
scrapy + selenium爬取网易新闻
前言:这算是一个比较综合的案例,理清了该案例会感到最近学的知识变的很条例、很清晰。需求是爬取五大板块对应的新闻标题以及每个标题对饮的新闻内容。
(一)分析网易页面
对于首页,通过定位发现每个板块都是嵌套在<ul>中,以单独的<li>存在。
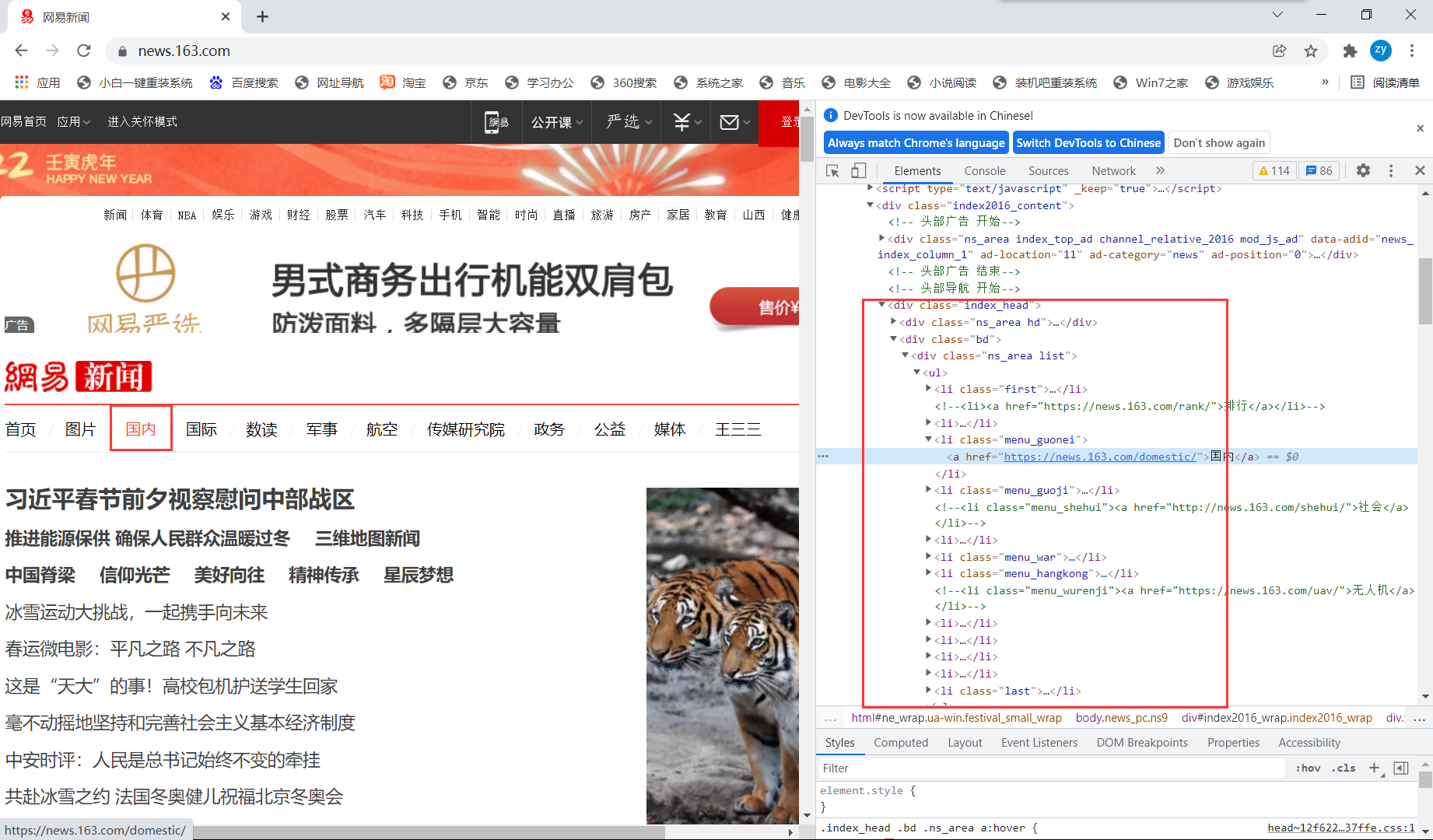
点击每个板块,进去后发现页面是这样加载的:
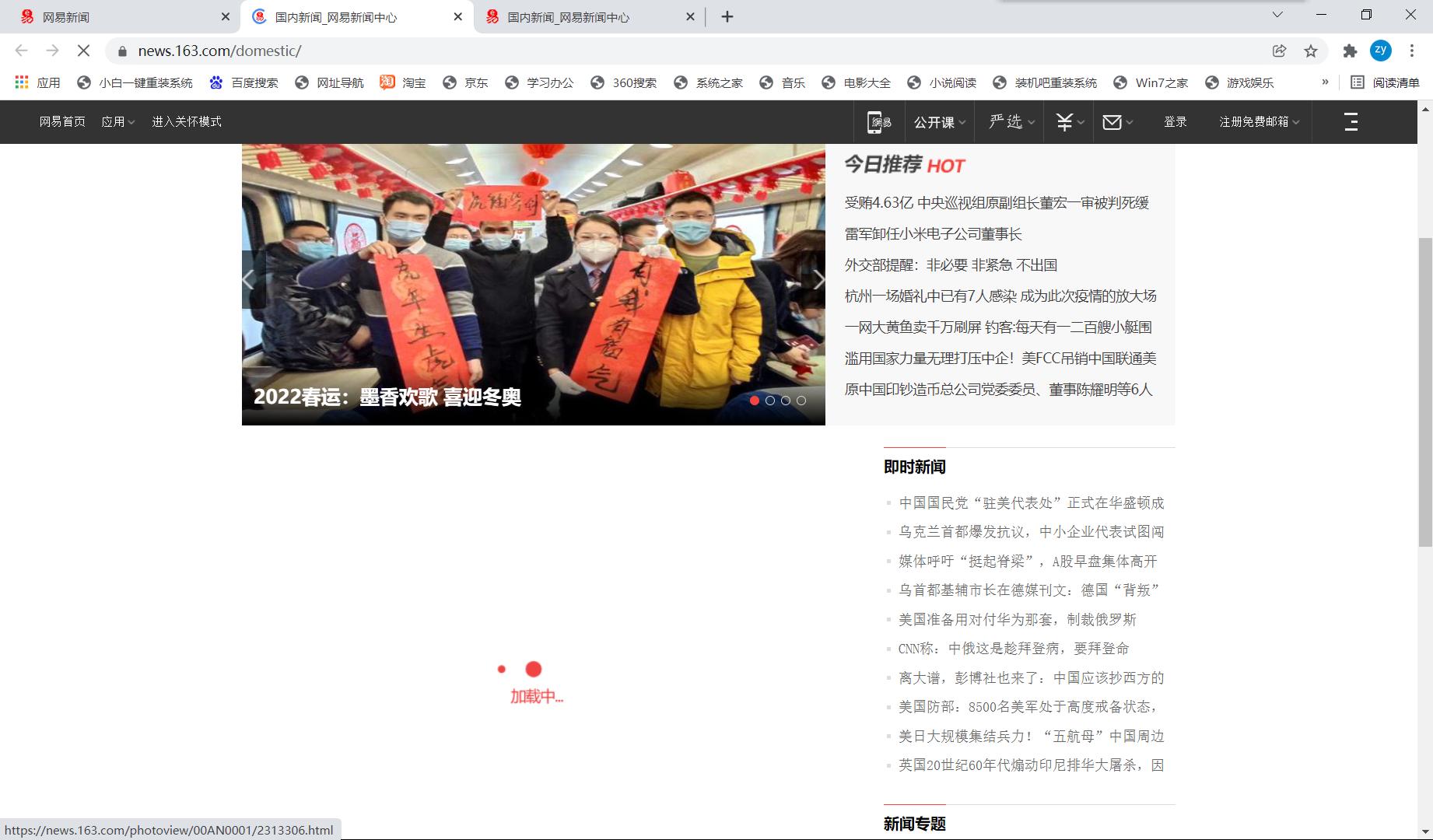
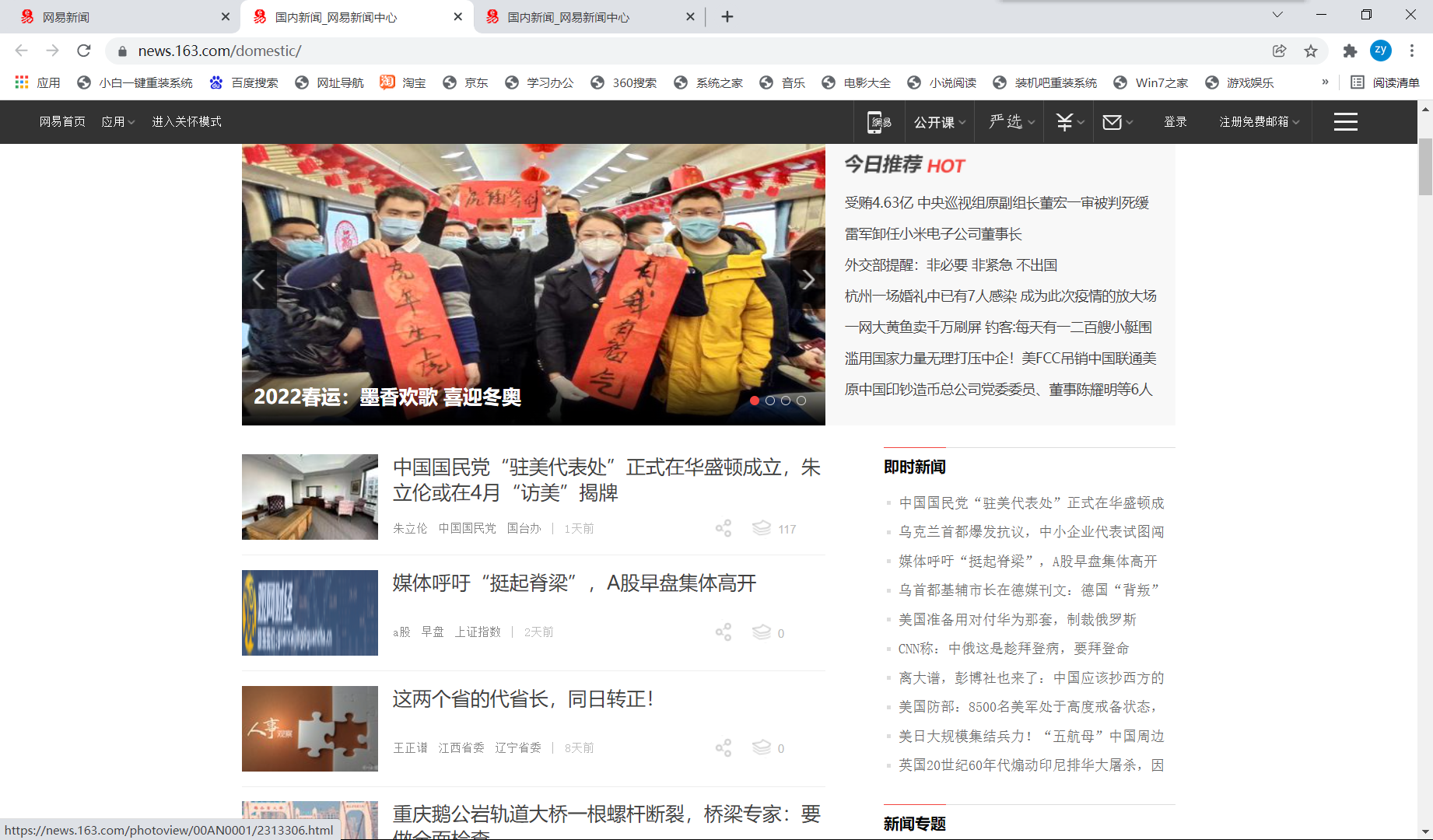
说明每个板块的新闻标题都是动态加载出来的数据(也对,新闻这种实时更新的内容是动态加载出来的也在意料之中),动态加载的数据我们不能直接通过当前url来解析到,那怎么办呢?
回顾五大中间件,调度器给到引擎url后,引擎将它发送到下载器,然后下载器去互联网上获取response,那么目前这种情况response里面是不包含动态加载数据的,因此我们需要对返回的response进行篡改,让它包含了动态加载数据。
问题来了,获取动态加载数据最便捷的方法是之前学过的selenium,可以通过selenium实现获取动态加载数据,那么在哪进行篡改呢,又在哪用selenium呢?------ 既然要篡改返回的response,那自然就在下载中间件的地方实现篡改喽。
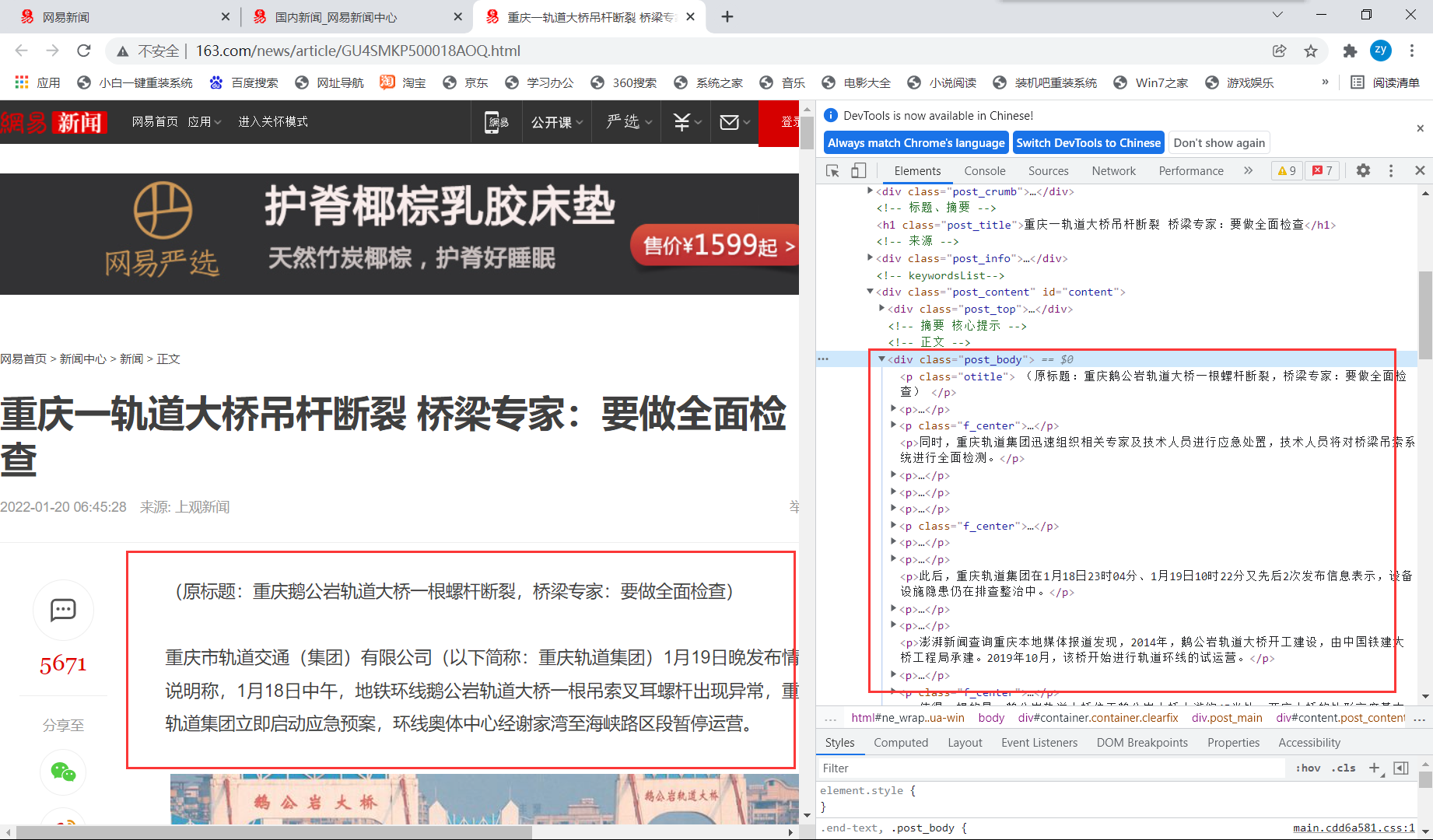
至于每条新闻标题对应的新闻内容,这就好说了,可以看到是直接写在源码中的,可以直接解析到,然后获取即可。
(二)代码编写
首先,获取五大板块的url并把它们存储到一个列表中,并依次对列表中的每个url发起请求:
# 解析首页五大板块url
def parse(self, response):
li_list = response.xpath('//*[@id="index2016_wrap"]/div[3]/div[2]/div[2]/div[2]/div/ul/li')
alist = [2,3,5,6]
for index in alist:
model_url = li_list[index].xpath('./a/@href').extract_first()
self.model_urls.append(model_url)
# 依次对各个板块url发起请求
for url in self.model_urls:
yield scrapy.Request(url,callback=self.parse_model)
接下来,我们要编写parse()中的回调函数parse_model(),涉及到response,那么就得去编写下载中间件进行篡改了。
先分析一波:所谓的篡改,无非就是用包含动态加载数据的new_response替代原response,那么new_response如何获得呢?
答:通过selenium再次向五大板块的url发起请求,此时的response中就包含了动态加载数据,然后用scrapy封装好的一个类HtmlResponse进行获取。
那么首先需要实例化一个浏览器对象,通过该对象进行selenium的模拟请求:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
def __init__(self):
self.s = Service(r'D:\Python\spider\selenium\chromedriver.exe')
self.driver = webdriver.Chrome(service=self.s)
接着在middlewares中进行编写,由于process_response继承了spider,也就意味着spider中涉及到的url需要进行一次检验,是五大板块的url在进行selenium的重新请求,否则直接用原response就行。
【注意:middlewares中有两个类,对应两个中间件,一个是爬虫中间件一个是下载中间件,别写错地方了,我们要写在类DownloaderMiddleware中】
# 拦截五大板块对应的响应对象,进行篡改
def process_response(self, request, response, spider):
# 获取在爬虫类中定义的浏览器对象
driver = spider.driver
# 挑选出需要篡改的response对应的request对应的url
if request.url in spider.model_urls:
# 针对五大板块对应的response进行篡改
# 对五大板块的url发起请求
driver.get(request.url)
sleep(2)
# 获取了包含动态加载数据的页面
page_text = driver.page_source
# 实例化一个新的响应对象(包含动态加载的数据)来代替原来旧的响应对象
new_response = HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request)
return new_response
else:
# 其它请求的response
return response
那经过上述操作,此时我们的response已经实现功能全覆盖,直接在脚本文件中编写回调函数即可:
# 解析每个板块对应的新闻标题(新闻标题是动态加载出来的,获取动态加载的数据用Selenium)
# 编写完下载中间件的process_response后,此时的response已经是new_response
def parse_model(self,response):
div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div')
for div in div_list:
news_title = div.xpath('./div/div[1]/h3/a/text() | ./div/h3/a/text()').extract_first()
news_detail_url = div.xpath('./div/div[1]/h3/a/@href | ./div/h3/a/@href').extract_first()
item = WangyiproItem()
item['news_title'] = news_title
# 对新闻详情页的url发起请求
yield scrapy.Request(url=news_detail_url,callback=self.parse_detail,meta={'item':item})
注意用到了请求传参,我们需要去item中定义一下item的内容:
class WangyiproItem(scrapy.Item):
# define the fields for your item here like:
news_title = scrapy.Field()
news_content = scrapy.Field()
# pass
另外注意请求传参的使用:
def parse_detail(self,response):
news_content = response.xpath('//*[@id="content"]/div[2]//text() | //*[@id="content"]/div[2]/div[1]//text()').extract()
news_content = ''.join(news_content)
item = response.meta['item']
item['news_content'] = news_content
yield item
注意一个小细节,在开头实例化了浏览器驱动程序后,记得在最后给它关闭,减少没必要的资源消耗:
# 关闭浏览器驱动程序
def closed(self,spider):
self.driver.quit()
最后,我们把获取到的新闻内容存储到一个txt文本中,方便观察运行结果,采用管道存储方式:
class WangyiproPipeline:
fp = None
# 重写父类方法,打开存储文件
def open_spider(self,spider):
print('开始爬取......')
self.fp = open('./网易新闻.txt','w',encoding='utf-8')
# 该方法专门用来处理item类型的对象,接收爬虫文件提交过来的item对象
# 该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
news_title = item['news_title']
news_content = item['news_content']
self.fp.write(news_title + ':' + '\n' + news_content + ':' + '\n')
return item
# 关闭文件
def close_spider(self,spider):
print('爬取完成!!!')
self.fp.close()
至此,代码内容已经编写完成,还需要设置一下,不遵守robots协议,UA伪装,设置输出日志的类型,同时打开下载中间件和管道类的配置信息:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'wangyiPro.pipelines.WangyiproPipeline': 300,
}
(三)报错处理
在运行后,一般可能有两个问题,一是:

二是:
ERROR:device_event_log_impl.cc(211)] USB: usb_device_handle_win.cc:1020 Failed to read
descriptor from node connection: 连到系统上的设备没有发挥作用。 (0x1F) 3ERROR:device_event_log_impl.cc(211)] Bluetooth: bluetooth_adapter_winrt.cc:1204 Gettin
g Radio failed. Chrome will be unable to change the power state by itself.
ERROR:device_event_log_impl.cc(211)] Bluetooth: bluetooth_adapter_winrt.cc:1297 OnPowe
redRadiosEnumerated(), Number of Powered Radios: 0”
问题一可能两种情况,一是数据解析时候xpath路径定位错了,二是获取列表元素时候忘加索引项了;至于问题二其实会正常运行,但强迫症的我还是想去掉这个提示,加几行代码即可:
# 实例化浏览器对象
def __init__(self):
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
self.s = Service(r'D:\Python\spider\selenium\chromedriver.exe')
self.driver = webdriver.Chrome(service=self.s,options=options)
(四)运行效果:
(马上要过年了,祝各位博友春节快乐,学业有成!!!)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号