
requests实现动态爬取页面的局部数据
以百度翻译为例:
用过百度翻译的小伙伴们都知道,在输入需要翻译的内容后,页面只会刷新翻译框下面的内容,并不会刷新整个页面,因此这种情况使用的是ajax,打开抓包工具,如下:
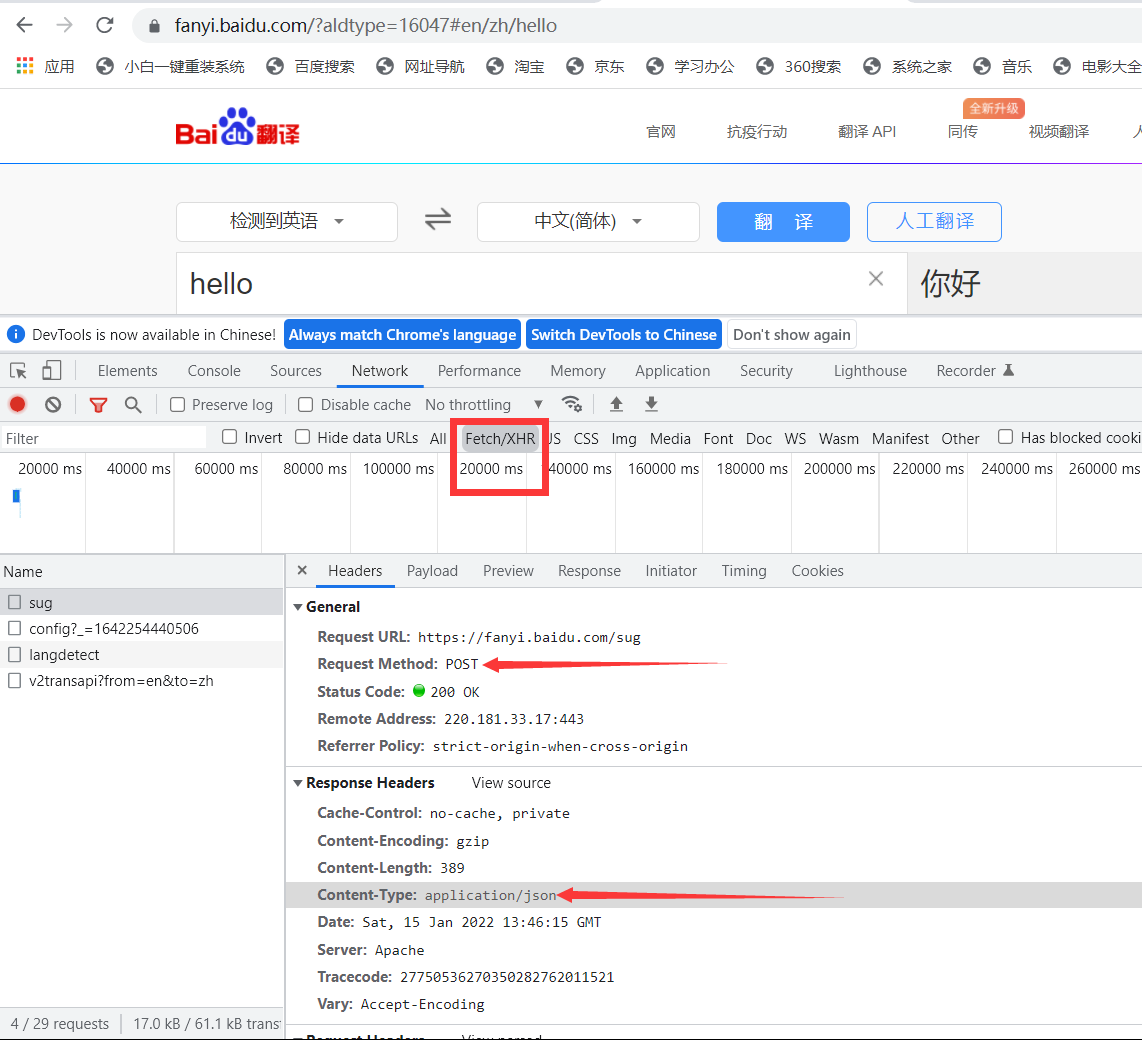
我们选中XHR后,可见该请求是POST类型,于是爬虫程序需要编写为POST型,此外还需要注意返回的响应数据为JSON格式。
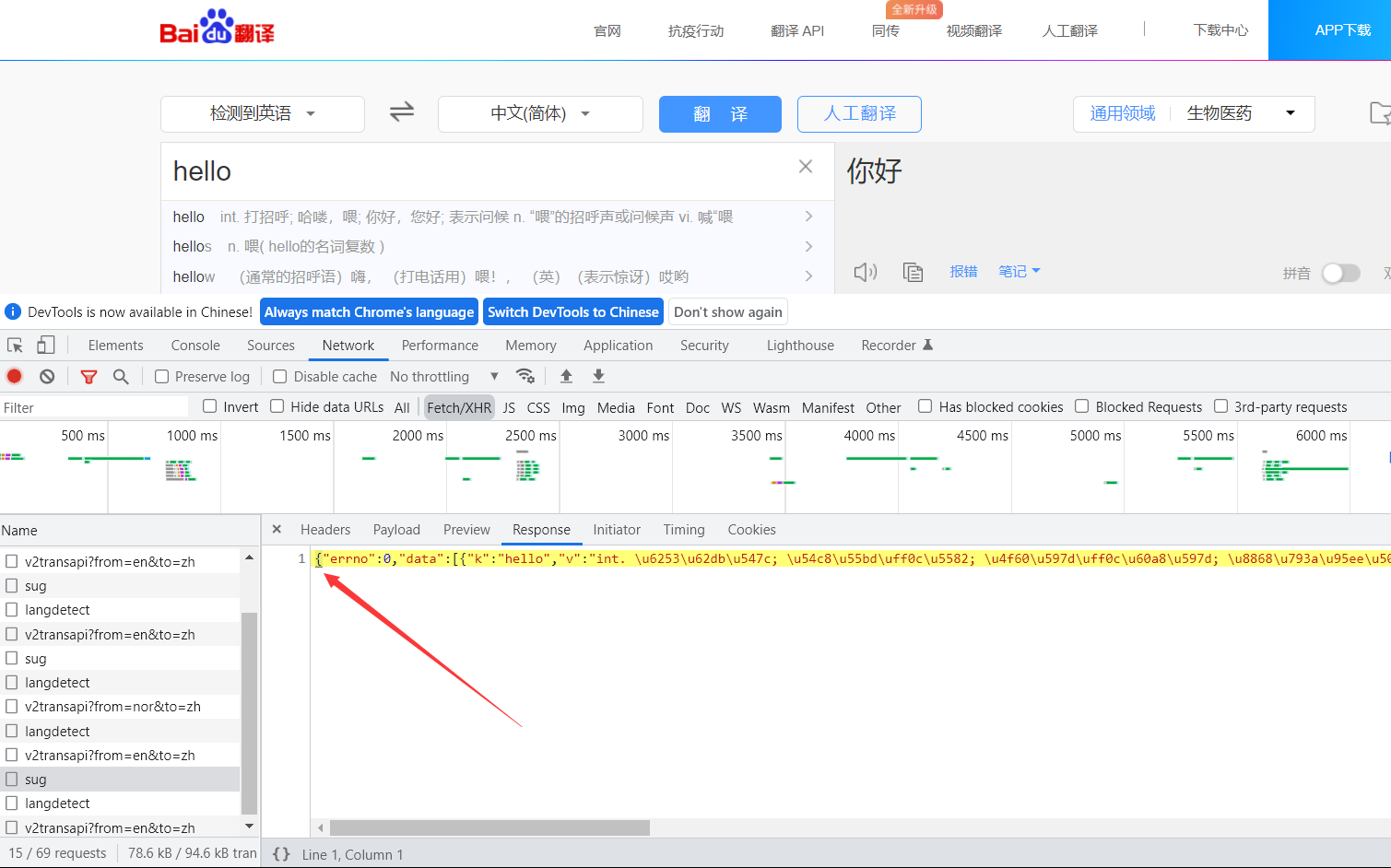
然后点开response,里面的内容为单括号开始,所以拿到的是字典对象,定义为dic_obj:
post_url = 'https://fanyi.baidu.com/sug'
# post请求处理
word = input('enter a word:')
data = {
'kw':word
}
response = requests.post(url=post_url,data=data,headers=headers)
# 获取响应数据,由于响应数据格式为json,而json()返回的是obj,当且仅当确认响应数据类型为json,才可以使用json()
dic_obj = response.json()
print(dic_obj)
在进行持久化存储时,因为要存储json格式的数据,所以直接使用json.dump()方法即可:
# 持久化存储
fileName = word + '.json'
fp = open(fileName,'w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
运行成功!


补充两个内容:
- 关于json.dump()
json.dump(para1,para2)用来存储json数据
para1:要存储的数据
para2:可用于存储数据的文件对象
如果json反应的文本内容均为中文则设置ensure_ascii=False
- 关于GET请求与POST请求区别
GET请求中参数携带在url后,并且有长度限制;而POST请求参数携带在request body中,其实他们本质没有区别,因为都是HTTP协议中的两种请求方式,底层都是TCP / IP

 浙公网安备 33010602011771号
浙公网安备 33010602011771号