第二次结对编程作业
在文章开头给出结对同学的博客链接、本作业博客的链接、你所Fork的同名仓库的Github项目地址(2分)
前言
我更喜欢麻将。
具体分工
邱畅杰:后端
孙承恺:前端
很简洁的分工
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 80 |
| Estimate | 估计这个任务需要多少时间 | 120 | 80 |
| Development | 开发 | 2990 | 3330 |
| Analysis | 需求分析(包括学习新技术) | 60 | 60 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范(为开发制定合适的规范) | 30 | 180 |
| Design | 具体设计 | 180 | 240 |
| Coding | 具体编码 | 2500 | 2550 |
| Code Review | 代码复审 | 60 | 120 |
| Test | 测试(自我测试,修改,提交修改) | 100 | 120 |
| Reporting | 报告 | 80 | 100 |
| Test Report | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结并提出过程改进计划 | 40 | 60 |
| 合计 | 3190 | 3510 |
解题思路描述与设计实现说明
网络接口的使用
出于对于处理方便的考虑,使用python的requests模块访问来自永福上游服务器的restful API,并且封装成了如下五个函数。
| 接口函数 | 功能 |
|---|---|
| login | 发送登入请求 |
| register | 发送注册请求 |
| find_info | 查询战局信息 |
| rank | 获取排行榜 |
| srank | 获取个人战局列表 |
代码组织与内部实现设计
事前准备
我们小队在开始设计程序前对题目做了一些简单的数学分析,当作为我方拿到13张牌的时候,所考虑的目标是摆出当前我们手上认为最大的牌,并且别人不能摆出超过我方当前所摆的牌。在这个条件下我们可以设总牌型数为N,摆出的牌型可以打过其他牌型的数为t,则t/N可以简单的认为这副牌的理想获胜率。
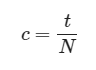
则权重可以简单的设定为
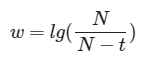
但是往往只考虑手上的牌不足以做出决策,还应当考虑可以胜过我方牌型的组合出现在对手手上的概率,我们将此概率设为s。则c*(1-s)可以简单认为是这副牌的相对获胜率:

往往,c越大,则s越小,这个还没有证明过。
下面是算法实现过程:
准备工作:寻找一个写好了扑克牌基本框架的可用库,能节约再搭建底层的时间,这里采用的是一个非常简单的第三方库叫poker。中文文档,使用了其中最简单的每张牌的初始化。前后端均采用python实现,以前写前端只接触过html+css,破天荒的用PyQT来实现这次的前端页面。
第一步:定义一个leveldict标记每种牌型的权值和各种提前准备

| 准备函数 | 功能 |
|---|---|
| make_suit | 获取当前手牌的花色dict |
| make_rank | 获取当前手牌的牌值dict |
| Weight_init | 初始化牌型矩阵权重 |
| Times_init | 初始化好奇心矩阵权重 |
| Compare_down | 比较两副牌第一墩大小 |
| Compare_up | 比较两副牌第二墩或第三墩大小(可比较一副牌二三墩是否倒水) |
| Compare_gap | 比较一副牌第一墩和第二墩是否倒水 |
| Compare_combo | 算出完整的两副牌的输赢 |
| Tips:牌型权重比如第一墩为0(散牌)第二墩为3(连对)第三墩为5(顺子)的情况,就将Weight[0][3][5]初始化为(0+3+5)/100其他以此类推。好奇心权重每个位置初始化为1,后面训练的时候才用到这俩。 |
第二步:用类dfs其实也就是无脑遍历所有可能(第一墩等级有可能为0-4也就是散牌到三条,第二墩有可能是0-9也就是散牌到同花顺,第三墩同理)总共5* 10 *10可能,将当前牌能组成的组合类型得出
类一:choose_action_option(Hand,color_dict,rank_dict)
参数:手牌和前面两个函数得到的两个dict
功能:根据当前手牌给出各种牌型的dict
返回:

| 类内方法 | 功能 | 返回 |
|---|---|---|
| Flush_Collection | 判断同花顺 | 同花顺花色和该顺最后一张牌牌值的list |
| Bomb | 判断炸弹 | 炸弹牌牌值的list |
| Gourd | 判断葫芦 | 葫芦牌中三条部分和可能的所有对子组成的list |
| Flush | 判断同花 | 同花的花色牌和能组成同花的5张牌中最大的牌值 |
| Collection | 判断顺子 | 该顺最后一张牌牌值的list |
| Three | 判断三条 | 三条牌牌值的list |
| Pair | 判断对子 | 对子牌牌值的list |
Tips:此处后面为什么是函数而不是类了呢。。当然是因为方便调试!(懒得写了。函数比较方便。。)
| 主要函数 | 功能 | 返回 |
|---|---|---|
| choose_step_sb(choose_) | 根据类返回的dict返回所有可能的牌型 | 包含了0-9所有可能牌型的dict |
| action_step_sb(Hand,choose_,shape,rank,suit) | 根据牌型dict对当前手牌进行更改 | 某墩的牌型和剩下的手牌 |
| action_step_add(Hand_three,Hand_two,Hand_rest,shape,rank,suit) | 将三墩牌完善 | 包含了三墩牌和各自牌型大小的dict |
| judge_right | 判断牌型的合理性 | True表示该三墩牌摆的合法 |
Tips:这里仅仅获得了手牌的一种排法的dict,包含了三墩的牌和各自的大小
第三步:由第二步得到的各种牌型可能训练权重
没错!这里我还是因为方便调试!只写了一个函数来训练它,甚至都没脸画表了!
主要函数:begin_game(myhand_need,Weight,Times,beta,is_Train,Auto,b,real)
| 参数 | 说明 |
|---|---|
| Weight | 牌型矩阵,决定了选某种牌型组合的可能性 |
| Times | 好奇心矩阵,记录了每种牌训练时遇到的次数 |
| beta | 我将其取名为好奇心削减指数,用来减弱训练时对某种经常出现的牌型的好奇心 |
| is_Train | 是否是训练情况,True时训练,False时把当前最大可能的牌型输出 |
| Auto | 人工训练还是自动训练 |
| b | 牌局中其他人的情况,若is_Train则为其他三人的牌,否则是None |
| real | 是否是真实比赛场景 |
| 训练第一步,从智障做起:上面第二步得到的第一种排法必然是从第三墩无脑最大,第二墩也无脑最大的类型,牌桌上的另外三副牌都用无脑大大大排出,自己则遍历手牌能排出的所有组合跟兄弟们的无脑大大大比较,根据赢输的reward回归(可能都不配叫回归)更改权重。 | |
| 训练第二步,利用智商击败智障:训练完第一步后得到了一个较为合理的权重矩阵,调real=True,牌桌上的另外三人仍然是大大大,但自己是根据现有牌型去牌型矩阵中找出最大可能的排出结果,用这副牌跟兄弟们比较,回归。 | |
| 训练第三步,利用智商击败智商,牌桌上四个人都从手牌牌型的可能中找权重矩阵中最大权重的牌型,回归。 | |
| Tips:reward即输赢的水 | |
| 回归方式: | |
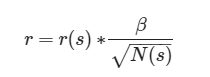 |
|
| r(s)即输赢的水,β即好奇心削减指数,N(s)即Times矩阵中记忆的次数 |
说明算法的关键与关键实现部分流程图
经由两个初始函数得到牌值dict和花色dict
经由choose_step_sb得到各牌型的dict(无论有无)
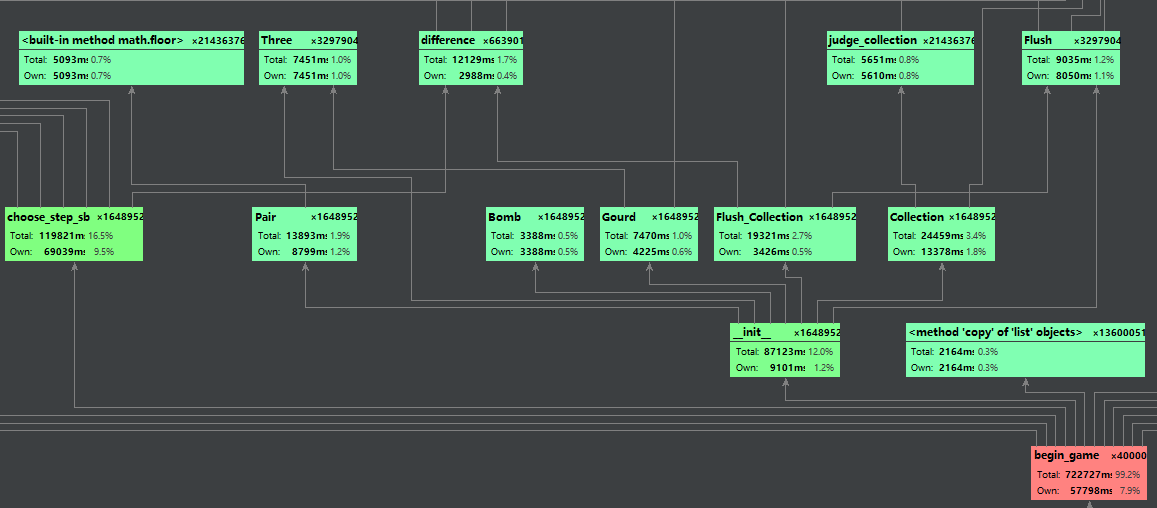
经由action_step_sb和action_step_add得到完整一副牌的摆法
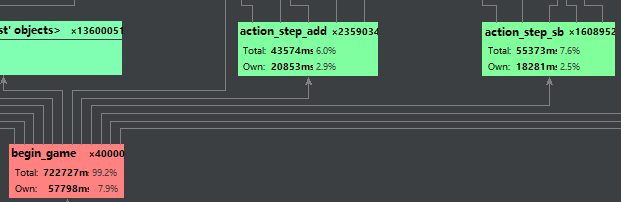
经由judge_right得到这种摆法的合法性
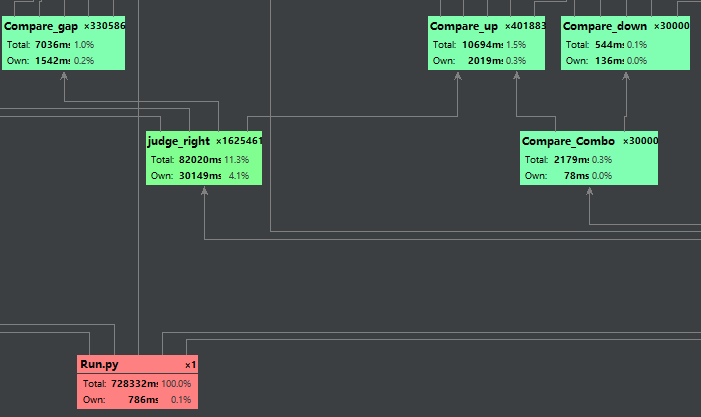
合法则开始训练。
前端与后端其余部分
前端主要页面划分如下
一个界面对应一个类和py文件相互独立,由统一的main.py文件进行组织,单mainbox,多窗体。
| 界面 | 类名 |
|---|---|
| 登陆与欢迎 | Index |
| 注册 | Register |
| 主界面 | MainIndex |
| 查询界面 | Search |
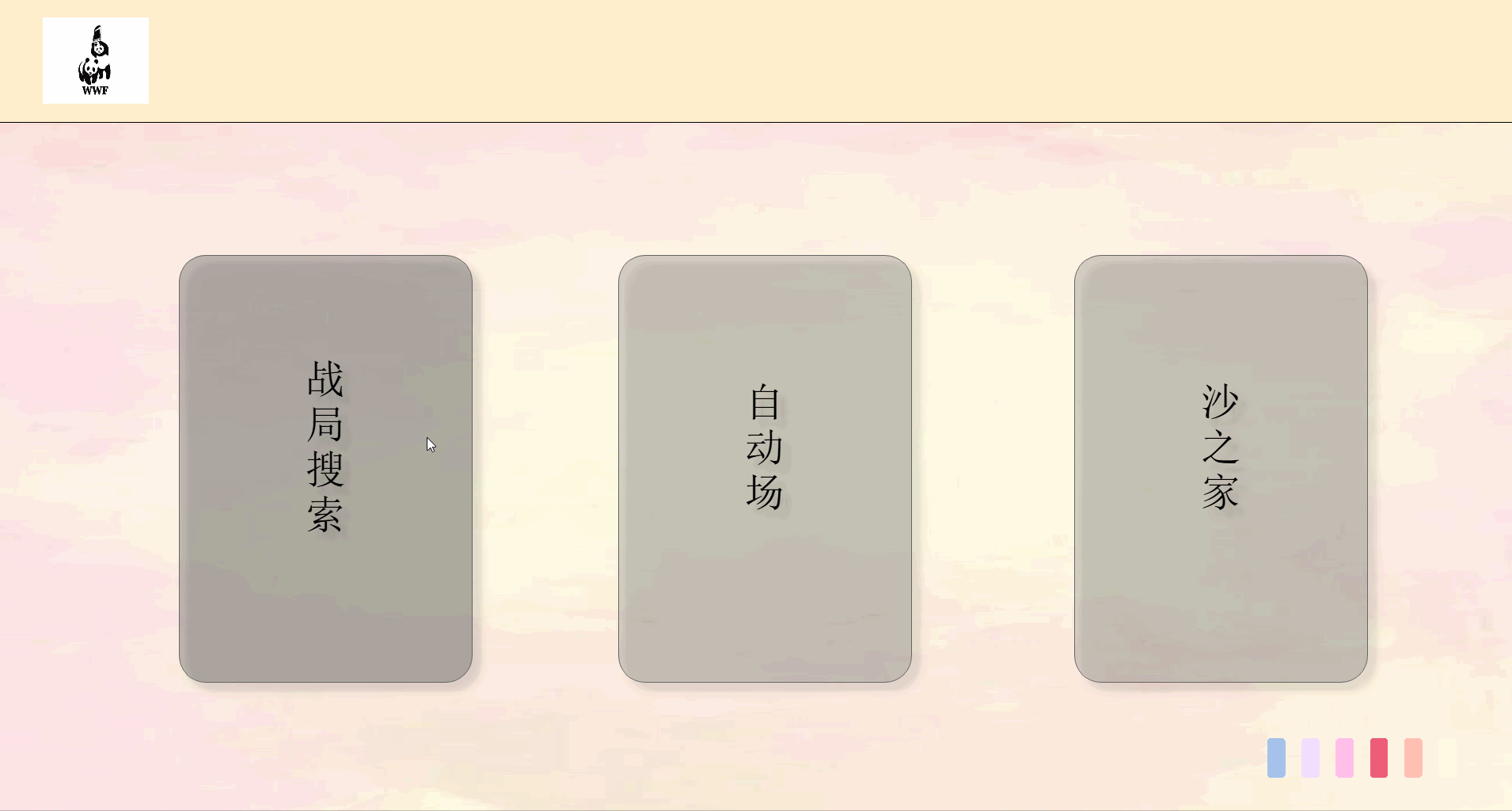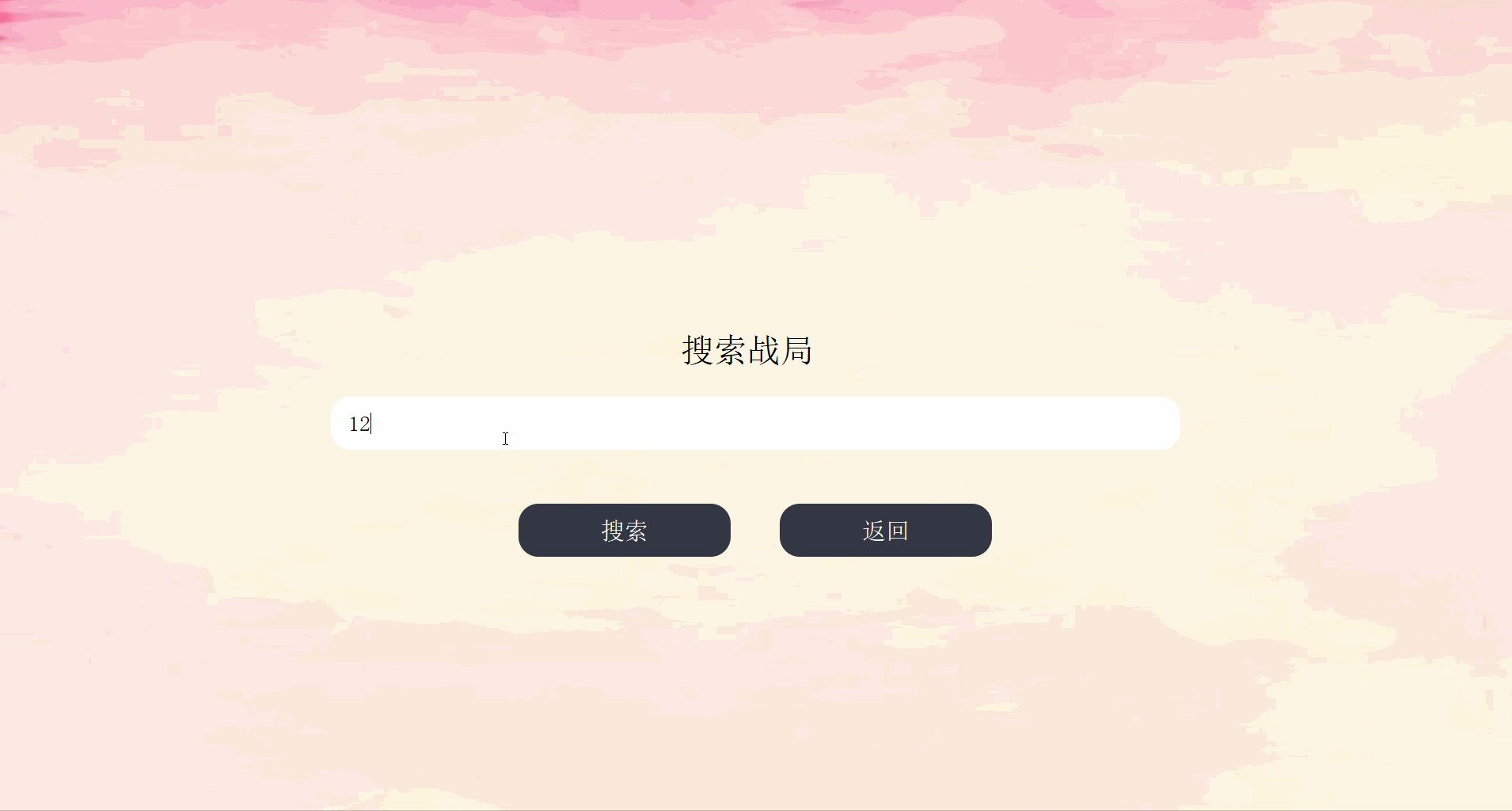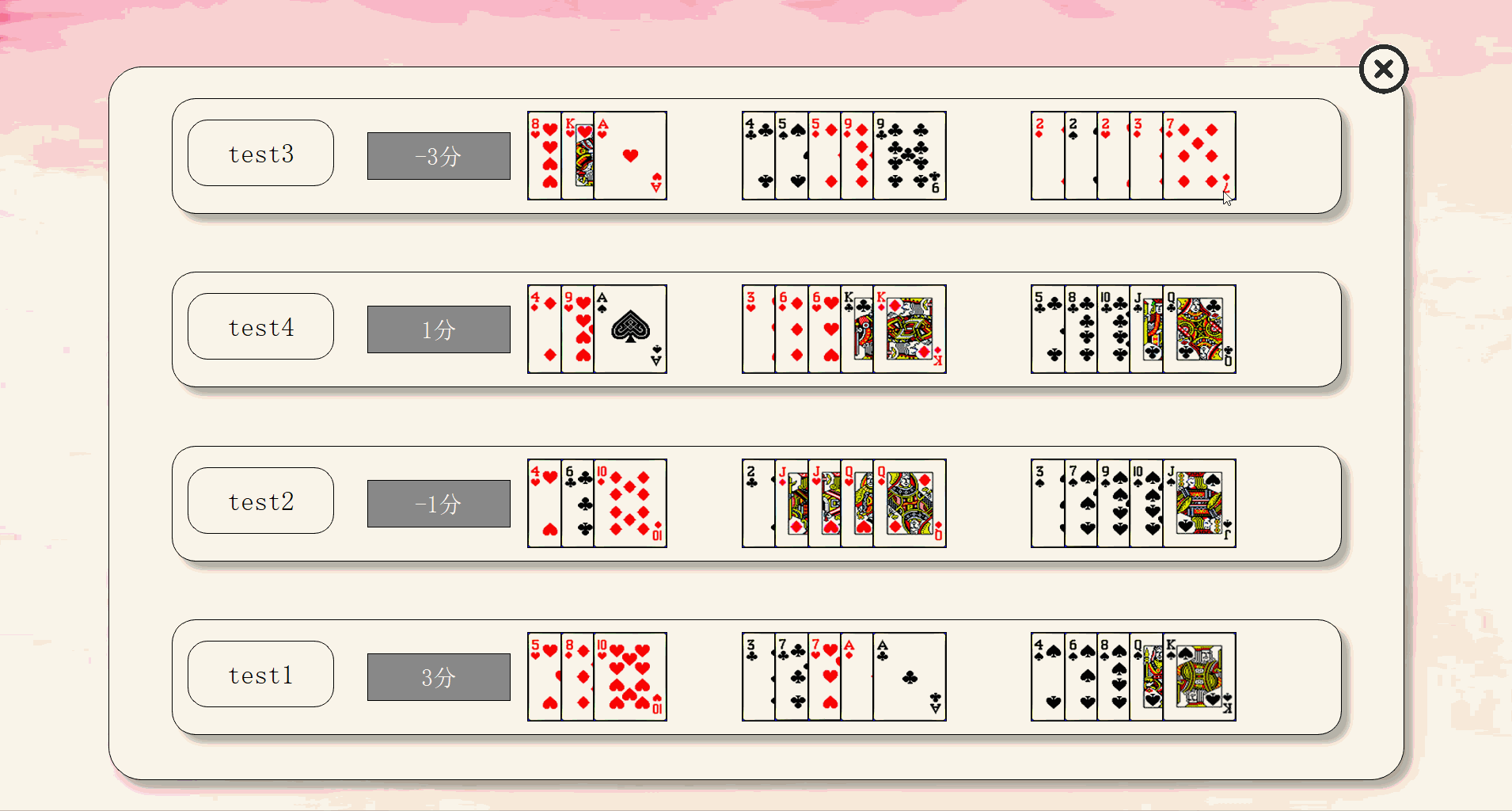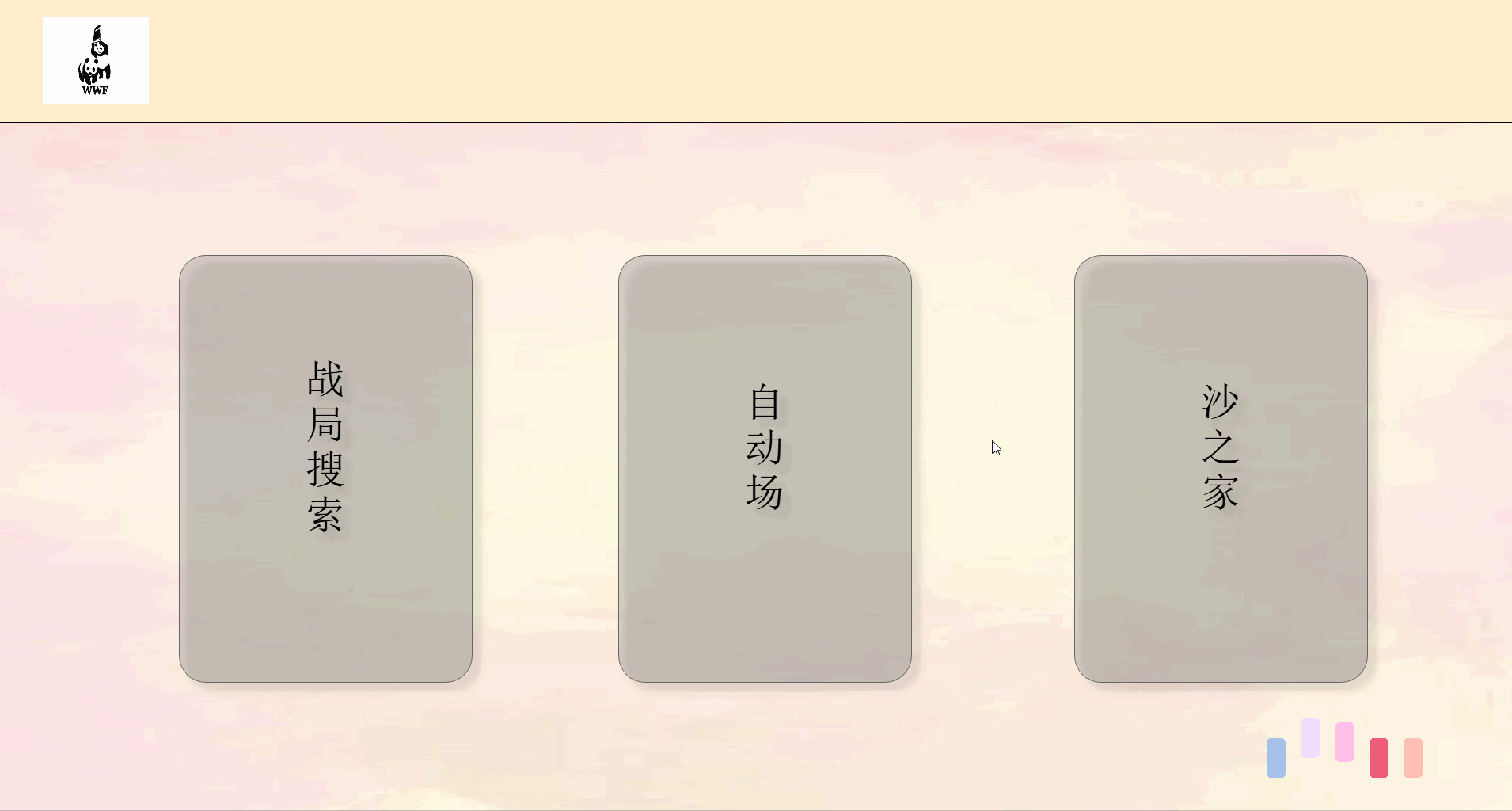
| 自动出牌结果界面 | ResultSingle |
| 战局信息界面 | Result |
| 个人中心 | Home |
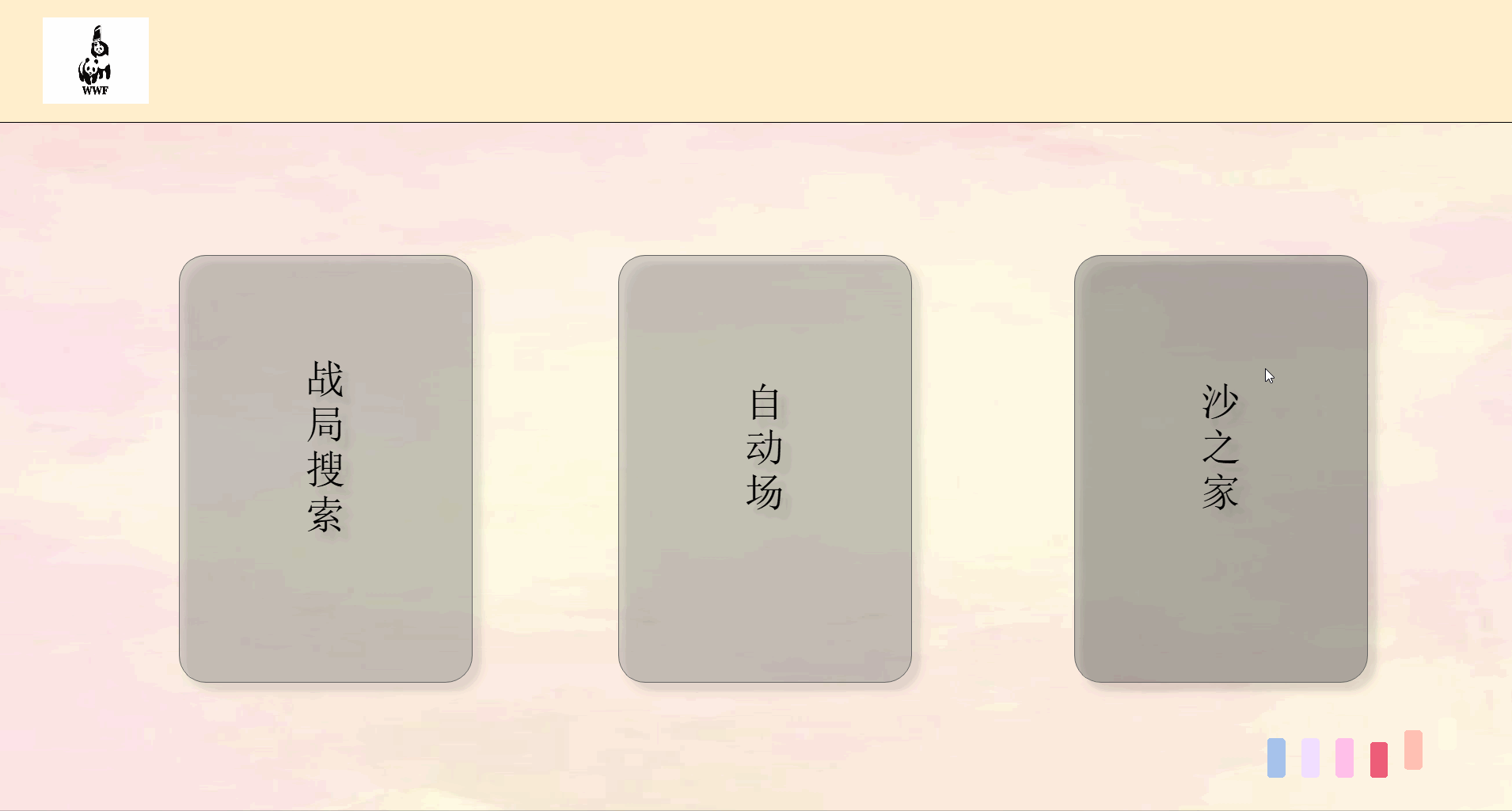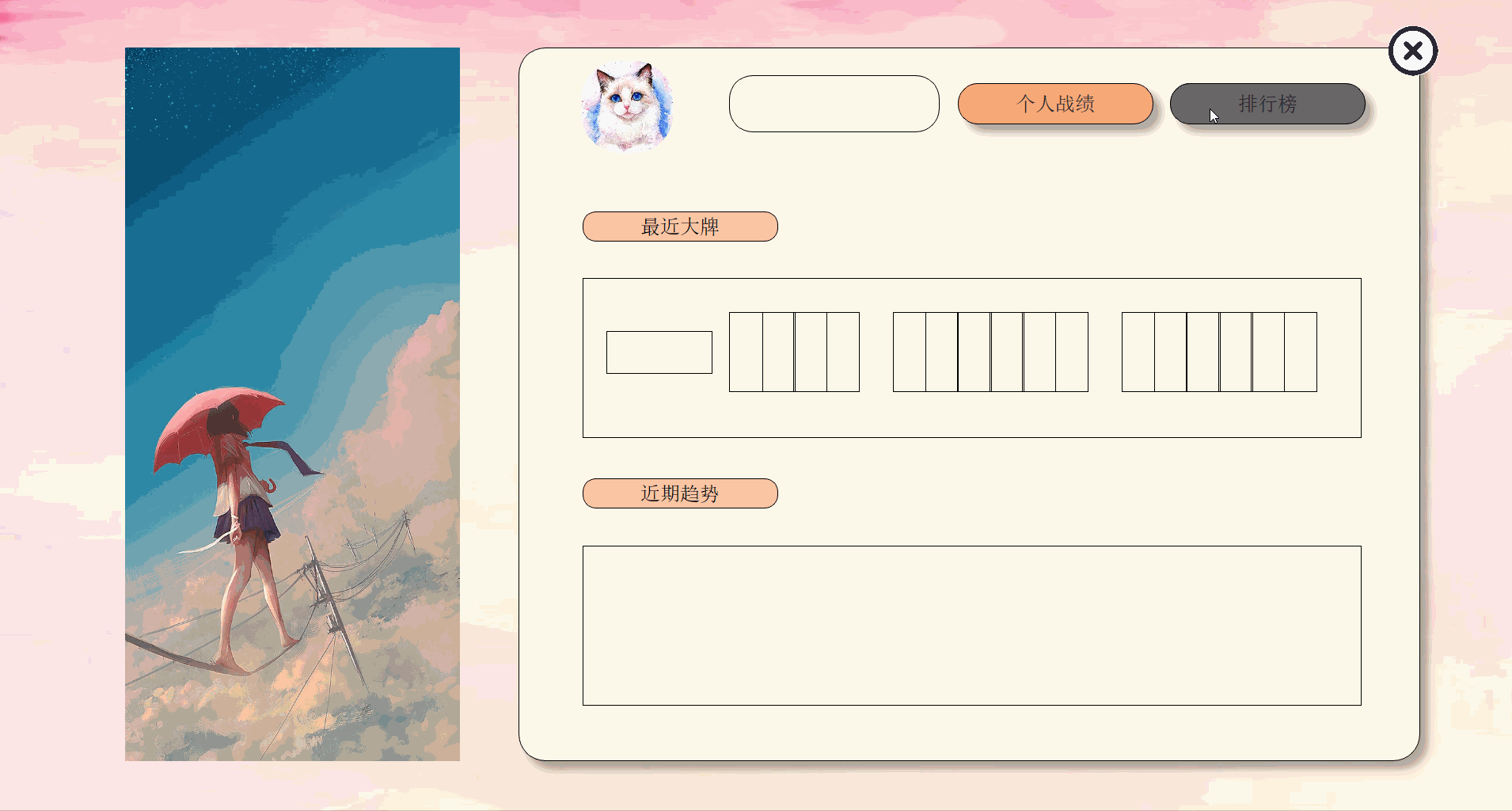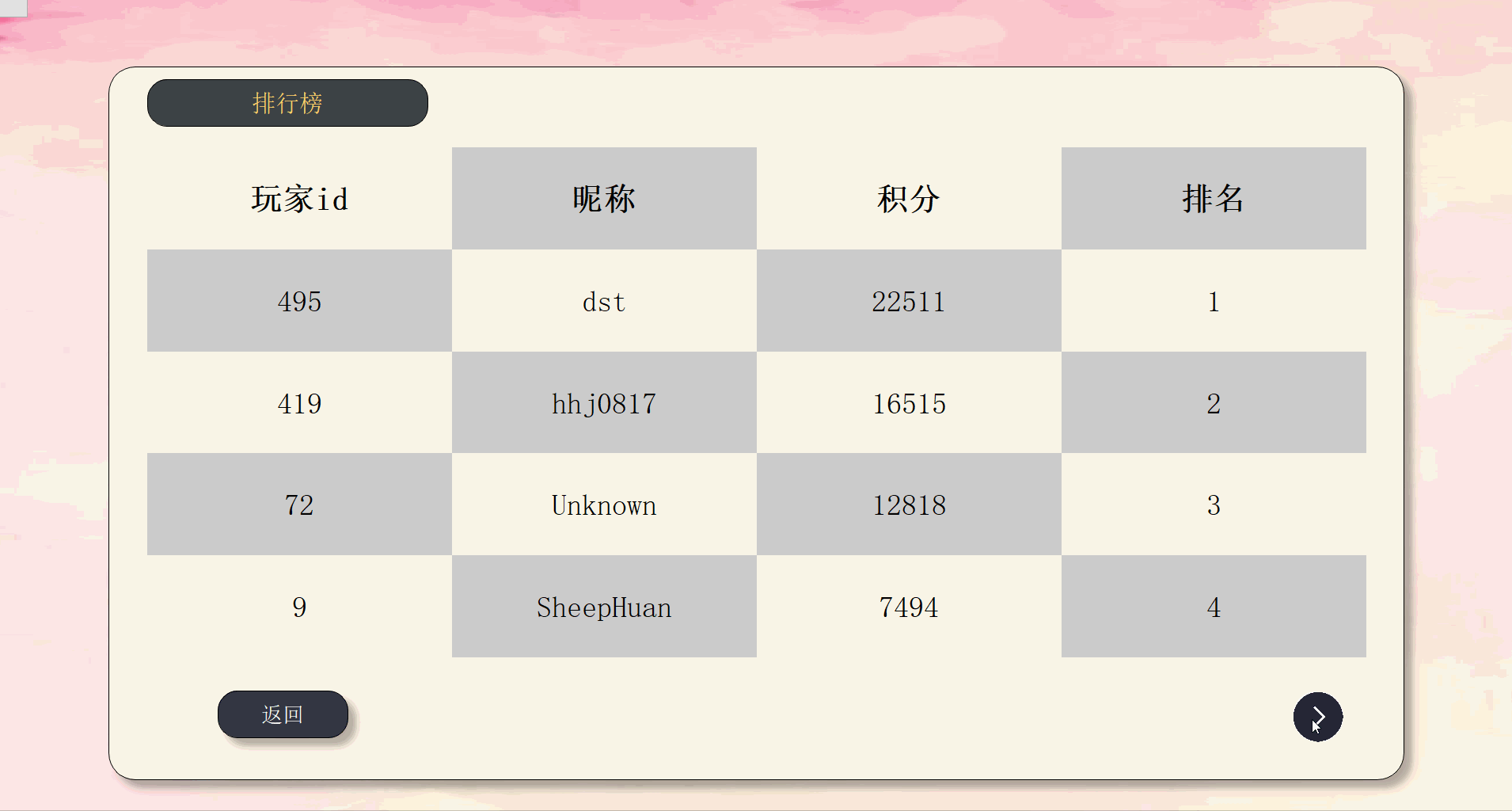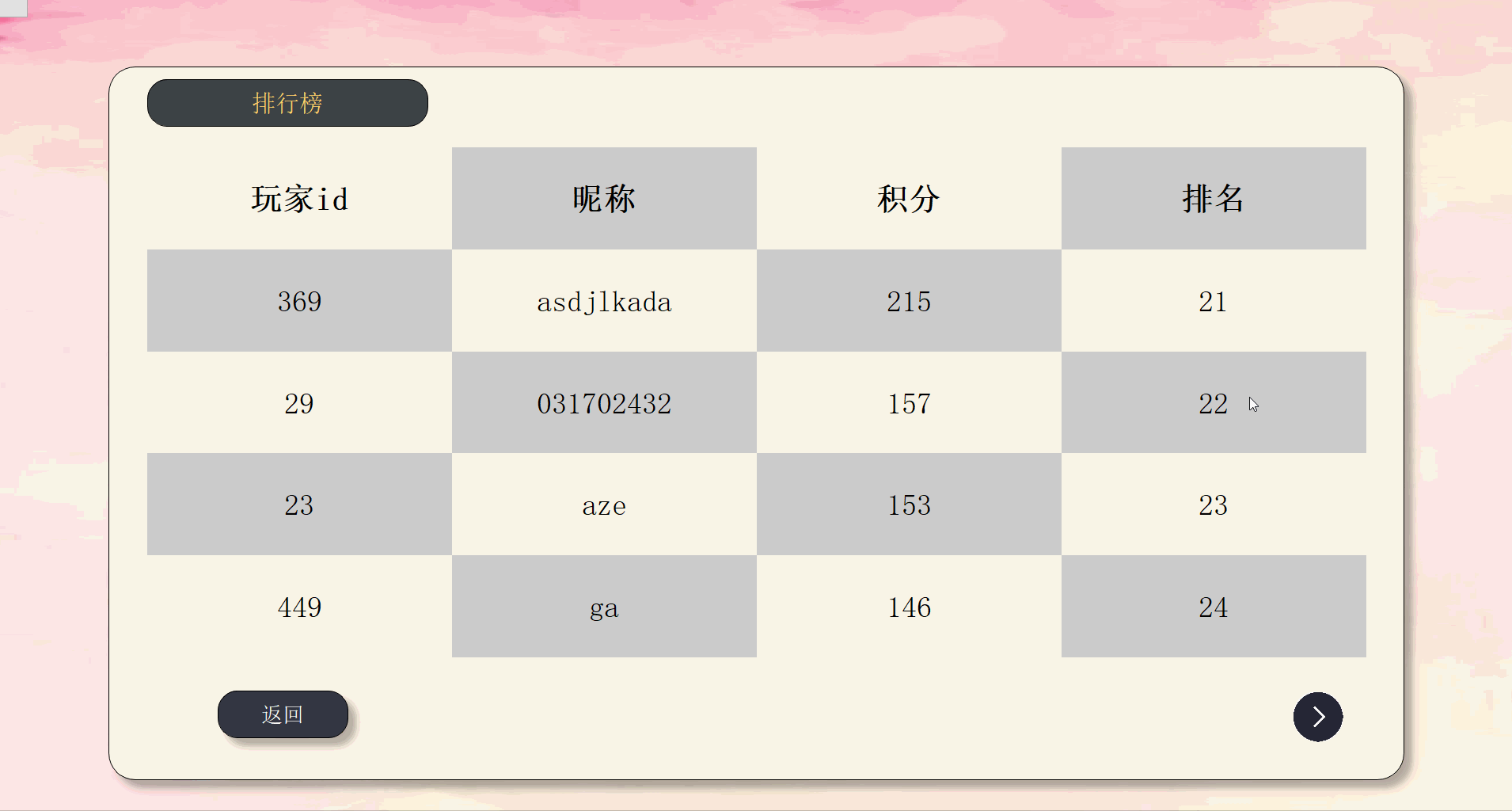
| 排行榜 | Rank |
| 个人战绩 | SingleRank |
与后端的接口如下:
| 接口函数 | 功能 |
|---|---|
| login | 登陆验证 |
| register | 注册 |
| play | 进行自动游戏 |
| find_infp | 查看战局信息 |
| rank | 查看排行榜 |
| srank | 查看个人记录 |
最终效果如下:
由于上传大小限制,拆分成5个部分来演示。

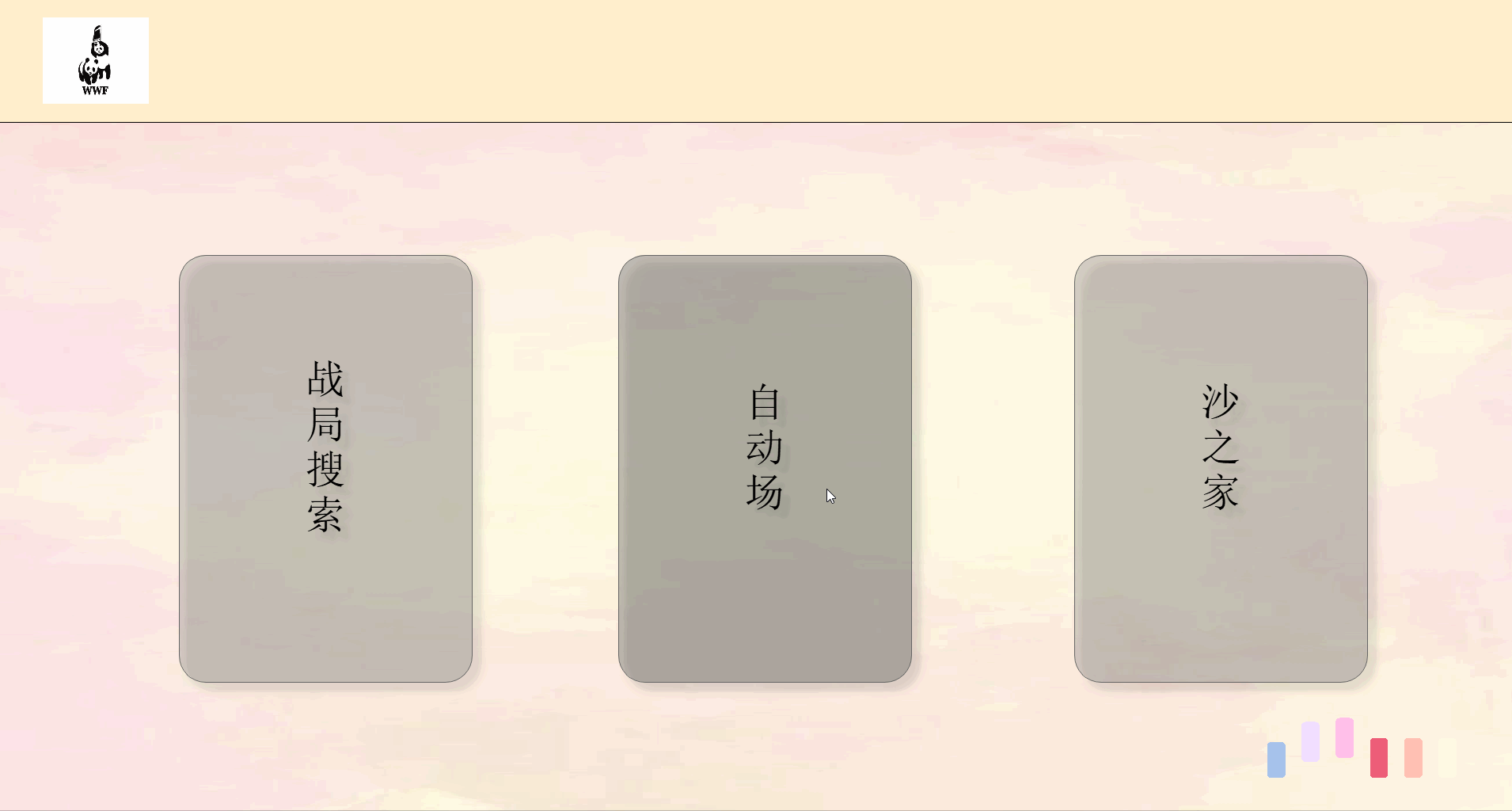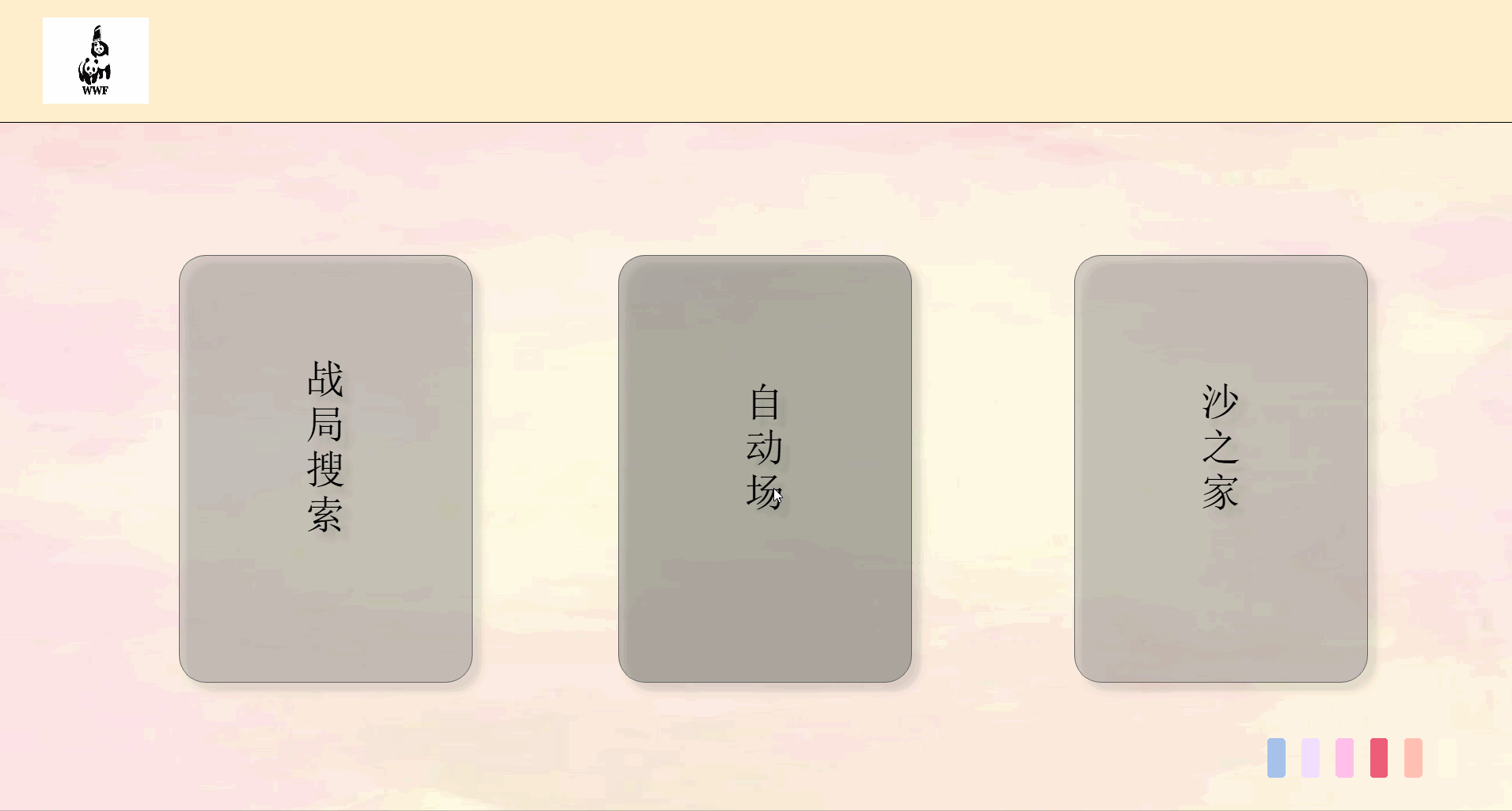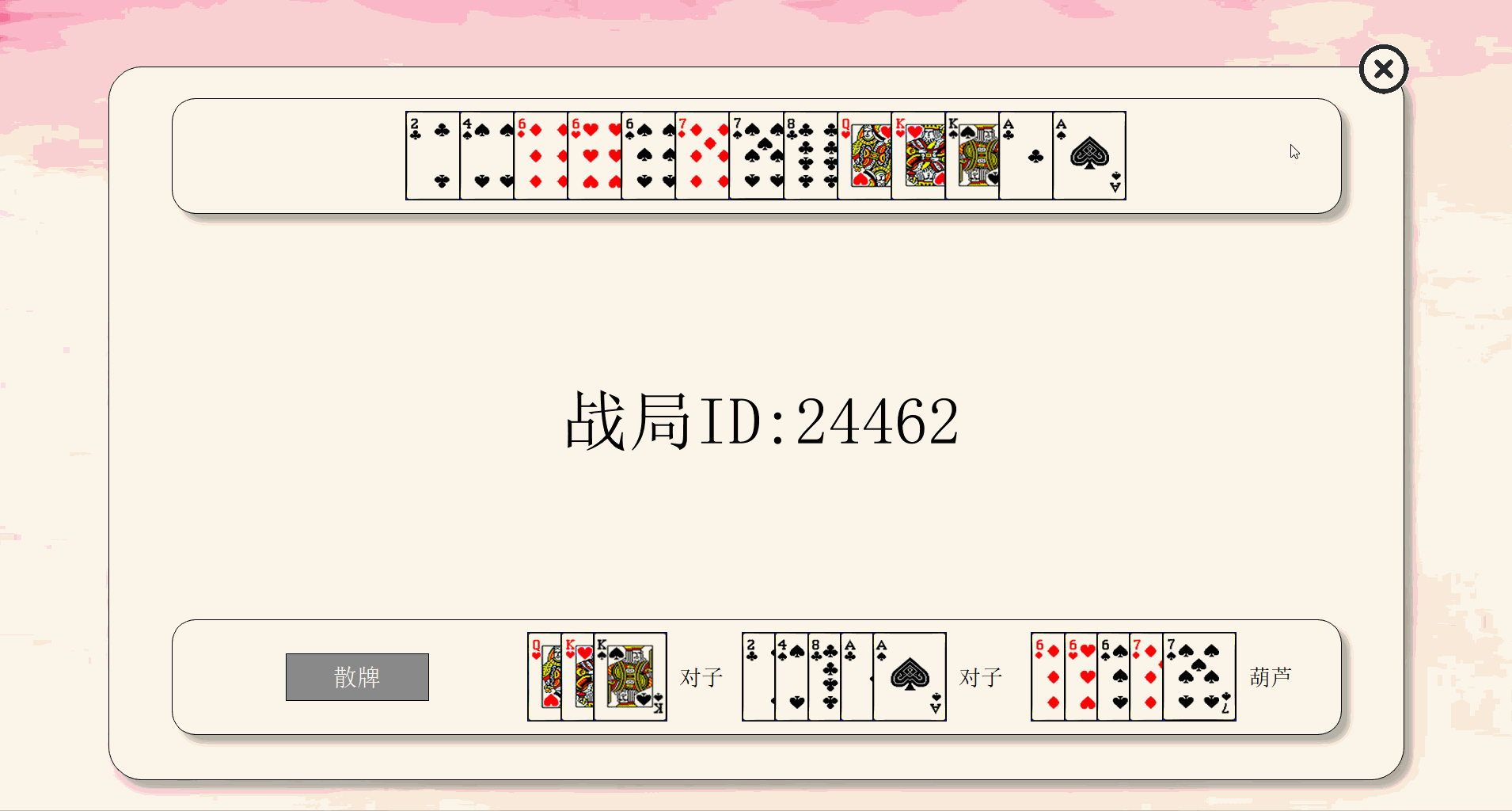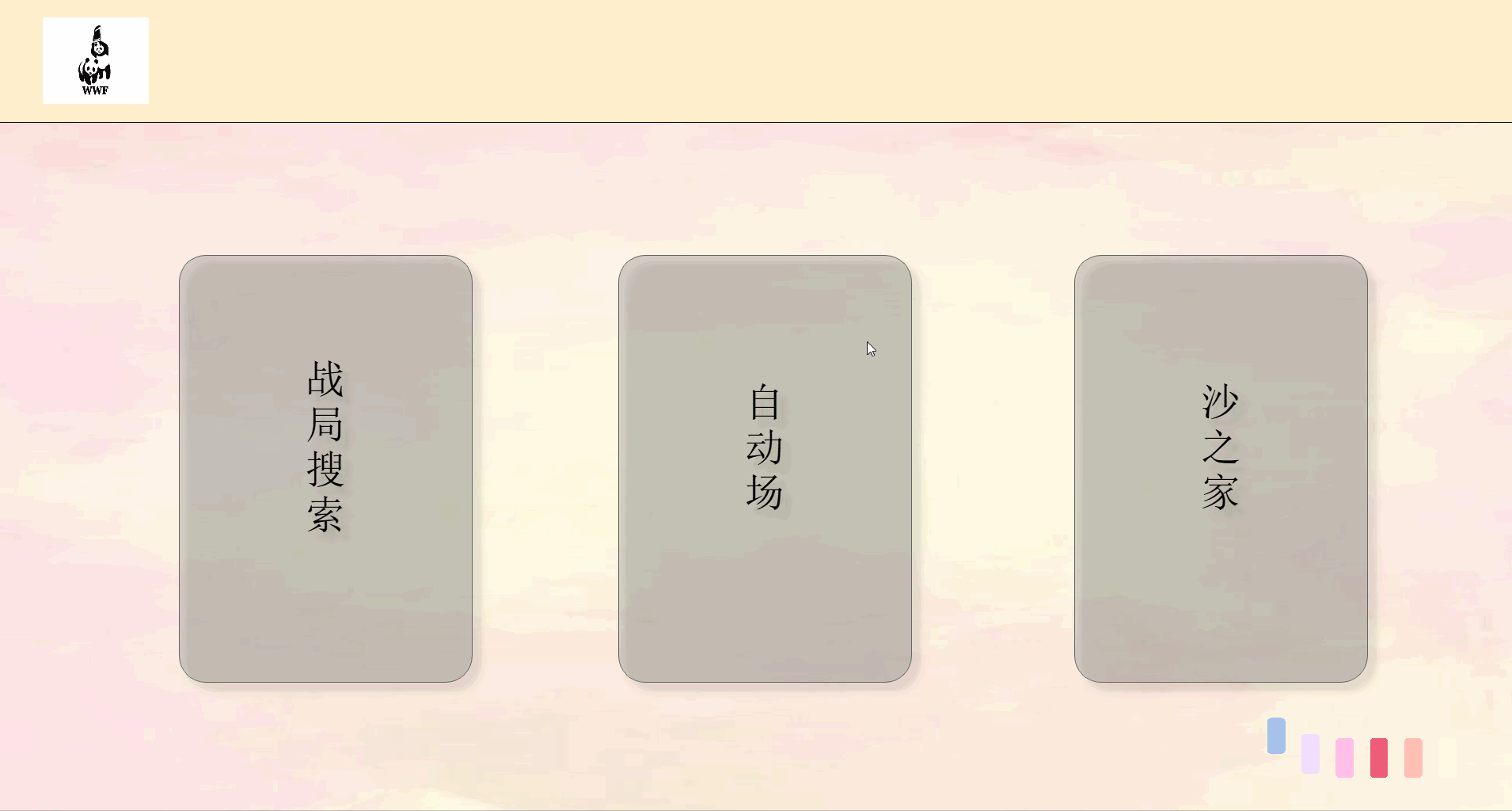
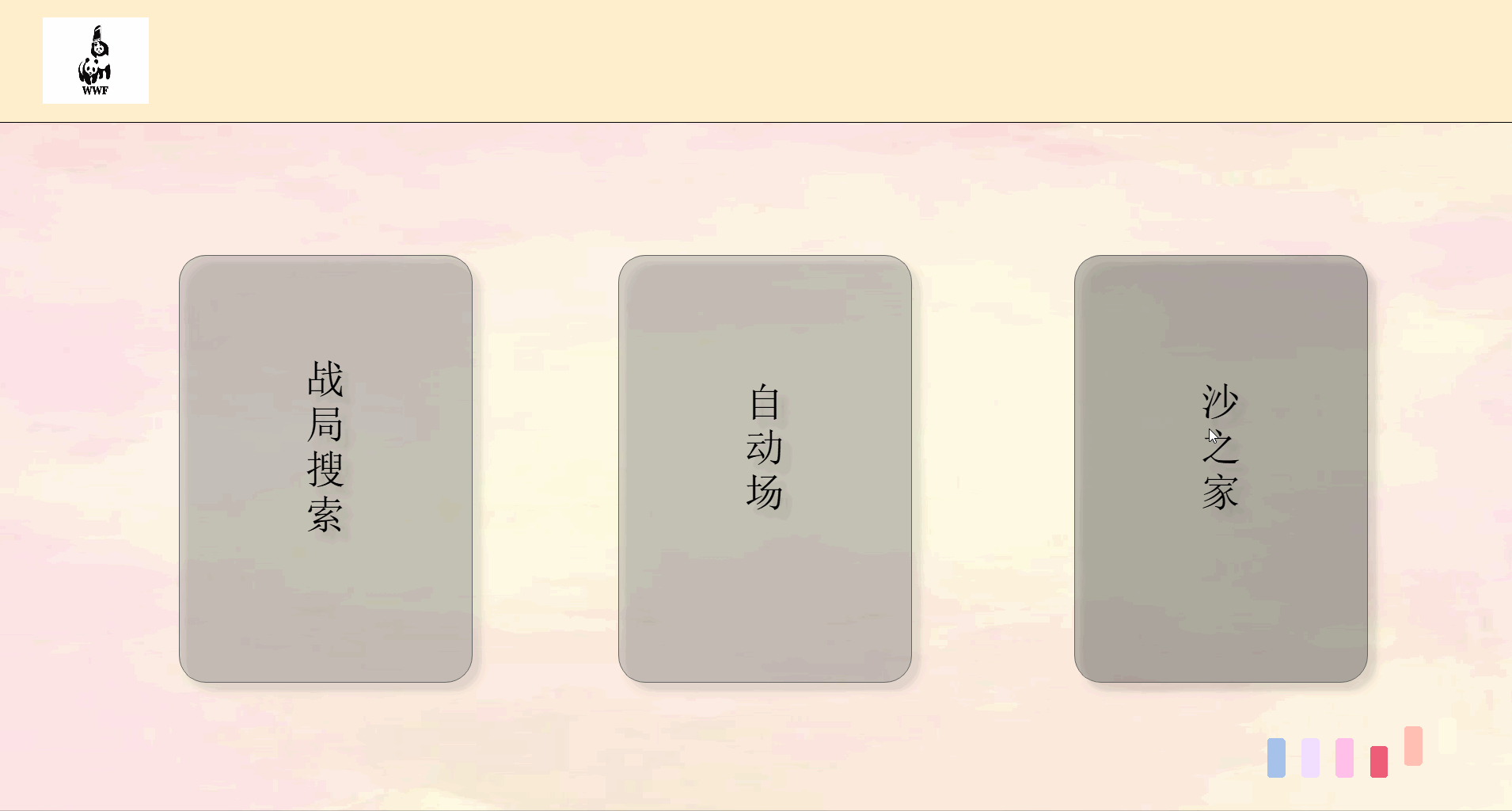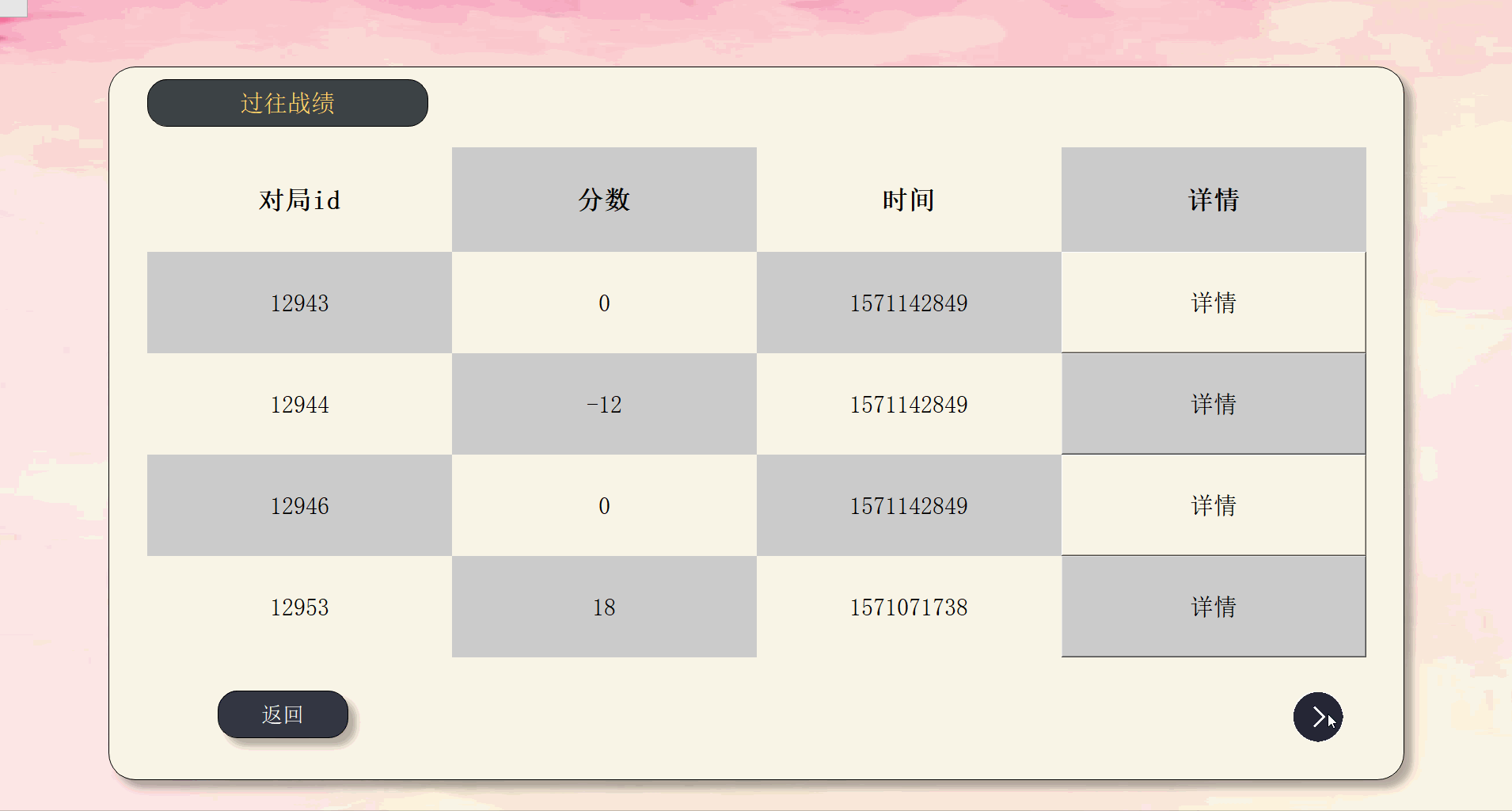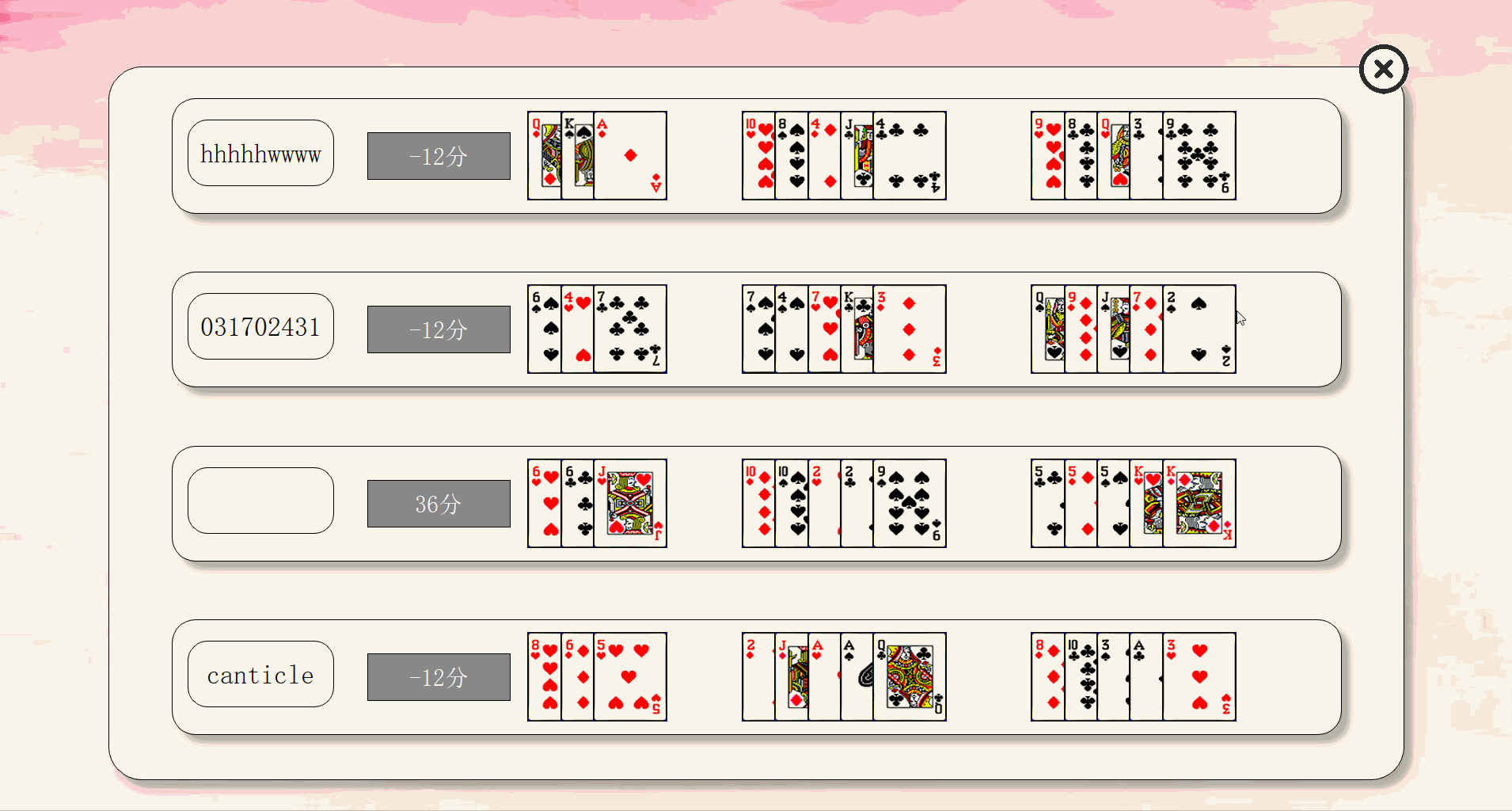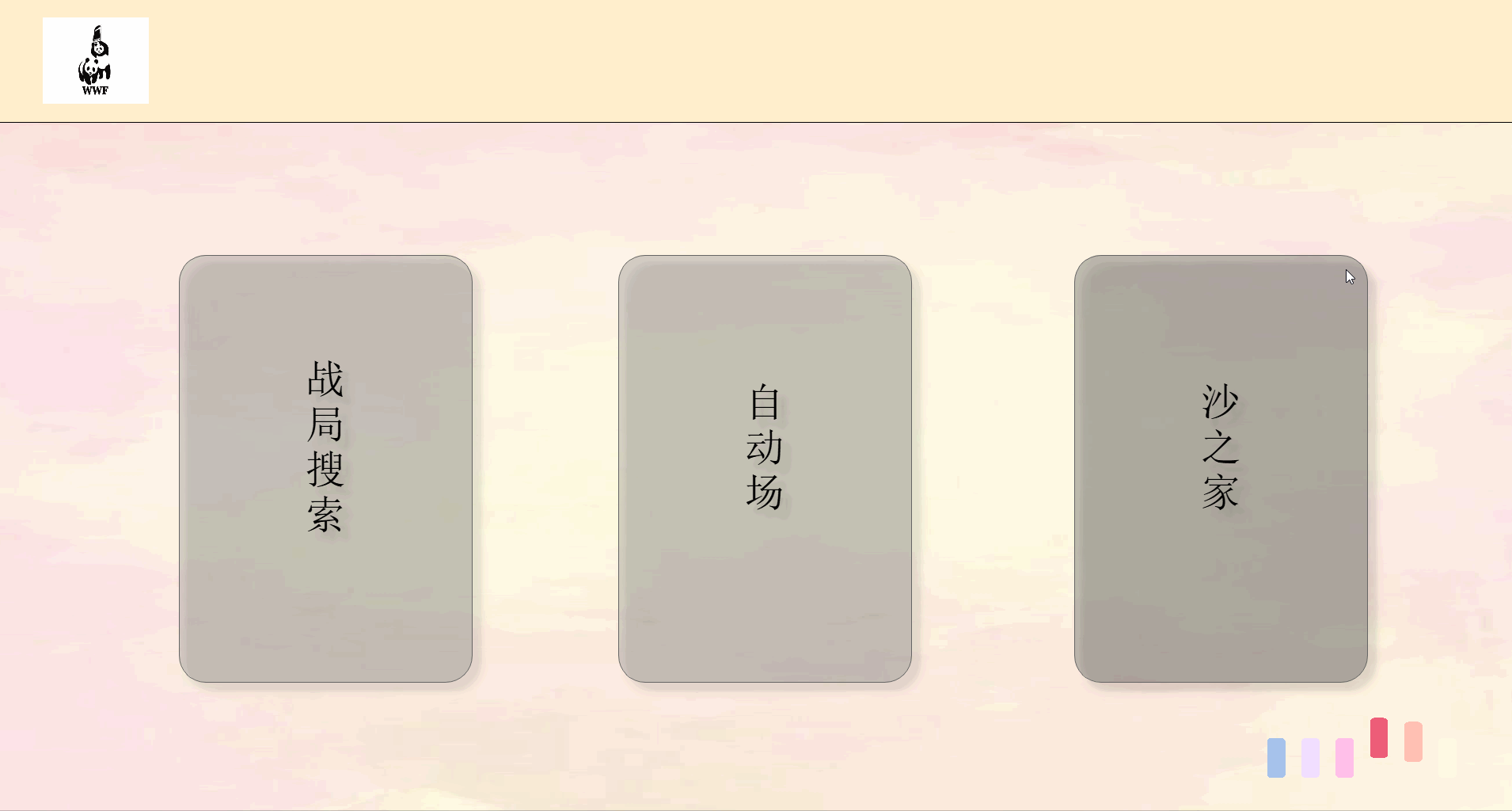
关键代码解释(3分)
算法
reward = 0
#得出手牌和牌桌其他人的输赢水
reward += Compare_Combo(finish_hand,b[0])
reward += Compare_Combo(finish_hand,b[1])
reward += Compare_Combo(finish_hand,b[2])
#好奇心衰减水
reward = reward * ((beta)/math.sqrt(Times[int(shape_1)][int(shape_2)][int(shape_3)]))
Times[int(shape_1)][int(shape_2)][int(shape_3)]+=1
#回归更改权重
Weight[int(shape_1)][int(shape_2)][int(shape_3)]+=(int(reward)/1000)
前端:
# 登陆界面切换主界面
ind.show_mainindex_sg.connect(show_mainindex)
# 登陆界面切换注册界面
ind.show_register_sg.connect(show_register)
# 注册界面切登陆界面
regind.register_ok_sg.connect(register_ok)
# 主界面切自动对战
mainind.auto_pressed_sg.connect(show_result)
# 主界面切用户中心
mainind.home_pressed_sg.connect(show_home)
# 主界面切搜索
mainind.search_pressed_sg.connect(show_search)
# 搜索切结果
searchind.search_sg.connect(show_id)
# 搜索返回
searchind.back_sg.connect(back_off)
# 自动对战返回
sresultind.result_exit_sg.connect(sresult_exit)
# 结果返回
resultind.result_exit_sg.connect(result_exit)
# 用户中心返回
homeind.home_exit_sg.connect(home_exit)
# 用户中心切排行榜
homeind.rank_sg.connect(show_rank)
# 用户中心切个人战绩
homeind.single_rank_sg.connect(show_single_rank)
# 排行榜返回
rankind.rk_comeback_sg.connect(rank_exit)
# 个人战绩返回
sgrankind.single_rk_comeback_sg.connect(single_rank_exit)
# 详情
sgrankind.detail_sg.connect(show_de)
sys.exit(app.exec())
后端:
def play(token):
for i in range(1):
try:
url = "https://api.shisanshui.rtxux.xyz/game/open"
headers = {'x-auth-token': token}
response = requests.request("POST", url, headers=headers)
result = response.text.encode("utf8")
result = json.loads(result)
print(result)
id = result['data']['id']
card = result['data']['card']
card = card.replace("10", 'T')
card = card.replace("*", '@')
hand_card = card.split()
url = "https://api.shisanshui.rtxux.xyz/game/submit"
Weight = pickle.load(open('./resource/model/a.txt', 'rb'))
Times = pickle.load(open('./resource/model/b.txt', 'rb'))
beta = 0.9
myhand = []
for i in range(13):
myhand.append(Card(str(hand_card[i][1]) + str(hand_card[i][0])))
print(myhand)
myhand.sort()
b = Game.begin_game(myhand, Weight, Times, beta, is_Train=False, Auto=False, b=None, real=True)
three = b['level_3'][0]
shape_3 = b['level_3'][1]
two = b['level_2'][0]
shape_2 = b['level_2'][1]
one = b['level_1'][0]
shape_1 = b['level_1'][1]
a = []
c = ''
for i in range(3):
c = c + str(one[i])[1] + str(one[i])[0]
if (i != 2):
c += ' '
c = c.replace("T", '10')
c = c.replace("@", '*')
a.append(c)
c = ''
for i in range(5):
c = c + str(two[i])[1] + str(two[i])[0]
if (i != 4):
c += ' '
c = c.replace("T", '10')
c = c.replace("@", '*')
a.append(c)
c = ''
for i in range(5):
c = c + str(three[i])[1] + str(three[i])[0]
if (i != 4):
c += ' '
c = c.replace("T", '10')
c = c.replace("@", '*')
a.append(c)
payload = str({'id': id, 'card': a})
payload = payload.replace(': ', ':')
payload = payload.replace(', ', ',')
payload = payload.replace("'", '"')
headers = {
'content-type': "application/json",
'x-auth-token': token
}
response = requests.request("POST", url, data=payload, headers=headers)
result = response.text.encode("utf8")
result = json.loads(result)
status = result['status']
msg = result['data']['msg']
if (msg != 'Success'):
print("11111111111")
print(myhand)
print(three)
print(two)
print(one)
break
flag_hand = []
for i in range(13):
f = str(myhand[i])
q = str(f[1]) + str(f[0])
q = q.replace("T", '10')
flag_hand.append(q)
except:
need = {'status': 1}
print(need)
return need
need = {'status': status, 'id': id, 'msg': msg, 'origin_cards': flag_hand, 'cards': []}
flag_one = []
for i in range(3):
a = str(one[i])
b = a[1] + a[0].replace("T", '10')
flag_one.append(b)
flag_two = []
for i in range(5):
a = str(two[i])
b = a[1] + a[0].replace("T", '10')
flag_two.append(b)
flag_three = []
for i in range(5):
a = str(three[i])
b = a[1] + a[0].replace("T", '10')
flag_three.append(b)
flag = {'lv': level_dict[str(shape_1)], 'card': flag_one}
need['cards'].append(flag)
flag = {'lv': level_dict[str(shape_2)], 'card': flag_two}
need['cards'].append(flag)
flag = {'lv': level_dict[str(shape_3)], 'card': flag_three}
need['cards'].append(flag)
print(need)
return need
性能分析与改进
描述你改进的思路
1.最开始的回归方式是单纯根据输赢水/100,这样可能会使一些很少遇到的情况出现偏差,它本来应该比另外一种经常出现的大,可经常出现的牌型出现的次数过多导致过分更改它的权重产生误判,所以使用了最近用来解决RL中sparse reward问题的好奇心的方法(其实就是个最简单的计数)。
2.因为由表得出make_suit也就是遍历得到花色dict的函数是最耗时的,估计因为是每次手牌的预处理都有用到它,所以第一墩13张牌时仍让它遍历,第二墩8张牌时就从先前的dict减去少掉5张牌的花色,第三墩类似,会稍微减少一点时间
3.在训练完十万个单位后,为了减少训练时间,不用让它遍历每种情况,只要是它经过的情况都用一个矩阵来标1,下次就不用再次访问同样牌型的情况
4.前端则是由于py的特性,导致本身启动时间较慢,唯一想到的解决方法是减少初始加载的模块数或者用c编写系统接口。
5.只有有网络请求,则网络请求部分往往是耗时最大的,该次作业也是一样。
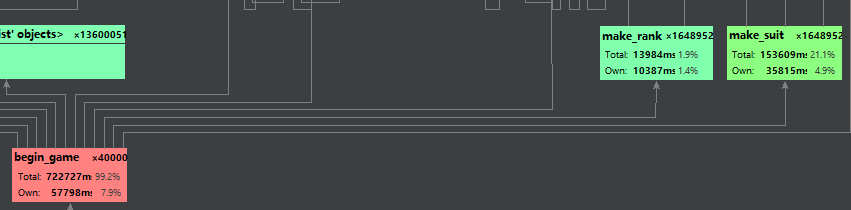
展示性能分析图和程序中消耗最大的函数
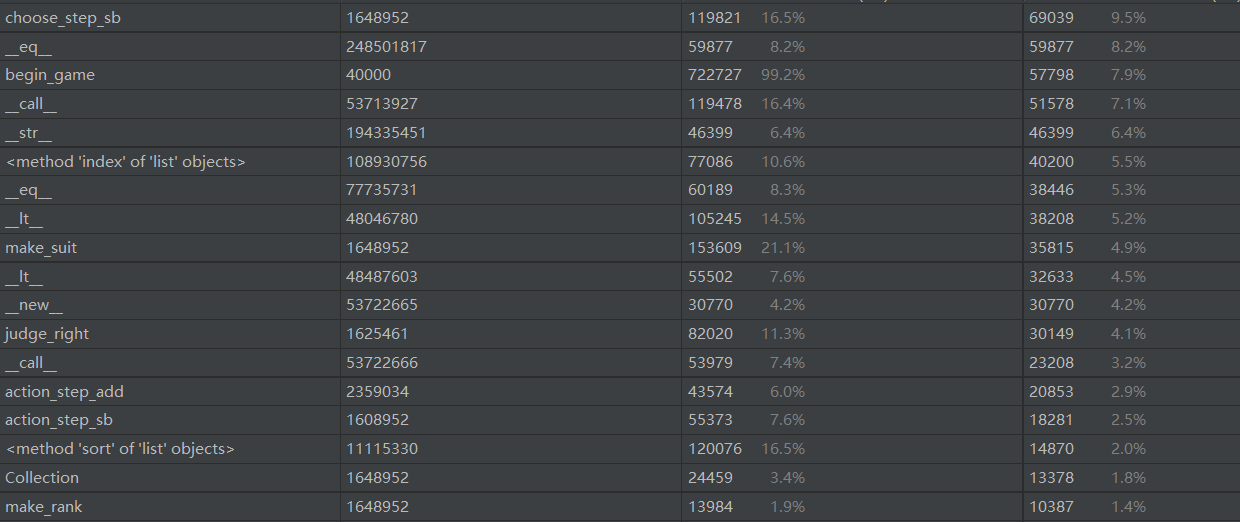
万万没想到居然是make_suit。这玩意不就遍历个手牌把花色记录下来居然花这么多时间。惊了。
单元测试
覆盖率
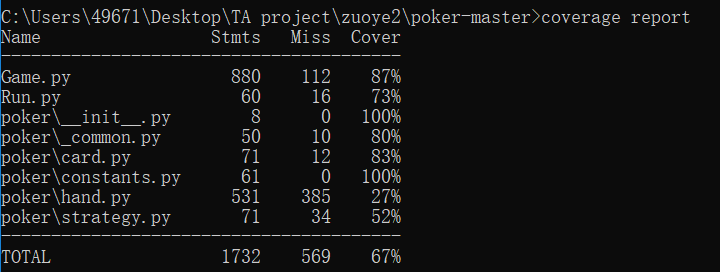
poker是用来初始化卡牌的基础库,这个就不关键了,可见控制出牌发牌逻辑的Game的覆盖率是87,虽然低但还算勉强。
贴出Github的代码签入记录。
遇到的代码模块异常或结对困难及解决方法
问题描述(2分)
1.手牌合法性检测
2.因为是遍历手牌牌型的所有情况,两种情况的两副牌有可能出现某一墩完全一样的情况,无法比较大小。
3.底层poker库的Card类型和接口提供的卡牌样式完全不同,本身花色类型和前端接口也是八字不合,会出现❤这种无法保存的现象
4.网络请求失败导致整个程序崩溃。
5.多界面切换的挂起导致的内存损耗。
6.队友的屁股不够翘
做过哪些尝试(2分)
1.本来是想写一个判断手牌牌型和最大牌大小的顺便也方便前端,但因为后面训练的时候需要进行两副牌输赢水的计算,干脆就把每墩之间的比较独立写出,若合法情况则是第三墩赢第二墩,第二墩赢第一墩,这种牌型就是合法的。
2.根据鸵鸟算法,那么我们就把它........直接返回不输不赢吧
3.手动更改底层库
4.增加异常处理
5.修改控件件的父子关系。
是否解决(2分)
1.解决了
2.根据鸵鸟算法,解决了
3.解决了,哭了
4.解决了
5.不完美解决
有何收获(2分)
1.大千世界无奇不有,换种思路展开新世界
2.操作系统教会了我们非常关键的一种算法,使我受益良多
3.在开展项目前因先沟通好前后端的接口设计问题,同时将功能合理区分开,降低耦合度。
4.完成不使用ps纯手码前端成就。
评价你的队友
值得学习的地方(2分)
1.你是我们大家的活宝
2.你到处散发着诱人的魅力
3.没有你,我们今天不会这么圆满
4.你给人感觉到一种权威和力量的存在
5.你让我们越来越有信心
6.你很有这方面的天赋
7.你真是一个德高望重的人
8.你很亲切
9.你很酷
10.你很有内涵
11.你真是魅力四射
需要改进的地方(2分)
1.全 栈 工 程 师
2.屁股不够翘
学习进度条(2分)
学习表
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 407 | 407 | 15 | 15 | 学到了十三水的玩法,了解了原型设计工具的使用方法 |
| 2 | 600 | 1007 | 26 | 26 | 实现了牌型的基础框架 |
| 3 | 312 | 1319 | 14 | 14 | 实现了牌型的训练和接口 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号