

强化学习基础知识
之前杂七杂八的看了很多关于强化学习的知识,脑子里比较混乱,经过这次的梳理感觉清晰条理了很多。
一、Terminologies
Agent、State、Action、Environment、Reward
Policy:Π( a | s ),策略函数,以状态 s 作为输入,输出所有动作 a 的概率。
State transition:状态转移,根据当前 s 与选择的 a ,状态会变为 s' 的概率。
Return( cumulative future reward ):把 t 时刻开始的奖励全都加起来,一直到结束。
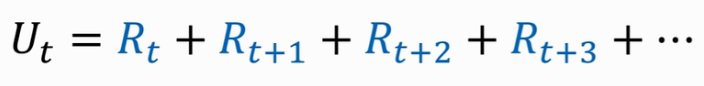
Q:Are Rt and Rt+1 equally important?
A:No, Rt+1 should be given less weight than Rt (Rt depends on St、At).
So, Discounted Return( cumulative discounted future reward ):
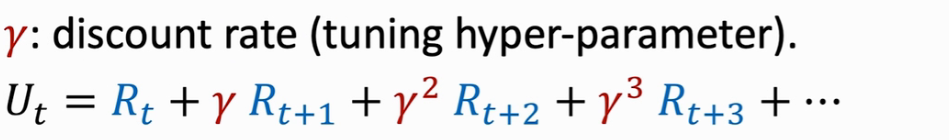
[ps:Ut is just a random variable,并不知道它在 t 时刻等于多少。]
At time step t, the return Ut is random. Two sources of randomness:
(1)Action can be random:通过 Policy 输出一个概率分布,动作 a 就是从该分布中随机抽样得到的。
(2)New state can be random:给定当前 s 和 a ,通过 State transition 输出一个概率分布,Environment 从这个分布中随机抽样得到一个新的状态 s'。
整体流程为:由 Environment 决定状态s,Agent 在 s 中根据 Policy 选择 a ,Agent 做出动作后,环境会更新 State,同时环境会给 Agent 对应的奖励 Reward。
二、Value Functions
Action-Value Function Q(s,a):Q 值是对未来动作奖励的期望(期望反映了离散型随机变量取值的平均水平),可以用来说明如果使用 Policy Π,在状态 s 下做出动作 a 是好是坏。

Optimal action-value function:用不同的 Policy Π 就会有不同的 QΠ,如何去掉 Policy Π? ------ 取最大值,让QΠ最大化的Policy Π。意义是在当前状态 s 下,可以对每个动作 a 进行一个评估,让 Agent 每次可以选择最好的动作 a。
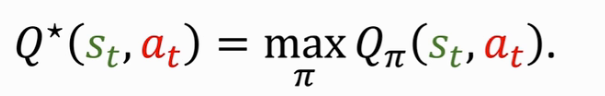
State-value function:VΠ是QΠ的期望,把动作 A 作为随机变量,关于 A 求期望把 A 消掉,最后得到的 VΠ 只跟 Π 和 S 有关。意义是评估当前的局势好坏,A 的概率密度函数是 Π( | st )。
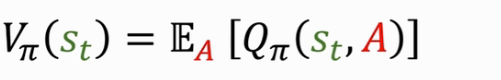 (Actions are discrete)
(Actions are discrete)
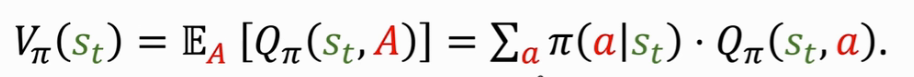
(Actions are continuous)
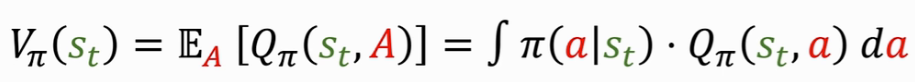
三、How does AI control the agent?
Method1:
Suppose we have a policy Π ( a | s ),observe state s, 通过 Π 得出每个 a 的概率 p ,然后做随机抽样得到 a ,最后 agent 执行该动作 a。
Method2:
Optimal action-value function,observe state s,每一个 s 作为输入,然后对每个 a 进行评价,选择最大的 Q 值对应的动作 a 作为输出,即:
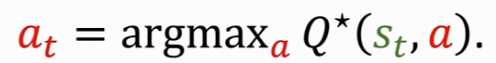
所以RL的目标就是学习到 Policty or Q_star。
四、CartPole Game
import gym # make()生成对应环境 env = gym.make('CartPole-v0') # reset()重置环境,即获取初始环境 state = env.reset() # 每一轮循环Agent做一个动作,环境会更新状态,给出奖励 for t in range(100): # 渲染,将运行效果展示出来(可视化) env.render() print(state) # 随即均匀的抽样一个动作记为action,实际上不应该随即均匀抽样,这样Agent会乱来,实际中会根据policy或Q函数计算一个action action = env.action_space.sample() # env.step(action),此时agent开始执行动作action,同时更新状态,返回奖励 state, reward, done, info = env.step(action) # done表示游戏进行到这一步是否结束,若结束则为1,反之为0 if done: print('Finished') break env.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号