

scrapy之五大组件
先说明一下五大组件各自的作用:
- 引擎(Scrapy)
用来完成整个系统的数据流处理,触发事务(框架核心)。
- 调度器(Scheduler)
包括两部分:过滤器和队列,用来接受引擎发过来的请求,先经过过滤器对请求进行去重,然后压入队列中,可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,然后再根据队列将URL返回给引擎。
- 下载器(Downloader)
用于下载网页内容,并将网页内容封装到response中,将它返回给引擎,引擎再把它返回给Spider(Scrapy下载器是建立在twisted这个高效的异步模型上的)。
- 爬虫(Spider)
爬虫是主要干活的,用于产生URL并对URL进行请求发送,然后调用response进行数据解析,封装在item(实体)中。
- 管道(Pipeline)
负责处理爬虫从网页中抽取的实体item,主要的功能是持久化存储、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过这几个特定的次序处理数据。
流程图:
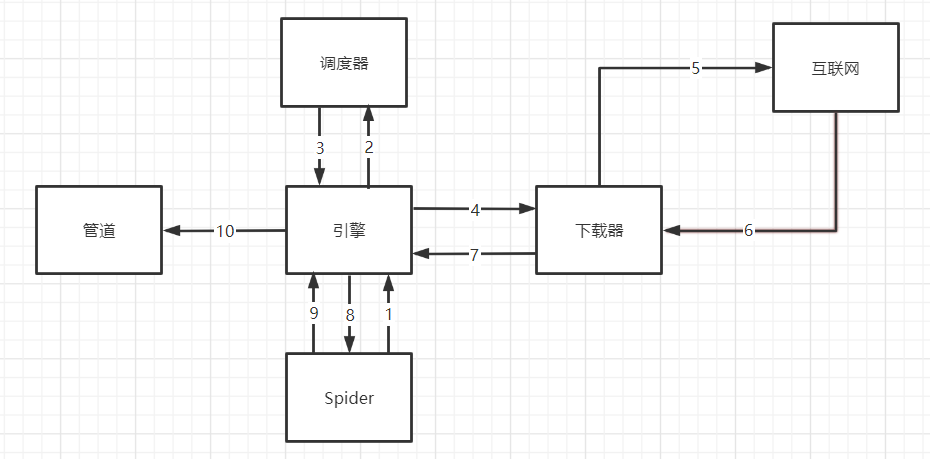
流程说明:
Spider将url封装成的请求对象发送给引擎,引擎再将它发送给调度器,经过调度器操作后给引擎返回URL队列,引擎再把它发给下载器进行下载数据,之后给引擎返回response,引擎再将它返回给Spider,然后Spider根据它生成item,发送给引擎,引擎在把它发送给管道。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号