LSTM改善RNN梯度弥散和梯度爆炸问题
我们给定一个三个时间的RNN单元,如下:
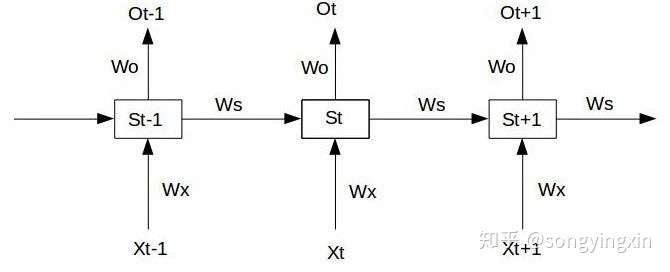
我们假设最左端的输入 为给定值, 且神经元中没有激活函数(便于分析), 则前向过程如下:
在 时刻, 损失函数为
,那么如果我们要训练RNN时, 实际上就是是对
求偏导, 并不断调整它们以使得
尽可能达到最小(参见反向传播算法与梯度下降算法)。
那么我们得到以下公式:
将上述偏导公式与第三节中的公式比较,我们发现, 随着神经网络层数的加深对 而言并没有什么影响, 而对
会随着时间序列的拉长而产生梯度消失和梯度爆炸问题。
根据上述分析整理一下公式可得, 对于任意时刻t对 求偏导的公式为:
由 以上可知,RNN 中总的梯度是不会消失的。即便梯度越传越弱,那也只是远距离的梯度消失,由于近距离的梯度不会消失,所有梯度之和便不会消失。RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系。

参考:
https://www.cnblogs.com/bonelee/p/10475453.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号