
fegin的retry机制
服务间调用如果因为网络原因访问失败了,也可以考虑使用fegin的重发功能来重新访问服务。
配置了 ribbon或者loadBalance后,重发会根据负载均衡规则寻找新服务。
举例:feignServer客户端访问userModel服务(两个节点userModel1,userModel2)如果使用轮询策略(负载均衡)且就爱社userModel1网络中断,则feignServer访问userModel微服务,先访问userModel1发现连接失败(connect)
则重发服务再次访问userModel2,如果2也失败,会继续轮询访问userModel1。 如果userModel微服务部署的节点足够多,利用重发服务一定可以拿到响应值。
feign目前支持的重发只支持超时重发,如果要满足其他场景可以自己定义retryer重发器。
测试例子:
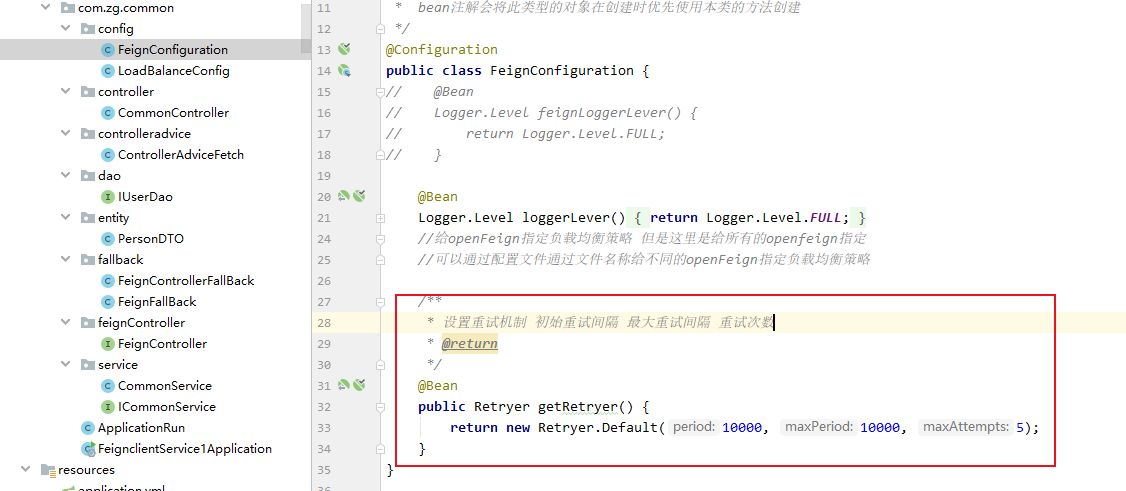
配置重发器 (fegin默认不使用重发机制)
两个服务节点8401服务和8404服务

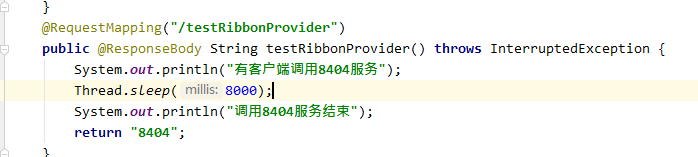
其中8404服务发布的接口方法 设置线程休眠8秒钟
客户端设置超时时间来模拟fegin超时后重发服务
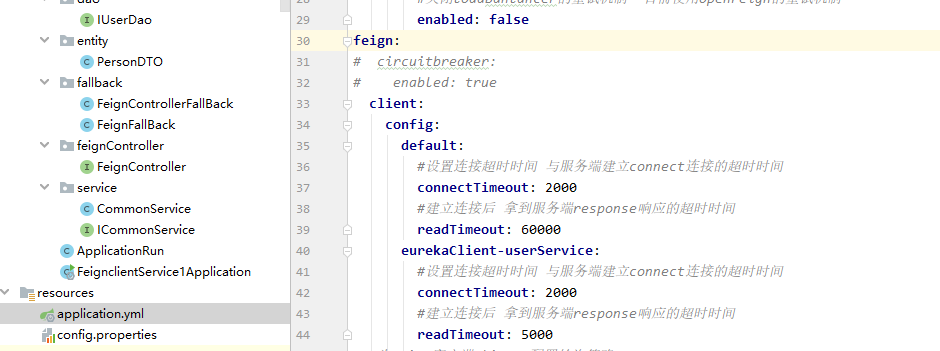
见如上配置可知,当客户端访问到8401端口服务,则正常访问,如果访问8404端口服务,connect连接建立之后,由于8404服务端口线程休眠了8秒钟,导致在第5秒钟时fegin就触发了超时(5秒内未拿到resonse),因此触发重发。
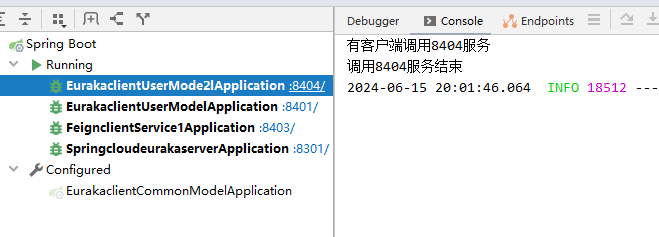
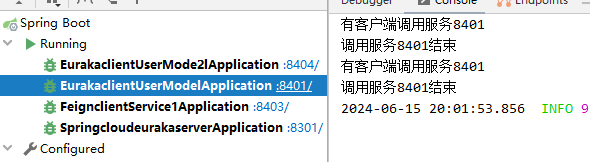
测试结果:第一次访问的8401端口服务,第二次访问的8404端口服务。可以看到时间开销为15秒。
为什么拿到结果的时间消耗是15秒呢? 由于我配置的connect连接超时设置是5秒,超时重发间隔是10秒,因此在请求8404服务失败后(花费5秒)。间隔10秒(花费10秒),轮询到下一个服务节点,调用服务成功,总共15秒。

由下图可得 8404服务调用了一次(超时) 8401服务调用了两次
跟踪源码
feign-core.jar.feign.SynchronousMethodHandler(类)调用invoke()方法
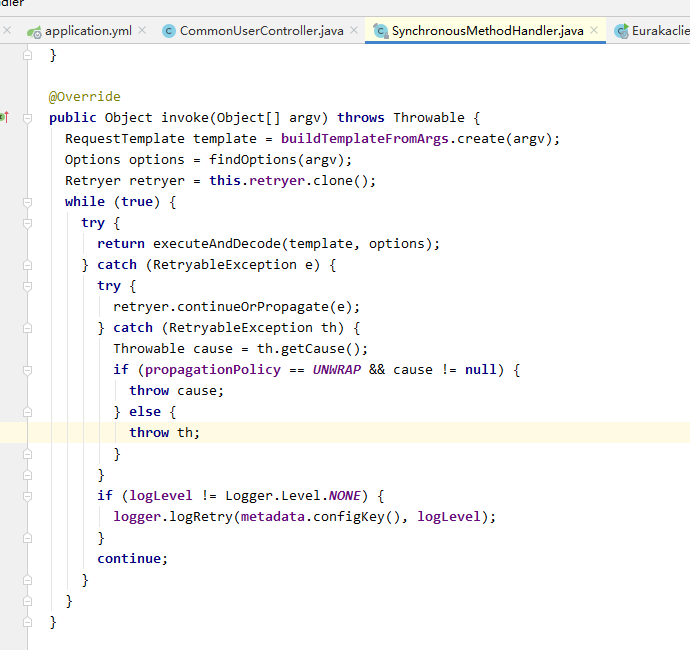
将代码拷出来注释
@Override
public Object invoke(Object[] argv) throws Throwable {
RequestTemplate template = buildTemplateFromArgs.create(argv);
//获得feign服务的超时设置(见上面yml文件的配置)
Options options = findOptions(argv);
//获得配置的重发器
Retryer retryer = this.retryer.clone();
while (true) {
try {
//执行http服务 如果超时则封装一个RetryableException抛出 被下方代码捕获后进行重发
return executeAndDecode(template, options);
} catch (RetryableException e) {
try {
//判断重发次数和重发间隔
retryer.continueOrPropagate(e);
} catch (RetryableException th) {
Throwable cause = th.getCause();
if (propagationPolicy == UNWRAP && cause != null) {
throw cause;
} else {
throw th;
}
}
if (logLevel != Logger.Level.NONE) {
logger.logRetry(metadata.configKey(), logLevel);
}
continue;
}
}
}
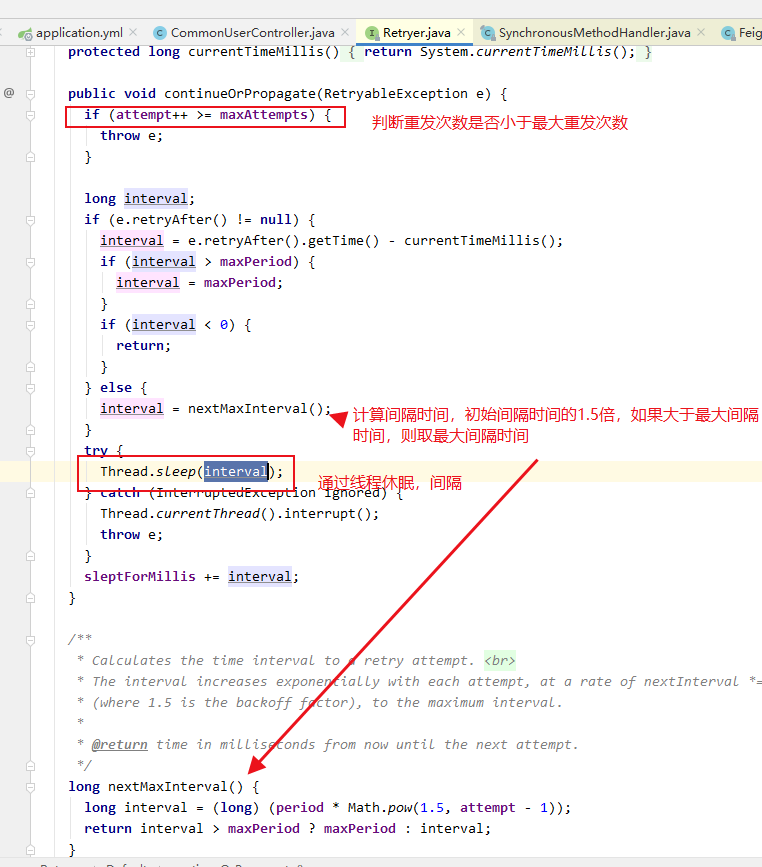
然后这里有个坑,如果配置了熔断方法,重发服务会失败,在超时后会进入熔断回调方法fallback,而不是进行重发。
原因:默认的熔断超时时间是1秒钟(没有配置的话) 我配置的feign超时是5秒。。。。feign还没判断进入超时状态就触发了熔断,产生了熔断线程。进入熔断服务。
(可参考https://blog.csdn.net/guntun8987/article/details/130971101)(https://blog.csdn.net/qq_28314431/article/details/128581203)
上诉代码都是在配置中取消了熔断服务。
加上熔断服务。
调试代码:发现异常类型是HytixTimeoutException 因为只过了1秒钟就触发熔断,创建熔断线程进入熔断回调方法。。
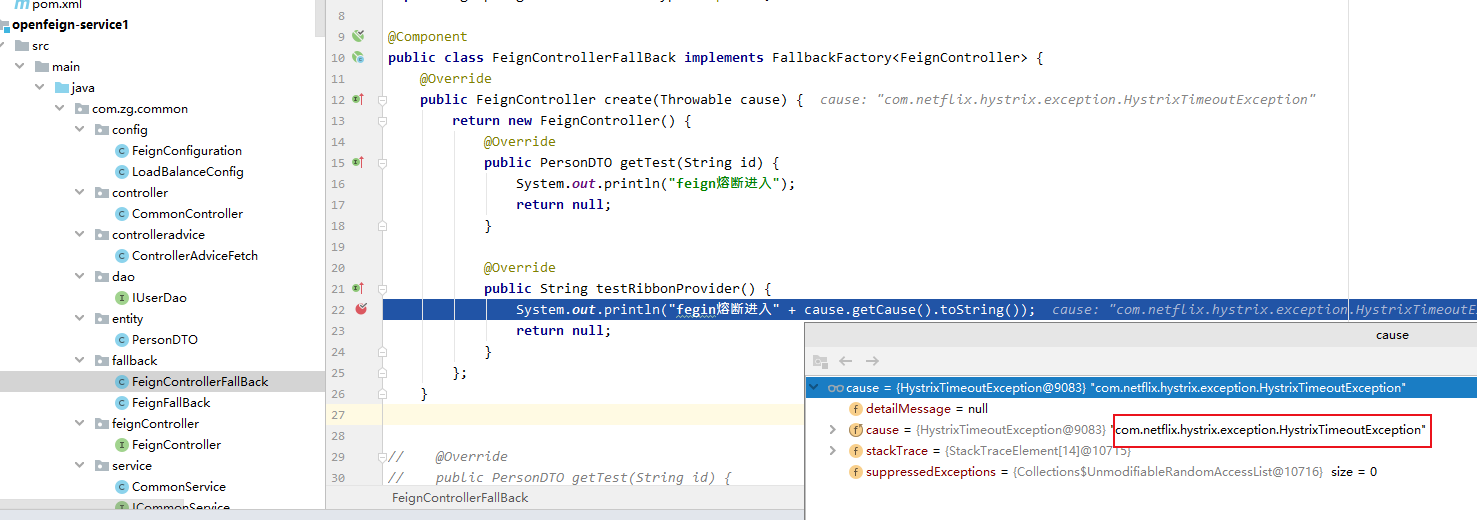
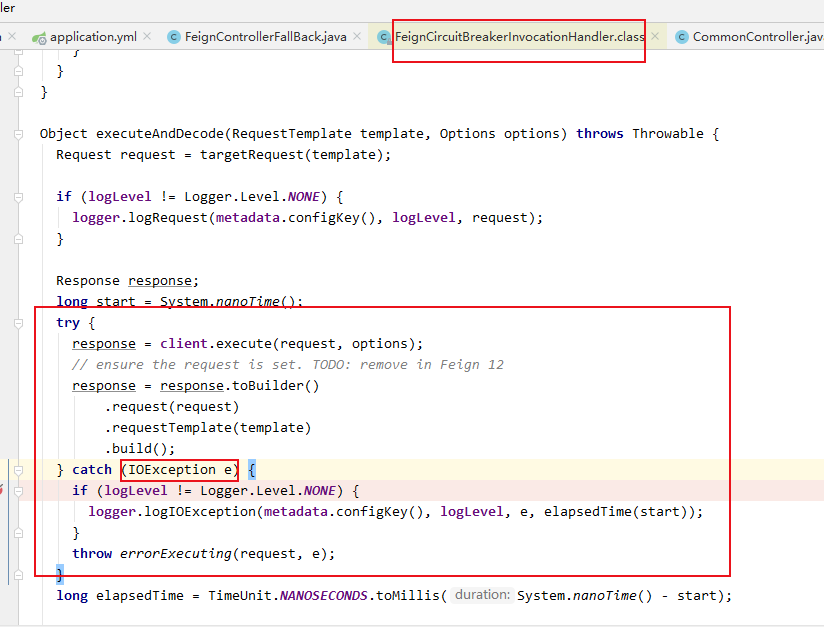
由重发执行的代码来看,只有IOExcetion才会被捕获封装成RetryableException异常。
执行命令的线程变了
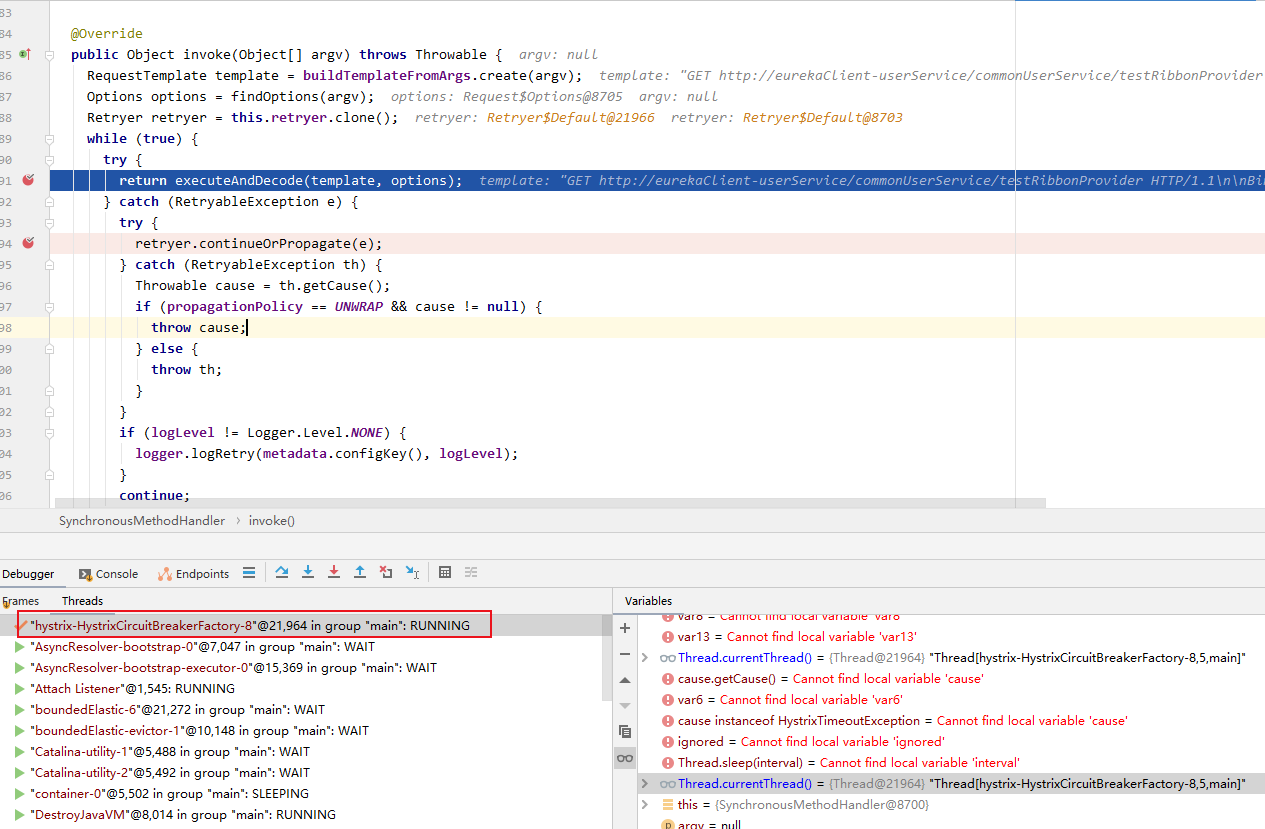
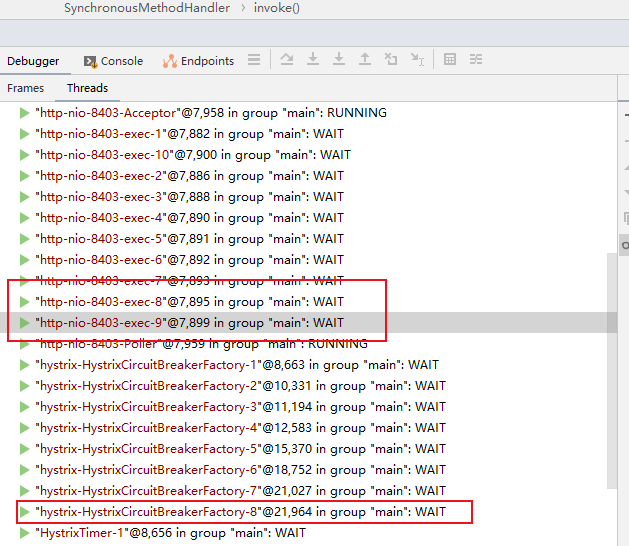
不加熔断方法(前面重发执行成功)时的线程是http-nio-8403 增加熔断方法后执行上诉访问微服务代码的线程变成了hystrix-HystrixCircuitBreakerFactory
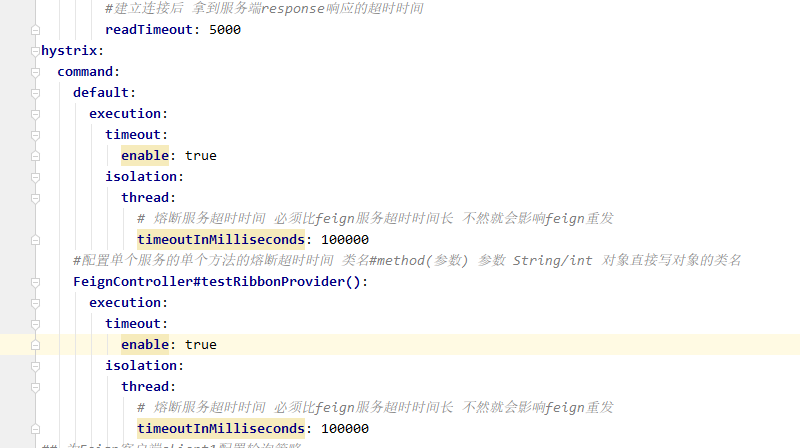
解决方案:增加hystrix的熔断超时时间 配置文件做如下修改
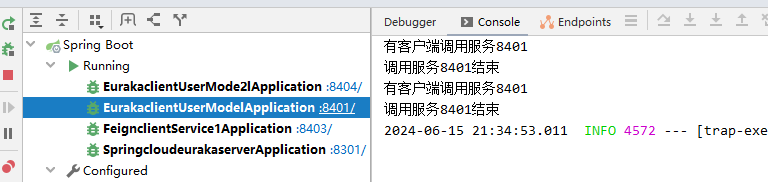
测试结果:符合上诉结果 8404调用一次 8401调用两次(其中一次是调用8404失败后重发调用)


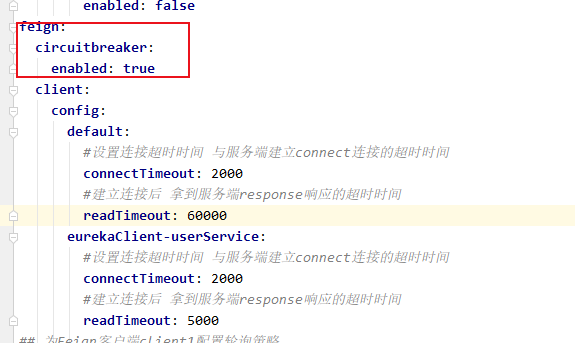
把配置拷出来:
feign:
circuitbreaker:
enabled: true
client:
config:
default:
#设置连接超时时间 与服务端建立connect连接的超时时间
connectTimeout: 2000
#建立连接后 拿到服务端response响应的超时时间
readTimeout: 60000
eurekaClient-userService:
#设置连接超时时间 与服务端建立connect连接的超时时间
connectTimeout: 2000
#建立连接后 拿到服务端response响应的超时时间
readTimeout: 5000
hystrix:
command:
default:
execution:
timeout:
enable: true
isolation:
thread:
# 熔断服务超时时间 必须比feign服务超时时间长 不然就会影响feign重发
timeoutInMilliseconds: 100000
#配置单个服务的单个方法的熔断超时时间 类名#method(参数) 参数 String/int 对象直接写对象的类名
FeignController#testRibbonProvider():
execution:
timeout:
enable: true
isolation:
thread:
# 熔断服务超时时间 必须比feign服务超时时间长 不然就会影响feign重发
timeoutInMilliseconds: 100000



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人