性能测试
性能测试的指标
一句口诀,多快好省。
多,并发量
要区分以下用户数:
- 注册用户数,占用磁盘
- 在线用户数,占用内存
- 并发用户数
狭义的并发数,用户同一时刻做同一件事或操作,如同时登陆、同时提交表单。
广义的并发数,用户同一时刻对系统做了请求,但是用户所做的事情或操作可以是相同的,也可以是不同的。
真正意义上的并发不存在!
上面试谈了这么多并发,现在又说真正意义上的并发不存在。何解?
学操作系统原理的同学都知道,CPU在一个时间点上只能干一件事儿。为什么我们可以边看电影,边打字,边语音。因为CPU很快很快,他可以处理一下电影,再处理一下打字,再处理一下语音。因为它很快,所以,它可以在多个程序之间快速瞬间的切换,给你造成的假象就是它在同时做这些事情。(现在的双核、四核的CPU另说)
那么我们的系统在接到用户的请求后也要调用CPU来完成某些处理,然后返回给用户。那么我们对系统有做并发测试是测什么呢?举个简单的例子。假如有一位神医,他的看病速度非常快,假设他的看病速度是不变的;然后有一群接待人员来接待看病的客人,有成千上万的病人来看病,接待人员要想各种办法来做好接待工作,使病人更快的看到病。比如,可以事先咨询病人得的什么病,然后将病人进行分类,比如可以扩大接待室,让更多的病人可以进到医院来看病等。
神医就是我们的CPU,接待人员就是我们的系统,病人就用户,我们做性能测试的目的就是了解接待人员哪个地方给医院看病造成了瓶颈。只来一个病人,医院的看病速度与服务很好。一下子来十万个病人各种问题就出来了。接待人员的服务态度下降,多余的人员跟本进不到医院去,医院的洗手间不够用,造成病人无法上厕所而离开,这些都属于系统问题。所以,我们一般测试的目的是看医院的接待能力。
如何计算并发数?
- 简单计算
如一个典型的上班签到系统,早上8点上班,7点半到8点的30分钟的时间里用户会登录签到系统进行签到。公司员工为1000人,平均每个员上登录签到系统的时长为5分钟。可以用下面的方法计算。
C=1000/30*5=166.7
C表示平均并发用户数,那么对这个签到系统每分钟的平均在线用户数为166。
在性能测试上,任何公式都不是严谨的,最重要的是对系统做出有效正确的分析。
- 一般计算
1、用户从登陆系统到退出系统的间隔时间L
2、登陆系统的用户数量n
3、被考察的时间长度T
计算公式:并发用户数 C = n * L / T
举例:
如果系统有3000个注册用户,平均每天400个用户要访问系统,一般一个典型用户在系统中停留4小时(从登陆到退出),在一天内,用户在8小时内使用该系统。
并发用户数=400X4/8=200
如果要计算峰值用户数的话,用公式:C1 = C + 3 * sqr(C)
C表示并发用户数
根据上面算出的结果,并发用户数是200,那么公式为:
C1 = 200 + 3 x sqr(200)= 242
为什么这样计算峰值?
并发用户数量的统计的方法目前还没有准确和标准的公式,不同系统会有不同的并发特点。
快,响应时间
响应时间:2-5-8
- 2s是好的
- 5s可以接受
- 8s不可接受
好,稳定,错误率
省,资源占用情况,内存、cpu、磁盘、带宽
确定场景、性能目标
- 甲方提出要求
- 分析服务器日志
了解业务逻辑,提取高频业务、核心业务、扎堆场景。
了解项目部署框架
服务器部署架构,在有性能问题时,能分析
db--tomcat
多个tomcat -- nginx
keeplive 主从模式
多个tomcat -- nginx -- lvs
高性能F5服务器
db瓶颈,redis缓存
db--reids--tomcat

思考时间-模拟人的行为,有停顿
初始化测试环境
性能测试环境需要与生产环境尽量一致,初始化环境。没有初始化环境等于没有作用的环境。
-
用户量初始化,测试环境用户量太少,那数据写入、读取缺少寻址时间。dump生产环境的数据,如果不能dump那了解生产环境的数据结构,在数据库中插入数据。
-
网络环境,测试环境距离服务器很近,而生产环境客户端是在广州,服务器是在北京,模拟网络延迟环境,人为注入延迟。
-
热机warm up,磁盘数据->内存。
-
缓存数据
-
数据清理
开发脚本
- 准确,只要压测的接口
- 简洁,逻辑清晰,易维护
有完善的接口文档,按照接口文档组装报文
没有完善的接口文档,录制脚本
调试脚本
关联
接口前后有关联,从前面接口的返回报文提前内容,使用变量保存下来,供后面接口使用。
jmeter使用:
json提取器
正则表达式提取器
参数化
测试场景不能使用相同数据重复测试,需要进行参数化。
设置集合点
jmeter是使用同步定时器实现
添加断言
基于业务场景,添加正确的断言条件
- 返回报文的断言
- 数据逻辑处理正确,如数据入库落地后处理正确的检查
执行压测
单台电脑大概可以支撑1000并发
更高并发需要用分布式,也可以在高配置的服务器环境跑脚本,jmeter是跨平台的
监测数据
serverAgent
jmeter的插件,监控颗粒度不高,界面简陋
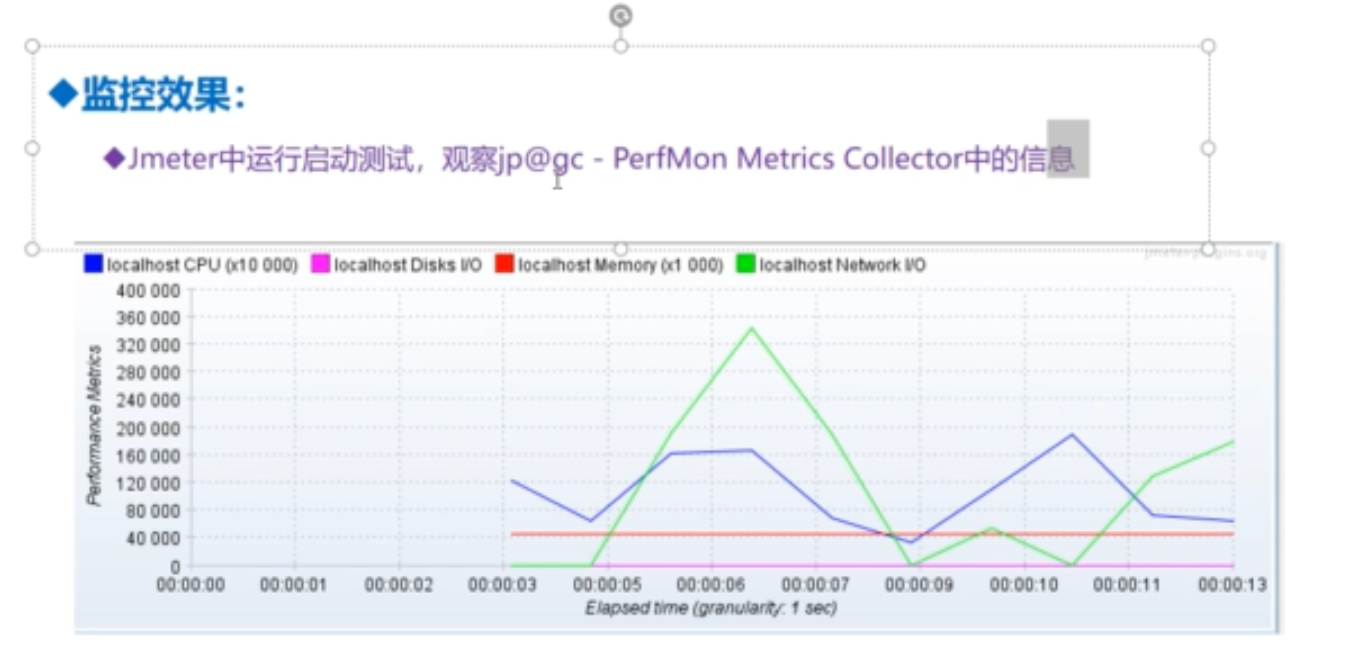
Nmon
Nmon工具是IBM提供的免费的在各种Linux操作系统上广泛使用的监控与分析工具。该工具可将服务器的系统资源耗用情况收集起来并输出一个特定的文件,并可利用excel分析工具NmonAnalyser进行数据的统计分析。
两种检测方案
-
离线方案:画过nmon收集器收集数据-等场景运行完成之后,使用分析离线分析
-
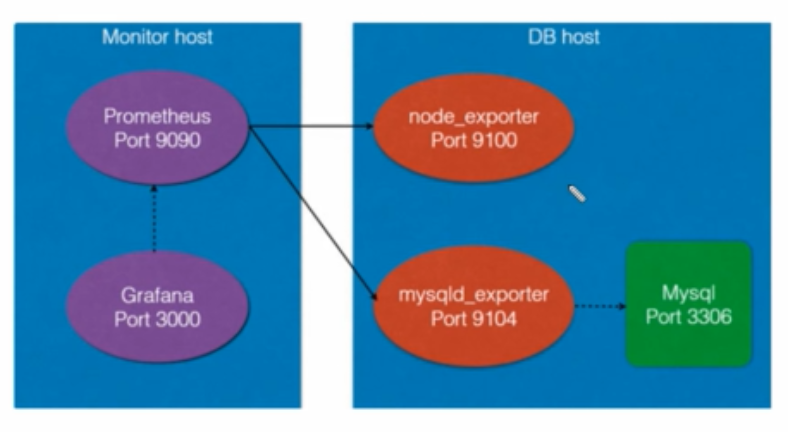
实时方案:grafana+nmon_exporter--实时
Grafana

- 收集器,下载对应的收集器,tomcat、redis、、mysql、服务器
- 储存器,Prometheus
- 接收器,grafana
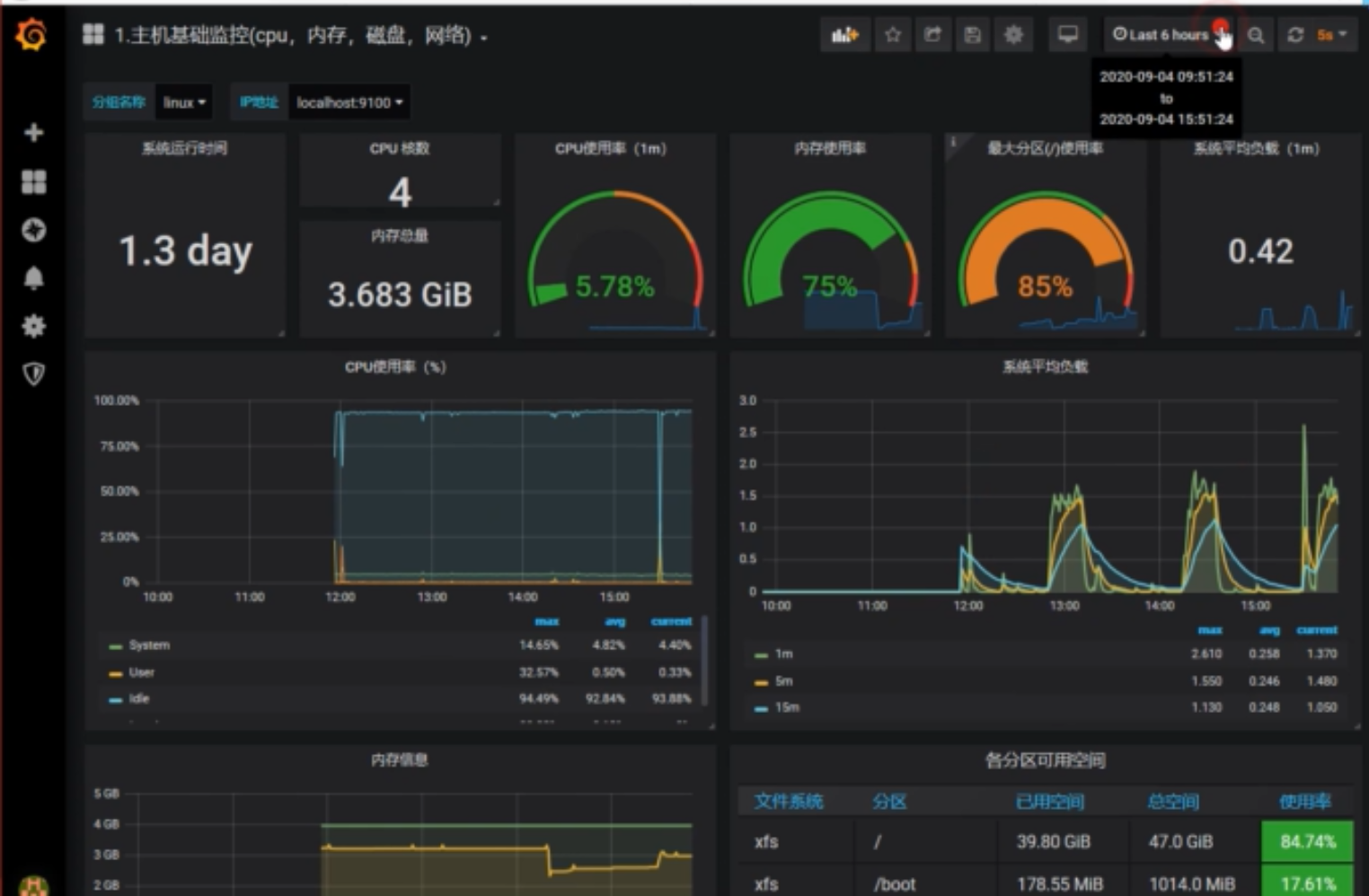
优秀监控方案所具备的特性:
- 准确性高
- 时效性好
- 可视化高
- 历史数据
- 警告通知
瓶颈分析
发现cpu使用率过高
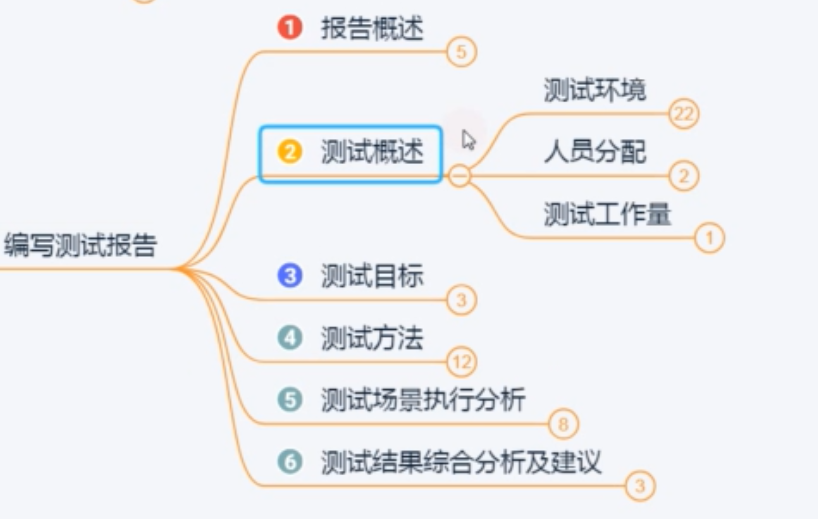
编写报告


参考:
https://wenku.baidu.com/view/64931c850329bd64783e0912a216147917117e39.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号