
windows安装elasticSearch
可参考文档(https://blog.csdn.net/Zhuxiaoyu_91/article/details/132126216)(https://blog.csdn.net/xyy1028/article/details/126948634)(https://www.cnblogs.com/dwywtd/p/16842731.html)
使用logstach同步mysql数据到 elasticsearch(https://blog.csdn.net/weixin_45394216/article/details/132906233)
elasticsearch好文(https://blog.csdn.net/dangfulin/article/details/124655391)
elasticsearch 使用restful风格的api,举例
{http_method} http://{server}:{port}/{index_name}/{api}/
查询:查询书籍ID为1的书
GET http://localhost:9200:books/_doc/1
GET books/count 查询索引中的有多少文档
GET books/_search{
query:{
ids:{
values:{1,2,3}
}
}
} 查询id为1,2,3的书 _search 是API books是索引 query是API的方法
由于elasticsearch是通过查询出的内容的得分来进行结果排序的 因此有种复合查询
包含以下四个属性
must: 一定要匹配的字段
should :可以不匹配的字段,但是匹配上了增加得分(score)
filter:必须要匹配查询条件,但是不参与得分计算
must not:不匹配的字段
GET books/_search{
"query":{
"bool":{
"must":[{
"match":{"auther":{"A"}}
}
]
"should":[
{"range":{"price":{"lt":50}}}
]
}
}
} 查询书名为“作者”为A的所有书,价值大于50的靠前(得分高),小于等于50的也会被查询到但是排名靠后(得分相对低)
eg:
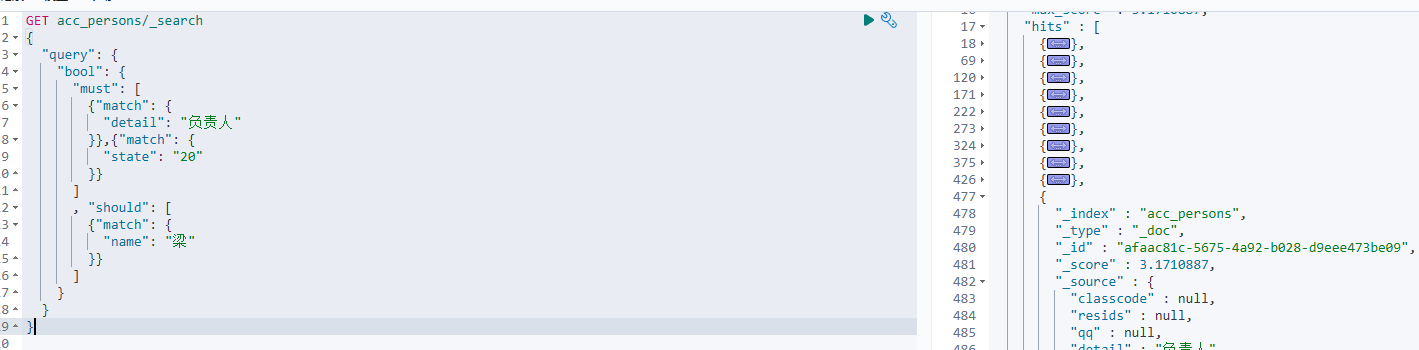
curl -XGET "http://localhost:9200/acc_persons/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{"match": {
"detail": "负责人"
}},{"match": {
"state": "20"
}}
]
, "should": [
{"match": {
"name": "梁"
}}
]
}
}
}'
安装elasticSearch
下载地址:官网https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-17-3
ealsticSearch支持的javajdk版本对照表:
https://www.elastic.co/cn/support/matrix#matrix_jvm
由于使用的jdk是1.8 因此elasticSearch版本选择7.17.3
windows下载后直接解压即可。
设置环境变量

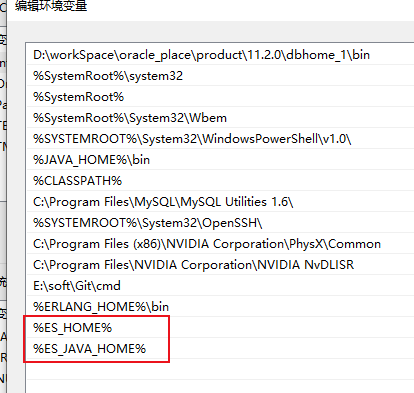
为什么环境变量取这个名字可看elasticSearch启动脚本
启动脚本会调用
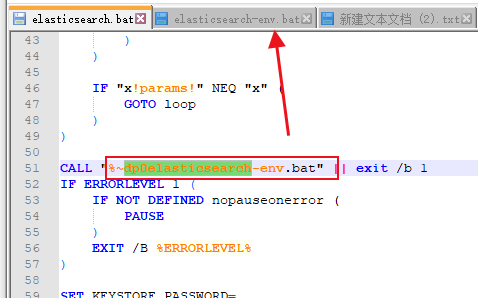
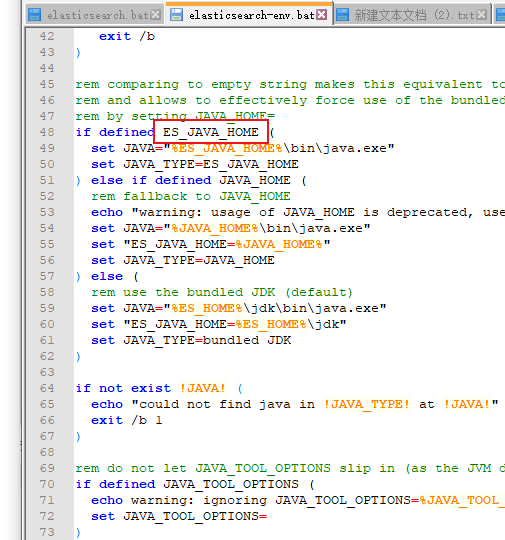
结果启动直接cmd窗口直接闪退,于是增加pause 命令查看发现是异常了且打印日志了
于是看日志发现是内存不够(我当时C盘只有1G左右空间了)。。这玩意儿也是启动脚本里的jvm检测,直接默认整了10G。。。
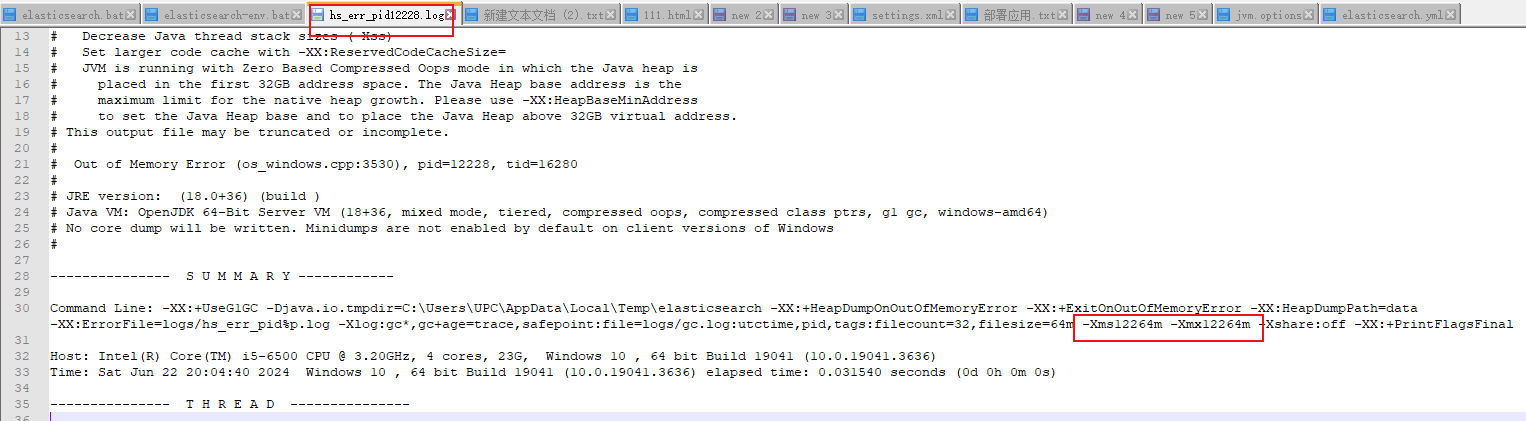
解决办法:
在config/jvm.options配置文件里增加jvm虚拟机内存配置参数
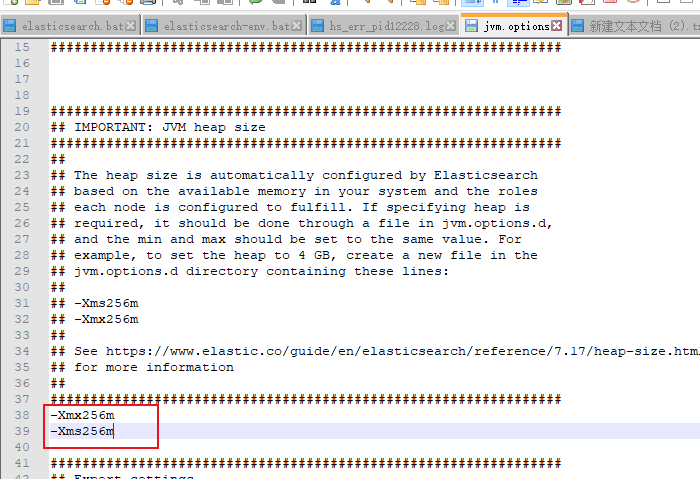
启动还是报错:原因是我的安装盘1T 还剩70G 磁盘使用率超过了90% 好像这玩意儿默认是不能超过85%
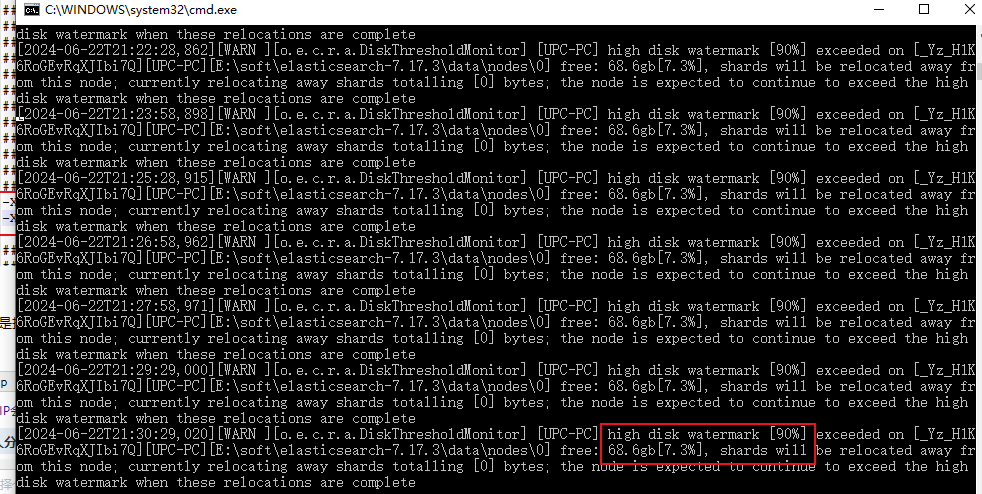
解决方法:
config/elasticsearch.yml增加如下配置:
cluster.routing.allocation.disk.threshold_enabled: true
cluster.routing.allocation.disk.watermark.low: 93% 磁盘使用率高于该值则阻止分配副本
cluster.routing.allocation.disk.watermark.high: 95% 磁盘使用率高于该值则会优先分配到其他节点
cluster.routing.allocation.disk.watermark.flooded_stage: 默认值是95 (这个值不用配置)超过该值索引变为只读索引
三个值得默认值分别为85% 90% 95
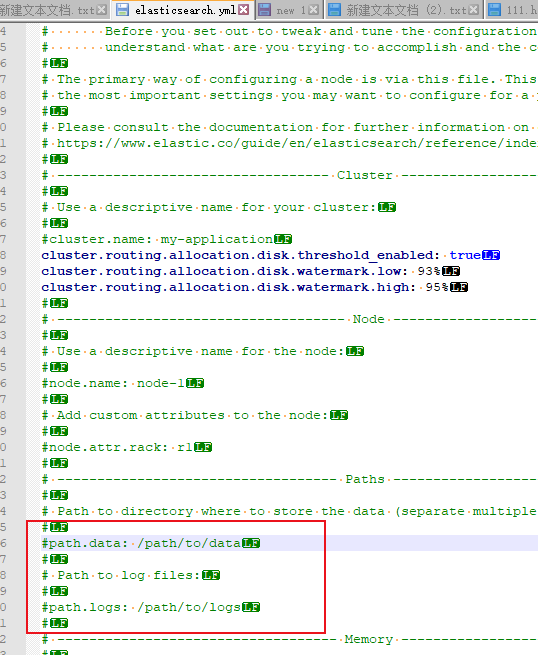
顺便将data文件和log存放路径也做修改 避免升级时将数据文件和日志文件清空导致丢失了
path.data: E://myesdata/data
path.logs: E://myesdata/log
换个方法安装:
本来直接执行启动脚本就可以安装
也可以使用服务的形式安装 那样启停服务方便 但是需要额外增加一个环境变量


步骤如下:
1.安装 elasticsearch-service.bat install
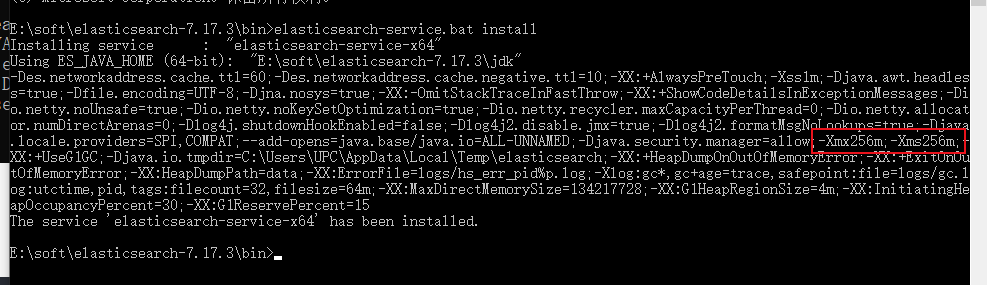
2. 启动服务 elasticsearch-service.bat start

3.关闭服务 elasticsearch-service.bat stop

4.卸载服务 elasticsearch-service.bat remove
5.启动属性gui elasticsearch-service.bat manager
安装成功
-------------------------------------------------------------------
安装elasticsearch-head
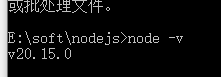
1.需要先安装node.js
安装地址:https://nodejs.org
安装成功

2. 安装grunt
安裝命令: npm install -g grunt-cli
3.下载elasticsearch-head
下载地址:https://github.com/mobz/elasticsearch-head/releases

解压文件夹
并在文件夹目录使用cmd
安装命令 npm install
安装好像提示版本不支持 但是只是警告级别 不是错误级别
我试着启动
npm run start
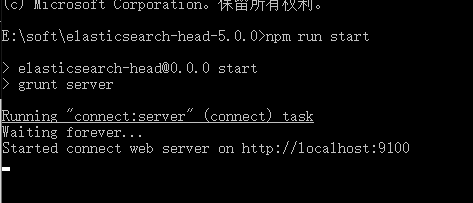
启动成功了
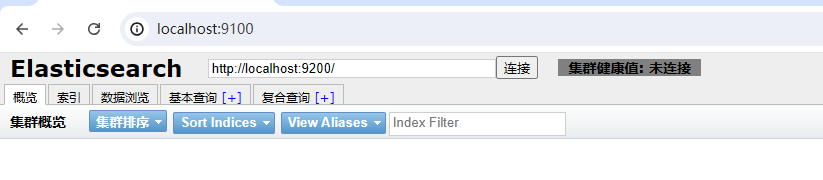
如果发现无法访问
可能是跨域问题(我都装在本机没有跨域问题)
则在elasticsearch安装目录:config/elasticsearch.yml
中增加
http.cors.enable: true
http.cors.allow-origin: 增加elasticsearch-head安裝的机器IP
-------------------------------------------------------------------------------------------------------------------------------------------------------
安装kinaba
kinaba版本必须和elasticsearch版本一致
下载地址:
https://www.elastic.co/cn/downloads/past-releases/kibana-7-17-3
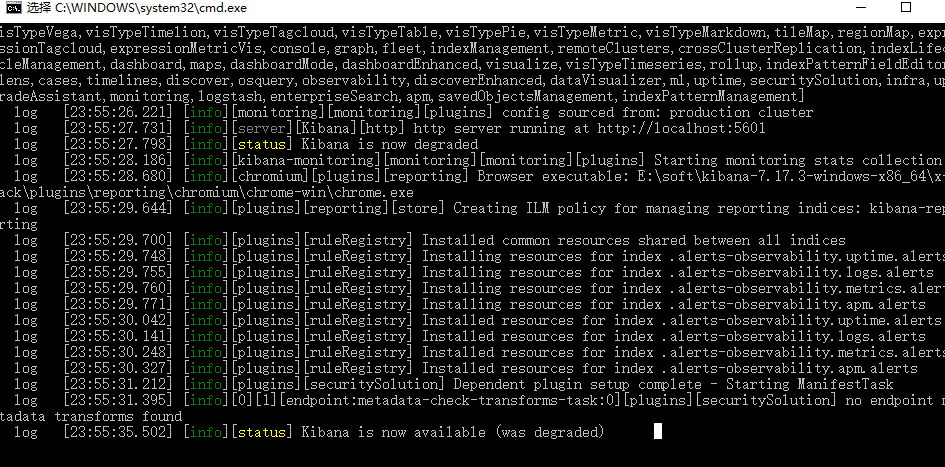
在config/kibana.yml中修改配置项
i18n.locale: "zh-CN"
设置成中文
启动成功
----------------------------------------------------------------------------------------------------------------------------------------------------------
下载地址:https://www.elastic.co/cn/downloads/past-releases/logstash-7-17-3
下载后解压



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人