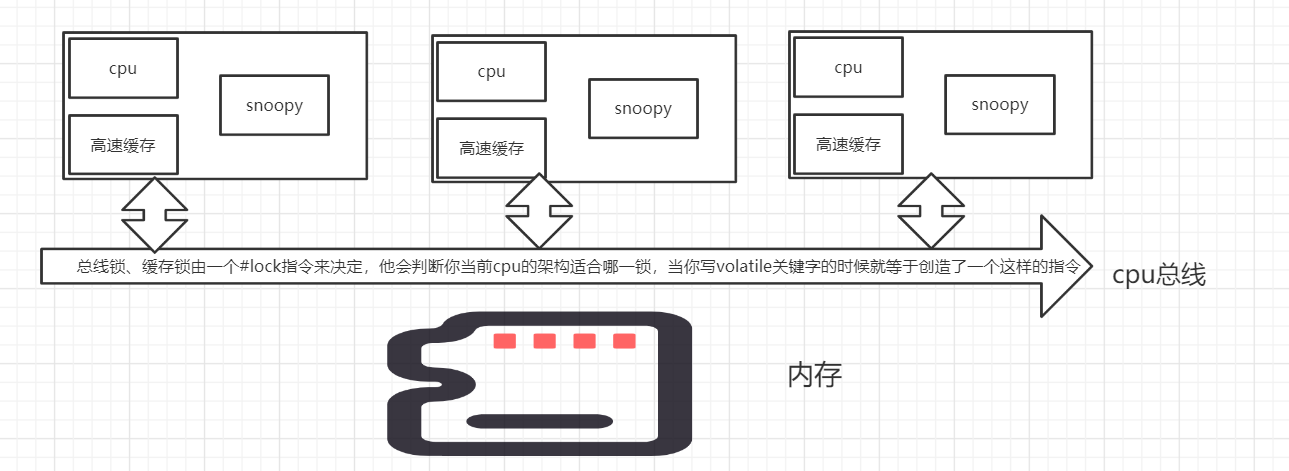
- 总线锁:其实在线程访问内存的时候还有要经过一个线程总线,其实我们可以给这个总线加锁,但是这就想当于阻塞其他线程。
- 缓存锁:我们知道cpu是一个缓存行一个缓存行对数据进行读取,那么我们就可以对緩存行进行加锁,从而提高控制的粒度,也不会对其他的线程阻塞,那么缓存锁是如何保障一致性的呢,那么就要引入一个概念, 缓存一致性协议MESI.
MESL(表示缓存的4中状态)
cpu读:【M、E、S】均可被读取
cpu写:【M、E】,当状态为S时必须先把其他cpu缓存中的状态设为失效
- M (Modify:修改):当我们对某个变量进行修改,那状态就变成了 M,该缓存行有效,数据被修改了,和内存中的数据不一致,数据只存在于本缓存行中
- E(Exclusive:互斥):也是就这一个数据只存在当前cpu对其他不可见那么状态就是 E,该缓存行有效,数据和内存中的数据一致,数据只存在于本缓存行中
- S(Shared:分享):和其他cpu共享一个数值时,状态就是 S ,该缓存行有效,数据和内存中的数据一致,数据同时存在于其他缓存中
- I (Invalid:无效):当共享一个变量时,cpuA把一个数据修改,那么就要把别的cpu中的状态变为 I 该缓存行数据无效
如何使用mesl呢
这里要引入一个东西叫做snoopy协议,我们都知道有线程总线这样一个概念,当其他cpu发起任务时候,会有一个状态在缓存总线上,这个snoopy就是来监听其他cpu的状态的,对不同状态做出不同的反应,你可以理解缓存、cpu、snoopy是一个一个总线上的一个个的整体。比如说cpuA要修改flag=1那么他先修改自己的高速缓存,同时同步到主内存的的时候,会发送一个失效的指令到缓存总线中,这个时候其他的的线程中的flag状态失效,然后他们就会去内存中重新获取数据。这就达到了缓存一致性的目的。这里,我们就知道当我们声明 volatile关键字的时候,底层就会有一个汇编指令【#lock】去对cpu加锁可能是总线锁、也可能是缓存锁取决于你的cpu
【#lock】:可以解决总线锁、缓存锁、以及内存屏障的问题
有序性
有时候代码可能不是按照正常顺序执行的,在多线程情况下,我们就能看出,例如下面的代码:正常执行结果可能是(1,0)、(0,1)或(1,1) 然而可能有第三种可能那就是(0,0)出现这种情况就是颠倒执行了顺序。像我下面图中最后的执行场景。然而这种情况很难发生,你需要运行下面的代码很久,我是循环了200多万次才复现的这个场景。那么到底是什么导致这种指令重排序的问题发生的呢?
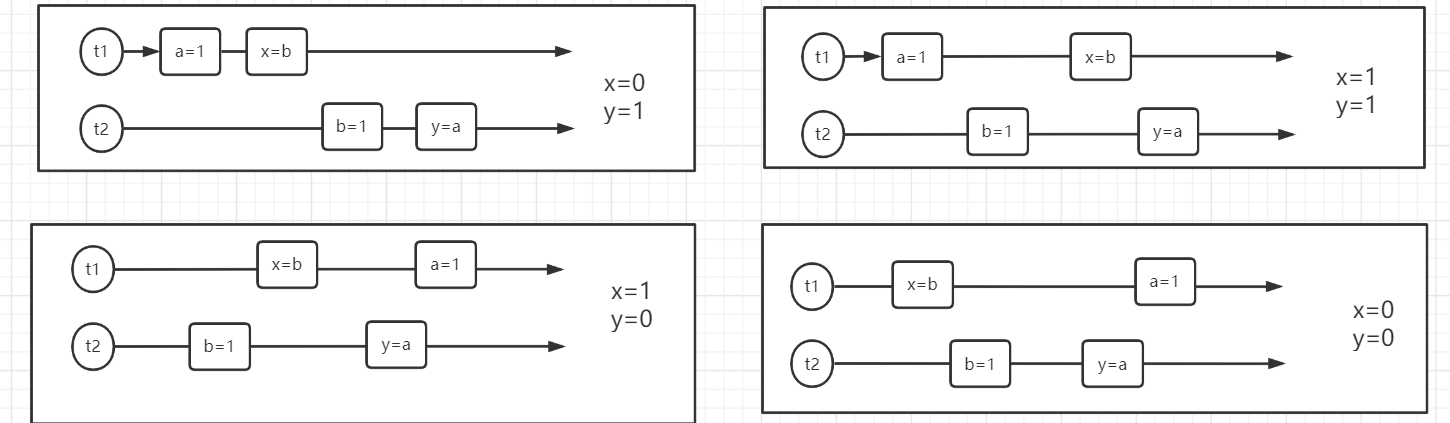
public class seq { private static int x = 0, y = 0; private static int a = 0, b = 0; public static void main(String[] args) throws InterruptedException { int i = 0; for (; ; ) { i++; x = 0; y = 0; a = 0; b = 0; Thread t1 = new Thread(() -> { a = 1; x = b; }); Thread t2 = new Thread(() -> { b = 1; y = a; }); t1.start(); t2.start(); t1.join(); t2.join(); String result = "第" + i + "次(" + x + "," + y + ")"; if (x == 0 && y == 0) { System.out.println(result); break; } else { } } } }
什么导致了指令重排序
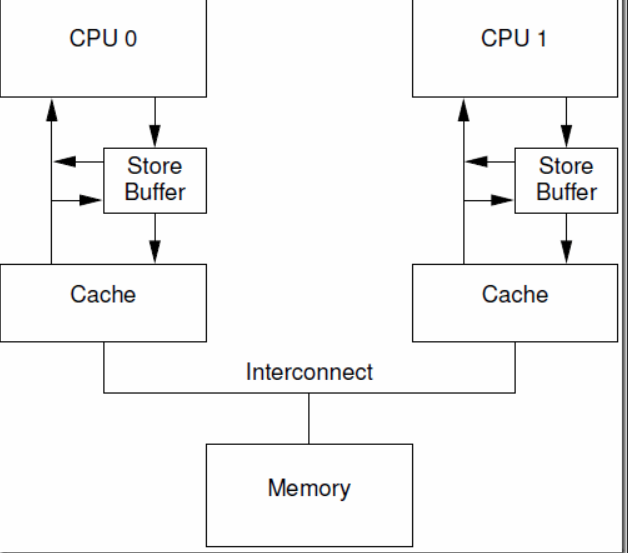
【store buffer】:我们可以想象他是类似于一个队列,上面说了咱们的MESL,当cpu修改某个数值的时候,其实先把这个消息告诉store buffer,然后他去通知别的cpu,说这个数值已经失效,接着其他cpu回复当前cpu收到后,当前cpu才修改他的缓存中的数值和内存中的数值,这个store buffer在一定的程度上提高了性能,因为当cpu把他要修改内存中的一个数值的信息告诉其他cpu的时候,其他cpu需要回复当前cpu后,当前cup才能对数据进行操作,那在等待的时候可能会有一段时间当前cpu闲置,这个store buffer 就可以去帮助当前cpu去通知消息,那样当前cpu就可以做后面的事情了,等到这个store buffer 返回消息后,他就可以对内存中的数据进行修改了
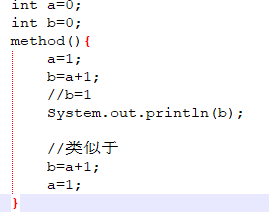
我们来看这段代码,最终结果为什是b=1,用这个来分析导致指令重排序的原因
用一个图来阐述问题
其实上面问题就是cpuA他给了【store buffer】了这个数值然后是其他线程返回了这个数据,那试想是否可以直接从store buffer中获取这个数据呢?是的,这个过程叫【store forwarding】,cpu可以直接从自己的store buffer中读取数据,但是这又会导致问题,这里不进行展开,推荐去一个博客内容。
tips:【store buffer】 和【store forwarding】已经很大程度的让cpu资源利用最大化,但是有个问题,那就是【store buffer】的大小是有限制的如果什么都放入这个里面cpu可能会阻塞的!,那又引入一个东西【Invalidate Queue】
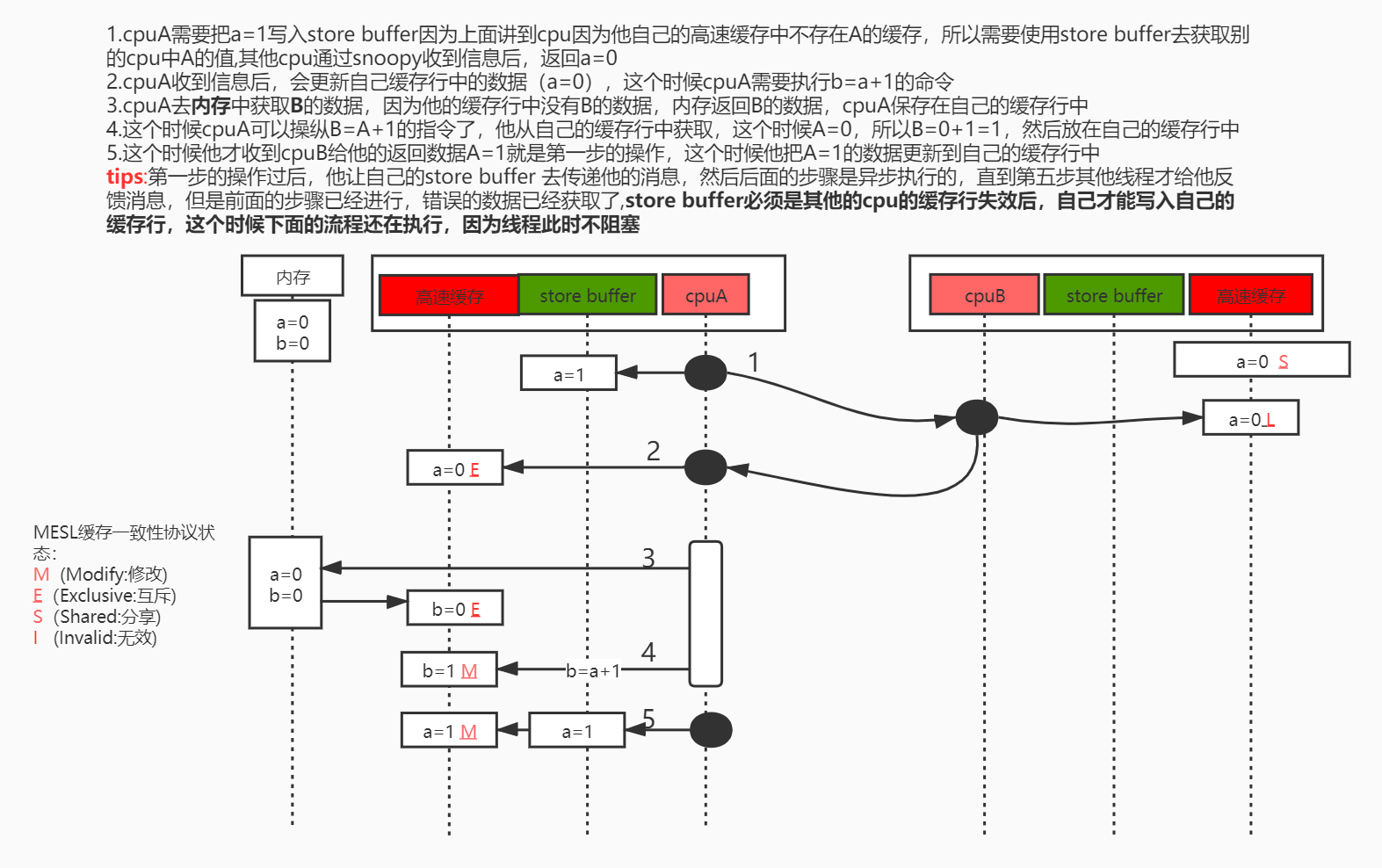
Invalidate Queue(失效队列)
实际上就是上面的图中的第二步,cpuA等到别的cpu返回消息后才对自己的信息进行修改,那么是否可以在cpuB中放置一个队列一样的东西,去接受cpuA的消息,然后立马返回收到的信息呢?是这样的。【Invalidate Queue】就是一个队列,接受其他cpu的失效内容,然后立马返回一个收到的信息【 invalidate ack】然后自己慢慢处理,这样就可以增加增加一些效率,让store buffer更快的执行。但是我们想这里可能又导致了另外一个问题,就是实际上,他只是放在自己的队列中,而没有真的对这个消息进行处理,或者说没有来的急对这个消息进行处理,但是线程别收到他的假消息,于是继续操作这个数据,所以可能又引出了指令重排序的问题。记住我们这些都是在说有序性的原因,这一切都可以使用【volatile】解决。那实在的怎么解决呢?这个时候要再介绍一个名词【内存屏障】
内存屏障
- 写屏障:所有的写操作必须在写屏障前面完成
- 读屏障:所有的读操作必须在读屏障前完成
- 和全屏障:读写操作必须在全屏障之前完成
内存屏障你就想象他是一个标记,他会锁定内存的系统,去确保执行顺序。他底层还是通过#Lock指令,#Lock指令是一个全屏障。这里记住#Lock指令在不同的系统中实现内存屏障的指令不同,只不过在X86中是#Lcok,其他的架构中,我们不去深究。
总结
可见性:我们想充分利用cpu的资源,所以提出使用cpu高速缓存去缓存一些数据,去减少cpu的执行时间增强执行效率,所以每个cpu都有自己的【缓存行】,这里牵扯到一个【伪共享】的问题,消耗了cpu的性能,然后使用了【对齐填充】解决了这个问题。我们想到可以使用加锁的方式对数据安全进行保障,然后又引入了【总线锁、和缓存行锁】去解决这个问题,这些锁是基于【mesl】协议去做的,我们使用【snoopy】去辅助各个线程去监听别的线程的【mesl】协议的状态,我们知道如果一个变量被volatile所修饰的话,在每次数据变化之后,值都会被强制刷入主存。而其他处理器的缓存由于遵守了mesl协议,也会把这个变量的值从主存加载到自己的缓存中,这就解决了可见性问题。
有序性:【store buffer】辅助cpu去通知各个线程自己的状态,但是其实直接从【store buffer】中获取当前自己已经修改的内存比通知别的线程更能提高性能,所以我们就引入了【store forwarding】,然而store forwarding 的内存大小有限,所以我们引入了【 Invalidate Queue】去充当一个失效队列,cpu在接收到内容后,就直接返回自己的结果,但是有可能他急于返回内存,并没有处理,那就造成了可能在后面的流程需要用到这个值,然而没有操作的结果,所以就导致了【指令重排序】,那只能交给开发自己解决,这个时候用volatile关键字就可以调用cpu提供的【内存屏障】,从而解决有序性问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号