
HIVE
什么是hive
Hive是建立在Hadoop之上的数据仓库基础构架、是为了减少MapReduce编写工作的批处理系统,Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce。Hive可以理解为一个客户端工具,将我们的sql操作转换为相应的MapReduce jobs,然后在Hadoop上面运行。
简单来说,hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样使得数据开发和分析人员很方便的使用SQL来完成海量数据统计与分析,二不必使用编程语言开发MapReduce那么麻烦。
Hive 具有 SQL 数据库的外表,但应用场景完全不同,Hive 只适合用来做海量离线数据统计分析,也就是数据仓库。
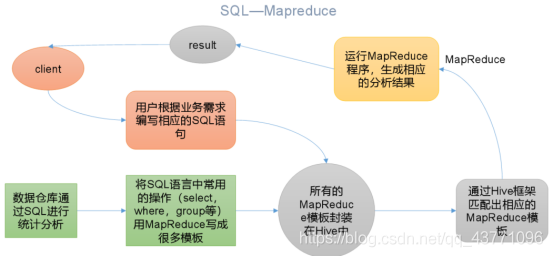
本质是:将HQL转化成MapReduce程序
hive和mysql的区别
1、查询语言不同:hive是hql语言,mysql是sql语句;
2、数据存储位置不同:hive是把数据存储在hdfs上,而mysql数据是存储在自己的系统中;
3、数据格式:hive数据格式可以用户自定义,mysql有自己的系统定义格式;
4、数据更新:hive不支持数据更新,只可以读,不可以写,而sql支持数据更新;
5、索引:hive没有索引,因此查询数据的时候是通过mapreduce很暴力的把数据都查询一遍,也造成了hive查询数据速度很慢的原因,而mysql有索引;
6、延迟性:hive延迟性高,原因就是上边一点所说的,而mysql延迟性低;
7、数据规模:hive存储的数据量超级大,而mysql只是存储一些少量的业务数据;
8、底层执行原理:hive底层是用的mapreduce,而mysql是excutor执行器;
hive sql
————————————————
深入理解Hive的优缺点以及架构原理:https://blog.csdn.net/qq_43771096/article/details/109481655
hive和mysql的区别_hive和mysql的区别是什么:https://blog.csdn.net/weixin_28996083/article/details/113126084
Hadoop是什么,能干什么,怎么使用:https://blog.csdn.net/qq_32649581/article/details/82892861
HIVE sql 语法介绍:https://zhuanlan.zhihu.com/p/162807676
