Redis-Cluster集群部署记录
Redis的集群方案大致有三种:
1)redis cluster集群方案;
2)master/slave主从方案;
3)哨兵模式来进行主从替换以及故障恢复。
Cluster集群模式介绍
redis集群是一个无中心的分布式redis存储架构,可以在多个节点之间进行数据共享,解决了redis高可用、可扩展等问题,redis集群提供了以下两个好处
- 将数据自动切分(split)到多个节点
- 当集群中的某一个节点故障时,redis还可以继续处理客户端的请求。
** Redis Cluster的数据分片原理说明:**
- redis cluster使用固定个数的slot存储数据,一共16384是slot
- 每组分片分得1/3 slot个数,分别为"0-5460,5461-10921,10922-16383"
- 基于CRC16(key) % 16384公式会得到一个"槽位号"(该编号范围在"0-16383"之间)
- 根据计算得出的槽位值,找到相对应的分片节点的主节点,存储到相应槽位上
- 如果客户端当时连接的节点不是将来要存储的分片节点,分片集群会将客户端连接切换至真正存储节点进行数据存储
Redis Cluster的特点如下:
- 节点自动发现
- slave->master选举,集群容错
- Hot resharding:在线分片
- 集群管理:clusterxxx
- 基于配置(nodes-port.conf)的集群管理
- ASK 转向/MOVED转向机制
- 布署无需指定master
- 可以支持超过1,000台节点的集群
Cluster架构
Redis 集群采用无中心结构,其中每个节点不仅存储数据,还维护整个集群的状态。所有节点彼此直接连接,实现了去中心化的设计。
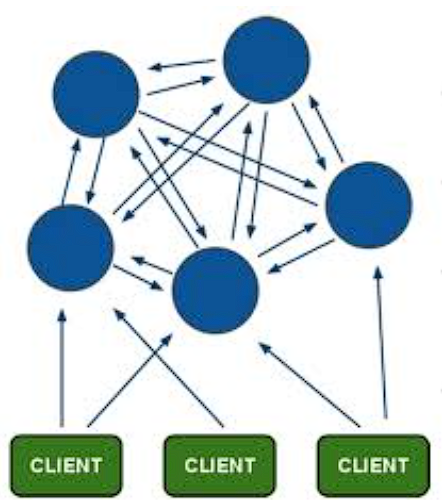
redis cluster集群是为了降低单节点或单纯主从redis的压力,主主节点之间是不存在同步关系的,各主从之间的数据存在同步关系。有多少主节点,就会把16384个哈希槽(hash slot)平均分配到这些主节点上,当往redis里写入数据时,会根据哈希算法算出这个数的哈希槽,决定它放到哪一个主节点上,然后这个主节点的从节点去自动同步。在客户端随便连接一个主节点即可,主节点之间会进行内部跳转!当取对应数据时,各节点之间会自动跳转到所取数据所在的主节点上!
redis cluster节点分配
假设现有有三个主节点分别是:A、 B、C ,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式
来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:
节点A 覆盖0-5460;
节点B 覆盖5461-10922;
节点C 覆盖10923-16383.
获取数据:
如果存入一个值,按照redis cluster哈希槽的算法: CRC16('key')%16384 = 6782。 那么就会把这个key 的存储分配到 B 上了。同样,当我连接
(A,B,C)任何一个节点想获取'key'这个key时,也会这样的算法,然后内部跳转到B节点上获取数据
新增一个主节点:
新增一个节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot到D上,我会在接下来的实践中实验。大致就会变成这样:
节点A 覆盖1365-5460
节点B 覆盖6827-10922
节点C 覆盖12288-16383
节点D 覆盖0-1364,5461-6826,10923-12287
同样删除一个节点也是类似,移动完成后就可以删除这个节点了。
Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据
备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉。
上面那个例子里, 集群有A、B、C三个主节点, 如果这3个节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群了。A和C的slot也无法访问。
所以在集群建立的时候,一定要为每个主节点都添加了从节点, 比如像这样, 集群包含主节点A、B、C, 以及从节点A1、B1、C1, 那么即使B挂掉系统也
可以继续正确工作。B1节点替代了B节点,所以Redis集群将会选择B1节点作为新的主节点,集群将会继续正确地提供服务。 当B重新开启后,它就会变成B1的从节点。
不过需要注意,如果节点B和B1同时挂了,Redis集群就无法继续正确地提供服务了。
在搭建集群时,会为每一个分片的主节点,对应一个从节点,实现slaveof的功能,同时当主节点down,实现类似于sentinel的自动failover的功能
主机规划
生产环境建议采用3master + 3slave总共6 台独立服务器架构
| 操作系统 | IP | 主机名 | CPU/内存 | 版本 |
|---|---|---|---|---|
| 麒麟信安3.3 | 10.0.0.31 | redis1 | 2核+2G | 6.2.6 |
| 麒麟信安3.3 | 10.0.0.32 | redis2 | 2核+2G | 6.2.6 |
| 麒麟信安3.3 | 10.0.0.33 | redis3 | 2核+2G | 6.2.6 |
| 麒麟信安3.3 | 10.0.0.34 | redis4 | 2核+2G | 6.2.6 |
| 麒麟信安3.3 | 10.0.0.35 | redis5 | 2核+2G | 6.2.6 |
| 麒麟信安3.3 | 10.0.0.36 | redis6 | 2核+2G | 6.2.6 |
Cluster集群搭建过程
下载redis
wget http://download.redis.io/releases/redis- 6.2.6.tar.gz
安装依赖
yum -y install gcc automake autoconf libtool make
关闭防火墙
1.#闭防火墙、selinux、dnsmasq/NetworkManager
systemctl disable --now firewalld
systemctl disable --now dnsmasq
systemctl disable --now NetworkManager
setenforce 0
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/sysconfig/selinux
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
#检查
grep ^SELINUX= /etc/selinux/config
编译安装redis
tar xf redis- 6.2.6.tar.gz
mv redis- 6.2.6 /usr/local/redis
cd /usr/local/redis
make
通过 echo $? 来判断编译和安装是否成功
所有主机配置环境变量
#/usr/local/redis/src
cat>>/etc/profile<<'EOF'
export PATH=/usr/local/redis/src:$PATH
EOF
tail -1 /etc/profile
source /etc/profile
echo $PATH
所有主机创建配置目录
#分别创建目录
mkdir /data/6379 -p
创建配置文件
cat > /data/6379/redis.conf <<EOF
port 6379
bind 0.0.0.0
daemonize yes
pidfile /data/6379/redis.pid
loglevel notice
logfile "/data/6379/redis.log"
dbfilename dump.rdb
dir /data/6379
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 10.0.0.31 #每个节点ip地址
appendonly yes
requirepass 123
EOF
内核优化
cat >>/etc/sysctl.conf<<EOF
net.ipv4.tcp_fin_timeout = 2
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_keepalive_time = 600
net.ipv4.ip_local_port_range = 4000 65000
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.route.gc_timeout = 100
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
net.core.somaxconn = 16384
net.core.netdev_max_backlog = 16384
net.ipv4.tcp_max_orphans = 16384
vm.overcommit_memory = 0
EOF
sysctl -p
关于vm.overcommit_memory参数说明
设置为2,禁用overcommit,会降低内存的使用效率,浪费内存资源。但是不会发生OOM。
设置为1,不建议使用。
设置为0,默认值,适度超发内存,但也有OOM风险。(这也是数据库经常发生OOM的原因)
启动redis
redis-server /data/6379/redis.conf
- 脚本管理
#!/bin/bash
REDIS_CONFIG_PATH=/data/6379/redis.conf
choice=$1
start(){
echo "开始启动redis"
PID=$(ps -ef | grep redis-server | grep -v grep | wc -l)
if [ $PID -eq 0 ]; then
/usr/local/redis/src/redis-server $REDIS_CONFIG_PATH
sleep 2
echo "redis启动成功"
else
echo "redis已启动"
fi
}
stop(){
echo "开始停止redis"
PID=$(ps -ef | grep redis-server | grep -v grep | wc -l)
if [ $PID -eq 1 ]; then
redis-cli -h 127.0.0.1 -p 6379 -a 123 shutdown
sleep 2
echo "redis停止成功"
else
echo "redis已停止"
fi
}
case "$choice" in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
*)
echo "请输入正确的格式: sh $0 {start|stop|restart}"
;;
esac
使用system管理
cat >/usr/lib/systemd/system/redis.service<<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/usr/local/redis/src/redis-server /data/6379/redis.conf --supervised systemd
ExecStop=/usr/local/redis/src/redis-cli shutdown
Type=notify
User=root
Group=root
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
- 启动
systemctl daemon-reload
systemctl enable --now redis.service
systemctl status redis.service
netstat -lantup | grep 6379
启动警告处理
echo '511' > /proc/sys/net/core/somaxconn
echo never > /sys/kernel/mm/transparent_hugepage/enabled
ulimit -SHn 65535
echo "* - nofile 65535" >>/etc/security/limits.conf #永久生效
Redis-cli创建集群
2018年十月 Redis 发布了稳定的 5.0 版本,推出了非常多的新特性,其中一点是放弃 Ruby的集群方式,改为 使用 C语言编写的 redis-cli 的方式。
所以说现在有两种方式来创建集群:
● 一种是ruby启动方式;
● 另外一个是 C语言的方式。
因为我用的 redis 版本是 6.2.6,如果要用ruby创建集群的方式,还需要安装ruby语言的一些东西,所以这里使用的 redis-cli 的方式创建集群。
创建集群
redis-cli -a 123 --cluster create \
10.0.0.31:6379 \
10.0.0.32:6379 \
10.0.0.33:6379 \
10.0.0.34:6379 \
10.0.0.35:6379 \
10.0.0.36:6379 \
--cluster-replicas 1
注意事项:如果出现Waiting for the cluster to join需要检查以下配置
1)配置文件redis.conf 中的bind 设置,IP要是本机地址
2)确保所有使用的端口之间互通,可用telnet ip port 测试**
3)登录到每个客户端,执行 flushall、 cluster reset,重启实例之前你要删除以下文件:
rm -rf nodes.conf // cluster-config-file
rm -rf dump.rdb // dbfilename
rm -rf appendonly.aof // appendfilename
重启所有实例:redis-server /data/6379/redis.conf
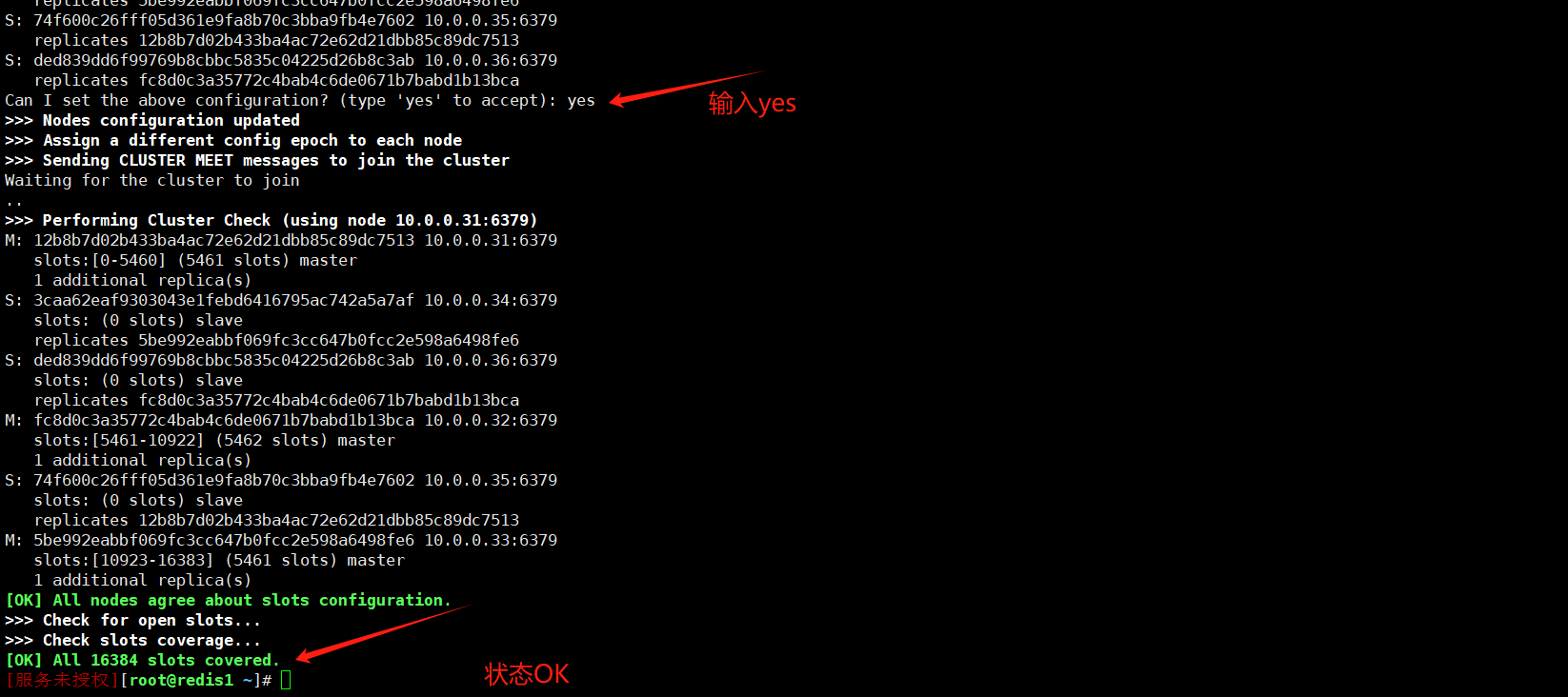
查看集群状态
redis-cli -h 10.0.0.31 -a 123 cluster info
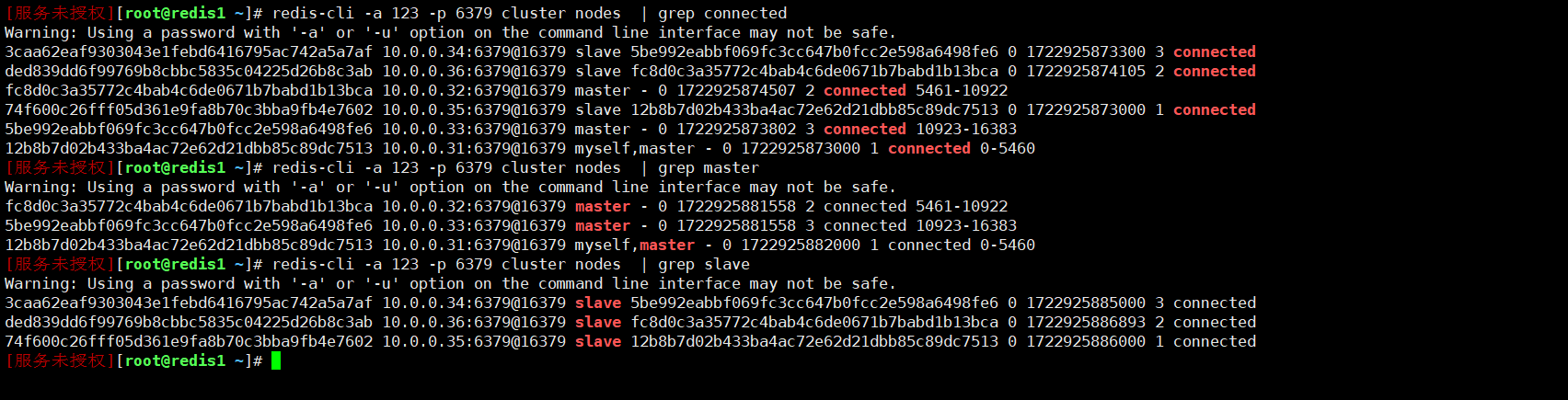
redis-cli -a 123 -p 6379 cluster nodes | grep connected
redis-cli -a 123 -p 6379 cluster nodes | grep master
redis-cli -a 123 -p 6379 cluster nodes | grep slave
可以看到每个节点的状态都是 connected,并且集群的槽位分配和节点角色(主节点和从节点)也都正确
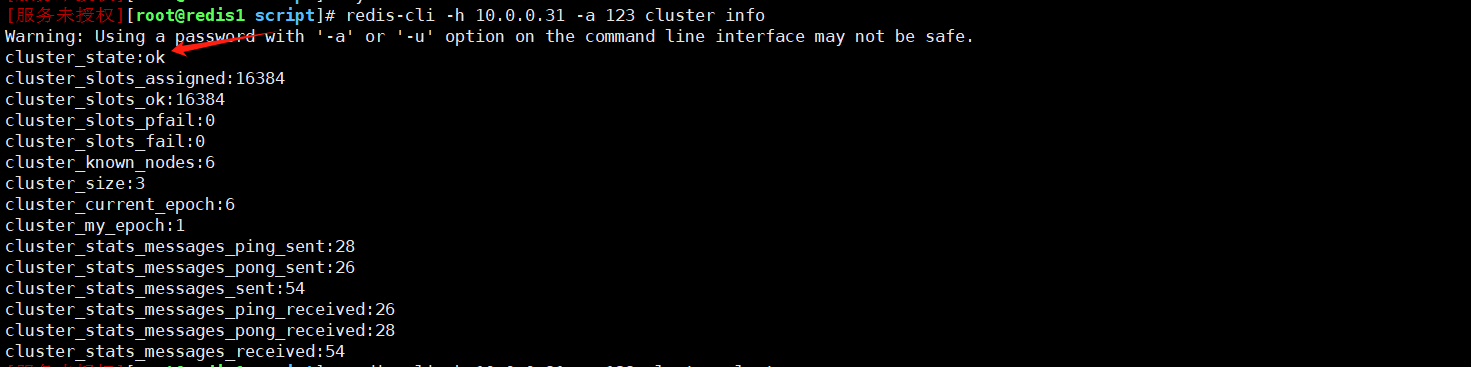
集群状态验证
集群状态的redis需要指定 -c 参数表示以集群模式连接
[服务未授权][root@redis1 ~]# redis-cli -h 10.0.0.31 -c -a 123
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.31:6379> set redis 6.26
OK
10.0.0.31:6379> exit
[服务未授权][root@redis1 ~]# redis-cli -h 10.0.0.35 -c -a 123
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.35:6379> get redis
-> Redirected to slot [1151] located at 10.0.0.31:6379
"6.26"
10.0.0.31:6379>
Redis Cluster日常操作命令
查看集群
cluster info :打印集群的信息
cluster nodes :列出集群当前已知的所有节点( node),以及这些节点的相关信息。
redis-cli -h 127.0.0.1 -a 123 cluster info
redis-cli -h 127.0.0.1 -a 123 cluster nodes
节点操作
cluster meet
cluster forget <node_id> :从集群中移除 node_id 指定的节点。
cluster replicate <master_node_id> :将当前从节点设置为 node_id 指定的master节点的slave节点。只能针对slave节点操作。
cluster saveconfig :将节点的配置文件保存到硬盘里面。
槽(slot)
cluster addslots
cluster delslots
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot
另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot
键
cluster keyslot
cluster countkeysinslot
cluster getkeysinslot
Redis Cluster集群重建
解决步骤:
1、停止服务,删除aof/rdb文件;【删了之前所有缓存数据会丢失,慎重慎重,血与泪的教训!!!】
2、删除nodes.conf
3、启动服务
4、启动集群
Redis Master下线及恢复
停止master
我们停止掉10.0.0.34的master节点

Master下线后,其对应的Slaver节点会自动变为Master节点,如下截图:
启动master
再次启动34节点的时候可以发现变为salve节点

观察日志发现Redis 集群在检测到节点失败后成功执行了自动故障转移,并且在故障节点恢复后,重新将其加入到集群中。
31239:M 06 Aug 2024 17:20:11.871 * Marking node 8c783b59b4b7e17d63fa4be2f3d0fea6a5e3b897 as failing (quorum reached).
31239:M 06 Aug 2024 17:20:11.871 # Cluster state changed: fail
31239:M 06 Aug 2024 17:20:12.905 # Failover auth granted to 6ec98ab38b949571ddd868014450069913565e48 for epoch 8
31239:M 06 Aug 2024 17:20:12.907 # Cluster state changed: ok
31239:M 06 Aug 2024 17:27:13.397 * Clear FAIL state for node 8c783b59b4b7e17d63fa4be2f3d0fea6a5e3b897: master without slots is reachable again.

从日志中可以看到,Redis 集群经历了以下几个事件:
- 节点失败检测:
31239:M 06 Aug 2024 17:20:11.871 * Marking node 8c783b59b4b7e17d63fa4be2f3d0fea6a5e3b897 as failing (quorum reached).
集群检测到节点 8c783b59b4b7e17d63fa4be2f3d0fea6a5e3b897 失败,达到了仲裁(quorum),因此将其标记为失败状态。
- 集群状态改变为失败:
31239:M 06 Aug 2024 17:20:11.871 # Cluster state changed: fail
由于检测到节点失败,集群状态被标记为 fail,这表示集群无法正常运行,可能因为关键节点不可用或没有足够的主节点来维持服务。
- 故障转移授权:
31239:M 06 Aug 2024 17:20:12.905 # Failover auth granted to 6ec98ab38b949571ddd868014450069913565e48 for epoch 8
集群授权节点 6ec98ab38b949571ddd868014450069913565e48 执行故障转移。这意味着该节点被选中作为新的主节点,以接管原来失败节点的职责。
- 集群状态恢复正常:
31239:M 06 Aug 2024 17:20:12.907 # Cluster state changed: ok
在故障转移成功后,集群状态恢复为 ok,表示集群恢复正常操作。
- 恢复连接:
31239:M 06 Aug 2024 17:27:13.397 * Clear FAIL state for node 8c783b59b4b7e17d63fa4be2f3d0fea6a5e3b897: master without slots is reachable again.
集群检测到原本标记为失败的节点 8c783b59b4b7e17d63fa4be2f3d0fea6a5e3b897 再次可用。虽然该节点不再持有数据槽(因为在故障转移过程中槽位已经被迁移到其他节点),但其作为一个无数据槽的主节点重新可用。
Redis Cluster节点扩缩容
启动新redis节点
mkdir /data/6379
cat > /data/6379/redis.conf <<EOF
port 6379
bind 0.0.0.0
daemonize yes
pidfile /data/6379/redis.pid
loglevel notice
logfile "/data/6379/redis.log"
dbfilename dump.rdb
dir /data/6379
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 10.0.0.37 #每个节点ip地址
appendonly yes
requirepass 123
EOF
redis-server /data/6379/redis.conf
添加master节点
redis-cli -a 123 -h 10.0.0.31 -p 6379 cluster meet 10.0.0.37 6379
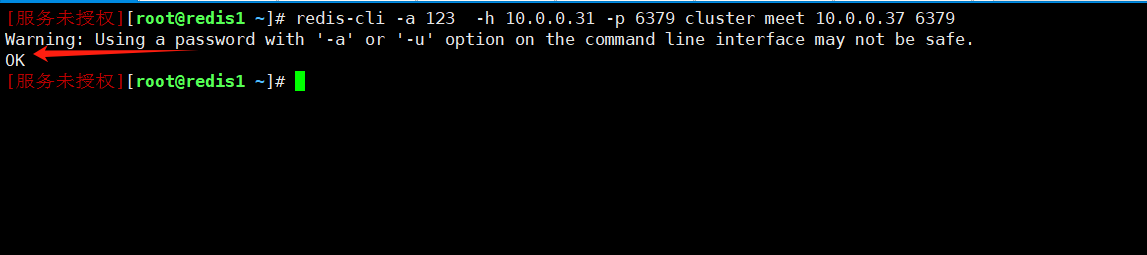
redis-cli -a 123 -h 10.0.0.31 -p 6379 cluster nodes
可以看到37节点已经新增加进来,但是新增加的主节点,是没有slots的,主节点如果没有slots的话,存取数据就都不会被选中

重新分配slot
redis-cli -a 123 --cluster reshard 10.0.0.31:6379
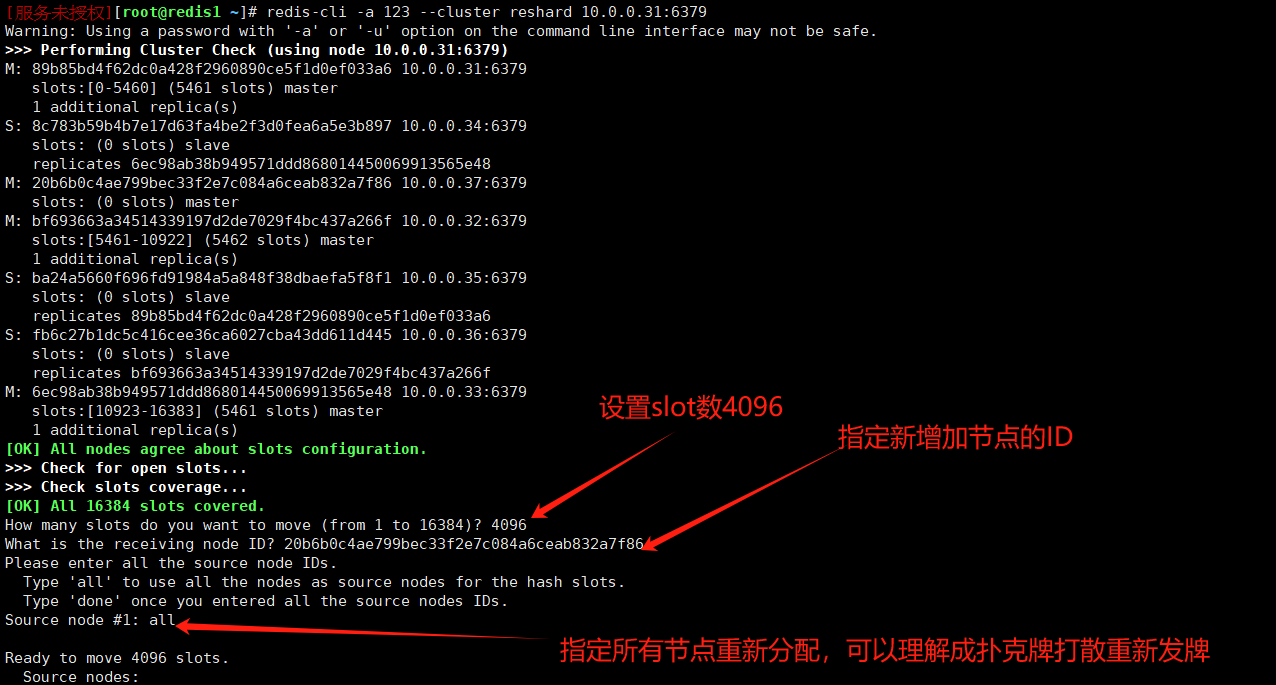
- 一共需要交互的信息
4096 #设置slot数4096 16384/4=4096
20b6b0c4ae799bec33f2e7c084a6ceab832a7f86 #新节点node id
all #示全部节点重新洗牌
yes #确认重新分
验证

移除master节点
转移slot
- 删除节点前将已有slot移动走
#37节点的槽位号
0-1364 5461-6826 10923-12287
1365个 1366个 1365个
- 执行reshard重新分配slot
redis-cli -a 123 --cluster reshard 10.0.0.31:6379
How many slots do you want to move (from 1 to 16384)? 1365#要转移的个数
What is the receiving node ID? 89b85bd4f62dc0a428f2960890ce5f1d0ef033a6 #谁接收
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 20b6b0c4ae799bec33f2e7c084a6ceab832a7f86 #谁发送,这里为37节点
Source node #2: done #确认
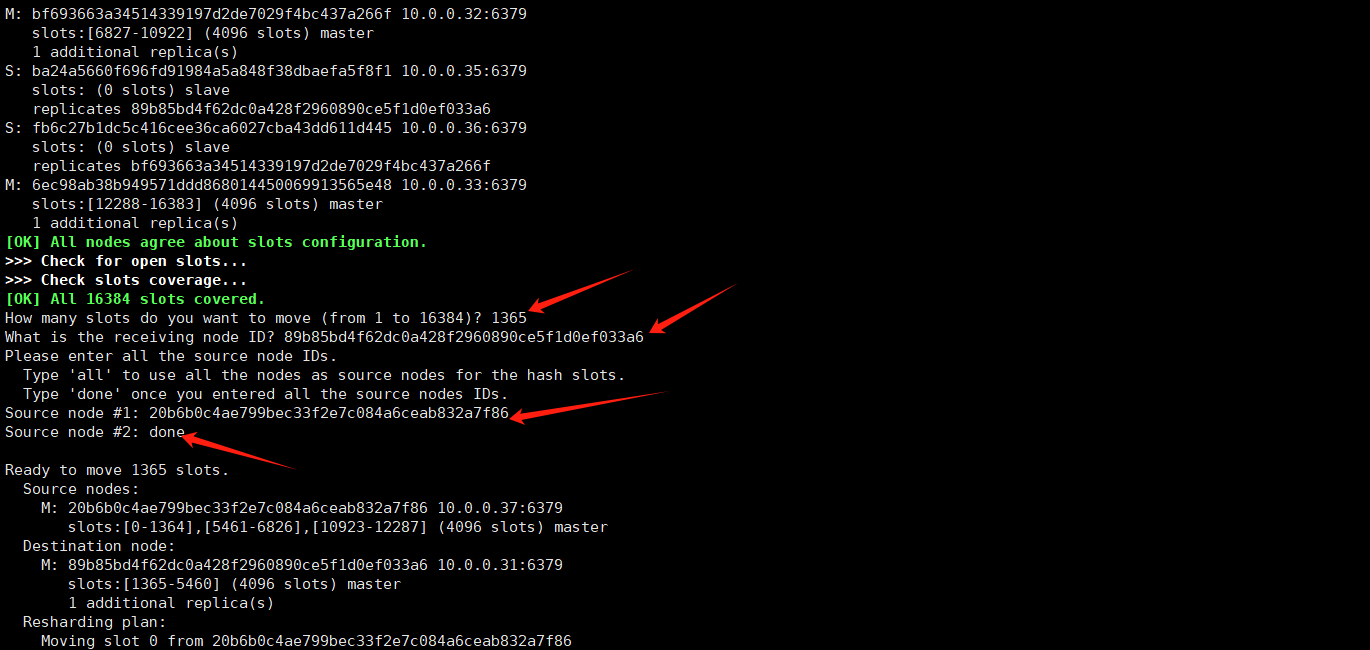
再次查看集群状态,可以看到 37 节点的 1365 个 slot 已成功迁移。

其他槽位以此类推,按照上面的重新移除即可
再次转移slot
按照上述步骤重新执行即可。需要注意的是,5461-6826 范围内有 1366 个槽位。可以看到槽位已经成功分配完毕。

移除节点
删除master节点之前首先要使用reshard移除master的全部slot,然后再删除当前节点
redis-cli -a 123 -h 10.0.0.31 -p 6379 cluster forget 20b6b0c4ae799bec33f2e7c084a6ceab832a7f86
移除成功
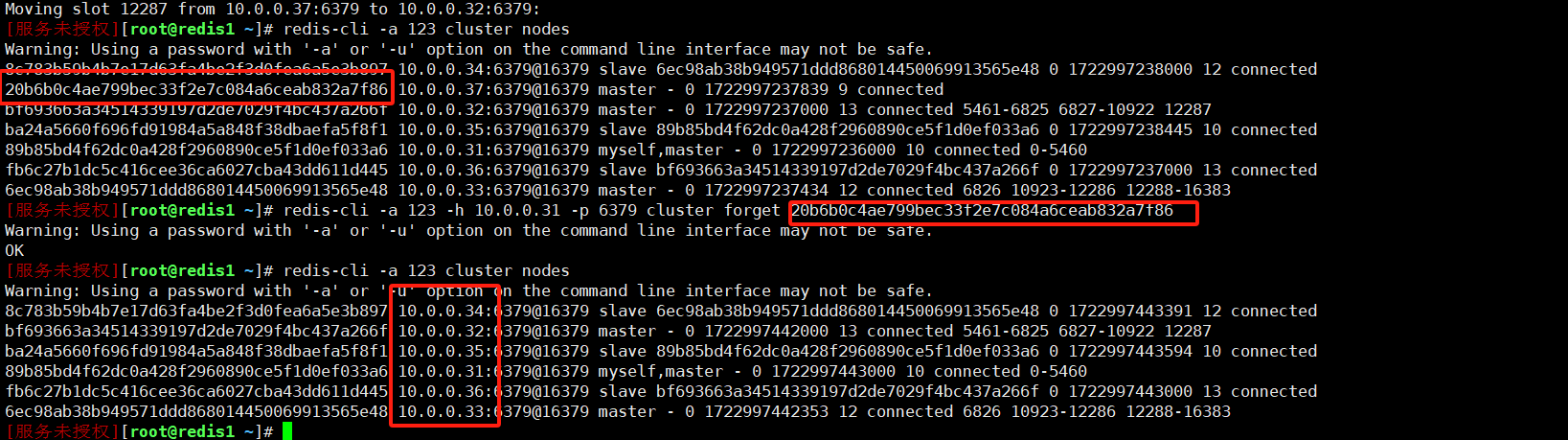
移除节点的node的数据
在移除 Redis 节点后,为了确保节点被彻底清理并从集群中完全移除:
[服务未授权][root@redis7 6379]# systemctl stop redis.service
[服务未授权][root@redis7 6379]# rm -f nodes.conf
**nodes.conf**:这是 Redis 集群的节点配置文件,包含了集群的配置信息。删除这个文件可以确保 Redis 节点不会以旧的配置重新加入集群
生产环境aof/rdb尽量避免删除,**删了之前所有缓存数据会丢失,慎重慎重,血与泪的教训!!
如果将来需要清理数据或重置节点,建议使用备份和恢复策略来最小化数据丢失的风险 **
添加slave节点
将节点加入集群
#添加节点
redis-cli -a 123 -h 10.0.0.31 -p 6379 cluster meet 10.0.0.37 6379
进入到37新节点
[服务未授权][root@redis1 ~]# redis-cli -a 123 -h 10.0.0.37
10.0.0.37:6379> cluster replicate 89b85bd4f62dc0a428f2960890ce5f1d0ef033a6 #新master的nodeid
OK
10.0.0.37:6379> quit
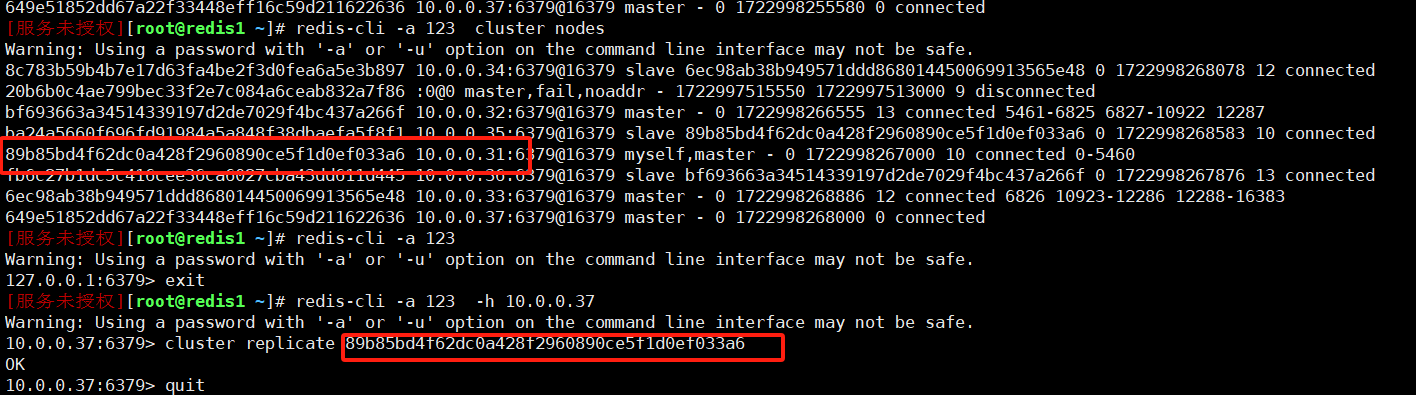
查看节点
redis-cli -a 123 cluster nodes | grep slave

移除slave节点
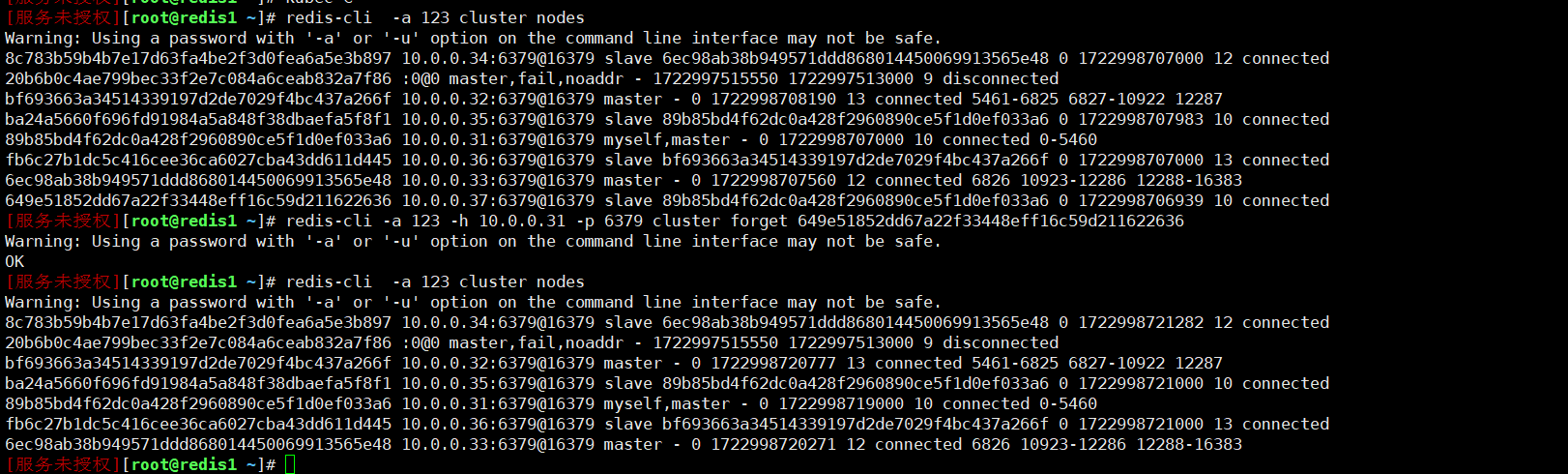
redis-cli -a 123 -h 10.0.0.31 -p 6379 cluster forget 649e51852dd67a22f33448eff16c59d211622636
本文来自博客园,作者:&UnstopPable,转载请注明原文链接:https://www.cnblogs.com/Unstoppable9527/p/18345367

 浙公网安备 33010602011771号
浙公网安备 33010602011771号