记录一次群答问:jmeter正则提取器轻松提取一个及多个值(关联)
一个正则提取问题
安装Dummy插件

勾选后,点击右下方开始安装,安装完成后会自动重启jmeter。

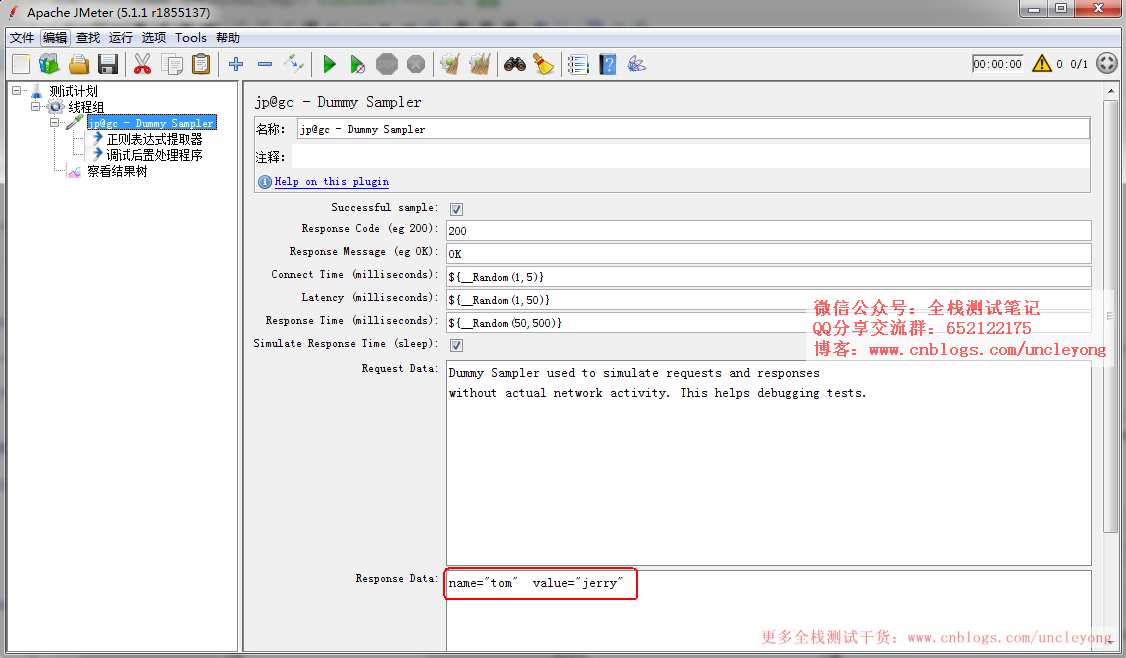
模拟响应
添加线程组,在线程组下添加Dummy取样器(在Dummy取样器的响应数据中填入模拟返回数据)、查看结果树监听器,在Dummy下添加正则表达式提取器、调试后置处理程序(用于查看提取结果的)。
正则基础
参考:https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E4%B9%8B%E9%81%93
. 匹配除“\r\n”之外的任何单个字符。要匹配包括“\r\n”在内的任何字符,请使用像“[\s\S]”的模式。(\s是指空白,包括空格、换行、tab缩进等所有的空白,而\S刚好相反,这样一正一反就表示所有的字符)
* 匹配前面的子表达式(也可以是一个字符)任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于o{0,}
+ 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。
组合:
.*具有贪婪的性质,匹配到不能匹配为止,最大匹配原则。
+或*后跟?表示非贪婪匹配,即尽可能少的匹配,最小匹配原则。
.*? 表示在能匹配成功的前提下尽可能少的匹配,最小匹配原则。
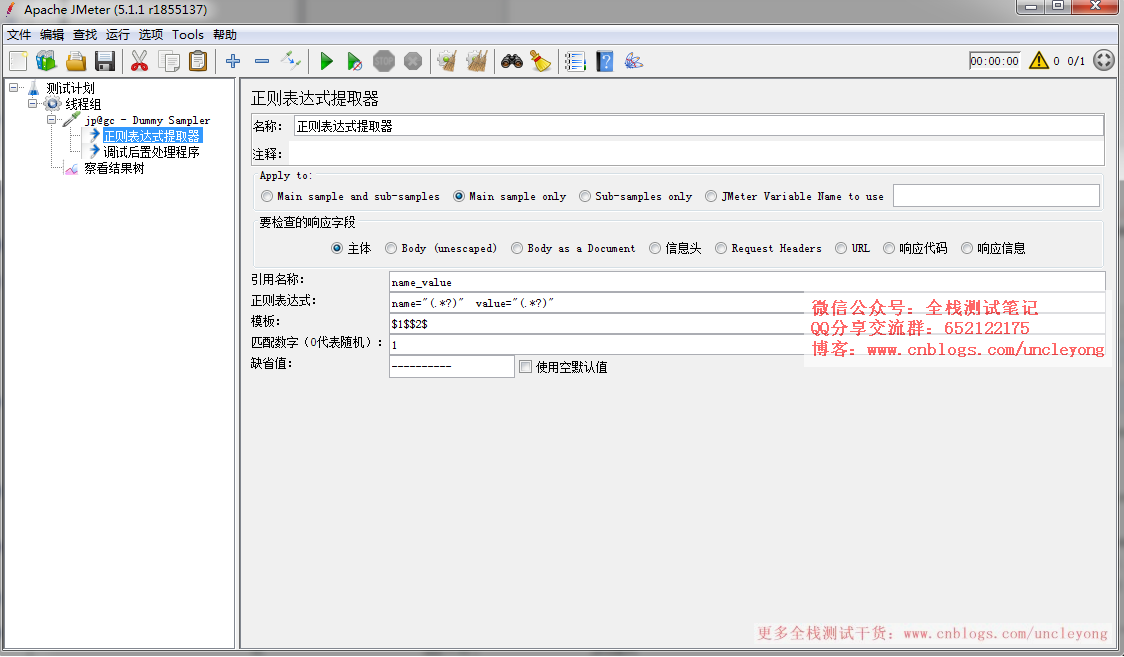
正则表达式提取器
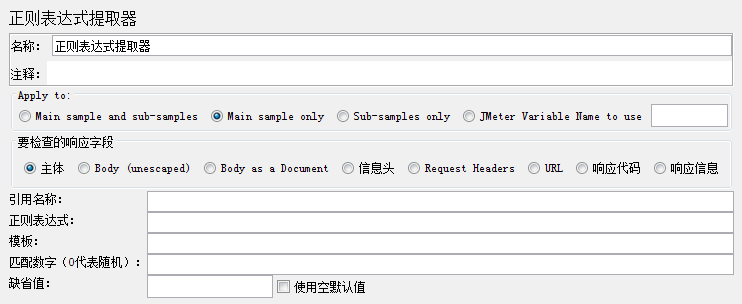
Apply to:一般保持默认选择Main sample only,这个用得最多,如果有sub-samples,可以选择第一个选项
要检查的响应字段:用得最多的是主体,即header+body,可以从响应头,也可以从响应体提取
引用名称:变量名,获取到的值存储到这个变量中
正则表达式:根据实际情况填写
模板:$1$,表示第一个正则表达式,如果有2个正则表达式,写为$1$$2$
匹配数字(0代表随机):一般填1,表示第一个,0表示随机,-1表示全部(此时提取结果是一个数组,如果引用名称是user,也可以通过${user_1}的方式来取第1个匹配的内容)
缺省值:没匹配到就用缺省值,我们可以设置一个,比如aaaaaa
提取多个值方法一:
运行结果
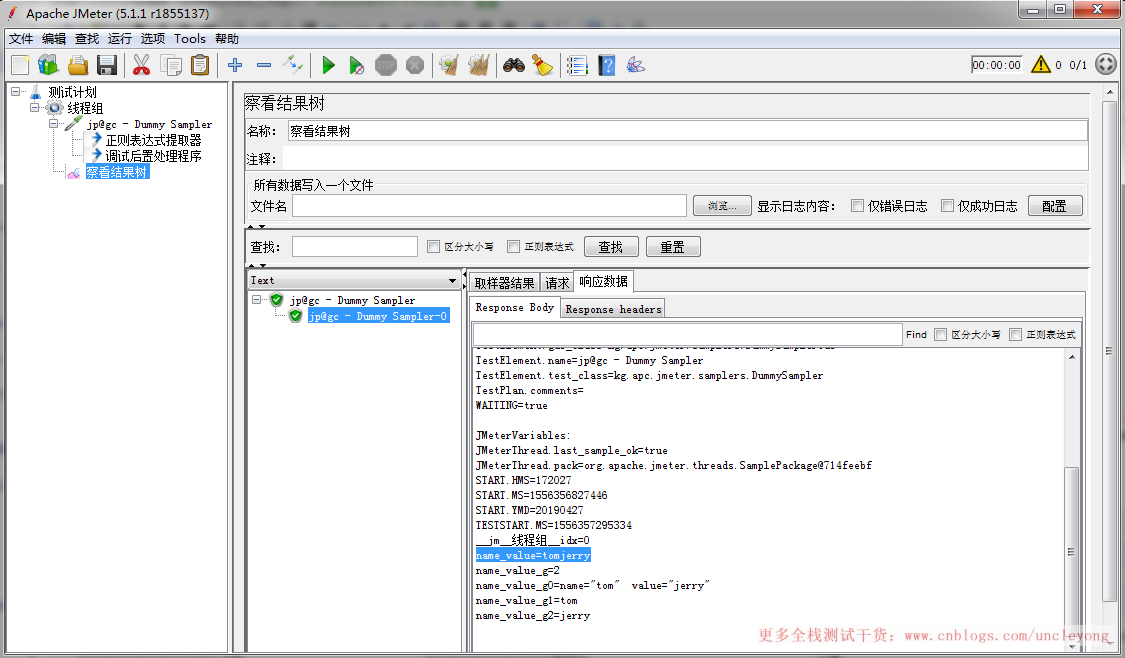
也可以用其它字符拼接,比如-,即如果模板写为:$1$-$2$,结果就是:nameandvalue=tom-jerry
参考:https://www.cnblogs.com/uncleyong/p/14049484.html
提取多个值方法二:两个提取器
name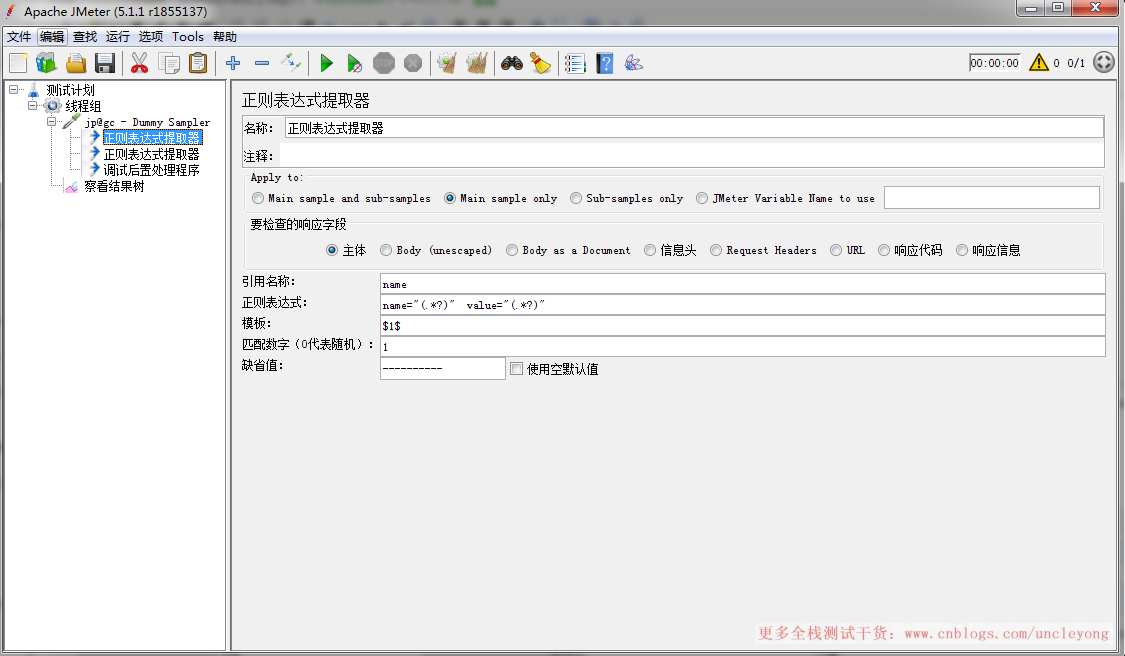
value

运行结果
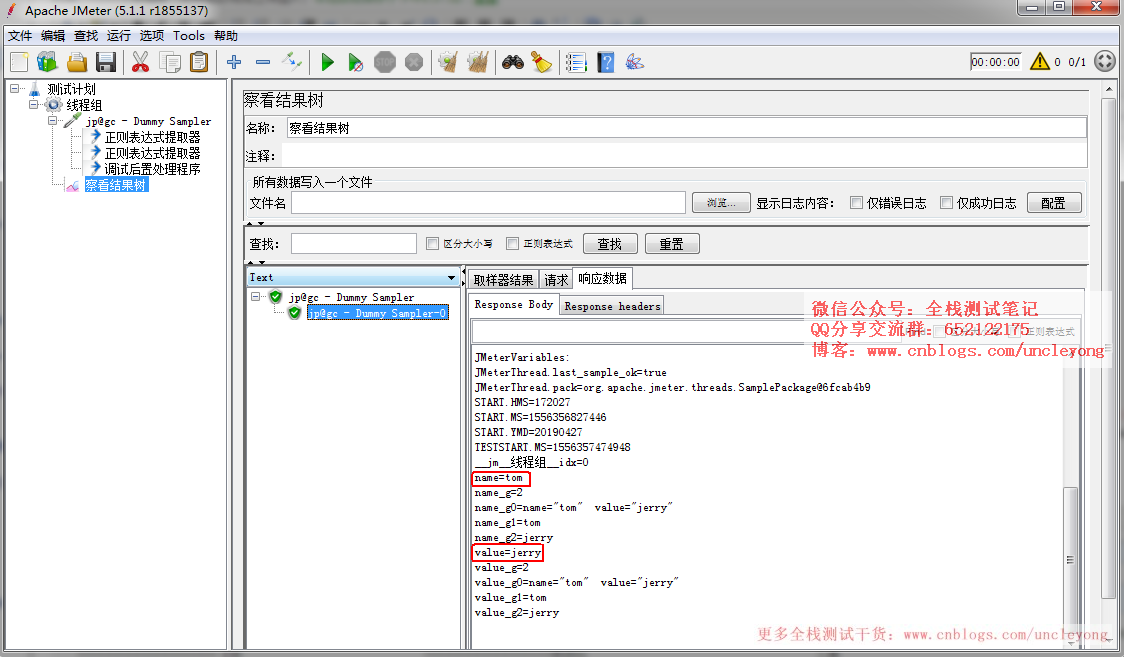
ok,就是这么简单,你觉得呢?欢迎交流。加群获取jxm脚本。
__EOF__

关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号