
scrapy的安装最新完整版(包括坑的预处理)
- 环境的安装
— mac 和 Linux的不要太轻松,直接:pip install scrapy
— windows相比而言可是麻烦不少,分以下几部分安装:
(1)pip install wheel
(2)下载Twisted,下载地址为 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted,下载对应版本的Twisted
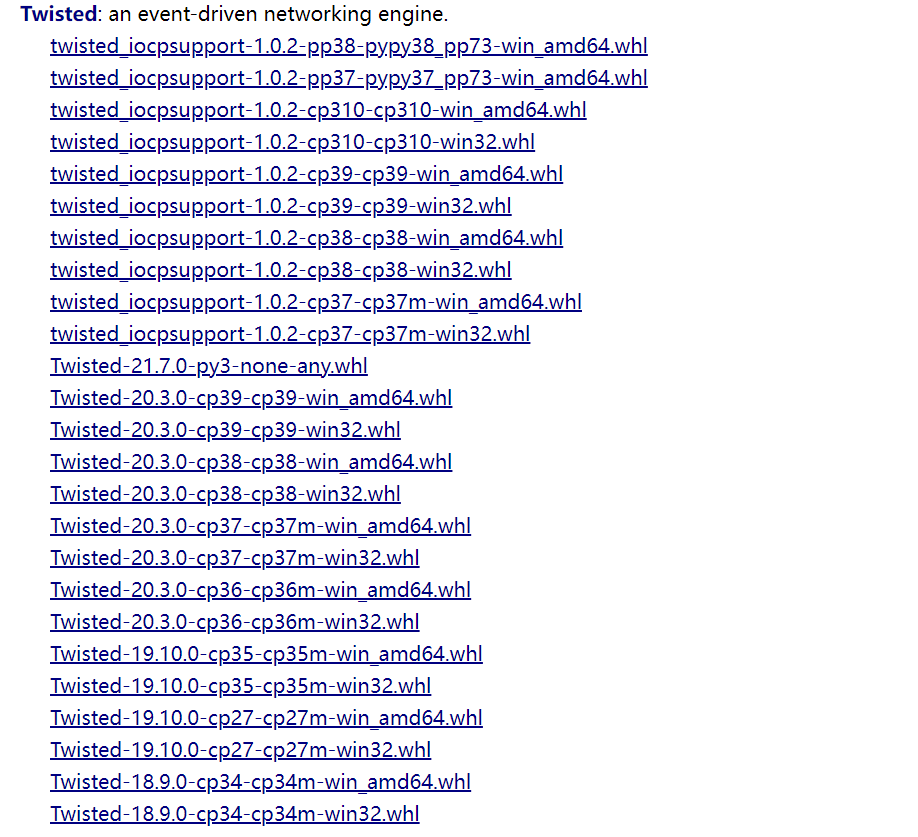
cp后面的数字对应你的python版本,比如笔者的python是3.7,就下载cp37m。
(3)安装Twisted:pip install Twisted‑17.1.0‑cp36‑cp36m‑win_amd64.whl,下载好上面的.whl文件后,最好是把它放到对应的项目空间中,记住这个路径,否则会很麻烦(笔者就因为路径的问题,折腾了一晚上......),比如:我放到了这里:
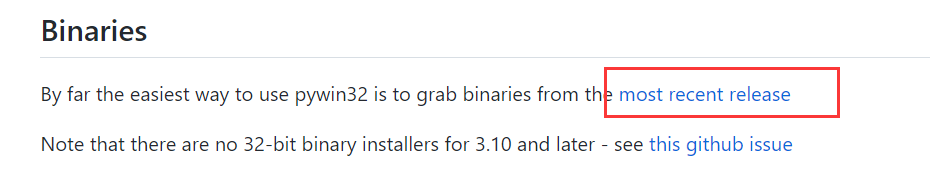
(4)安装pywin32,python3.7之前的好像直接在pycharm中或者是通过pip命令行就可以安装,但是我的是python 3.7,既不能在pycharm中直接按照也不能通过pip安装,只能手动安装了(骂骂咧咧...),打开 https://github.com/mhammond/pywin32/,往下翻,有:
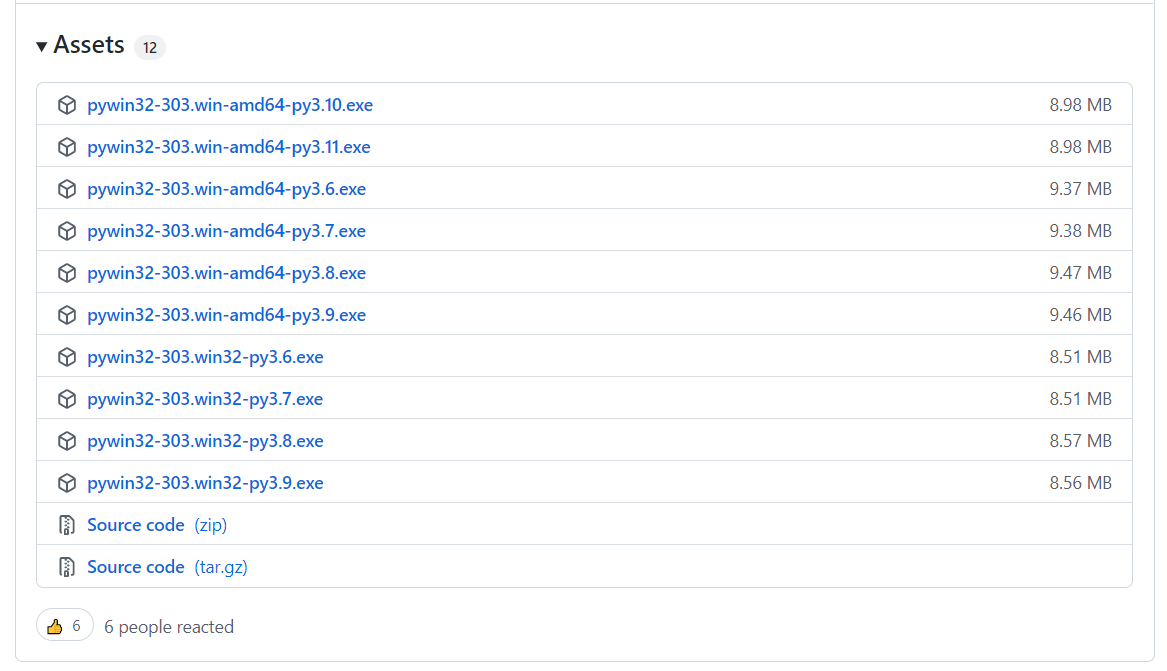
点击进入,选择自己对应的版本:
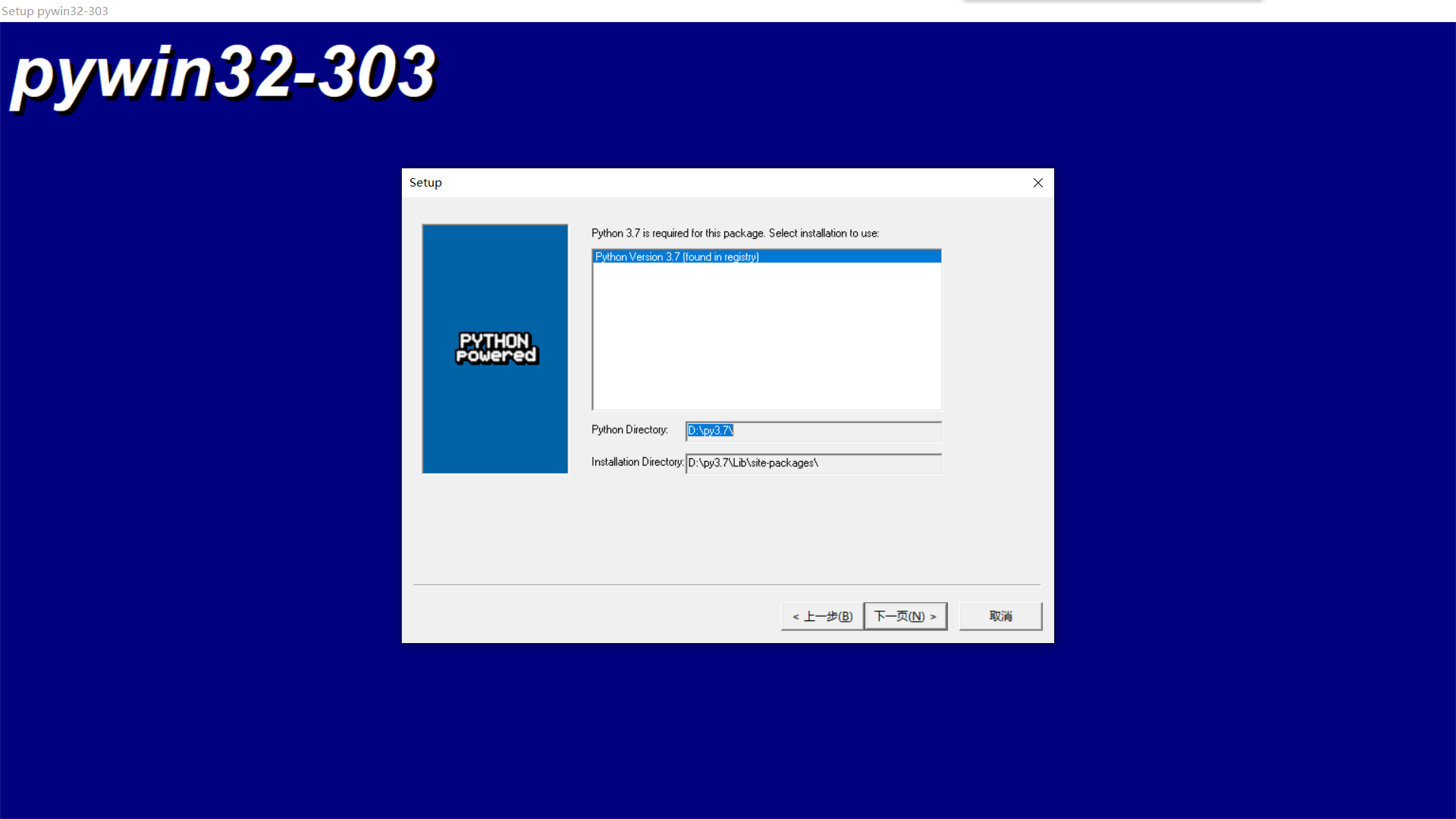
一直Next,最后Finish,安装完毕。
【注意:pywin32下载的.exe一定要和Twisted的.whl放在同一个目录下,这样在后面安装scrapy时候会方便很多!!!】
(5)安装scrapy,直接在pycharm的终端Terminal输入pip命令,如果之前的路径设置好的话,会很快很顺利的安装好,如果路径没弄好的话会在安装某个包的地方卡死,然后超时报错,网上虽然有对应的解决方案是延长时间,pip命令输为:pip --default-timeout=1000 install -U scrapy,虽然解决了超时报错的问题,但这样安装会很慢很慢,个人尝试了这种方法,一直是4.5K/s,安装好得猴年马月(家里的网络还是不错的......)
安装完毕后,在终端输入scrapy没有报错则是成功安装。
- 创建工程
在终端输入命令:
scrapy startproject ProName


创建项目成功后,看看项目的文件目录,首先会生成一个spiders的子目录,里面存放的是爬虫源文件,还有配置文件scrapy.cfg和settings.py。
- 在spiders子目录中创建爬虫文件
在终端输入命令:
cd ProName
scrapy genspider spiderName www.xxx.com(xxx后面可以在代码中直接修改)
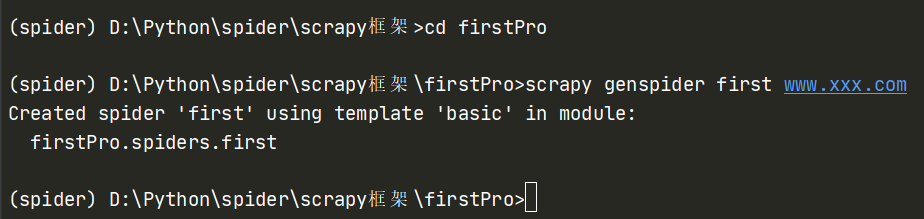
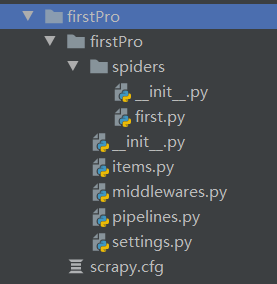
import scrapy
class FirstSpider(scrapy.Spider):
# 爬虫文件的名称,唯一标识,后面会根据该标识定位该文件
name = 'first'
# 允许的域名,用来限定start_urls列表中哪些url可以进行请求发送,不过一般不使用,注释掉
allowed_domains = ['www.xxx.com']
# 起始的url列表,该列表中存放的url会被scrapy自动进行请求发送,代替了之前requests手动get/post请求
start_urls = ['https://www.baidu.com','https://www.sogou.com']
# 用作数据解析,response参数表示的是请求成功后对应的响应对象
def parse(self, response):
print(response)
- 执行工程
scrapy crawl spiderName
接下来涉及到一些简单配置,以上述代码运行为例:
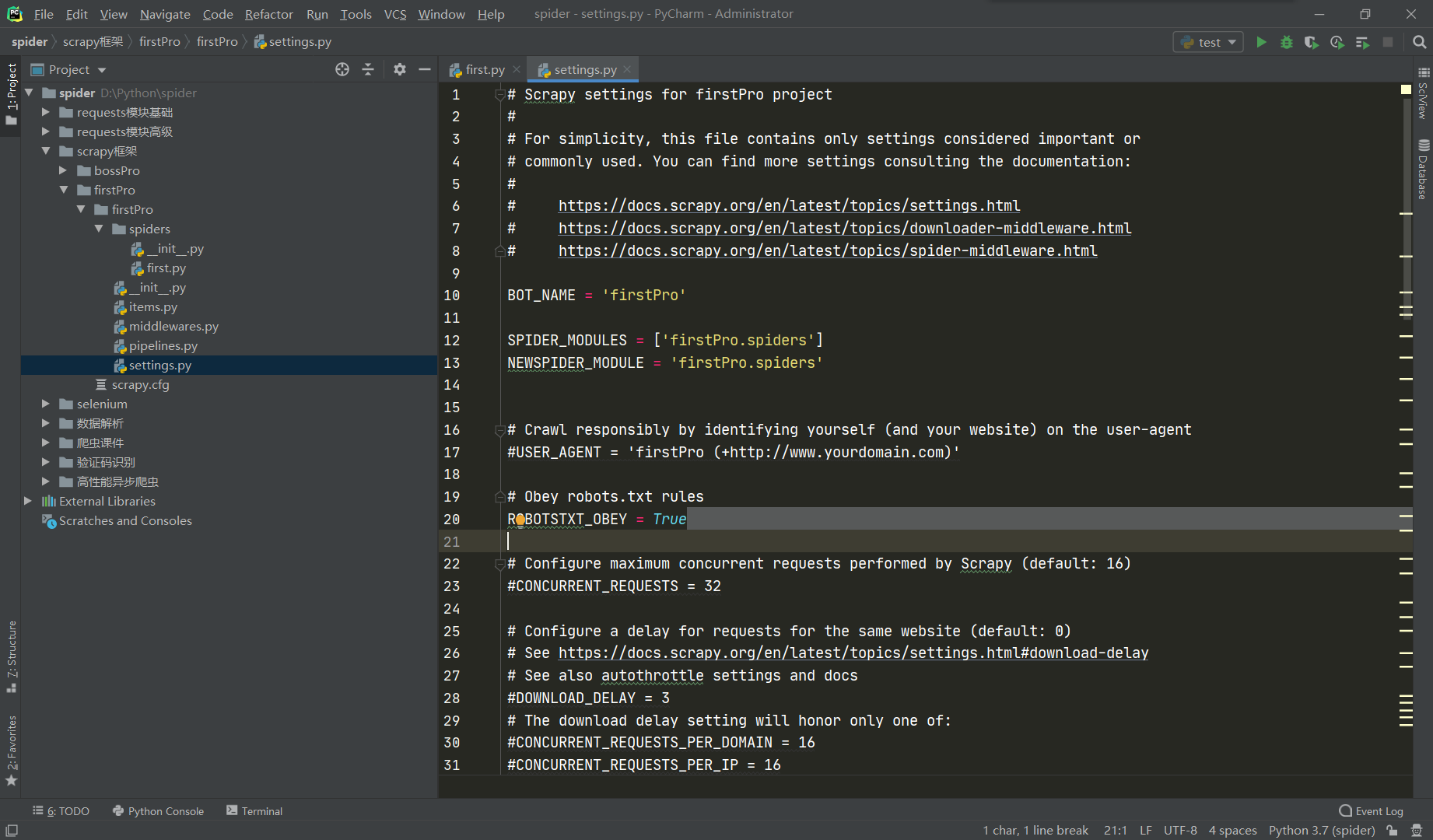
打开setting.py,第20行意思是遵守robots协议,在之前就说过,每个门户网站都会设定一个robots协议,规定哪些是可以爬取的数据哪些不可以爬取,如果遵守的话我们几乎爬不到任何内容,所以这里要改为False。
下图为运行结果:
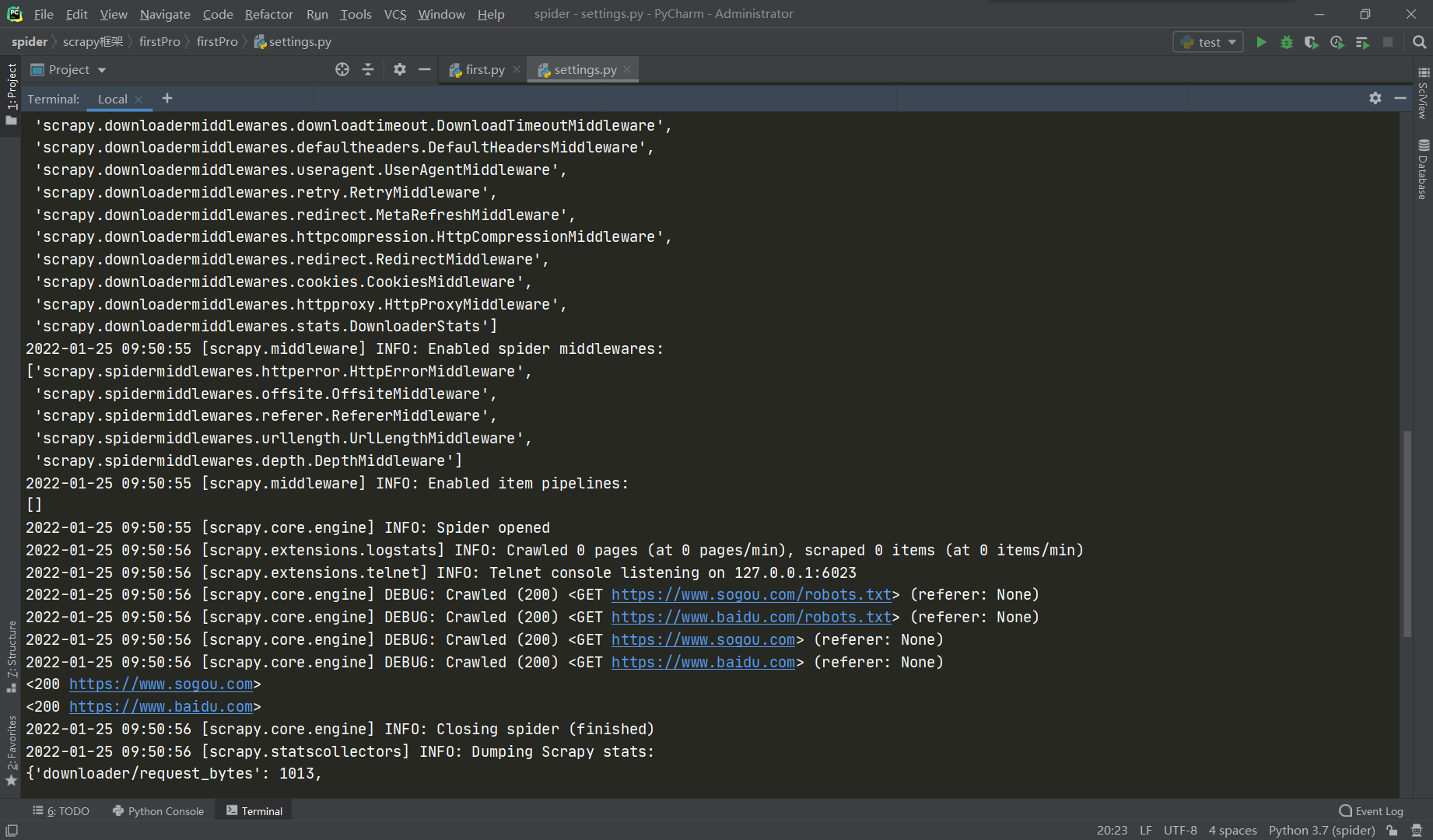
可以看到,爬取的内容已经打印出来了,但却包含在很多密密麻麻的日志文件中,并不直观也不利于我们直接了当的看到运行结果,可如果把日志文件都不打印的话,如果有报错或者警告的话,我们也查看不到,所以我们要在配置文件中设置:
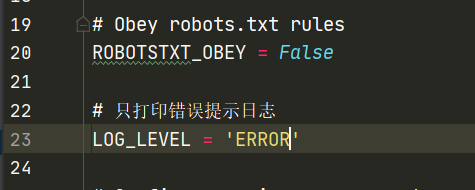
设置好了再次运行:

可以看到只运行了输出结果,没有多于日志信息。
把代码改错,再试一下,看看情况:
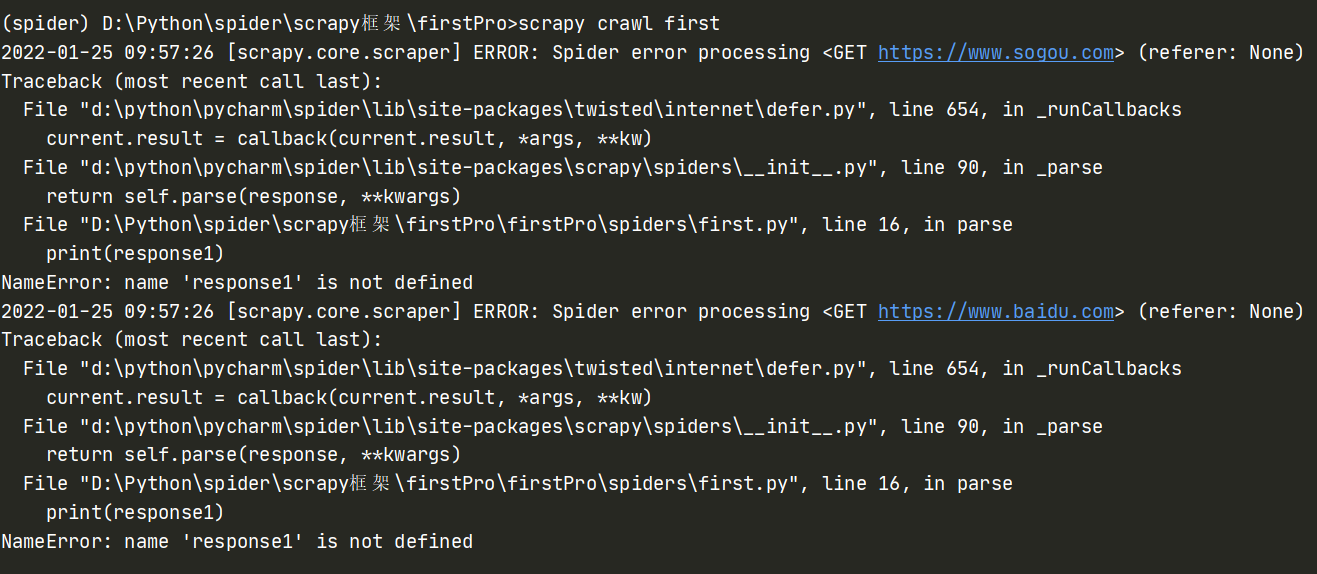
可以看到,只有提示错误的日志,没有多于内容,一目了然。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号