loadstach使用
loadstach是一个数据导入引擎
现在我需要将数据库中acc_persons表的内容导入到elasticsearch中
做如下配置
在loadstach安装目录的config目录下新建acc_persons_oracle.conf文件(配置导入规则)
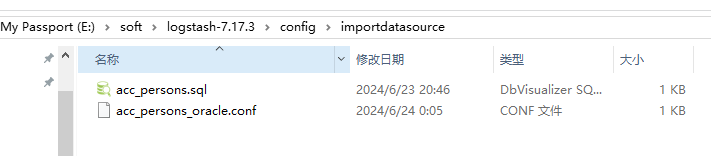
input {
jdbc {
jdbc_driver_library => "E:/soft/logstash-7.17.3/lib/ojdbc6-11.2.0.3.jar"
jdbc_driver_class => "Java::oracle.jdbc.OracleDriver"
jdbc_connection_string => "jdbc:oracle:thin:@127.0.0.1:1521:orcl"
jdbc_user => "szwy"
jdbc_password => "szwy"
use_column_value => "true"
#通过uniqid增量增加
tracking_column => "uniqid"
last_run_metadata_path => "E:/soft/logstash-7.17.3/config/station_parameter.txt"
#定时任务 每分钟更新导入
schedule => "* * * * *"
#导入的执行文件路径 也可以使用statement: select 'acc_persons' as es_index (写清所有参数因为要建立es的field) from acc_persons
statement_filepath => "E:/soft/logstash-7.17.3/config/importdatasource/acc_persons.sql"
}
}
filter {}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
#导入到es中的索引名
index => "%{es_index}"
document_type => "_doc"
#上述查询sql中的uniqid 作为文档ID
document_id => "%{uniqid}"
}
}
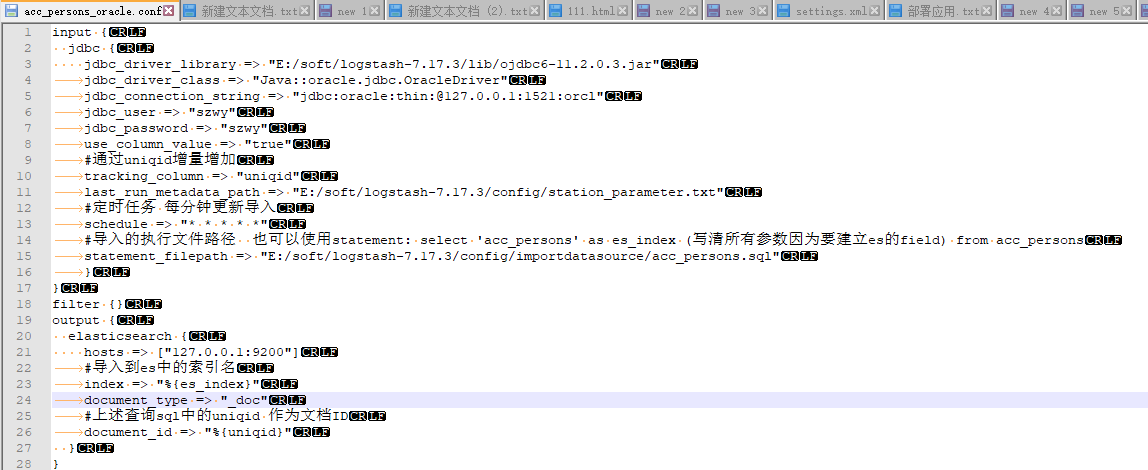
acc_persons.sql

配置管道
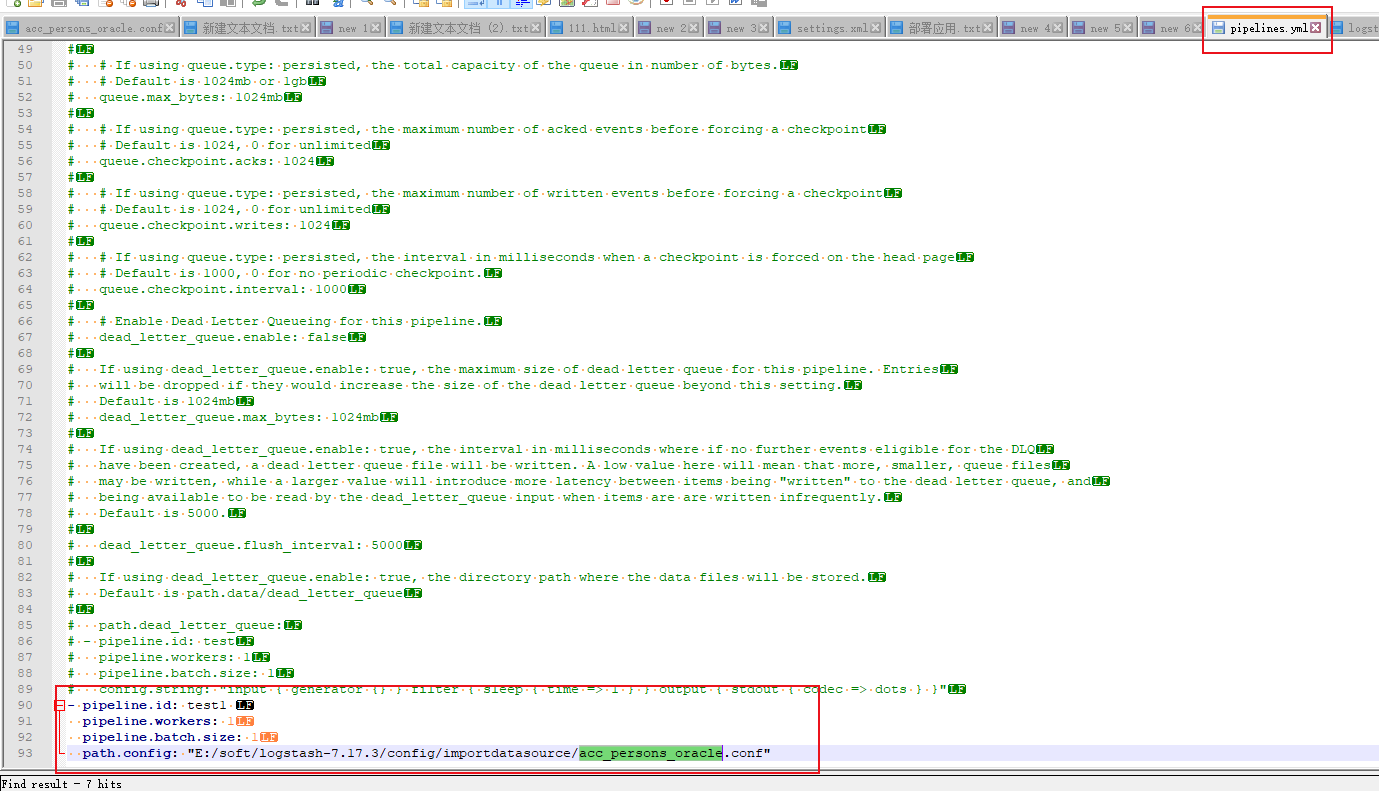
在bin目录使用命令 logstash.bat结果一直报错。。。
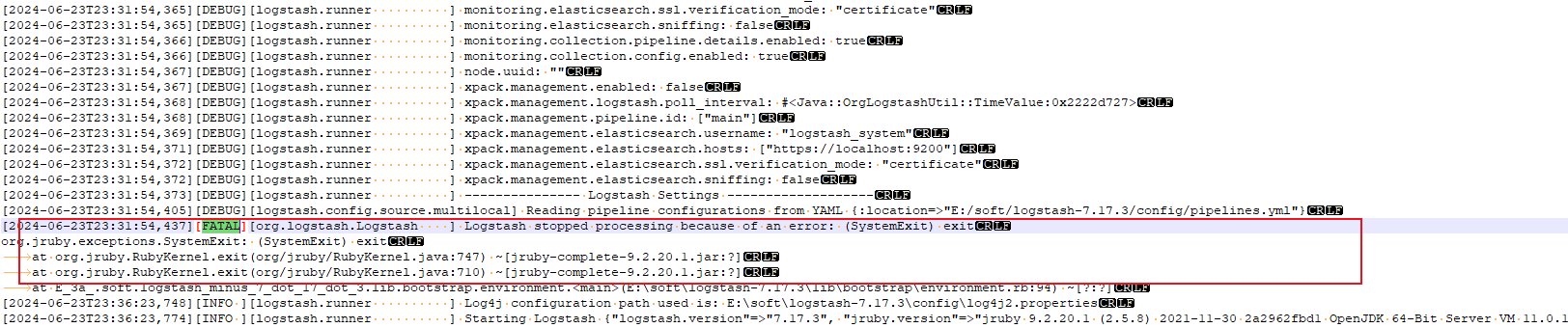
也不知道啥原因
先不管 于是我猜想会不会是没找到导入规则执行文件 于是把acc_persons_oracle.conf拷贝到bin目录下
执行命令 logstash.bat -f acc_persons_oracle.conf 结果成功了
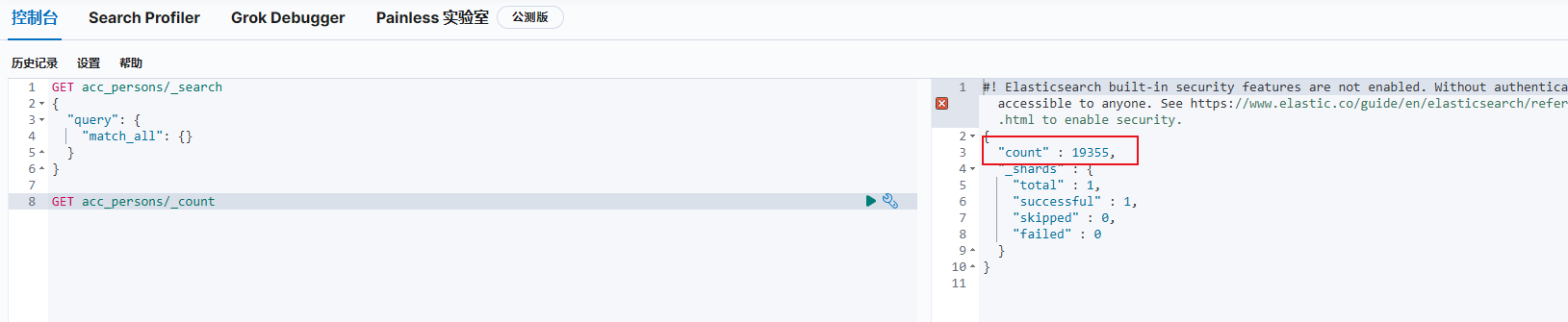
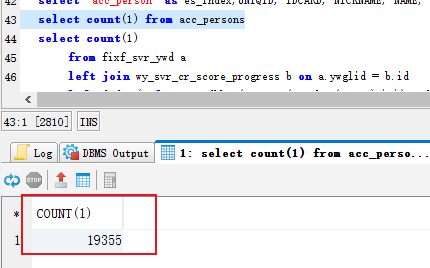
于是我去kibana验证看看数据是否导入成功 验证成功 数目对上了
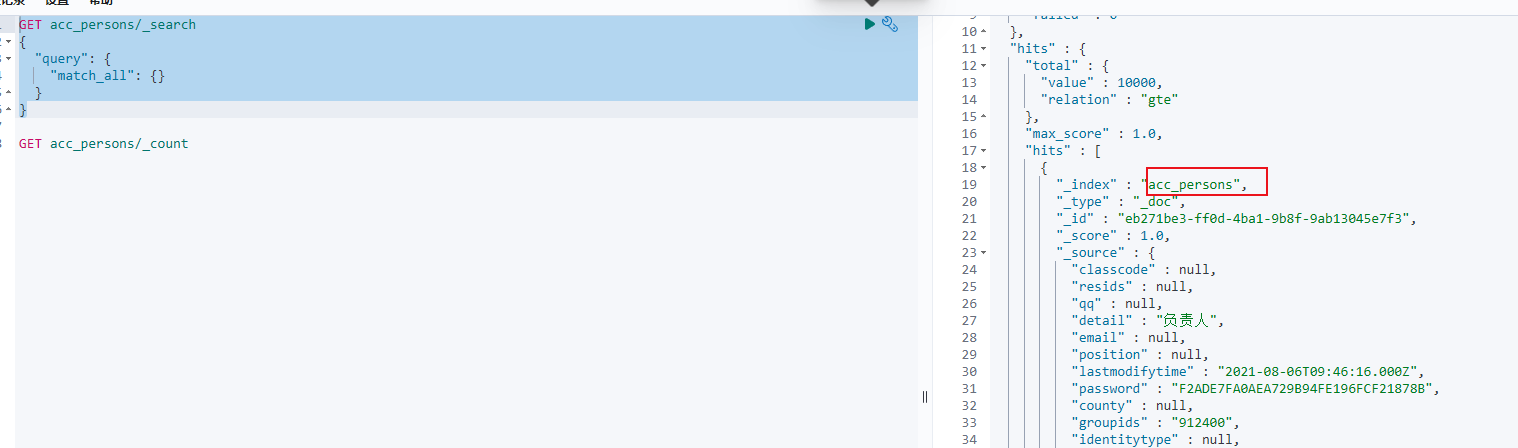
数据查询也成功了
但是上述直接pipelines.yml中为啥不能成功 不知道原因
下面是jdbc相关参数:转自(https://www.cnblogs.com/hahaha111122222/p/12859313.html)
| Setting | Input type | Required |
|---|---|---|
clean_run |
boolean | No |
columns_charset |
hash | No |
connection_retry_attempts |
number | No |
connection_retry_attempts_wait_time |
number | No |
jdbc_connection_string |
string | Yes |
jdbc_default_timezone |
string | No |
jdbc_driver_class |
string | Yes |
jdbc_driver_library |
string | No |
jdbc_fetch_size |
number | No |
jdbc_page_size |
number | No |
jdbc_paging_enabled |
boolean | No |
jdbc_password |
password | No |
jdbc_password_filepath |
a valid filesystem path | No |
jdbc_pool_timeout |
number | No |
jdbc_user |
string | Yes |
jdbc_validate_connection |
boolean | No |
jdbc_validation_timeout |
number | No |
last_run_metadata_path |
string | No |
lowercase_column_names |
boolean | No |
parameters |
hash | No |
record_last_run |
boolean | No |
schedule |
string | No |
sequel_opts |
hash | No |
sql_log_level |
string, one of ["fatal", "error", "warn", "info", "debug"] |
No |
statement |
string | No |
statement_filepath |
a valid filesystem path | No |
tracking_column |
string | No |
tracking_column_type |
string, one of ["numeric", "timestamp"] |
No |
use_column_value |
boolean | No |
clean_run
- 值类型为布尔值
- 默认值为
false
是否应保留先前的运行状态
columns_charset
- 值类型为哈希
- 默认值为
{}
特定列的字符编码。此选项将覆盖:charset指定列的选项。
例:
输入{
jdbc { ...
columns_charset => { “ column0” => “ ISO-8859-1” } ... } }
这只会转换具有ISO-8859-1作为原始编码的column0。
connection_retry_attempts
- 值类型是数字
- 默认值为
1
尝试连接数据库的最大次数
connection_retry_attempts_wait_time
- 值类型是数字
- 默认值为
0.5
两次尝试之间休眠的秒数
jdbc_connection_string
- 这是必需的设置。
- 值类型为字符串
- 此设置没有默认值。
JDBC连接字符串
jdbc_default_timezone
- 值类型为字符串
- 此设置没有默认值。
时区转换。SQL不允许在时间戳字段中输入时区数据。此插件将以ISO8601格式的相对UTC时间自动将您的SQL时间戳字段转换为Logstash时间戳。
使用此设置将手动分配指定的时区偏移,而不是使用本地计算机的时区设置。例如,您必须使用标准时区,例如America / Denver。
jdbc_driver_class
- 这是必需的设置。
- 值类型为字符串
- 此设置没有默认值。
例如,如果使用的是Oracle JDBC,则按照https://github.com/logstash-plugins/logstash-input-jdbc/issues/43加载的JDBC驱动程序类,例如“ org.apache.derby.jdbc.ClientDriver” NB。驱动程序(ojdbc6.jar)正确jdbc_driver_class是"Java::oracle.jdbc.driver.OracleDriver"
jdbc_driver_library
- 值类型为字符串
- 此设置没有默认值。
尝试将JDBC逻辑抽象为mixin,以便在其他插件(输入/输出)中潜在地重用。当某人包含此模块时,将调用此方法。将这些方法添加到给定的基础中。第三方驱动程序库的JDBC驱动程序库路径。如果需要多个库,可以通过逗号分隔它们。
如果未提供,则插件将在Logstash Java类路径中查找驱动程序类。
jdbc_fetch_size
- 值类型是数字
- 此设置没有默认值。
JDBC提取大小。如果未提供,将使用各自的驱动程序默认值
jdbc_page_size
- 值类型是数字
- 默认值为
100000
JDBC页面大小
jdbc_paging_enabled
- 值类型为布尔值
- 默认值为
false
JDBC启用分页
这将导致sql语句分解为多个查询。每个查询将使用限制和偏移量来集体检索完整的结果集。限制大小通过设置jdbc_page_size。
请注意,不能保证查询之间的顺序。
jdbc_password
- 值类型为密码
- 此设置没有默认值。
JDBC密码
jdbc_password_filepath
- 值类型是路径
- 此设置没有默认值。
JDBC密码文件名
jdbc_pool_timeout
- 值类型是数字
- 默认值为
5
连接池配置。引发PoolTimeoutError之前等待获取连接的秒数(默认为5)
jdbc_user
- 这是必需的设置。
- 值类型为字符串
- 此设置没有默认值。
JDBC用户
jdbc_validate_connection
- 值类型为布尔值
- 默认值为
false
连接池配置。使用前验证连接。
jdbc_validation_timeout
- 值类型是数字
- 默认值为
3600
连接池配置。验证连接的频率(以秒为单位)
last_run_metadata_path
- 值类型为字符串
- 默认值为
"$HOME/.logstash_jdbc_last_run"
上次运行时间的文件路径
lowercase_column_names
- 值类型为布尔值
- 默认值为
true
是否强制使用标识符字段的小写
parameters
- 值类型为哈希
- 默认值为
{}
查询参数的散列,例如 { "target_id" => "321" }
record_last_run
- 值类型为布尔值
- 默认值为
true
是否保存状态 last_run_metadata_path
schedule
- 值类型为字符串
- 此设置没有默认值。
定期运行语句的时间表,例如Cron格式:“ * * * * *”(每分钟,每分钟执行一次查询)
默认情况下没有时间表。如果没有给出时间表,则该语句仅运行一次。
sequel_opts
- 值类型为哈希
- 默认值为
{}
常规/特定于供应商的续集配置选项。
可选连接池配置的示例max_connections-连接池的最大连接数
可以在此文档页面中找到特定于供应商的选项的示例:https : //github.com/jeremyevans/sequel/blob/master/doc/opening_databases.rdoc
sql_log_level
- 值可以是任何的:
fatal,error,warn,info,debug - 默认值为
"info"
记录SQL查询的日志级别,可接受的值是常见的致命,错误,警告,信息和调试值。默认值为info。
statement
- 值类型为字符串
- 此设置没有默认值。
如果未定义,则即使未使用编解码器,Logstash也会进行投诉。执行语句
要使用参数,请使用命名参数语法。例如:
“选择*从MYTABLE WHERE id =:target_id”
在这里,“:target_id”是一个命名参数。您可以使用该parameters设置配置命名参数。
statement_filepath
- 值类型是路径
- 此设置没有默认值。
包含要执行的语句的文件的路径
tracking_column
- 值类型为字符串
- 此设置没有默认值。
值将被跟踪的列use_column_value设置为true
tracking_column_type
- 值可以是任何的:
numeric,timestamp - 默认值为
"numeric"
跟踪列的类型。目前仅“数字”和“时间戳”
use_column_value
- 值类型为布尔值
- 默认值为
false
设置为时true,将定义的 tracking_column值用作:sql_last_value。设置为时false,:sql_last_value反映上一次执行查询的时间。
常用选项
| Setting | Input type | Required |
|---|---|---|
add_field |
hash | No |
codec |
codec | No |
enable_metric |
boolean | No |
id |
string | No |
tags |
array | No |
type |
string | No |
add_field
- 值类型为哈希
- 默认值为
{}
向事件添加字段
codec
- 值类型为编解码器
- 默认值为
"plain"
用于输入数据的编解码器。输入编解码器是一种在数据输入之前解码数据的便捷方法,而无需在Logstash管道中使用单独的过滤器。
enable_metric
- 值类型为布尔值
- 默认值为
true
默认情况下,为此特定插件实例禁用或启用度量标准日志记录,我们会记录所有可以度量的数据,但是您可以禁用特定插件的度量标准收集。
id
- 值类型为字符串
- 此设置没有默认值。
ID向插件配置添加唯一。如果未指定ID,Logstash将生成一个。强烈建议在您的配置中设置此ID。当您有两个或多个相同类型的插件时,例如在您有2个jdbc输入时,这特别有用。在这种情况下,添加命名ID将有助于在使用监视API时监视Logstash。
输入{
jdbc {
id => “ my_plugin_id” } }
tags
- 值类型为数组
- 此设置没有默认值。
将任意数量的任意标签添加到您的事件中。
这可以帮助以后进行处理。
type
- 值类型为字符串
- 此设置没有默认值。
type向此输入处理的所有事件添加一个字段。
类型主要用于过滤器激活。
该类型存储为事件本身的一部分,因此您也可以使用该类型在Kibana中进行搜索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号