

数据解析之bs4
选择器bs4进行数据解析:
- 数据解析的原理:首先进行标签定位,然后进行提取标签以及标签属性中存储的数据
- bs4数据解析的原理:首先实例化一个BeautifulSoup对象,并将页面源码数据加载到该对象中,然后通过调用BeautifulSoup对象中相关的属性和方法进行标签定位和数据提取
- 环境安装:bs4与lxml
- 实例化BeautifulSoup对象:
1、导包:from bs4 import BeautifulSoup
2、对象的实例化,有两种方法:
方法一:将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml') # 参数二是固定的,参数一是本地的html的文件指针fp
方法二:将互联网上获取的源码页面加载到该对象中
page_text = response.text
soup = BeautifulSoup(page_text,'lxml')
3、提供的用于数据解析的方法和属性:
soup.tagName(标签名):返回的是文档中第一次出现的tagName对应的标签


soup.find():返回一个单数,只能找到符合要求的第一个标签的内容
(1)find('tagName'):等同于soup.tagName
(2)属性定位:soup.find('tagName',属性名='属性值') ------------------------------------------------------------- 【若属性名为特殊的class等,加个下划线即可】
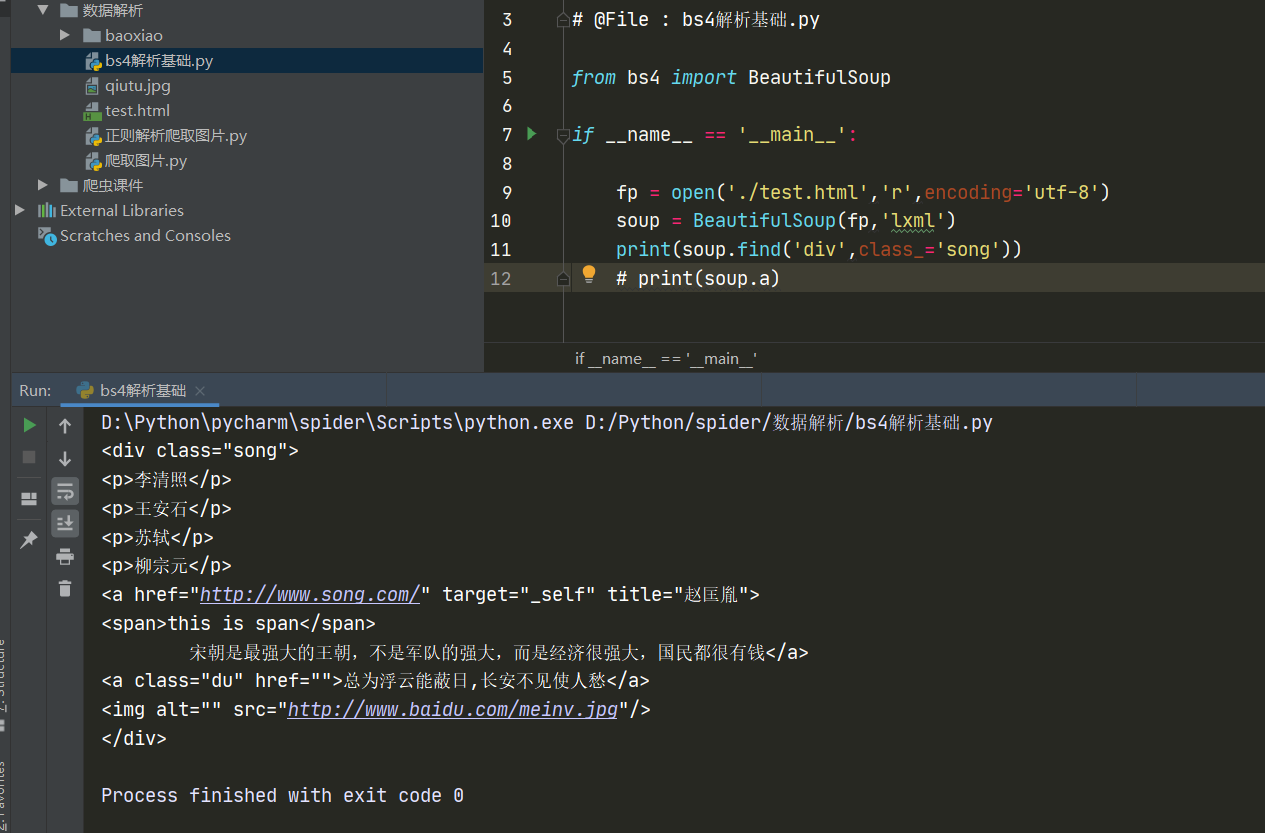
soup.find_all('tagName'):返回一个复数(列表),可以找到符合要求的所有标签内容
soup.select():
soup.select('某种选择器(id、class、标签等)'),返回一个列表 ------------------------------------------------------------- 【类选择器写法 .value值】

层级选择器soup.select('选择器1 > 选择器2 > 选择器3')[Num]: > 表示一个层级,因为返回的是一个列表,所以用[Num]表示选取列表中的第Num个内容
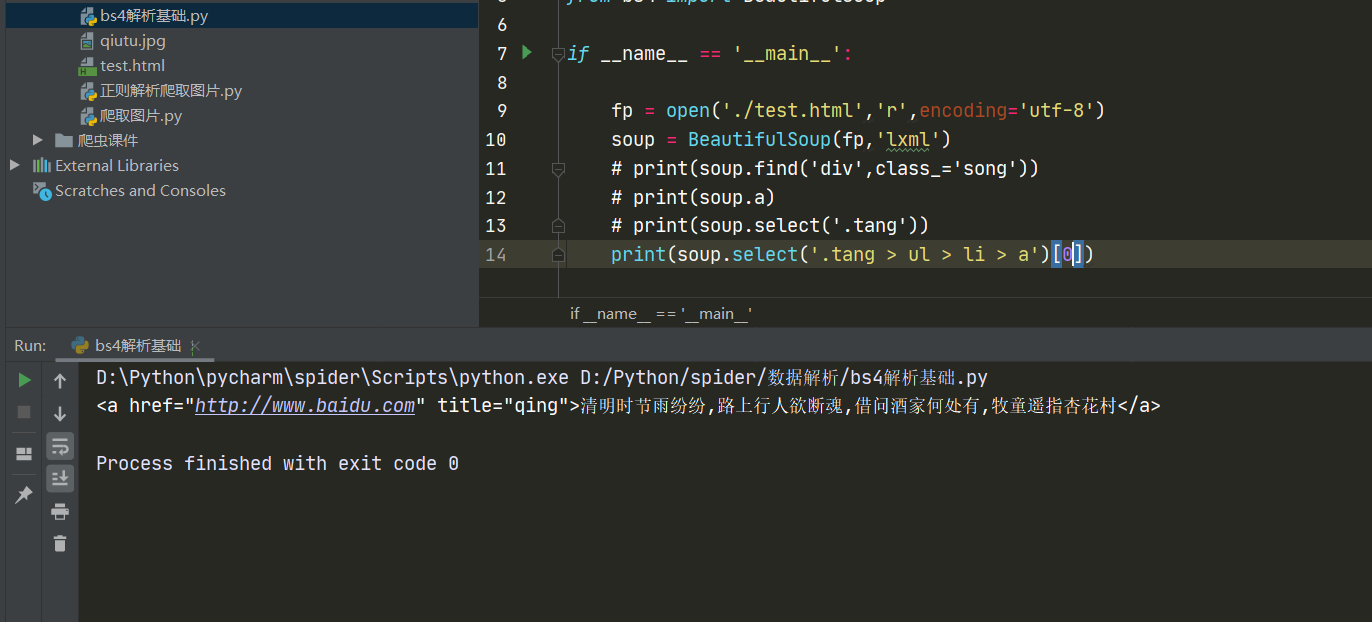
层级选择器soup.select('选择器1 > 选择器2 选择器3'):空格表示多个层级
4、获取标签之间的文本数据:
在定位到某个标签后,还需要获取,比如:soup.a.text、soup.a.string、soup.a.get_text()
区别:.text与.get_text()可以获取某一标签中所有的文本内容;.string只可以获取该标签下直系的文本内容
5、获取标签中的属性值:
soup.a['属性名称']
- 实际案例:爬取某小说的标题与章节内容
首先,对首页数据进行爬取,按照之前的代码会存在抓取到的数据乱码的问题,于是对代码进行了改进:
# 对首页页面数据进行爬取 url = 'https://www.shicimingju.com/book/sanguoyanyi.html' # 解决标题乱码 html = requests.get(url=url,headers=headers) html.encoding = 'utf-8' page_text = html.text
然后通过分析可知,我们要找的章节标题和详情页的超链,在class为book_mulu的div中:
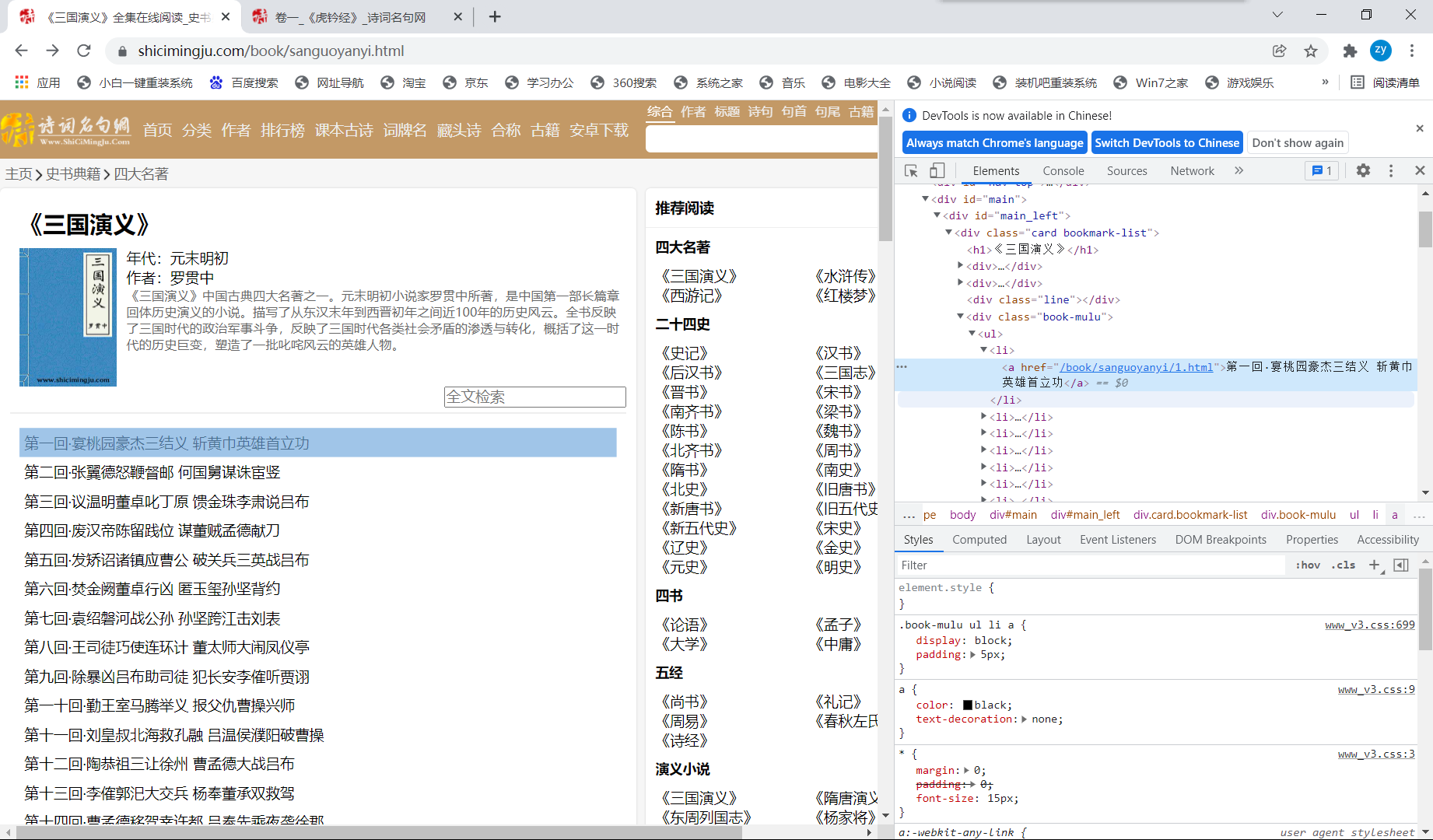
那么就可以开始编写代码了,通过select解析,初步解析出一个存放<li>标签内容的列表,然后对该列表进行遍历,每次要通过string获取单个<li>标签中的<a>标签的内容,即为标题;再获取标签属性值href,即为每章节详情页的url,接下来模拟对每章详情页发送请求,然后解析出小说正文内容,最后获取到并进行持久化存储,over!!!
for li in li_list: # 获取li标签中的a标签的数据,因为string只能获取直系数据 title = li.a.string detail_url = 'https://www.shicimingju.com/' + li.a['href'] # 对详情页发起请求,解析出章节内容 # 解决文本乱码 html_detail = requests.get(url=detail_url,headers=headers) html_detail.encoding = 'utf-8' detail_page_text = html_detail.text # 解析出详情页中的章节内容 detail_soup = BeautifulSoup(detail_page_text,'lxml') div_tag = detail_soup.find('div',class_='chapter_content') # 获取章节内容 content = div_tag.text # 持久化存储 fp.write(title + ':' + content + '\n') print(title,'爬取成功!!!')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号