kubernetes-kubelet节点资源预留
一、Node Allocatable
1、node资源预留
1.1 为什么要做资源预留?
-
Kubernetes 的节点可以按照节点的资源容量进行调度,默认情况下 Pod 能够使用节点全部可用容量。这样就会造成一个问题,因为节点自己通常运行了不少驱动 OS 和 Kubernetes 的系统守护进程。除非为这些系统守护进程留出资源,否则它们将与 Pod 争夺资源并导致节点资源短缺问题。
-
当我们在线上使用 Kubernetes 集群的时候,如果没有对节点配置正确的资源预留,我们可以考虑一个场景,由于某个应用无限制的使用节点的 CPU 资源,导致节点上 CPU 使用持续100%运行,而且压榨到了 kubelet 组件的 CPU 使用,这样就会导致 kubelet 和 apiserver 的心跳出问题,节点就会出现 Not Ready 状况了。默认情况下节点 Not Ready 过后,5分钟后会驱逐应用到其他节点,当这个应用跑到其他节点上的时候同样100%的使用 CPU,是不是也会把这个节点搞挂掉,同样的情况继续下去,也就导致了整个集群的雪崩,集群内的节点一个一个的 Not Ready 了,后果是非常严重的,或多或少的人遇到过 Kubernetes 集群雪崩的情况,这个问题也是面试的时候镜像询问的问题。
-
要解决这个问题就需要为 Kubernetes 集群配置资源预留,kubelet 暴露了一个名为 Node Allocatable 的特性,有助于为系统守护进程预留计算资源,Kubernetes 也是推荐集群管理员按照每个节点上的工作负载来配置 Node Allocatable。
1.2 node allocatable
Kubernetes 节点上的 Allocatable 被定义为 Pod 可用计算资源量,调度器不会超额申请 Allocatable,目前支持 CPU, memory 和 ephemeral-storage 这几个参数。

1.2.1 查看node节点资源
我们可以通过 kubectl describe node 命令查看节点可分配资源的数据:
[root@master01 ~]# kubectl describe node node01
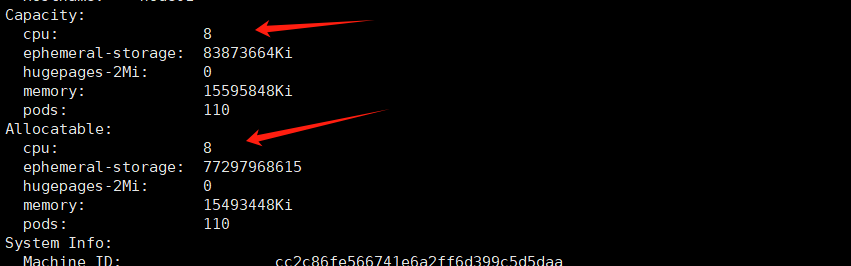
这段 Kubernetes 节点的配置信息描述了该节点的总容量(Capacity)和可分配资源(Allocatable)。
其中,Capacity 字段列出了该节点上可用的 CPU、内存、磁盘空间和 Pod 等资源的总数。具体来说:
cpu: 8表示该节点上有 8 个 CPU 核心;memory: 15595848Ki表示该节点上有 15,595,848 KiB (约为 14.87 GiB)的内存;ephemeral-storage: 83873664Ki表示该节点上有 83,873,664 KiB (约为 79.97 GiB)的临时存储空间;pods: 110表示该节点上最多可以调度 110 个 Pod。
Allocatable 字段列出了该节点上实际可分配的资源数量,也就是 Kubernetes 调度器实际可以使用的资源数量。通常情况下,Allocatable 的值应该小于或等于 Capacity 的值。具体来说:
cpu: 8表示该节点上可供调度器使用的 CPU 核心数为 8 个;memory: 15493448Ki表示该节点上可供调度器使用的内存为 15,493,448 KiB (约为 14.79 GiB);ephemeral-storage: 77297968615表示该节点上可供调度器使用的临时存储空间为 77,297,968,615 字节;pods: 110表示该节点上最多可以调度 110 个 Pod。
如果在一个节点上运行的 Pod 数量超过了该节点的 Allocatable 值,Kubernetes 将会拒绝将更多的 Pod 调度到该节点上。因此,在进行集群规划和调度时,需要根据节点的 Capacity 和 Allocatable 值来合理分配和调度应用程序,以充分利用资源并确保系统的稳定性和可靠性。
1.2.2 确认node01节点资源

可以看到其中有 Capacity 与 Allocatable 两项内容,其中的 Allocatable 就是节点可被分配的资源,我们这里没有配置资源预留,所以默认情况下 Capacity 与 Allocatable 的值基本上是一致的。下图显示了可分配资源和资源预留之间的关系:
- Kubelet Node Allocatable 用来为 Kube 组件和 System 进程预留资源,从而保证当节点出现满负荷时也能保证 Kube 和 System 进程有足够的资源。
- 目前支持 cpu, memory, ephemeral-storage 三种资源预留。
- Node Capacity 是节点的所有硬件资源,kube-reserved 是给 kube 组件预留的资源,system-reserved 是给系统进程预留的资源,eviction-threshold 是 kubelet 驱逐的阈值设定,allocatable 才是真正调度器调度 Pod 时的参考值(保证节点上所有 Pods 的 request 资源不超过Allocatable)。
节点可分配资源的计算方式为:
- Node Allocatable Resource = Node Capacity - Kube-reserved - system-reserved - eviction-threshold
2、 配置资源预留
2.1 kube预留值
首先我们来配置 Kube 预留值,kube-reserved 是为了给诸如 kubelet、容器运行时、node problem detector 等 kubernetes 系统守护进程争取资源预留。要配置 Kube 预留,需要把 kubelet 的 --kube-reserved-cgroup 标志的值设置为 kube 守护进程的父控制组。
不过需要注意,如果 --kube-reserved-cgroup 不存在,Kubelet 不会创建它,启动 Kubelet 将会失败。
比如我们这里修改 node-ydzs4 节点的 Kube 资源预留,我们可以直接修改/var/lib/kubelet/config.yaml 文件来动态配置 kubelet,添加如下所示的资源预留配置:
kubeReserved: 这个配置是用来为 Kubernetes 系统守护进程(如 kubelet、docker 等)预留资源的。当您在 kubeReserved 中设置了特定的资源量(比如 CPU、内存、临时存储等),Kubernetes 将保留这些资源,不会将它们分配给普通的 Pod 使用。这是为了确保系统进程有足够的资源运行,避免因资源不足而出现问题。
enforceNodeAllocatable:
- pods
kubeReserved:
cpu: "100m" # 为Kubernetes系统组件预留100m CPU
memory: "100Mi" # 为Kubernetes系统组件预留100Mi 内存
ephemeral-storage: "7Gi" # 保持原配置,为Kubernetes系统组件预留8Gi 临时存储
2.2 systemReserved预留
systemReserved:
memory: "100Mi" # 为系统级服务预留1Gi 内存
2.3 evictionHard预留
硬驱逐策略
evictionHard:
memory.available: "200Mi" # 当可用内存降至200Mi时开始驱逐Pods
nodefs.available: "10%" # 当节点文件系统可用空间降至总空间的10%时开始驱逐Pods
nodefs.inodesFree: "5%" # 当节点文件系统可用inode数量降至总数的5%时开始驱逐Pods
imagefs.available: "15%" # 当镜像文件系统可用空间降至总空间的15%时开始驱逐Pods
2.4 整体配置
enforceNodeAllocatable:
- pods
kubeReserved:
cpu: "100m" # 为Kubernetes系统组件预留100m CPU
memory: "100Mi" # 为Kubernetes系统组件预留100Mi 内存
ephemeral-storage: "7Gi" # 保持原配置,为Kubernetes系统组件预留8Gi 临时存储
systemReserved:
memory: "100Mi" # 为系统级服务预留1Gi 内存
evictionHard:
memory.available: "200Mi" # 当可用内存降至200Mi时开始驱逐Pods
nodefs.available: "10%" # 当节点文件系统可用空间降至总空间的10%时开始驱逐Pods
nodefs.inodesFree: "5%" # 当节点文件系统可用inode数量降至总数的5%时开始驱逐Pods
imagefs.available: "15%" # 当镜像文件系统可用空间降至总空间的15%时开始驱逐Pods
victionMinimumReclaim:
memory.available: "100Mi" # 在内存驱逐发生后,尝试至少回收300Mi内存
nodefs.available: "100Mi" # 在节点文件系统空间驱逐后,尝试至少回收500Mi空间
imagefs.available: "500Mi" # 在镜像文件系统空间驱逐后,尝试至少回收2Gi空间
2.5 重启服务
systemctl daemon-reload
systemctl restart kubelet
systemctl status kubelet
查看资源

2.6 Allocatable资源说明
这是一个用于说明节点可分配(Node Allocatable)计算方式的示例:
- 节点拥有 32Gi memory、16 CPU 和 100Gi Storage 资源
- --kube-reserved 被设置为 cpu=1,memory=2Gi,ephemeral-storage=1Gi
- --system-reserved 被设置为 cpu=500m,memory=1Gi,ephemeral-storage=1Gi
- --eviction-hard 被设置为 memory.available<500Mi,nodefs.available<10%
在这个场景下,'Allocatable' 将会是 14.5 CPUs、28.5Gi 内存以及 88Gi 本地存储。 调度器保证这个节点上的所有 Pod 的内存 requests 总量不超过 28.5Gi,存储不超过 '88Gi'。 当 Pod 的内存使用总量超过 28.5Gi 或者磁盘使用总量超过 88Gi 时,kubelet 将会驱逐它们。 如果节点上的所有进程都尽可能多地使用 CPU,则 Pod 加起来不能使用超过 14.5 CPUs 的资源。
当没有执行 kube-reserved 和/或 system-reserved 策略且系统守护进程使用量超过其预留时, 如果节点内存用量高于 31.5Gi 或 storage 大于 90Gi,kubelet 将会驱逐 Pod。
本文来自博客园,作者:&UnstopPable,转载请注明原文链接:https://www.cnblogs.com/Unstoppable9527/p/18341549


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具