超详细总结面试常问的排序算法
常用排序算法总结
排序算法大体可分为两种:
一种是比较排序,时间复杂度O(nlogn) ~ O(n^2),主要有:冒泡排序,选择排序,插入排序,归并排序,堆排序,快速排序等。
另一种是非比较排序,时间复杂度可以达到O(n),主要有:计数排序,基数排序,桶排序等。
1. 常用的比较排序算法
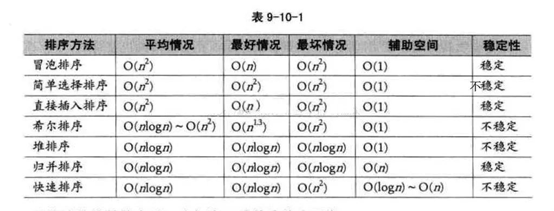
有一点我们很容易忽略的是排序算法的稳定性(腾讯校招2016笔试题曾考过)。排序算法稳定性的简单形式化定义为:如果Ai=Aj,排序前Ai在Aj之前,排序后Ai还在Aj之前,则称这种排序算法是稳定的。通俗地讲就是保证排序前后两个相等的数的相对顺序不变。
对于不稳定的排序算法,只要举出一个实例,即可说明它的不稳定性;而对于稳定的排序算法,必须对算法进行分析从而得到稳定的特性。需要注意的是,排序算法是否为稳定的是由具体算法决定的,不稳定的算法在某种条件下可以变为稳定的算法,而稳定的算法在某种条件下也可以变为不稳定的算法。
例如,对于冒泡排序,原本是稳定的排序算法,如果将记录交换的条件改成A[i] >= A[i + 1],则两个相等的记录就会交换位置,从而变成不稳定的排序算法。
其次,说一下排序算法稳定性的好处。排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,前一个键排序的结果可以为后一个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位排序后元素的顺序在高位也相同时是不会改变的。
(1) 冒泡排序
思想:重复地走访过要排序的元素,依次比较相邻两个元素,如果他们的顺序错误就把他们调换过来,直到没有元素再需要交换,排序完成。这个算法的名字由来是因为越小(或越大)的元素会经由交换慢慢“浮”到数列的顶端。
算法步骤:
1.比较相邻的元素,如果前一个比后一个大,就把它们两个调换位置。
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
Python代码:

(2) 选择排序
思想:初始时在序列中找到最小(大)元素,放到序列的起始位置作为已排序序列;然后,再从剩余未排序元素中继续寻找最小(大)元素,放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
Python代码:

选择排序是不稳定的排序算法,不稳定发生在最小元素与A[i]交换的时刻。
比如序列:{ 5, 8, 5, 2, 9 },一次选择的最小元素是2,然后把2和第一个5进行交换,从而改变了两个元素5的相对次序。
(3) 插入排序
思想:非常类似于我们抓扑克牌,对于未排序数据(右手抓到的牌),在已排序序列(左手已经排好序的手牌)中从后向前扫描,找到相应位置并插入。
算法步骤:
1.从第一个元素开始,该元素可以认为已经被排序
2.取出下一个元素,在已经排序的元素序列中从后向前扫描
3.如果该元素(已排序)大于新元素,将该元素移到下一位置
4.重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
5.将新元素插入到该位置后
6.重复步骤2~5
Python代码:

插入排序不适合对于数据量比较大的排序应用。但是,如果需要排序的数据量很小,比如量级小于千,那么插入排序还是一个不错的选择。 插入排序在工业级库中也有着广泛的应用,在STL的sort算法和stdlib的qsort算法中,都将插入排序作为快速排序的补充,用于少量元素的排序(通常为8个或以下)。
插入排序的改进1:二分插入排序
对于插入排序,如果比较操作的代价比交换操作大的话,可以采用二分查找法来减少比较操作的次数,我们称为二分插入排序,代码如下:

当n较大时,二分插入排序的比较次数比直接插入排序的最差情况好得多,但比直接插入排序的最好情况要差,所当以元素初始序列已经接近升序时,直接插入排序比二分插入排序比较次数少。二分插入排序元素移动次数与直接插入排序相同,依赖于元素初始序列。
(4) 希尔排序(插入排序的更高效的改进)
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
1.插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
2.但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
思想:通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了(此时插入排序较快)。
Python代码:

希尔排序是不稳定的排序算法,虽然一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱。
比如序列:{ 3, 5, 10, 8, 7, 2, 8, 1, 20, 6 },h=2时分成两个子序列 { 3, 10, 7, 8, 20 } 和 { 5, 8, 2, 1, 6 } ,未排序之前第二个子序列中的8在前面,现在对两个子序列进行插入排序,得到 { 3, 7, 8, 10, 20 } 和 { 1, 2, 5, 6, 8 } ,即 { 3, 1, 7, 2, 8, 5, 10, 6, 20, 8 } ,两个8的相对次序发生了改变。
(5) 归并排序
思想:归并排序的实现分为递归实现与非递归(迭代)实现。递归实现的归并排序是算法设计中分治策略的典型应用,我们将一个大问题分割成小问题分别解决,然后用所有小问题的答案来解决整个大问题。非递归(迭代)实现的归并排序首先进行是两两归并,然后四四归并,然后是八八归并,一直下去直到归并了整个数组
归并排序算法主要依赖归并(Merge)操作。归并操作指的是将两个已经排序的序列合并成一个序列的操作,归并操作步骤如下:
1.申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
2.设定两个指针,最初位置分别为两个已经排序序列的起始位置
3.比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
4.重复步骤3直到某一指针到达序列尾
5.将另一序列剩下的所有元素直接复制到合并序列尾
Python代码(递归实现):

(6) 堆排序
堆是一种近似完全二叉树的结构(通常堆是通过一维数组来实现的),并满足性质:以最大堆(也叫大根堆、大顶堆)为例,其中父结点的值总是大于它的孩子节点。
算法步骤:
1.由输入的无序数组构造一个最大堆,作为初始的无序区
2.把堆顶元素(最大值)和堆尾元素互换
3.把堆(无序区)的尺寸缩小1,并调用heapify(A, 0)从新的堆顶元素开始进行堆调整
4.重复步骤2,直到堆的尺寸为1
堆排序是不稳定的排序算法,不稳定发生在堆顶元素与A[i]交换的时刻。
比如序列:{ 9, 5, 7, 5 },堆顶元素是9,堆排序下一步将9和第二个5进行交换,得到序列 { 5, 5, 7, 9 },再进行堆调整得到{ 7, 5, 5, 9 },重复之前的操作最后得到{ 5, 5, 7, 9 }从而改变了两个5的相对次序。
Python代码:

def heap_sink(heap, heap_size, parent_index):
"""最大堆-下沉算法"""
child_index = 2 * parent_index + 1
# temp保存需要下沉的父节点,用于最后赋值
temp = heap[parent_index]
while child_index < heap_size:
# 如果有右孩子,且右孩子比左孩子大,则定位到右孩子
if child_index + 1 < heap_size and heap[child_index + 1] > heap[child_index]:
child_index += 1
# 如果父节点的值不小于左右孩子节点的值,可直接跳出循环
if temp >= heap[child_index]:
break
heap[parent_index] = heap[child_index]
parent_index = child_index
child_index = 2 * parent_index + 1
heap[parent_index] = temp
def heap_sort(mylist):
"""堆排序"""
n = len(mylist)
# 1. 无序列表构建成最大堆
for i in range(n - 2 // 2, -1, -1):
heap_sink(mylist, n, i)
# 2. 循环删除堆顶元素,移到列表尾部,调节堆产生新的堆顶
for i in range(n - 1, 0, -1):
mylist[0], mylist[i] = mylist[i], mylist[0]
heap_sink(mylist, i, 0)
if __name__ == "__main__":
mylist = [1, 3, 4, 5, 2, 6, 9, 7]
heap_sort(mylist)
print(mylist)
(7) 快速排序
快速排序使用分治策略来把一个序列分为两个子序列。步骤为:
1.从序列中挑出一个元素,作为”基准”(pivot).
2.把所有比基准值小的元素放在基准前面,所有比基准值大的元素放在基准的后面(相同的数可以到任一边),这个称为分区(partition)操作。
3.对每个分区递归地进行步骤1~2,递归的结束条件是序列的大小是0或1,这时整体已经被排好序了。
Python代码:

快速排序是不稳定的排序算法,不稳定发生在基准元素与A[tail+1]交换的时刻。
比如序列:{ 1, 3, 4, 2, 8, 9, 8, 7, 5 },基准元素是5,一次划分操作后5要和第一个8进行交换,从而改变了两个元素8的相对次序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号