
Data Collection with Apache Flume(三)
最后提及两个agent。首先第一个是使用一个avro souce和一个avro sink向另一个agent传递event,然后再写入特定目录。
先看看配置代码。
agent6.sources = avrosource //定义avrosource,可以使用avro client在网络上向其传送数据 agent6.sinks = avrosink agent6.channels = memorychannel agent6.sources.avrosource.type = avro agent6.sources.avrosource.bind = localhost agent6.sources.avrosource.port = 2000 agent6.sources.avrosource.threads = 5 agent6.sinks.avrosink.type = avro agent6.sinks.avrosink.hostname = localhost agent6.sinks.avrosink.port = 4000 //端口是4000,与下面agent3的source相对应 agent6.channels.memorychannel.type = memory agent6.channels.memorychannel.capacity = 1000 agent6.channels.memorychannel.transactionCapacity = 100 agent6.sources.avrosource.channels = memorychannel agent6.sinks.avrosink.channel = memorychannel
这里另一个agent的配置代码如下。
agent3.sources = avrosource //定义avro scource agent3.sinks = filesink agent3.channels = jdbcchannel //使用jdbc channel agent3.sources.avrosource.type = avro agent3.sources.avrosource.bind = localhost agent3.sources.avrosource.port = 4000 agent3.sources.avrosource.threads = 5 agent3.sinks.filesink.type = FILE_ROLL agent3.sinks.filesink.sink.directory = /home/leung/flume/files agent3.sinks.filesink.sink.rollInterval = 0 agent3.channels.jdbcchannel.type = jdbc agent3.sources.avrosource.channels = jdbcchannel agent3.sinks.filesink.channel = jdbcchannel
OK,从两个配置文件可以看出,event是从agent6向agent3传递,最后写入到files目录中。首先逐一启动agent。

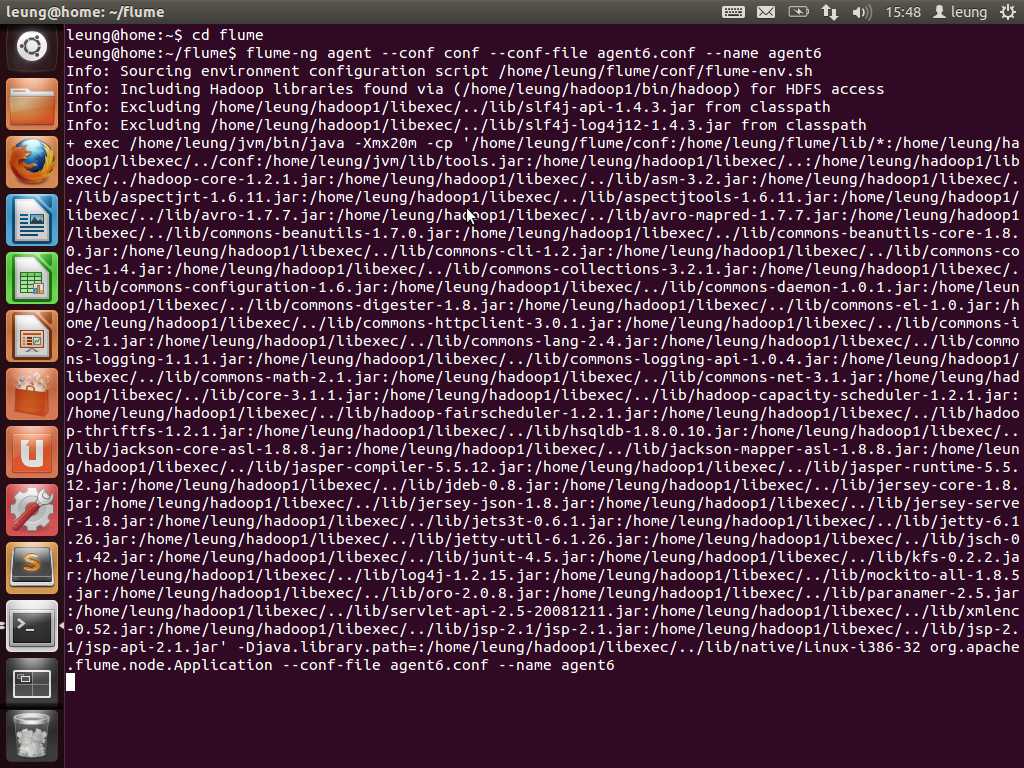
因为两个agent都是使用avro source,故现在尝试使用avro-client向两个agent分别提交数据。首先是向agent3提交message,这个message的内容是today is a good day.
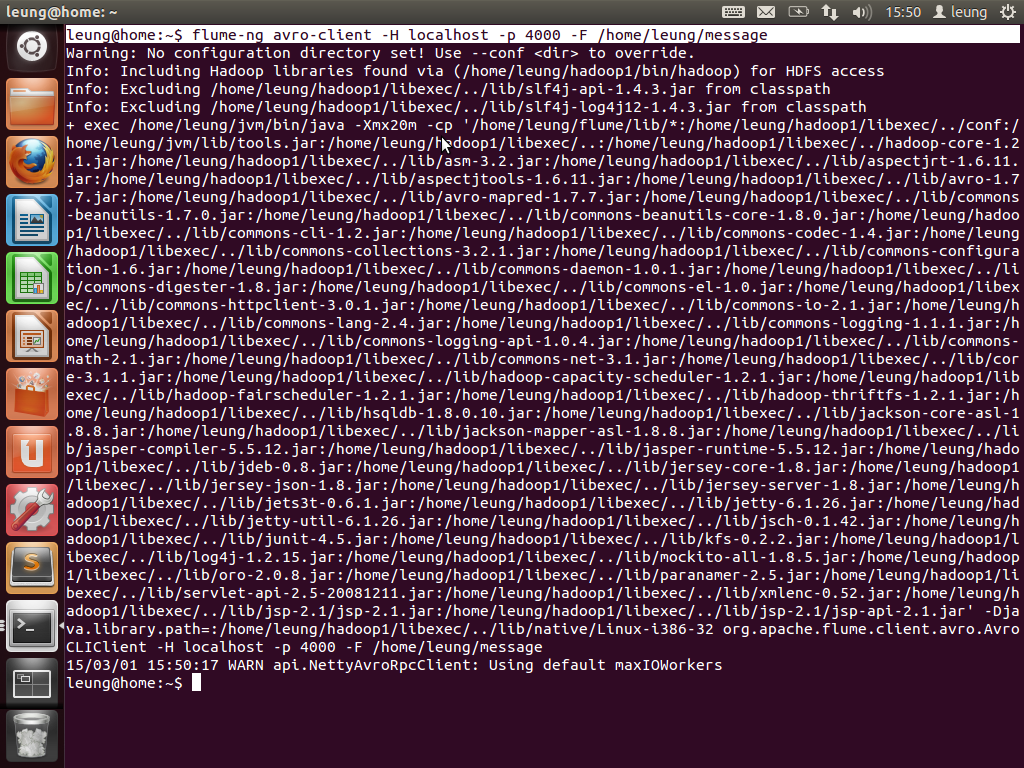
然后再向agent6提交数据。message2的内容是hadoop is a good project!
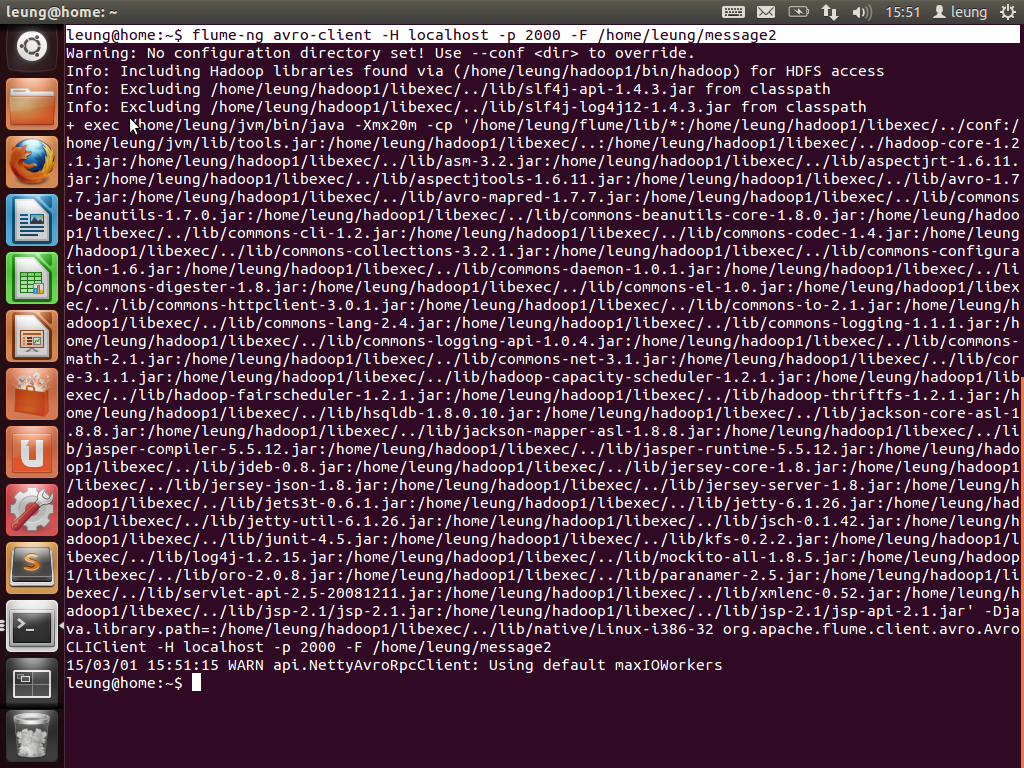
最后看一下目标文件的写入情况。可以看到两句话的先后顺序。由于都是由同一个agent写入,故都写在了同一个文件。
这样就实现了一个chain。向2000端口提交数据,数据经过agent6,agent3,最后到达目标文件。大家可以按照这个例子实现多个chain,在network上通信主要是使用avro,故中间节点同时需要使用avro source 和avro sink两个类型。
最后再看一个agent。这个agent实现从一个source传入多个sink。这里是通过两个memorychannel分别将event传入hdfs以及files。首先看agent的配置代码。
agent7.sources = netsource agent7.sinks = hdfssink filesink //分别定义两个sink agent7.channels = memorychannel1 memorychannel2 //分别定义两个channel agent7.sources.netsource.type = netcat agent7.sources.netsource.bind = localhost agent7.sources.netsource.port = 3000 agent7.sources.netsource.interceptors = ts agent7.sources.netsource.interceptors.ts.type = org.apache.flume.interceptor.TimestampInterceptor$Builder agent7.sinks.hdfssink.type = hdfs agent7.sinks.hdfssink.hdfs.path = /flume-%Y-%m-%d agent7.sinks.hdfssink.hdfs.filePrefix = log agent7.sinks.hdfssink.hdfs.rollInterval = 0 agent7.sinks.hdfssink.hdfs.rollCount = 3 agent7.sinks.hdfssink.hdfs.fileType = DataStream agent7.sinks.filesink.type = FILE_ROLL agent7.sinks.filesink.sink.directory = /home/leung/flume/files agent7.sinks.filesink.sink.rollInterval = 0 agent7.channels.memorychannel1.type = memory agent7.channels.memorychannel1.capacity = 1000 agent7.channels.memorychannel1.transactionCapacity = 100 agent7.channels.memorychannel2.type = memory agent7.channels.memorychannel2.capacity = 1000 agent7.channels.memorychannel2.transactionCapacity = 100 agent7.sources.netsource.channels = memorychannel1 memorychannel2 agent7.sinks.hdfssink.channel = memorychannel1 //指定channel1对应hdfssink agent7.sinks.filesink.channel = memorychannel2 //指定channel2对应filesink agent7.sources.netsource.selector.type = replicating //指定source传递到sink的方式为全部sink都接收全部event
下面启动agent7。

这里source的selectors选择了replicating,故会向所有channel传送全部的event。如果选择multiplexing,则会根据指定的header field传送到指定的sink。ok,下面看一下结果。分别在hdfs以及files目录中看到输入的信息。
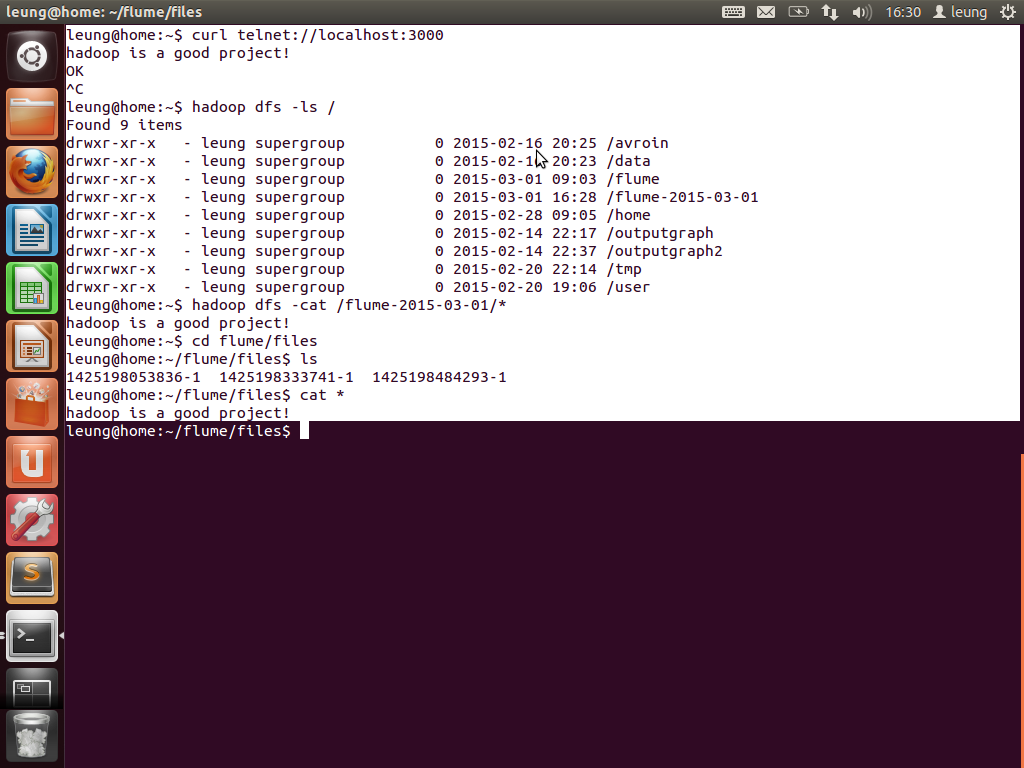
到这里,可以想象一下。首先实现从web server获取数据,然后通过一个agent传送到hadoop集群,然后传递到下一个agent,再由下一个agent传递到本地保存,或者传递到什么地方。。。可以由大家自由发挥!可见,flume是一款非常灵活以及方便的工具!
谢谢大家!水平有限,请不吝指正!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号