AlertManager简介与使用
一、AlertManager简介
AlertManager 常用的功能
- 抑制:指的是当某一告警信息发送后,可以停止由此告警引发的其它告警,避免相同的告警信息重复发送。
- 静默:静默也是一种机制,指的是依据设置的标签,对告警行为进行静默处理。
- 发送告警:支持配置多种告警规则,可以根据不同的路由配置,采用不同的告警方式发送告警通知。
- 告警分组:分组机制可以将详细的告警信息合并成一个通知。
Prometheus 和 AlertManager 的关系
二、分组、抑制、静默
分组
被触发的警报合并为一个警报进行通知,避免瞬间突发性的接受大量警报通知,使得管理员无法对问题进行快速定位。
场景:
在Kubernetes集群中,运行着重量级规模的实例,即便是集群中持续很小一段时间的网络延迟或者延迟导致网络抖动,也会引发大量类似服务应用无法连接 DB 的故障。如果在警报规则中定义每一个应用实例都发送警报,那么到最后的结果就是会有大量的警报信息通过Alertmanager发送给咱们的运维及研发小伙伴。
抑制
Inhibition 是 当某条警报已经发送,停止重复发送由此警报引发的其他异常或故障的警报机制。
场景:
在我们的灾备体系中,当原有集群故障宕机业务彻底无法访问的时候,会把用户流量切换到备份集群中,这样为故障集群及其提供的各个微服务状态发送警报机会失去了意义,此时, Alertmanager 的抑制特性就可以在一定程度上避免管理员收到过多无用的警报通知。
静默
Silences 提供了一个简单的机制,根据标签快速对警报进行静默处理;对传进来的警报进行匹配检查,如果接受到警报符合静默的配置,Alertmanager 则不会发送警报通知。
场景:
- 用于解决严重生产故障问题时,因所花费的时间过长,通过静默设置避免接收到过多的无用通知;
- 在已知的例行维护中,为了防止对例行维护的机器发送不必要的警报;
三、Alertmanager部署
基于k8s部署
PVC资源 alertmanager-storage.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager-pvc
namespace: monitor
spec:
accessModes:
- ReadWriteMany
storageClassName: "nfs-storage"
resources:
requests:
storage: 5Gi
ConfigMap(邮件方式)
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: monitor
data:
alertmanager.yml: |-
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.qq.com:465' # 邮箱服务器的SMTP主机配置
smtp_from: '123@qq.com' # 发送人
smtp_auth_username: '123@qq.com' # 登录用户名
smtp_auth_password: 'XXXX' # 此处的auth password是邮箱的第三方登录授权密码,而非用户密码
smtp_require_tls: false # 有些邮箱需要开启此配置,这里使用的是企微邮箱,仅做测试,不需要开启此功能。
templates:
- '/etc/alertmanager/*.tmpl'
route:
group_by: ['dba','dev','ops','group','job','alertname','cluster'] # 报警分组
group_wait: 5s # 在组内等待所配置的时间,如果同组内,5秒内出现相同报警,在一个组内出现。
group_interval: 1m # 如果组内内容不变化,合并为一条警报信息,2m后发送。
repeat_interval: 2m # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
receiver: 'ops' #默认接收者
routes:
#- receiver: 'dba'
# match:
# severity: critical
# group_wait: 5s
# group_interval: 5m
# repeat_interval: 30m
- receiver: 'dev'
match:
severity: critical
alertname: nginx service status is WODN
group_wait: 5s
group_interval: 5m
repeat_interval: 30m
- receiver: 'ops'
match:
severity: critical
alertname: EtcdNoLeader
group_wait: 5s
group_interval: 5m
repeat_interval: 30m
receivers:
- name: 'ops'
email_configs:
- to: '123@qq.com'
send_resolved: true
html: '{{ template "wechat.default.message" . }}'
- name: 'default-receiver'
email_configs:
- to: '123456789@qq.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
- name: 'dev'
email_configs:
- to: '123@163.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
inhibit_rules: # 抑制规则
- source_match:
alertname: 'node节点挂了'
instance: node13
target_match:
project: test-web #当node节点标签触发时,下面project的标签也就是nginx就会被抑制
- source_match:
severity: critical #当触发告警标签,severity=critical时,触发抑制规则,包含severity=warning的告警将被抑制
target_match:
severity: warning #包含severity=warning的告警将被抑制
equal:
- project #还添加了一个equal标签,作用就是source和target中都包含project这个标签,且他们的值一致时,才会抑制,比如nginx端口挂了,监控https的就会被抑制
#- source_match: # 源标签警报触发时抑制含有目标标签的警报,在当前警报匹配 servrity: 'critical'
# severity: 'critical'
# target_match:
# severity: 'warning' # 目标标签值正则匹配,可以是正则表达式如: ".*MySQL.*"
# equal: ['alertname', 'dev', 'instance'] # 确保这个配置下的标签内容相同才会抑制,也就是说警报中必须有这三个标签值才会被抑制。
wechat.tmpl: |-
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 告警恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
email.tmpl: |-
{{ define "email.from" }}xxx.com{{ end }}
{{ define "email.to" }}xxx.com{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{ range .Alerts }}
========= 监控报警 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
#触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
触发时间: {{ .alert.StartsAt.Local }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{ range .Alerts }}
========= 告警恢复 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- end }}
参数说明:
global:
resolve_timeout: 5m ##超时,默认5min
smtp_smarthost: 'smtp.exmail.qq.com:25'
smtp_from: 'xxxxxxx'
smtp_auth_username: 'xxxx'
smtp_auth_password: '123'
smtp_require_tls: false
templates: ##告警模板(可定义多个)
- '/etc/alertmanager/*.tmpl'
##route:用来设置报警的分发策略。Prometheus的告警先是到达alertmanager的根路由(route),alertmanager的根路由不能包含任何匹配项,因为根路由是所有告警的入口点
##另外,根路由需要配置一个接收器(receiver),用来处理那些没有匹配到任何子路由的告警(如果没有配置子路由,则全部由根路由发送告警),即缺省
##接收器。告警进入到根route后开始遍历子route节点,如果匹配到,则将告警发送到该子route定义的receiver中,然后就停止匹配了。因为在route中
##continue默认为false,如果continue为true,则告警会继续进行后续子route匹配。如果当前告警仍匹配不到任何的子route,则该告警将从其上一级(
##匹配)route或者根route发出(按最后匹配到的规则发出邮件)。查看你的告警路由树,https://www.prometheus.io/webtools/alerting/routing-tree-editor/,
##将alertmanager.yml配置文件复制到对话框,然后点击"Draw Routing Tree"
route:
group_by: ['env','instance','type','group','job','alertname','cluster'] ##用于分组聚合,对告警通知按标签(label)进行分组,将具有相同标签或相同告警名称(alertname)的告警通知聚合在一个组,然后作为一个通知发送。如果想完全禁用聚合,可以设置为group_by: [...]
group_wait: 10s ##当一个新的告警组被创建时,需要等待'group_wait'后才发送初始通知。这样可以确保在发送等待前能聚合更多具有相同标签的告警,最后合并为一个通知发送
group_interval: 2m ##当第一次告警通知发出后,在新的评估周期内又收到了该分组最新的告警,则需等待'group_interval'时间后,开始发送为该组触发的新告警,可以简单理解为,group就相当于一个通道(channel)
repeat_interval: 10m ##告警通知成功发送后,若问题一直未恢复,需再次重复发送的间隔(根据实际情况来调整)
receiver: 'email' ##配置告警消息接收者,与下面配置的对应,例如常用的 email、wechat、slack、webhook 等消息通知方式。
routes: ##子路由
- receiver: 'wechat'
match: ##通过标签去匹配这次告警是否符合这个路由节点;也可以使用match_re进行正则匹配
severity: error ##标签severity为error时满足条件使用wechat警报
continue: true ##匹配到这个路由后是否继续匹配,默认flase
receivers: ##配置报警信息接收者信息
- name: 'email' ##警报接收者名称
email_configs:
- to: 'xxxxxx' ##接收警报的email(可引用模板文件中定义的变量),可定义多个
## html: '{{ template "email.to.html" .}}' ##发送邮件的内容(调用模板文件中的)
helo: 'alertmanager.com' #alertmanager的地址
send_resolved: true #故障恢复后通知
- name: 'wechat'
wechat_configs:
- corp_id: xxxxxxxxx ##企业信息
to_user: '@all' ##发送给企业微信用户的ID,这里是所有人
agent_id: xxxxx ##企业微信AgentId
api_secret: xxxxxxxxx ##企业微信Secret
## message: '{{ template "wechat.default.message" .}}' ##发送内容(调用模板里面的微信模板)
send_resolved: true ##故障恢复后通知
inhibit_rules: ##抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitor
labels:
k8s-app: alertmanager
spec:
replicas: 1
selector:
matchLabels:
k8s-app: alertmanager
template:
metadata:
labels:
k8s-app: alertmanager
spec:
containers:
- name: alertmanager
image: prom/alertmanager:v0.24.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 31093
args:
## 指定容器中AlertManager配置文件存放地址 (Docker容器中的绝对位置)
- "--config.file=/etc/alertmanager/alertmanager.yml"
## 指定AlertManager管理界面地址,用于在发生的告警信息中,附加AlertManager告警信息页面地址
- "--web.external-url=https://alertmanager.kubernets.cn"
## 指定监听的地址及端口
- '--cluster.advertise-address=0.0.0.0:31093'
## 指定数据存储位置 (Docker容器中的绝对位置)
- "--storage.path=/alertmanager"
resources:
limits:
cpu: 1000m
memory: 512Mi
requests:
cpu: 1000m
memory: 512Mi
readinessProbe:
httpGet:
path: /-/ready
port: 31093
initialDelaySeconds: 5
timeoutSeconds: 10
livenessProbe:
httpGet:
path: /-/healthy
port: 31093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: data
mountPath: /alertmanager
- name: config
mountPath: /etc/alertmanager
- name: configmap-reload
image: jimmidyson/configmap-reload:v0.7.1
args:
- "--volume-dir=/etc/config"
- "--webhook-url=http://localhost:31093/-/reload"
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/config
readOnly: true
volumes:
- name: data
persistentVolumeClaim:
claimName: alertmanager-pvc
- name: config
configMap:
name: alertmanager-config
查看启动状态
kubectl -n monitor logs -f alertmanager-6786c86556-2jlpj alertmanager

创建svc.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: monitor
labels:
k8s-app: alertmanager
spec:
type: NodePort
ports:
- name: http
port: 31093
targetPort: 31093
nodePort: 31093
selector:
k8s-app: alertmanager
ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: monitor
name: alertmanager-ingress
spec:
ingressClassName: nginx
rules:
- host: alertmanager.kubernets.cn
http:
paths:
- pathType: Prefix
backend:
service:
name: alertmanager
port:
number: 31093
path: /
访问验证:
$ curl http://alertmanager.kubernets.cn
四、Prometheus添加告警配置
修改ConfigMap资源文件prometheus-config.yaml,改动内容如下:
- 添加AlertManager服务器地址
- 指定告警规则文件路径位置
- 添加Prometheus中触发告警的告警规则(已经简单添加了2条)
k8s部署添加
修改 prometheus-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
cluster: "kubernetes"
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:31093']
############ 数据采集job ###################
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['127.0.0.1:9090']
labels:
instance: prometheus
按上面方法重载 Prometheus,打开 Prometheus 的 Target 页面,就会看到 上面定义的 mysql-exporter 任务
kubectl apply -f prometheus-config.yaml
kubectl apply -f prometheus-deploy.yaml
url -XPOST http://10.0.0.0.12:30090/-/reload
查看
五、Alertmanager配置解析
alertmanager配置一般分为以下五个部分
- 全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置、Slack配置等。
- 模版(templates):用于定义告警通知时的模板,如HTML模板、邮件模板等。
- 告警路由(route):根据标签匹配,确定当前告警应该如何处理。
- 接收者(receivers):接收者是一个抽象的概念,它可以是一个邮箱,也可以是微信、Slack或者Webhook等。接收者一般配合告警路由使用。
- 抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生。
全局配置
- 用于定义一些全局的公共参数,如全局的SMTP配置、Slack配置等。
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.qq.com:465' # 邮箱服务器的SMTP主机配置
smtp_from: '1748310713@qq.com' # 发送人
smtp_auth_username: '1748310713@qq.com' # 登录用户名
smtp_auth_password: 'rebmydxljnawfaie' # 此处的auth password是邮箱的第三方登录授权密码,而非用户密码
smtp_require_tls: false # 有些邮箱需要开启此配置,这里使用的是企微邮箱,仅做测试,不需要开启此
模板
- 用于定义告警通知时的模板,如HTML模板、邮件模板等。
templates:
- '/etc/alertmanager/*.tmpl'
告警路由
- 根据标签匹配,确定当前告警应该如何处理
# 每个告警信息进入的根路由,用于设置告警的分发策略
route:
# 根路由不能有任何匹配器,因为它是所有告警的入口点。它需要配置一个接收器,以便将不匹配任何
# 子路由的告警发送出去,receiver的默认值为default,如果某条告警没有被一个route匹配,
# 则发送给默认的接收器
receiver: 'team-X-mails'
# 将多个告警匹配聚合到单个组中,这将完全禁用聚合,按原样传递所有告警。例如,group_by: […]
group_by: ['alertname', 'cluster']
# 当一个新的告警组被创建时,至少要等待'group_wait'时间来发送初始通知。通过这种方式,
# 可以确保有足够多的时间为同一份组获取多条告警,然后一起触发这些告警信息
group_wait: 30s
# 在发送完第一条告警以后,等待group_interval时间来发送一组新的告警信息
group_interval: 5m
# 如果告警已成功发送,则等待'repeat_interval'时间重新发送它们
repeat_interval: 3h
# 所有上述属性是根路由的内容,由所有子路由继承,并且可以覆盖每个子路由
routes:
# 此路由对告警标签执行正则表达式匹配,以捕捉与服务列表相关的告警
- matchers:
- service=~"^(foo1|foo2|baz)$"
receiver: team-X-mails
# 该服务有一个用于紧急告警的子路由,任何不匹配的告警,!= severity: critical,
# 都会退回到父节点并发送到“team- x -mail”
routes:
- matchers:
- severity="critical"
receiver: team-X-pager
- matchers:
- service="files"
receiver: team-Y-mails
routes:
- matchers:
- severity="critical"
receiver: team-Y-pager
# 此路由处理来自数据库服务的所有告警。如果没有团队来处理它,则默认由DB团队处理
- matchers:
- service="database"
receiver: team-DB-pager
# 还可以根据受影响的数据库对告警进行分组
group_by: [alertname, cluster, database]
routes:
- matchers:
- owner="team-X"
receiver: team-X-pager
- matchers:
- owner="team-Y"
receiver: team-Y-pager
接收者
receivers:
- name: 'ops'
webhook_configs:
- url: http://10.0.0.11:31008/prometheusalert?type=dd&tpl=dd-test&ddurl=https://oapi.dingtalk.com/robot/send?access_token=6081ef0eaec970f0ef3e5f2799f46a8b0e3c343744ec90e990f212b07910f03c
- name: 'dev'
email_configs:
- to: '13168993708@163.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
- name: 'dba'
email_configs:
- to: '13168993708@163.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
抑制规则
inhibit_rules: # 抑制规则
- source_match:
alertname: 'node节点挂了'
instance: node13
target_match:
project: test-web # 当node节点标签触发时,下面project的标签也就是nginx就会被抑制
- source_match:
severity: critical # 当触发告警标签,severity=critical时,触发抑制规则,包含severity=warning的告警将被抑制
target_match:
severity: warning # 包含severity=warning的告警将被抑制
equal:
- project # 还添加了一个equal标签,作用就是source和target中都包含project这个标签,且他们的值一致时,才会抑制,比如nginx端口挂了,监控https的就会被抑制
# - source_match: # 源标签警报触发时抑制含有目标标签的警报,在当前警报匹配 servrity: 'critical'
# severity: 'critical'
# target_match:
# severity: 'warning' # 目标标签值正则匹配,可以是正则表达式如: ".*MySQL.*"
# equal: ['alertname', 'dev', 'instance'] # 确保这个配置下的标签内容相同才会抑制,也就是说警报中必须有这三个标签值才会被抑制。
测试告警规则
curl -X POST http://10.0.0.11:9093/api/v1/alerts \
-H "Content-Type: application/json" \
-d '[
{
"labels": {
"alertname": "主机内存高",
"job": "node-exporter",
"instance": "node01",
"severity": "warning",
"application": "NodeExporter"
},
"annotations": {
"description": "主机内存利用率过高",
"summary": "主机内存高",
"value": "node01"
},
"startsAt": "2024-07-02T09:36:01.979669601Z"
}
]'
v2接口
curl -XPOST -H 'Content-Type: application/json' \
http://IP:9093/api/v1/alerts -d \
'[{"labels":{"severity":"critical"},"annotations":{"summary":"测试一下告警"}}]'
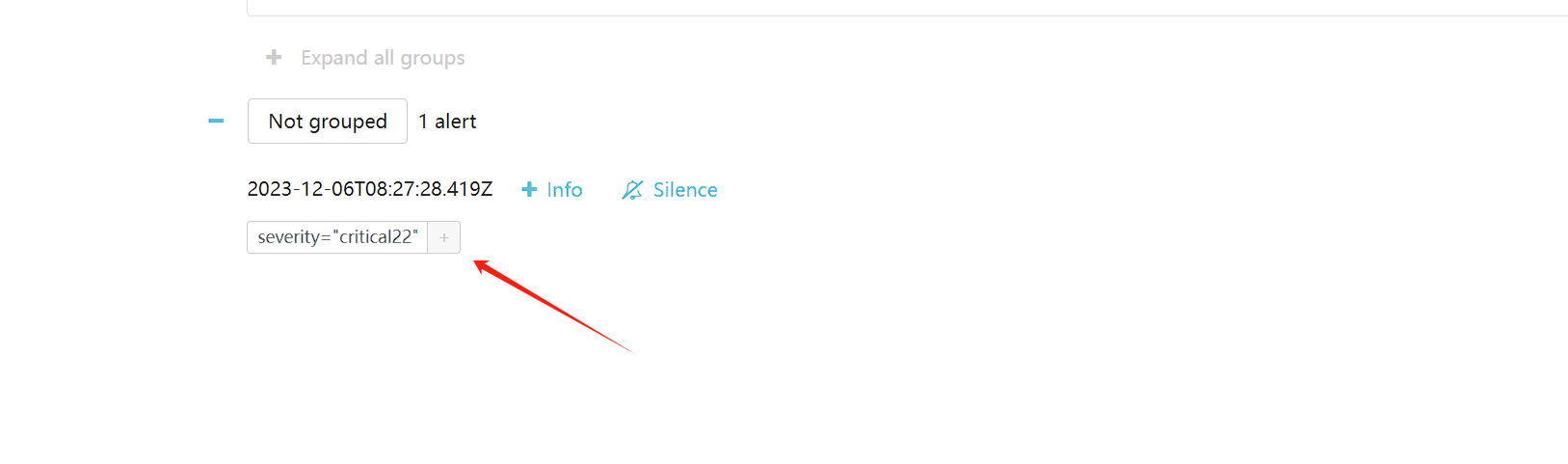
Prometheus UI查看配置和告警规则是否生效
本文来自博客园,作者:&UnstopPable,转载请注明原文链接:https://www.cnblogs.com/Unstoppable9527/p/18336865

 浙公网安备 33010602011771号
浙公网安备 33010602011771号