MySQL事务&锁
一、事务&锁


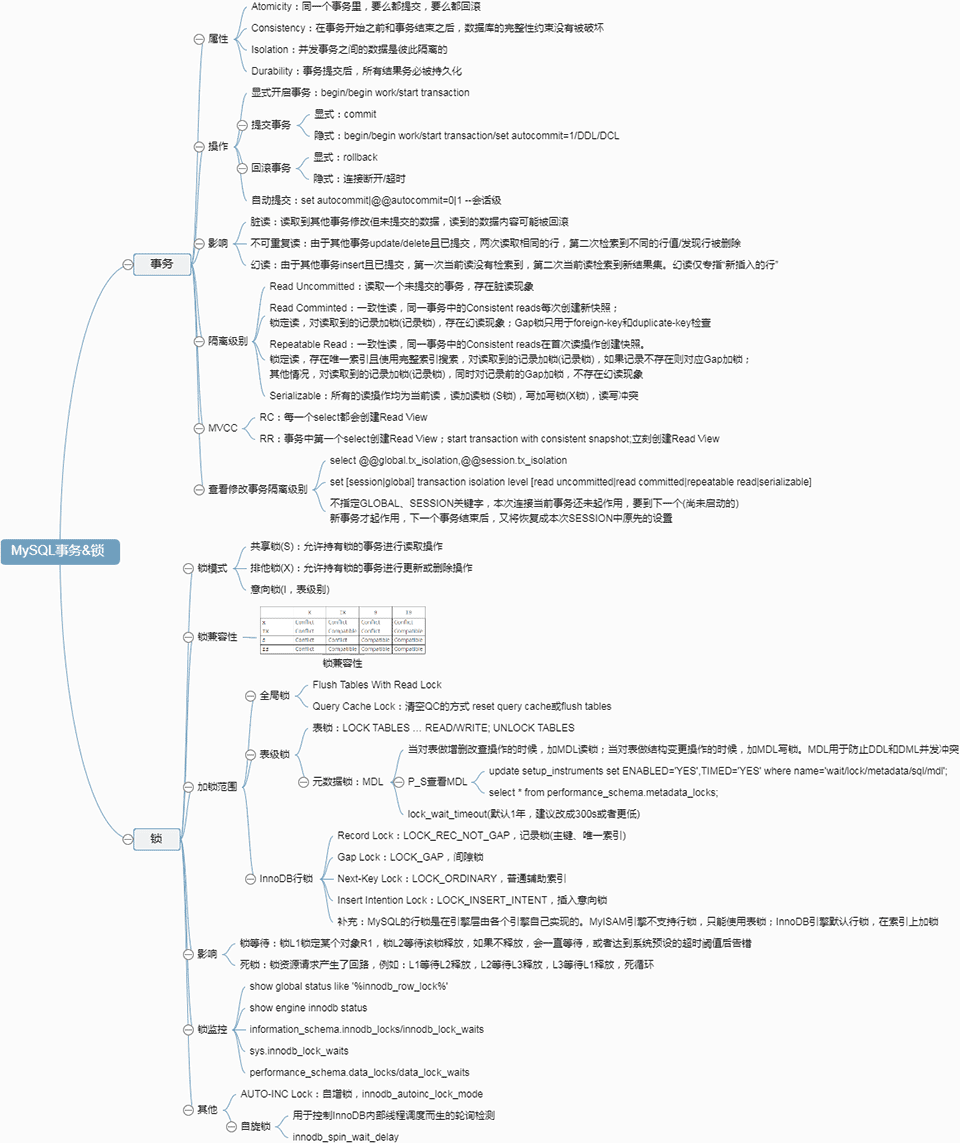
MySQL事务&锁 事务 属性 Atomicity:同一个事务里,要么都提交,要么都回滚 Consistency:在事务开始之前和事务结束之后,数据库的完整性约束没有被破坏 Isolation:并发事务之间的数据是彼此隔离的 Durability:事务提交后,所有结果务必被持久化 操作 显式开启事务:begin/begin work/start transaction 提交事务 显式:commit 隐式:begin/begin work/start transaction/set autocommit=1/DDL/DCL 回滚事务 显式:rollback 隐式:连接断开/超时 自动提交:set autocommit|@@autocommit=0|1 --会话级 影响 脏读:读取到其他事务修改但未提交的数据,读到的数据内容可能被回滚 不可重复读:由于其他事务update/delete且已提交,两次读取相同的行,第二次检索到不同的行值/发现行被删除 幻读:由于其他事务insert且已提交,第一次当前读没有检索到,第二次当前读检索到新结果集。幻读仅专指“新插入的行” 隔离级别 Read Uncommitted:读取一个未提交的事务,存在脏读现象 Read Comminted:一致性读,同一事务中的Consistent reads每次创建新快照;\n锁定读,对读取到的记录加锁(记录锁),存在幻读现象;Gap锁只用于foreign-key和duplicate-key检查 Repeatable Read:一致性读,同一事务中的Consistent reads在首次读操作创建快照。\n锁定读,存在唯一索引且使用完整索引搜索,对读取到的记录加锁(记录锁),如果记录不存在则对应Gap加锁;\n其他情况,对读取到的记录加锁(记录锁),同时对记录前的Gap加锁,不存在幻读现象 Serializable:所有的读操作均为当前读,读加读锁 (S锁),写加写锁(X锁),读写冲突 MVCC RC:每一个select都会创建Read View RR:事务中第一个select创建Read View;start transaction with consistent snapshot;立刻创建Read View 查看修改事务隔离级别 select @@global.tx_isolation,@@session.tx_isolation set [session|global] transaction isolation level [read uncommitted|read committed|repeatable read|serializable] 不指定GLOBAL、SESSION关键字,本次连接当前事务还未起作用,要到下一个(尚未启动的)\n新事务才起作用,下一个事务结束后,又将恢复成本次SESSION中原先的设置 锁 锁模式 共享锁(S):允许持有锁的事务进行读取操作 排他锁(X):允许持有锁的事务进行更新或删除操作 意向锁(I,表级别) 锁兼容性 锁兼容性 加锁范围 全局锁 Flush Tables With Read Lock Query Cache Lock:清空QC的方式 reset query cache或flush tables 表级锁 表锁:LOCK TABLES … READ/WRITE; UNLOCK TABLES 元数据锁:MDL 当对表做增删改查操作的时候,加MDL读锁;当对表做结构变更操作的时候,加MDL写锁。MDL用于防止DDL和DML并发冲突 P_S查看MDL update setup_instruments set ENABLED='YES',TIMED='YES' where name='wait/lock/metadata/sql/mdl'; select * from performance_schema.metadata_locks; lock_wait_timeout(默认1年,建议改成300s或者更低) InnoDB行锁 Record Lock:LOCK_REC_NOT_GAP,记录锁(主键、唯一索引) Gap Lock:LOCK_GAP,间隙锁 Next-Key Lock:LOCK_ORDINARY,普通辅助索引 Insert Intention Lock:LOCK_INSERT_INTENT,插入意向锁 补充:MySQL的行锁是在引擎层由各个引擎自己实现的。MyISAM引擎不支持行锁,只能使用表锁;InnoDB引擎默认行锁,在索引上加锁 影响 锁等待:锁L1锁定某个对象R1,锁L2等待该锁释放,如果不释放,会一直等待,或者达到系统预设的超时阈值后告错 死锁:锁资源请求产生了回路,例如:L1等待L2释放,L2等待L3释放,L3等待L1释放,死循环 锁监控 show global status like '%innodb_row_lock%' show engine innodb status information_schema.innodb_locks/innodb_lock_waits sys.innodb_lock_waits performance_schema.data_locks/data_lock_waits 其他 AUTO-INC Lock:自增锁,innodb_autoinc_lock_mode 自旋锁 用于控制InnoDB内部线程调度而生的轮询检测 innodb_spin_wait_delay
二、Next-key Lock说明
https://dev.mysql.com/doc/refman/8.0/en/innodb-next-key-locking.html
To prevent phantoms, InnoDB uses an algorithm called next-key locking that combines index-row locking with gap locking. InnoDB performs row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. In addition, a next-key lock on an index record also affects the “gap” before that index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on record R in an index, another session cannot insert a new index record in the gap immediately before R in the index order.
When InnoDB scans an index, it can also lock the gap after the last record in the index.
下面通过一个例子来说明Next-key Lock
#创建测试表 CREATE TABLE test ( id int(11) NOT NULL, code int(11) NOT NULL, PRIMARY KEY(id), KEY (code) ) ENGINE=InnoDB; #插入数据 INSERT INTO test(id,code) values(1,1),(5,5),(10,10),(15,10);
隔离级别RR,按顺序执行下面操作
| 会话1 | 会话2 | 说明 |
| begin; | begin; | |
| select * from test where code = 5 for update; | ||
| insert into test select 2,2; | 被阻塞,因为Gap Locks | |
| insert into test select 8,8; | 被阻塞,因为Gap Locks | |
| insert into test select 9,10; | 被阻塞,因为Gap Locks | |
| insert into test select 10,10; | 报错,Duplicate entry '10' for key 'PRIMARY' | |
| insert into test select 11,10; | 正常 | |
| update test set code=0 where id=1; | 正常,说明(1,1)这条记录没有加锁 | |
| update test set code=11 where id=10; | 正常,说明(10,10)这条记录没有加锁 |
会话1,对于普通索引的记录(code:id)
| code:id | 操作 | 说明 |
| 1:1 | ||
| ({1:1},{5:5}) 左开右开 Gap Lock |
Gap Lock+Record Lock 组成 Next-key Lock |
|
| 2:2 写入被阻塞 | ||
| 5:5 | {5:5} Record Lock,({1:1},{5:5}] 左开右闭 组成Next-key Lock | |
| ({5:5},{10:10}) 左开右开 Gap Lock | 当InnoDB扫描一个索引时,它还会锁定索引中最后一条记录之后的Gap | |
| 8:8 写入被阻塞 | ||
| 10:9 写入被阻塞 | ||
| 10:10 | ||
| 10:11 写入正常 | ||
| 15:10 |
会话1中 code=5 for update,对索引的锁定用区间表示,Gap锁锁定了({1:1},{5:5}),Record锁锁定了{5:5}索引记录,最后一条Record后的Gap锁锁住了({5:5},{10:10}),也就是说整个({1:1},{10:10})的区间被锁定了
如果会话1执行的是:
begin; select * from test where code = 3 for update; --3是不存在的记录
则它在区间 ({1:1},{5:5}) 加 Gap Lock
如果会话1执行的是:
begin; select * from test where code > 8 for update;
在扫描过程中,找到了code=10,此时就会锁住5到10之间的Gap,10本身Record,以及10之后所有范围。此时另一个事务插入(6,6)、(9,9)或(11,11)都是不被允许的,只有在前一个索引5及5之前的索引和间隙才能执行插入(更新和删除也会被阻塞)
|
|
【作者】: 醒嘞 |
| 【出处】: http://www.cnblogs.com/Uest/ | |
| 【声明】: 本文内容仅代表个人观点。如需转载请保留此段声明,且在文章页面明显位置给出原文链接! |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号