关于LSTM的输入和训练过程的理解
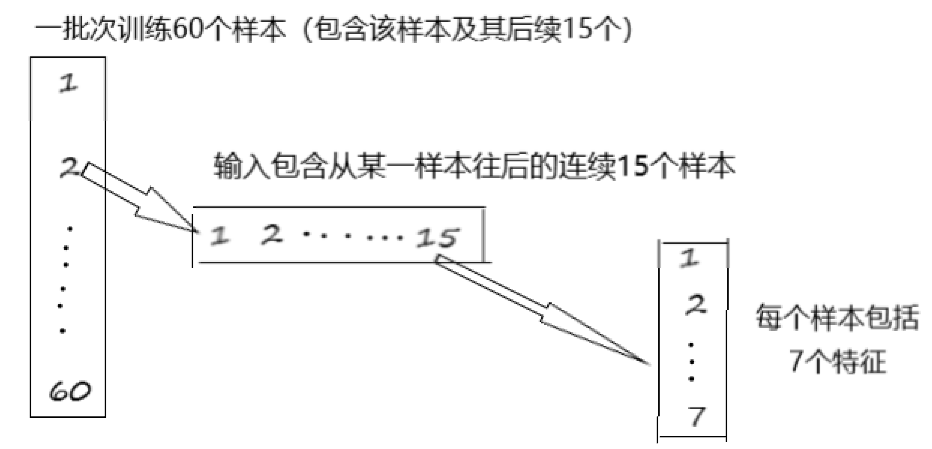
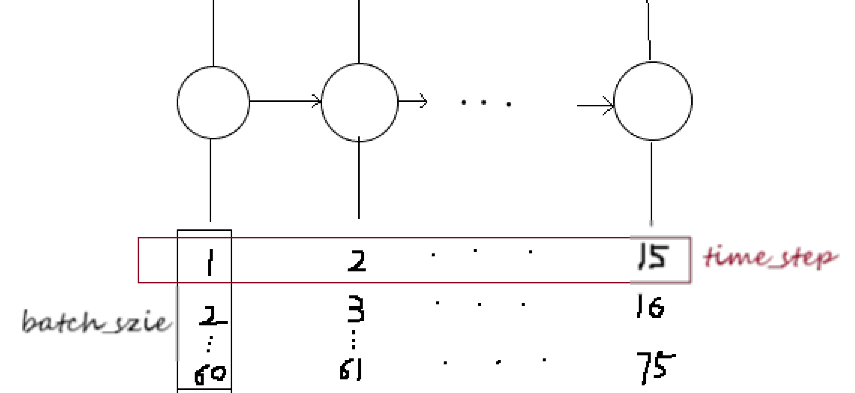
1.训练的话一般一批一批训练,即让batch_size 个样本同时训练;
2.每个样本又包含从该样本往后的连续seq_len个样本(如seq_len=15),seq_len也就是LSTM中cell的个数;
3.每个样本又包含inpute_dim个维度的特征(如input_dim=7)
因此,输入层的输入数据通常先要reshape:
x= np.reshape(x, (batch_size , seq_len, input_dim))
(友情提示:每个cell共享参数!!!)
举个例子:
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import numpy as np
#在这里做数据加载,还是使用那个MNIST的数据,以one_hot的方式加载数据,记得目录可以改成之前已经下载完成的目录
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
'''
MNIST的数据是一个28*28的图像,这里RNN测试,把他看成一行行的序列(28维度(28长的sequence)*28行)
'''
# RNN学习时使用的参数
learning_rate = 0.001
training_iters = 100000
batch_size = 128
display_step = 10
# 神经网络的参数
n_input = 28 # 输入层的n
n_steps = 28 # 28长度
n_hidden = 128 # 隐含层的特征数
n_classes = 10 # 输出的数量,因为是分类问题,0~9个数字,这里一共有10个
# 构建tensorflow的输入X的placeholder
x = tf.placeholder("float", [None, n_steps, n_input])
# tensorflow里的LSTM需要两倍于n_hidden的长度的状态,一个state和一个cell
# Tensorflow LSTM cell requires 2x n_hidden length (state & cell)
istate = tf.placeholder("float", [None, 2 * n_hidden])
# 输出Y
y = tf.placeholder("float", [None, n_classes])
# 随机初始化每一层的权值和偏置
weights = {
'hidden': tf.Variable(tf.random_normal([n_input, n_hidden])), # Hidden layer weights
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'hidden': tf.Variable(tf.random_normal([n_hidden])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
'''
构建RNN
'''
def RNN(_X, _istate, _weights, _biases):
# 规整输入的数据
_X = tf.transpose(_X, [1, 0, 2]) # permute n_steps and batch_size
_X = tf.reshape(_X, [-1, n_input]) # (n_steps*batch_size, n_input)
# 输入层到隐含层,第一次是直接运算
_X = tf.matmul(_X, _weights['hidden']) + _biases['hidden']
# 之后使用LSTM
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0)
# 28长度的sequence,所以是需要分解位28次
_X = tf.split(0, n_steps, _X) # n_steps * (batch_size, n_hidden)
# 开始跑RNN那部分
outputs, states = tf.nn.rnn(lstm_cell, _X, initial_state=_istate)
# 输出层
return tf.matmul(outputs[-1], _weights['out']) + _biases['out']
pred = RNN(x, istate, weights, biases)
# 定义损失和优化方法,其中算是为softmax交叉熵,优化方法为Adam
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) # Softmax loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Adam Optimizer
# 进行模型的评估,argmax是取出取值最大的那一个的标签作为输出
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# 初始化
init = tf.initialize_all_variables()
# 开始运行
with tf.Session() as sess:
sess.run(init)
step = 1
# 持续迭代
while step * batch_size < training_iters:
# 随机抽出这一次迭代训练时用的数据
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 对数据进行处理,使得其符合输入
batch_xs = batch_xs.reshape((batch_size, n_steps, n_input))
# 迭代
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2 * n_hidden))})
# 在特定的迭代回合进行数据的输出
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2 * n_hidden))})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2 * n_hidden))})
print "Iter " + str(step * batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + \
", Training Accuracy= " + "{:.5f}".format(acc)
step += 1
print "Optimization Finished!"
# 载入测试集进行测试
test_len = 256
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label,
istate: np.zeros((test_len, 2 * n_hidden))}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号